-
Interface Summary Interface Description AddressServer Provides an API for the implementation of a registry of the nodes in the network, especially in regards to enabling effective multi-hop routing.InterruptHandler An API for objects that handleInterruptedException.LowLevelSession API for transport-level session function.MessageTypes Defines all valid message types for the distributed application protocol.NetSocket This interface represents a (secure) socket/channel and all related input/output streams as a one unit.NetSocket.NetSocketFactory NetSocket factorySession Defines the public API for a network session, including methods for low level message transport, and methods for higher level session management.SessionListener Defines an event notification framework for users of network sessions.StateSynchronizer An interface for objects which manage incremental and bidirectional synchronization of state between two sides of a P2J session. -
Class Summary Class Description AddressPair This is a simple container as a payload during the address exchange procedure (INIT_STANDARD/INIT_CONVERSATION/INIT_REPLY messages).BaseSession Abstract implementation of theSessioninterface.BlockingSSL Implements SSL support over the SocketChannel.ByteArrayHandler This class splits input data stream into chunks.Control Tracks the state of the "conversation" between the two sides of the networking session and provides a local and remote delivery mechanism for notification of interruptions.Control.Operation Container for the current executed operation and its type.Conversation This class represents one side of a two-sided single-threaded cooperative synchronous communication session.CriticalSectionManager This class provides a mechanism to protect critical sections against thread interruption.CriticalSectionManager.WorkArea Container for context-local variables.DirectSession A concrete implementation of theSessioninterface, built uponBaseSession.Dispatcher This class represents an incoming request processor.Dispatcher.KeyMapEntry This class is used as an entry in the Key Map.Echo Helper class which provides a simple mechanism to test a session's connectivity.Echo.Invoker Helper class to delegate execution of thetransactEchomethod.ExportTracker A session tracker for each static exported API.HighLevelObject Base class for remote objects which provides some useful utility methods.InboundRequest This class holds a message and a reference to the instance of theQueuewhich received that message.InvocationStub Provides common logic for dynamic proxy implementations.LeafSessionManager Concrete implementation of a session manager for a leaf network node.LocalRedirector Provides the proxy handler for a local object which redirects interface methods to target instance methods.LocalStateSync Used by a proxy to implement state synchronization where both "sides" are in the same JVM.LocalStaticRedirector Provides the proxy handler for a local object which redirects interface methods to static target methods.LoggingNetSocket Logging wrapper for different implementation of the NetSocket interfaceMessage This class represents messages which are used to exchange information via the distributed application protocol.NetResource Implements the "net" abstract resource.NetRights Implements the "net" rights objects.NetSocketBase Implements NetSocket operations with session listeners.NetSocketWrapper This class represents a (secure) socket and all related input/output streams as a one unit.NIONetSocket Implements NetSocket operations which are specific for insecure channelsNIONetSocketBase Implements NetSocket operations which are common for all NIO-based implementations.NIOSslSocket Implements NetSocket operations which are specific for SSL channelsNodeInfo This class is a simple container that describes a single node in the network.Protocol This class implements the low level part of the protocol.Queue The Queue class is the kernel of message processing.RemoteObject Helper class which can handle the export, import and transaction processing for a given list of interfaces.RemoteObject.RemoteAccess Provides the proxy implementation for a remote object.RemoteObject.WorkArea Stores global data relating to the state of the current context.RequesterSession An extension of a multiplexed session, used on the requesting side of a virtualized connection.Router This singleton class is responsible for delivering messages between nodes which have no direct connection.RouterSessionManager Concrete implementation of a session manager for a router network node.RoutingKey RoutingKey holds all information related message routing, both external routing (source and destination node addresses) and internal routing (exported entry point IDs).SessionManager This class is the central focal point of all queue and session management for the net package.SessionManagerFactory Factory for creating a singleton instance of the networkSessionManagerfor this process.SSL Implements abstract SSL FSM.SyncMessage This class provides state synchronization extensions to a standard message.VirtualSession A concrete implementation of theSessioninterface, built uponBaseSession.WaitingThread This class represents an container which is placed into Pool of Waiting Threads (PWT). -
Enum Summary Enum Description RouterSessionManager.Mode Connection mode -
Exception Summary Exception Description ApplicationRequestedStop This class represents an artificial exception object which is used as an indicator that particularQueueinstance is stopped by application request.ProtocolViolation An extension of the Exception used to notify application that protocol is violated.RequestTimeoutException An extension of the Exception used to notify application that timeout occurred during processing of the request.SilentUnwindException This class represents an artificial exception object which is used as an indicator that the Conversation thread needs to be terminated, as the client connection went down.
Package com.goldencode.p2j.net Description
Provides a multiplexed, symmetric low level network transport,
transaction requester/server support and all necessary queuing,
addressing, naming, routing and security integration needed to create a
logical network of leaf and router nodes that can implement a flexible
distributed application system.
Design Criteria
Messages
Network Transport
Queues
Exporting Interfaces
Remote Objects
Remote Method Call Flow
Routing and Address Space
Session Authentication and Final Setup
Terminating a Session
State Synchronization Hooks
Asynchronous Session Interruption
Performance Hints
Exported Interface Access Control
Backward Compatibility
TODO List
Introduction
The Distributed Application
Protocol (DAP) is the name of the protocol provided by this package.
The DAP is designed as a message passing system where messages are exchanged by nodes arranged into a logical network.
The network is comprised of leaf nodes and routing nodes. Leaf nodes are end-points in the network. They may only have a direct connection to a routing node. Routing nodes may connect to any type of node and are a superset of leaf node function with the additional ability to forward or route messages between two nodes which have no direct connection. The logical network can be arbitrarily complex by connecting routing nodes together into mesh, star, tree or other topologies. Nothing in the protocol has any knowledge or dependency upon the topology of the logical network. That is left as a runtime choice.
For the network to exist, a session must be established between two nodes (leaf <--> router or router <--> router). As more nodes establish sessions, the network grows. Messages may be passed between any two nodes that have an active session with the same logical network. A message may be directly sent (if the two nodes are directly connected) or indirectly sent (if no direct connection exists between the nodes).
Messages can contain a graph of arbitrarily complex objects as a payload. The Serializable interface is used to enable the transmission and reception of messages over a network connection.
Each end of a session has a message queue that is used to send and receive messages. Once a message is enqueued, if the caller does not require synchronous processing, the caller continues immediately without waiting for transmission. If the caller requires the semantics of a synchronous call, then that calling thread will block while the message is sent to the other side, processed there and the result is returned. Even though the protocol is based on messages and queues (an inherently asynchronous concept), at the high level interface to the caller, the mechanism naturally provides for both synchronous and asynchronous forms of processing.
Messages contain the following fields:
Messages can be manually and dynamically created by an application. This would be required for any "low level" usage of the DAP.
The vast majority of applications use the remote object paradigm. In such cases, each side of a session has a local object upon which to make method calls. These method calls are transparently converted into the proper messages and synchronous semantics by the remote object implementation. This means that the messages and their usage are completely hidden from the high level caller of the remote object.
Each node can have can have more than one session active at a time. This is common for routing nodes and is even possible for leaf nodes. An example of such a use on a leaf node would be providing an infrastructure for automatic failover. No such usage is currently implemented, but it is possible.
On each side of the session, there is a protocol driver (implemented as an instance of the Protocol class). The protocol driver is just a low-level transmission worker for the socket. Protocol instances have no real idea of the packet structure being sent over the socket, it simply provides a reader thread and writer thread. Even the socket is somewhat abstracted, since it is represented as 2 streams (an ObjectInputStream and an ObjectOutputStream).
The message passing system is designed with an asynchronous approach (as is common in message passing systems). As such, the protocol does not place any synchronous requirements or constraints on the transmission of messages. This means that some temporary storage is needed to hold inbound and outbound messages. This queuing function is provided by the Queue class. There is a queue instance on each side of every session. The queue handles storage but it also provides the public interface to the session. Messages that are enqueued for outbound transmission in a given queue instance will be sent on the associated session. Messages received from that session will be enqueued in the inbound queue of the associated Queue instance.
While the session is active, the protocol driver's reader thread uses Serialization to read and restore an object from the ObjectInputStream. This object is the message that was sent from the peer end (the remote side) of the session. This message is then enqueued using Queue.enqueueInbound(). The reader then reads the next object or blocks on reading the input stream when there are no objects to read.
Likewise, the protocol driver's writer thread dequeues outbound messages using Queue.dequeueOutbound() and then uses Serialization to write the object to the ObjectOutputStream. It continues to do this while it finds outbound messages to send otherwise it blocks in dequeueOutbound().
The protocol driver is the "lower third" of the overall DAP design. This functionality is driven by the queue and is not available at the application level.
By implementing using Serialization, any Serializable object can be sent through this protocol, without unusual measures being taken. This leverages the value of the J2SE platform, without requiring the disadvantages of RMI. This does limit this implementation to supporting only Java clients and servers, although this limitation is not any significant issue for the following reasons:
Internally, the Queue is really made up of 3 queues and a table (or map) of waiting threads. The queues:
In standard mode, blocking is handled by storing a descriptor in a map of waiting threads and blocking the calling thread on that descriptor (using wait()). This map is called the Pool of Waiting Threads (PWT) and it contains information about all suspended threads waiting for results from the remote side. In conversation mode, there is only a single thread that is involved so the blocking is handled without the descriptors and PWT.
Through forward() and transact(), the queue presents an upper level interface to the "middle third" of the protocol. It is the message processing kernel that glues together the upper and lower portions of DAP.
On any node which provides services (entry points) to the DAP network, those services must be registered such that they can be found and used. The process of registration is called "exporting".
The list of exported entry points is maintained in the Exported Interfaces Registry (EIR). Each entry point is uniquely identified by a two part name (a group name + a method name). Each group can be considered a separate API or list of entry points. Each entry point in the same group must have a unique method name.
The use of groups provides a natural separation of method namespace to reduce name conflicts. It also provides a method to organize like or related methods together into a common API. Each group consists of a set of methods. Group names must be globally unique and the names of methods within a specific group are unique but different groups may contain methods with the same names. Therefore each entry point in the EIR is only identified with a combination of two names - the group name and the method name. The separation into groups is completely logical, it does not mean that if a method belongs to some group then that method is required to be part of a particular class or Java interface.
The EIR consists of two parallel mappings:
Since the IDs are based on index positions in this mapping data, the IDs can be seen to be:
RoutingKey generateRoutingKey(String group, String method)
Using this routing key, one may export a new entry point. To do this, use the following Dispatcher methods:
void addMethod(RoutingKey, Object obj, Method method)
void addMethod(RoutingKey, Object obj, Class[] signature, Class class)
void addMethod(RoutingKey, Object obj, Class[] signature, String fullyQualifiedClassName)
Lookups in Method Map are described in message processing: the RoutingKey from each message is used as a key to lookup the target MethodEntry in the Method Map.
Certain "special" entry points are always present in the method map:
All exported entry points are exported for the entire node, they are not registered per-connection. In other words, the EIR is a node-wide resource rather than a per-session resource.
It is very important to note that both leaf nodes and routing nodes can export interfaces. The protocol is completely symmetric in this regard. Providing a service layer on any node is necessary for many kinds of applications such as peer-to-peer, though traditional client/server can also be supported easily.
One can build custom objects and/or alternatives to the provided RemoteObject implementation. In particular, if a higher level asynchronous interface was needed, RemoteObject does not support such a construct at this time. All APIs provided by RemoteObject are synchronous method calls.
The interesting part about the RemoteObject implementation is that it makes it as easy to export an interface as it does to call that interface remotely. Assume that one has a service named "Foo" to export. The API for this service would be defined by a Java Interface named Foo (it could be named anything). Then on the node on which Foo is to be exported:
RemoteObject.registerNetworkServer(Class[] iface, Object impl)
RemoteObject.registerStaticNetworkServer(Class[] iface, Class impl)
In both cases, the list of interface classes define the full set of exported methods (everything that is public, which in an interface is everything). In the case of a static server, the given implementation class is searched for static versions of every method in the list of interfaces. There is no such thing as a "static interface" in Java but this export process behaves as if this were the case. In the case of the non-static server, the given implementation object must actually implement all interfaces in the list. Either way, the java.lang.reflect.Method objects for each exported API are gathered and for each one a routing key is generated and the method is registered for export. At that point, the exported interfaces may be called.
No matter how many sessions exist on this node, the above registration code is enough to export the APIs for the entire node. This is because the EIR is a per-node resource, not a per-session resource.
On the remote node, to obtain a local object that represents the remote service, one uses the following:
Object RemoteObject.obtainNetworkServer(Class iface, Queue queue, int timeout)
The returned object will implement the given interface and will be a local representation of the remote service on the peer end of the given queue. Convenience forms of this are available to use the default queue for the current session. Just cast the returned object to the interface and then make method calls. Everything else is transparently handled by the RemoteObject implementation.
Standard Mode
The following diagram shows the high level flow of a synchronous call between two nodes (in multi-threaded mode).
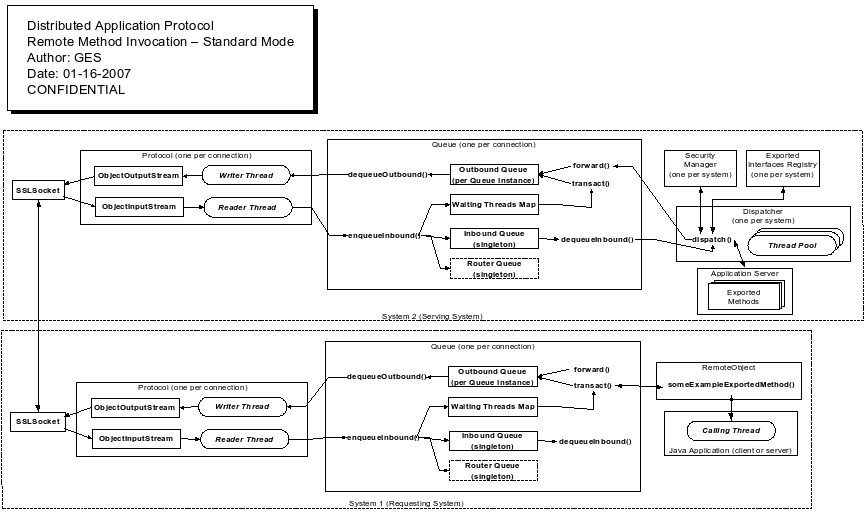
The sequence starts with a Java application on system 1. This application has previously established a session and obtained a RemoteObject which represents an exported interface on the remote node. The application calls someExampleExportedMethod() on that RemoteObject.
The RemoteObject obtains the routing key associated with the someExampleExportedMethod() on the remote node. It then creates a Message with the method parameters marshaled as the payload.
The message is then sent using Queue.transact() method. Inside the queue, a unique requestID is generated and assigned to the message. Then the message is placed into the outbound queue. A new WaitingThread instance is created. Then waitingThread is registered in the PWT using the requestID assigned to the message as a key and the calling thread is suspended by calling the waitingThread.wait() method.
The protocol driver's writer thread retrieves the message from the outbound queue and serializes it onto the stream (an instance of ObjectOutputStream created from the Socket at startup) by calling the stream.writeObject() method.
At the remote side, the protocol driver reader thread restores the message from the stream (an instance of ObjectInputStream created from the Socket at startup) by calling the stream.readObject() method. Then it passes the message to the queue using the queue.enqueueInbound() method. The message is placed into the inbound queue.
A thread from the Dispatcher thread pool retrieves the inboundRequest from the inbound queue using queue.dequeueInbound() method and processes it. Processing includes the following steps:
The protocol driver reader thread restores the message from the stream (an instance of ObjectInputStream created from the Socket at startup) by calling the stream.readObject() method. Then it passes the message to the queue using queue.enqueueInbound() method. This is a reply message so it is processed as follows:
If the Message is a synchronous request, then any returned data from the called method is packaged into a REPLY or REPLY_EXCEPTION message and is enqueued on the correct queue for transmission. The thread then drops its security context (if this is a server system) and tries to read the next incoming message. If there are no messages to read, the thread blocks on reading the incoming queue. Note that the incoming queue in every Queue object is actually a singleton object which allows the Dispatcher to greatly simplify its processing since it only needs to monitor a single incoming queue for all request messages. When it dequeues a message it has access to the Queue reference of the node that originated the message, which is needed to allow the SecurityManager to set its security context AND for the knowledge of where to enqueue any responses.
Since each thread processing a request on a server has its security context set to that of the calling user or process, all security decisions for any resource accessed by that thread can be made in a very natural way since that thread is now the proxy for that user or remote process.
Any response messages that are sent back eventually enter the Queue through the enqueueInbound() method. In multi-threaded mode, this method identifies REPLY and REPLY_EXCEPTION messages and finds the matching descriptor in the waiting threads map. It then stores a reference to the returned data or exception and unblocks the thread (using notify()). The calling thread obtains the return data and returns this to the RemoteObject caller as if the entire transaction had been local. In conversation mode, the reply is posted to the Conversation thread, unblocking that thread and allowing it to return the result naturally (as part of the call stack).
Conversation Mode
The following diagram shows the high level flow of a synchronous call between two nodes (in single-threaded mode).
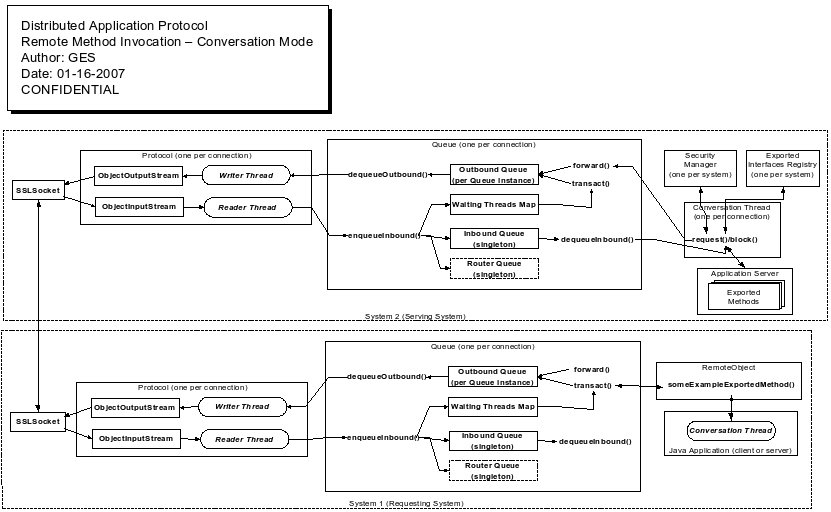
In single-threaded (conversation) mode, both sides have a Conversation object that handles all synchronous messages for the session.
In this mode, any asynchronous messages are still handled by the Dispatcher (see above). The Conversation has a thread that is dedicated to processing all messages for the associated session. The thread has a permanent security context assigned so it does not need to set or drop context for each message as does the normal Dispatcher processing. Other than this, incoming synchronous messages are handled by the Conversation object, exactly as described for the Dispatcher. This thread is also responsible for waiting on responses to synchronous requests that where sent out by this node to the remote node. This is quite different from the Dispatcher approach since in the Dispatcher, only incoming requests are handled.
The conversation mode is useful because it does not require any resources from the Dispatcher's thread pool. The thread pool is a static resource created at startup and then never changed. The Conversation thread, in contrast, is created when a session is initialized and it is dedicated to only that session's processing. When that session terminates, the Conversation thread also terminates. This allows for a dynamic allocation of just those resources needed. When sessions are long-running entities, this approach makes sense.
In any design which is inherently single threaded, the conversation mode is especially valuable. This is because the multi-threaded mode can easily handle the semantics of a single-threaded model BUT it handles nested calls in a manner that is wasteful of resources. Consider the case where node1 calls node2, then node2 (before returning from node1's request) has a nested call back to the node 1. In the multi-threaded model, node1 will have 1 blocked thread waiting on the original request and 1 active thread executing the nested call from node2. node2 has a single thread blocked waiting on the nested call to node2. So for each level of nesting N, multi-threaded mode will require N+1 threads to process BUT ONLY ONE OF THESE THREADS IS ACTIVE AT ANY MOMENT ANYWAY! Conversation mode solves this nesting problem by simply having only a single thread on each side. This works as long as the processing is truly single threaded. If that is not a valid assumption, then conversation mode cannot be used.
Routing and Address Space
In order to support building of the large distributed data processing
systems, the protocol provides a message routing facility.
Message
routing allows delivering of the messages between nodes in the
situations
where nodes have no direct connection.
The routing mechanism is built with two levels. The first layer consists of leaf nodes (clients and servers) which actually process data. The second layer consists of routing nodes or routers. Routers can establish and drop connections to other routers as necessary, routes messages and handle other related tasks.
It should be noted that this layering is a logical architecture. A server which is a leaf node can (and usually does) support the functionality of both layers (i.e. leaf and routing nodes). Each leaf node can have connections to one or more routing node(s). If more that one connection to a router is present then the leaf node can perform load balancing and failover and use some algorithm to choose the router to which a message will be sent for delivery. A leaf node can connect only to routing nodes, it does not connect to other leaf nodes directly.
Provisions have been made to allow an arbitrarily complex distributed system. This is enabled by the concept of addressing and routing. A Router processes messages stored in the Routing Queue, handles them or forwards them to remote nodes. The routing queue is the 3rd queue in every Queue object and is also a singleton queue. This allows the Router to read from a single queue that is fed from multiple connections. The Router handles all aspects of the address space partitioning/distribution, name lookups, firewall support, remote access enablement (remote authentication) and of course the actual forwarding of messages between nodes.
The following diagram shows a simplified view of a node with a Router:
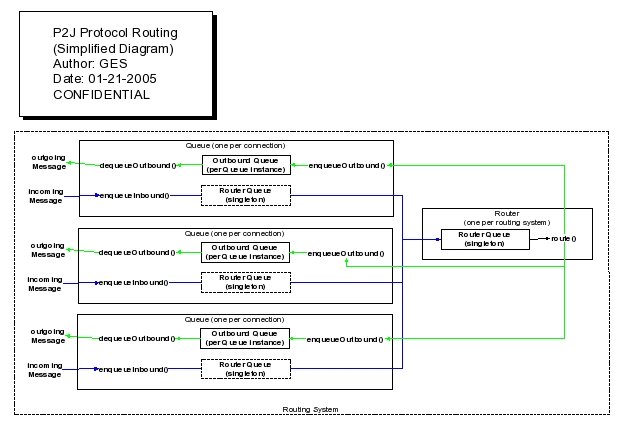
The blue arrows show inbound flows and the green arrows show outbound flows.
Node Address
Each node (regardless of the layer) has a node address. One system may have more than one node address. For example, if a leaf node has connections to more than one routing node, each routing node assigns a unique address to the leaf node. In order to deliver messages and replies, the router requires information about source and destination node addresses. This information is stored in the RoutingKey which is part of each message.
Address Distribution
Each routing node has a set of addresses which belong to that routing node. In that address space, the first address is assigned to the routing node itself and the last address is a special broadcast address. A Message sent to the broadcast address is delivered to all leaf nodes connected to the routing node. It is not delivered to other routing nodes that are connected. The Routing node assigns an address from its address space to each client which connects. When the connection is closed, the address is released and can be assigned to another leaf node.
When two nodes establish a connection they exchange address information. For this purpose the node which establishes the connection sends an INIT_STANDARD message (to request a multi-threaded mode session) or INIT_CONVERSATION message (to request a conversation or single-threaded mode session). If the node that initiates the connection is a routing node, this message contains the router's address. If the connecting node is a leaf node, no address is sent to the routing node since at connection the leaf node has no address assigned. This tells router that it must assign an address to the client. When routing node connects other routing node, it already has an assigned address, so it just informs remote node about its address. Presence of the address in the INIT_STANDARD or INIT_CONVERSATION message from a routing node informs the remote node that an address is already assigned and there is no need to allocate one from the routers' address space. A leaf node may neither request nor require a particular address using this facility. Any address specified in this message by a leaf node will be ignored.
Address Partitioning
Taking into account that the routing mechanism has exactly two layers and in order to simplify address space management, each node address consists of two logical parts: the high bits of the address represent the address of the routing node to which a particular address belongs while the low bits represent the specific address in the routing node's address space. An address with low bits set to 0 is assigned to the routing node itself and the address with all low bits set to 1 represents the broadcast address. The broadcast address is used to send s message to all nodes connected to a particular routing node.
For example:
If the node address contains 32 bits and the address is split into two parts with 16 bits each, then the system can have up to 65536 routing nodes and each routing node can have up to 65534 clients (two addresses are dedicated for the routing node address and the broadcast address). Each routing node in this case has an address like 0x00010000, 0x00020000, etc. The broadcast address which belongs to these nodes will be 0x0001FFFF, 0x0002FFFF, etc. Clients of the routing node 0x00010000 will get addresses in the range 0x00010001-0x0001FFFE.
This approach simplifies address maintenance because the node address also encodes the router's node address, the broadcast address, the range of addresses assigned to the routing node and even the node type.
Address Server
In addition to leaf and routing nodes, an important part of the routing mechanism is the address server. The purpose of the address server is to hold and process address information. All routing nodes use the address server to request information about other routing nodes, to translate node addresses into names and vice versa, etc. A particular implementation can have a real or virtual address server. If the address server is virtual, it is most likely that the Router implementation provides the address server functionality as well.
The address server represents a centralized approach to the maintenance and access of routing tables. This makes it unnecessary to dynamically exchange routing tables between routers at runtime. This is a great simplification to the protocol.
At this time, the design of this centralized registry is not complete nor is there more than a cursory interface implemented.
Virtual Session Support
In order to communicate with "far" nodes (i.e. nodes which do not belong to the local router's address space) the router supports a Remote Node Registry. This registry contains a list of all local queues (connected leaf nodes) which have sent at least one request message to "far" nodes. For each such session, the router maintains a list of addresses of "far" nodes and the security context ID for each address. The security context ID is used to help the "far" node maintain its associated security context during the processing of request messages. Since there is no direct connection between a "far" node and the node which sends a request message, it is impossible to perform direct authentication (and therefore create a security context) and drop security context when connection is closed. In order to resolve this problem the following mechanism is introduced:
When a client sends it's first message to a "far" node, the router finds that there is no appropriate record in the Remote Node Registry. Then it performs the following steps:
void terminateSession(int ID);
The security context ID entry points mentioned above are implemented by the Dispatcher class and must be exported by all nodes which support processing of "far" requests (such nodes MUST have a security manager). In order to access these entry points there is no need to request RoutingKey at "far" node, appropriate instances of RoutingKey can be generated locally with a special constructor.
Security Considerations
In some cases, a leaf node will need to make requests to a remote system on which it is not authenticated. By definition, this can only happen in cases where there is no direct connection and all messages will be forwarded through the Router. In order to process requests in this case the "home" routing node (i.e. routing node to which the leaf node belongs) during processing of the first message sent to the target remote node, provides authentication information about the client to the target remote node. This authentication information is obtained from the local SecurityManager and is forwarded to the target remote node. If the remote node accepts the forwarded identity, it generates the appropriate security context for its own use (the context is used during processing of requests from the leaf node) and returns a security context identifier to the client's "home" routing node. The security context identifier is transparently inserted into messages by the "home" routing node during routing of messages between the client and the remote node. The context identifier is removed from the message (before delivery to the client) when the remote node sends reply messages to client. Handling security context identifiers in this way hides potentially sensitive security information from the client.
The routing node maintains a list of addresses of remote nodes to which each client sends requests. When a client closes its connection for any reason, routing node notifies those associated remote nodes that a particular security context identifier is no longer used and that the appropriate security context can be deleted.
As a part of the message processing, the router node may provide a firewall. The concept of a firewall is based on the idea that each incoming message should be checked against firewall rules. Each rule has a type (or action) and a boolean expression. The purpose of the expression is to check message properties and provide a boolean result: a particular message matches the rule conditions or it doesn't. If the message does not match the rule then the firewall tries the next rule or performs the default action when the list of rules is exhausted. The default action is to silently drop the message. If the message matches the rule then the firewall's resulting action depends on the rule type. The rule type may cause the firewall to silently drop the message, send an artificial reply, forward message to another destination, change message content, etc. The firewall functionality is tightly coupled with security. For this reason it closely cooperates with the SecurityManager, in particular the firewall rules and actions would be implemented as a SecurityManager plugin.
Session Startup
Before any processing can occur, one must establish a session with the
remote node. The processing that occurs is different for leaf
nodes and router nodes. Leaf nodes initiate a socket connection
to router nodes. Router nodes and servers bind to a socket to
listen for incoming connections. In this section, the terms
client and server will be used. Generally client can be
interchanged for leaf. Server can be interchanged for router.
It should be noted that the session startup or "bootstrapping" is very different depending on the node type.
Client bootstrapping has minimal runtime requirements and the data needed is primarily necessary simply to connect to the server and to properly authenticate with the security manager. Since client's can have non-interactive sessions (e.g. a batch process or remote application accessing the server's resources), there are provisions for authenticating without any interactive prompts. Such an approach relies upon encryption keys and certificates to work.
Server bootstrapping has more requirements for the runtime initialization (the DirectoryService, the SecurityManager, logging and other non-network facilities must be initialized). For this reason, there is much more information needed to bootstrap a server.
Create the Bootstrap Configuration
The BootstrapConfig is an object that stores the configuration values necessary for the startup of the runtime system and the session. This "database" is a list of values each of which is arranged with a 3-part name (category:group:key).
A properly configured instance of this class is needed to provide the session initialization with enough information to succeed. There are 2 ways to create an instance:
As an example of a minimal interactive client configuration:
BootstrapConfig bc = new BootstrapConfig();
bc.setServer(false);
bc.setConfigItem("net", "server", "port", "3333");
bc.setConfigItem("net", "server", "host", "localhost");
If one was needing a non-interactive client configuration, these are the other minimum values needed:
bc.setConfigItem("security", "keystore", "processalias", "batch_process_43");
bc.setConfigItem("security", "keystore", "filename", "custom_keystore.store");
bc.setConfigItem("access", "password", "keystore", "kjhdsa");
bc.setConfigItem("access", "password", "keyentry", "ytfryu");
These values allow the bootstrapping process to find its private key and use that to authenticate with the server. Note that the keystore file needs to be properly setup (which is beyond the scope of this document).
Implement SessionListener If Needed
SessionListener is an interface which provides session-related notifications. It is sometimes useful to hook these notifications for initialization or termination purposes.
In particular, the initialize() hook is a safe moment to export entry points because the session has not yet started but the minimum runtime environment (for entry point registration) is available. As an example, the RemoteObject.registerNetworkServer() could be safely used at that time.
An instance of the class implementing this interface must be passed to the bootstrapping process to obtain this service. Note that use of this is optional. It is perfectly valid to ignore notifications.
As an example implementation:
public void initialize()
{
MyServer myserver = new MyServer();
RemoteObject.registerNetworkServer(MyExportedInterfaceInMyServer.class, myserver);
}
public void terminate(Queue queue)
{
// clean up resources here
}
Initialize the Session
The initialization of the session is only a single method call, but it differs depending on whether a client or server session is being created.
For the client:
Queue queue = ClientBootstrap.connect(bootstrapConfig, mySessionListener);
The resulting queue object can be used to directly send messages, but of greater interest would be using it to obtain a local proxy object for a remote interface. This can be done in this way (assuming you have a remote object registered on the peer node with an interface named MyPowerfulService):
MyPowerfulService mprs = (MyPowerfulService) RemoteObject.obtainNetworkServer(MyPowerfulService.class, queue);
Then use this returned object as if it was a local object:
mprs.firstPowerfulMethodCall(parm1, parm2, parm3);
boolean success = mprs.secondPowerfulMethodCall();
Remote methods can be void or can return any serializable type (or any of the primitives). They can take any list of parameters including all primitive types. They can also throw exceptions and the client code will have to put try/catch/finally blocks in place just as if it was a local call. The calling code has no understanding that the calls are not being locally serviced.
For the server:
ServerBootstrap.bootstrap(bootstrapConfig, mySessionListener);
In this case, the method does not return until the server is terminating. This is because the thread that calls into this bootstrap method eventually enters an infinite loop where it blocks listening for inbound connections. For each new connection, it launches a new thread to authenticate and initialize that session and loops back around to wait for the next incoming session. If there is some fatal problem with the server or the server is told to terminate, this loop ends and the thread returns. At that point the server is no longer running.
This is why the bootstrap configuration of the client must contain enough information to properly identify the client and allow authentication to occur. Very little configuration is needed in the case of an interactive authentication, since there will be a prompt to the user for authentication credentials. More configuration is needed for batch processes since no interactive prompt will occur.
The SecurityManager is responsible for authentication and certificate management so setup of the TLS connection is tightly coupled with the SecurityManager.
For example, SSL socket factories and key/trust stores are setup. The security package contains all classes needed to process keystores such that SSL sockets are instantiated using protected and well known keys/certificates. As a result, on the client side a connected SSL socket is obtained. On the server side, a bound SSLServerSocket is obtained.
Before the new session can be used on the client, the security package provides methods to handle the authentication handshake with the server. The SecurityManager will own and use the SSL socket throughout the authentication process. The result is that authentication will occur before the protocol is started for a given connection. For this reason, the protocol does not have any embedded knowledge of the basic authentication process other than how to request that the security manager initiate/handle authentication. For the client, the authentication process is invoked after the SSL socket is connected but before the DAP network transport and queue implementation is instantiated.
On the server, the bootstrap process has a more substantial initialization process since features such as the directory and security manager need to be fully initialized. Once the SSLServerSocket is bound, an infinite "listener" loop is started. For each accepted incoming connection, a new thread is started which will do the following:
At this point, ClientBootstrap.connect() returns and the session is ready for use.
Terminating a Session
The protocol uses several interacting threads to accomplish
tasks.
This causes problems informing the application thread about an
exception thrown on another thread involved in processing a
request. As a result an application thread may get wrong
information
about the problem (for example, null pointer exception or timeout
exception) or would not get information about the problem at all.
In particular, an abnormal end may occur if the process at the
remote side crashed or in the case of a network failure. In
order to resolve this, any fatal failure will cause Queue.stop()
method to be invoked with the exception as a parameter. This represents the reason of
the queue shutdown. This parameter is then passed to all waiting
threads and thrown in behalf of the calling application threads.
This allows application handle this exception just like other
exceptions.
Since this approach does not inform an application which has no waiting threads inside the PWT (this is normal situation for the server application for example), a parallel mechanism is introduced. After delivering of the exception to the waiting threads the Queue.stop() method stores reference to this exception for further use. Any registered SessionListener instances will have their terminate() method called. The queue parameter to this call can be examined using getException(). If that method returns null, then this is a normal termination. If it is an exception, then that is the termination reason.
The application may stop the session intentionally at any time using Queue.stop(null).
In addition, a special case exists for complete shutdown on the server. This is a condition in which all connections must be cleanly terminated at the same time. This is accomplished via the special export Dispatcher.stop().
To take advantage of this, one must implement the StateSynchronizer interface. Then an instance of this implementation class (if it is symmetric or two classes if they are asymmetric in design) is registered on each side of the session using Queue.registerSynchronizer().
After that moment, every time any message is about to be serialized onto the socket by the protocol driver's writer thread, a call will be made to StateSynchronizer.getChanges(). This method packages all state changes up (however you like) and returns them as a single serializable object. The protocol driver "attaches" this extra hidden payload to the message and sends the entire message and piggybacked state out the socket.
On the reading side, when any message is read, any piggybacked state is detached and the protocol driver's reader thread will pass it was a parameter to the registered synchronizer's StateSynchronizer.applyChanges() method. This method handles any update to the state BEFORE the message ever gets processed. This means that any state updates are always applied in the same logical order as they would have if they were synchronously applied through remote method calls instead of being deferred and batched in this piggybacking mechanism.
In single threaded (conversation) mode, this represents a very powerful way to minimize round trips to the remote node without losing any of the value of keeping state synchronized.
Limitations:
The Control class implements a sort of "interrupt manager". It tracks the location of current processing in any single threaded environment (where the application only is active on one thread on one node at a time). This can be simulated with multi-threaded mode or it can be forced in conversation mode. Either way, the Control class is notified whenever control flow shifts from one side to the other. In particular, the Queue notifies Control before and after every synchronous message is sent. Likewise, the Dispatcher (or Conversation if single threaded mode is in use) notifies Control before and after it processes an inbound request. This means that on each side of the session, there is a Control instance that knows whether the application is processing locally or remotely.
When another thread notifies the Control instance that an interrupt has occurred, the Control object uses Thread.interrupt() on the thread that is currently processing if processing is currently local. If processing is remote, a special interrupt message is sent asynchronously and on the other side the Control instance picks up that interrupt and calls Thread.interrupt() on the remote thread.
As can be expected, there are inherent race conditions in such an implementation. Control has been written to safely and reliably handle such conditions.
This support is enabled by calling Control.init() on both sides of the session. A user defined action can be triggered in response to the interrupt notification. This interrupt handler can throw an exception in the target thread's context or otherwise respond to the interrupt.
State synchronization can be used as one way to reduce overhead.
Although this protocol benefits from the Java Serialization technology in many ways, those benefits come at a cost. Serialization is one of the most expensive parts of the overhead of each round trip. Combine this high expense with the fact that for message send the message (with payload) is serialized on node1, encrypted, transmitted, received, decrypted then deserialized on node2. This "one way" processing happens twice in each round trip. This means that objects are serialized twice and deserialized twice for every round trip. This means that another important performance improvement can be achieved by reducing the cost of serialization. This is possible by using the java.io.Externalizable interface instead of Serializable. Serializable is a super-interface of Externalizable, so an Externalizable can be used anywhere that a Serializable can be used. The difference is that the object graph being serialized is manually written to or read from the given stream. Normal techniques for doing this are over twice as efficient as the "dynamic" techniques the Serializable implementation uses to walk the object graph and flatten each object. Some of this savings comes from hard coding the flattening processing versus using reflection. Other savings comes by hard coding the order and type of what is transmitted such that less data is written. For example, serialization has to document the type and member name of each serialized object but manual use of externalizable does not require this.Exported Interface Access Control
The naming rule for the net resource forms a two-level name space. The top level name is a group name. The group names form their own flat subspace where names have to be unique. The bottom level name is a method, also known as API, name. Within group, method names form their own flat subspace, where names have to be unique. Between groups, methods may have identical names.
The external syntax for coding net resource instance names is
The protection model for the exported APIs is based on these access modes:
Thus, the access rights for the net resource are coded using one field, which is a bitfield of 4 bits: RWXN.
There is one predefined
Notes
New types of messages can be safely added since unknown types of messages can be skipped before they are ever enqueued. This is done during the initial processing of messages in the enqueueInbound() method of Queue.
Nevertheless compatibility problems are possible, because a new protocol implementation may include instances of new classes as a message payload. In this case, an old application will be unable to instantiate these new messages from the network and an exception will be thrown. It may be possible to resume work with the object stream (in the Protocol class) after such an exception but this issue requires further investigation.
Copyright (c) 2004-2010, Golden Code Development Corporation.
ALL RIGHTS RESERVED. Use is subject to license terms.
| Author(s) |
Sergey Yevtushenko, Greg Shah Nick Saxon |
| Date |
November 19, 2010 |
| Access Control |
CONFIDENTIAL |
Contents
IntroductionDesign Criteria
Messages
Network Transport
Queues
Exporting Interfaces
Remote Objects
Remote Method Call Flow
Routing and Address Space
Node Address
Address Distribution
Address Partitioning
Address Server
Virtual Session Support
Security Considerations
Session StartupAddress Distribution
Address Partitioning
Address Server
Virtual Session Support
Security Considerations
Session Authentication and Final Setup
Terminating a Session
State Synchronization Hooks
Asynchronous Session Interruption
Performance Hints
Exported Interface Access Control
Backward Compatibility
TODO List
Introduction
The Distributed Application
Protocol (DAP) is the name of the protocol provided by this package.The DAP is designed as a message passing system where messages are exchanged by nodes arranged into a logical network.
The network is comprised of leaf nodes and routing nodes. Leaf nodes are end-points in the network. They may only have a direct connection to a routing node. Routing nodes may connect to any type of node and are a superset of leaf node function with the additional ability to forward or route messages between two nodes which have no direct connection. The logical network can be arbitrarily complex by connecting routing nodes together into mesh, star, tree or other topologies. Nothing in the protocol has any knowledge or dependency upon the topology of the logical network. That is left as a runtime choice.
For the network to exist, a session must be established between two nodes (leaf <--> router or router <--> router). As more nodes establish sessions, the network grows. Messages may be passed between any two nodes that have an active session with the same logical network. A message may be directly sent (if the two nodes are directly connected) or indirectly sent (if no direct connection exists between the nodes).
Messages can contain a graph of arbitrarily complex objects as a payload. The Serializable interface is used to enable the transmission and reception of messages over a network connection.
Each end of a session has a message queue that is used to send and receive messages. Once a message is enqueued, if the caller does not require synchronous processing, the caller continues immediately without waiting for transmission. If the caller requires the semantics of a synchronous call, then that calling thread will block while the message is sent to the other side, processed there and the result is returned. Even though the protocol is based on messages and queues (an inherently asynchronous concept), at the high level interface to the caller, the mechanism naturally provides for both synchronous and asynchronous forms of processing.
Design Criteria
This protocol is designed for a wide range of Java-based distributed applications. The following are key design points:- Each communication session is a point-to-point connection-oriented link between 2 nodes.
- The underlying communication technology is a Transaction Layer Security (TLS) socket which is a standardized form of SSL 3.0. This is well supported in Java using Java Secure Socket Extensions (JSSE) in J2SE 1.4 and above.
- Both synchronous processing (e.g. a remote procedure call) and asynchronous processing (e.g. message queuing) must be possible.
- Client/Server applications must be possible. In such cases, the functionality of the system is normally quite asymmetric. A traditional client tends to be heavy on user interface and light on other functions. A traditional server is heavy on logic and data processing/access but light on user interface.
- Peer-to-Peer applications must be possible. Such cases are often symmetric in their distribution of functionality (as opposed to Client/Server applications).
- Single-threaded or "conversational" communication must be supported. In such cases, when a request is made to the remote end of the session, processing blocks on the local end, until a reply is received OR until the remote end makes a "recursive" request back to the local side. In this way, the distributed application (in this case split into 2 pieces) is single threaded in that only a single thread on only one node is active at any given moment. Control (which node is active) transfers back and forth over the session.
- Multi-threaded communication must be supported. No limits are placed on the ability to have multiple independent threads communicating in either direction and with no dependencies on other threads. All communication is safely multiplexed over the same session and can be properly associated with the threads.
- A remote object implementation must be possible.
- An arbitrarily large number of nodes must be allowed to combine as a single network, with any node having indirect access to any other node. There are 2 types of nodes: leaf and routing. Leaf nodes are those nodes that only connect to a routing node and which have no routing function themselves. A router node is any node that both connects multiple nodes AND provides routing function.
Messages
A Message is the most atomic data container that can be transferred between 2 nodes. Each message defines a request or a reply and can written to a stream and read from a stream using Serialization.Messages contain the following fields:
| type | - | defines the purpose of the message:
|
|||||||||||||||
| requestID | - | unique request identifier (only used with synchronous requests, the value is only unique for this session) | |||||||||||||||
| routing key | - | information about requested
destination node and entry point This RoutingKey class is used as a key for indexing entry points in a registry on each node (Exported Interfaces Registry or EIR). It also contains the necessary information to route a message between any 2 nodes of the same logical network, even if they do not share a direct connection. Each instance consists of the following integer fields:
|
|||||||||||||||
| payload | - |
packet payload (often used as method call parameters or
return value/exception), this is a single Serializable object (which may be an array object) The content of the payload is entirely application defined (not defined by the protocol). More specifically, the payload structure and content is specific to each unique combination of groupID and methodID from the routing key. This combination of IDs represents a unique entry point being targeted by a given message. Only that entry point can interpret the payload. While these entry points are exported via the DAP, the DAP does not implement any entry points (except for some simple housekeeping functions). The DAP has no knowledge of any payload structure or whether the payload is valid. |
Messages can be manually and dynamically created by an application. This would be required for any "low level" usage of the DAP.
The vast majority of applications use the remote object paradigm. In such cases, each side of a session has a local object upon which to make method calls. These method calls are transparently converted into the proper messages and synchronous semantics by the remote object implementation. This means that the messages and their usage are completely hidden from the high level caller of the remote object.
Network Transport
A session is comprised of two DAP nodes which have an active and direct network connection. This connection is required to be a working SSL socket. This approach ensures the privacy and integrity of all data transmitted through standards-based encryption and digital signatures.Each node can have can have more than one session active at a time. This is common for routing nodes and is even possible for leaf nodes. An example of such a use on a leaf node would be providing an infrastructure for automatic failover. No such usage is currently implemented, but it is possible.
On each side of the session, there is a protocol driver (implemented as an instance of the Protocol class). The protocol driver is just a low-level transmission worker for the socket. Protocol instances have no real idea of the packet structure being sent over the socket, it simply provides a reader thread and writer thread. Even the socket is somewhat abstracted, since it is represented as 2 streams (an ObjectInputStream and an ObjectOutputStream).
The message passing system is designed with an asynchronous approach (as is common in message passing systems). As such, the protocol does not place any synchronous requirements or constraints on the transmission of messages. This means that some temporary storage is needed to hold inbound and outbound messages. This queuing function is provided by the Queue class. There is a queue instance on each side of every session. The queue handles storage but it also provides the public interface to the session. Messages that are enqueued for outbound transmission in a given queue instance will be sent on the associated session. Messages received from that session will be enqueued in the inbound queue of the associated Queue instance.
While the session is active, the protocol driver's reader thread uses Serialization to read and restore an object from the ObjectInputStream. This object is the message that was sent from the peer end (the remote side) of the session. This message is then enqueued using Queue.enqueueInbound(). The reader then reads the next object or blocks on reading the input stream when there are no objects to read.
Likewise, the protocol driver's writer thread dequeues outbound messages using Queue.dequeueOutbound() and then uses Serialization to write the object to the ObjectOutputStream. It continues to do this while it finds outbound messages to send otherwise it blocks in dequeueOutbound().
The protocol driver is the "lower third" of the overall DAP design. This functionality is driven by the queue and is not available at the application level.
By implementing using Serialization, any Serializable object can be sent through this protocol, without unusual measures being taken. This leverages the value of the J2SE platform, without requiring the disadvantages of RMI. This does limit this implementation to supporting only Java clients and servers, although this limitation is not any significant issue for the following reasons:
- The only planned implementation for the foreseeable future is for pure Java clients and servers. Even the case where a web client (pure HTML) is provided would be done using a Java "gateway" that acts as a client to the application system while emitting pure HTML to the end node which is a web browser.
- Web Services or other protocols can be implemented in parallel
with this protocol to provide non-Java client or server access to the
system. In a Java to Java environment, it doesn't make any sense
to use
language independent protocols which are likely to be slower and more
complicated. Such protocols can be added later without any
breakage.
Queues
The queue provides a clean way of separating the high level protocol (upper third) from the low level protocol (lower third) and is a visible interface/boundary. This is important to allow the low level protocol to be swapped out without a complete rewrite. The queuing would not need to be changed even if the low level protocol is changed. This is a different and conscious choice from a monolithic approach where the queue is simply an internal mechanism in the protocol.Internally, the Queue is really made up of 3 queues and a table (or map) of waiting threads. The queues:
- Outbound Queue - this is a per-session message queue that contains messages waiting for transmission to the remote node.
- Inbound Queue - this is a per-node queue containing all incoming request messages that have a destination address which is the same as the local node address.
- Routing Queue - this is a per-node queue containing incoming messages which require forwarding (are destined for another node) OR which represent protocol level requests to be handled directly by the router (INIT_STANDARD, INIT_CONVERSATION, ADDRESS_REQUEST).
- forward() - enqueues a message as a REQUEST_ASYNCH type and then returns
- transact() - enqueues a message as a REQUEST_SYNCH type and then blocks until a matching reply arrives OR there is a timeout (whichever comes first)
In standard mode, blocking is handled by storing a descriptor in a map of waiting threads and blocking the calling thread on that descriptor (using wait()). This map is called the Pool of Waiting Threads (PWT) and it contains information about all suspended threads waiting for results from the remote side. In conversation mode, there is only a single thread that is involved so the blocking is handled without the descriptors and PWT.
Through forward() and transact(), the queue presents an upper level interface to the "middle third" of the protocol. It is the message processing kernel that glues together the upper and lower portions of DAP.
Exporting Interfaces
While the lower layers of the DAP have message passing design, to facilitate clean and simple remote objects it is necessary to create infrastructure that can hide the complexity of the message passing system behind a simple application-specific API (an API that is not specific to DAP).On any node which provides services (entry points) to the DAP network, those services must be registered such that they can be found and used. The process of registration is called "exporting".
The list of exported entry points is maintained in the Exported Interfaces Registry (EIR). Each entry point is uniquely identified by a two part name (a group name + a method name). Each group can be considered a separate API or list of entry points. Each entry point in the same group must have a unique method name.
The use of groups provides a natural separation of method namespace to reduce name conflicts. It also provides a method to organize like or related methods together into a common API. Each group consists of a set of methods. Group names must be globally unique and the names of methods within a specific group are unique but different groups may contain methods with the same names. Therefore each entry point in the EIR is only identified with a combination of two names - the group name and the method name. The separation into groups is completely logical, it does not mean that if a method belongs to some group then that method is required to be part of a particular class or Java interface.
The EIR consists of two parallel mappings:
- The method map provides
a correspondence between RoutingKeys and the associated Method
that is to be invoked as an entry point. This mapping is used
during
the dispatching of inbound messages. Each message header has a
routing key and this key is used to lookup the method object to be
invoked. The invocation mechanism is Java's reflection.
- The name registry is based on a list of group names. For each group in the list, there is a sequential list of method names that are exported as part of that group. This design provides a reliable way to dynamically generate unique IDs for each group and for each method in group. The pair of integer IDs (group ID and method ID) is directly based on indexes in the respective lists. These are used to create routing keys that identify the associated method.
Since the IDs are based on index positions in this mapping data, the IDs can be seen to be:
- Specific to only that node where the method is registered. In other words, the same integer IDs on different nodes can refer to different APIs.
- Dynamically created at the moment a new entry point is registered.
RoutingKey generateRoutingKey(String group, String method)
Using this routing key, one may export a new entry point. To do this, use the following Dispatcher methods:
void addMethod(RoutingKey, Object obj, Method method)
void addMethod(RoutingKey, Object obj, Class[] signature, Class class)
void addMethod(RoutingKey, Object obj, Class[] signature, String fullyQualifiedClassName)
Lookups in Method Map are described in message processing: the RoutingKey from each message is used as a key to lookup the target MethodEntry in the Method Map.
Certain "special" entry points are always present in the method map:
- Dispatcher.getRoutingKey()
- Dispatcher.stop()
- Dispatcher.interruptSession()
- Optionally (these are needed to secure remote access to nodes in a routed environment):
- Dispatcher.authenticateRemote()
- Dispatcher.terminateSession()
All exported entry points are exported for the entire node, they are not registered per-connection. In other words, the EIR is a node-wide resource rather than a per-session resource.
It is very important to note that both leaf nodes and routing nodes can export interfaces. The protocol is completely symmetric in this regard. Providing a service layer on any node is necessary for many kinds of applications such as peer-to-peer, though traditional client/server can also be supported easily.
Remote Objects
The high level parts of the protocol (the "upper third") are designed to provide the simplicity of using objects as local resources but having those method calls transparently converted into synchronous calls or for sending asynchronous messages to the remote side of the connection. It is comprised of the following components:- RemoteObject instances - these can be considered the local object against which an application will be built. In other words, these are the "service requester" portion of the protocol. They create messages based on a specific method call and enqueue such messages via the proper synchronous or asynchronous interface in the Queue.
- Dispatcher - this can be the "service" side of the protocol in multi-threaded mode, it reads the Inbound queue for all request messages (synchronous or asynchronous) and converts these into a local call to a specific Object and method as defined in a registry (see EIR). If this is a synchronous call, any return results are sent back to the caller in a REPLY or REPLY_EXCEPTION message.
- Conversation - this is a dedicated thread for message processing when using single-threaded or conversation mode. All synchronous messages (REQUEST_SYNCH, REPLY orREPLY_EXCEPTION) are handled by this class.
- Exported Interfaces Registry (EIR) - maintains the information necessary for the dispatcher to identify and call a specific method in response to an inbound request. For each entry point the following information is stored: reference to instance of java.lang.reflect.Method, optional reference to object instance (if method is not static).
- If this is the first call to this entry point (during this session), a synchronous transaction (using the well known routing key for Dispatcher.getRoutingKey()) is executed with the remote node to lookup the addressing information (the RoutingKey) necessary to identify the matching method call on the remote node. This routing key also will have the destination node address set.
- Any parameters are marshaled and added to the Message as the payload. The payload can be a single Object or an array of Objects. As long as the payload is Serializable, it can be sent in a message. If there are multiple parameters, an Object[] will be used. The key point here is that all parameters must be Serializable and the order of the parameters MUST exactly match the signature (data types and order) of the remote method being called.
- The message is enqueued using the synchronous interface Queue.transact(). At this time, all APIs are synchronous. No use of Queue.forward() is made.
- The Queue object handles the blocking semantics to force the calling thread to wait until the matching reply is received. The Queue manages this using an integer request ID that is unique (within this session) to this request. In particular, Queue.transact() will generate a descriptor that uniquely identifies the matching response and then it inserts this descriptor into the map of waiting threads and blocks the calling thread on that descriptor.
- If the timeout is reached without a matching reply being received, then an exception is thrown.
- If the session is terminated before a matching reply is received, then an exception is thrown.
- Otherwise, when the matching transaction reply is received (a REPLY or REPLY_EXCEPTION message with the same request ID), then the waiting thread is released.
- This thread examines the reply message. If the payload is an exception, this exception is thrown. Otherwise the payload is returned as an Object.
One can build custom objects and/or alternatives to the provided RemoteObject implementation. In particular, if a higher level asynchronous interface was needed, RemoteObject does not support such a construct at this time. All APIs provided by RemoteObject are synchronous method calls.
The interesting part about the RemoteObject implementation is that it makes it as easy to export an interface as it does to call that interface remotely. Assume that one has a service named "Foo" to export. The API for this service would be defined by a Java Interface named Foo (it could be named anything). Then on the node on which Foo is to be exported:
RemoteObject.registerNetworkServer(Class[] iface, Object impl)
RemoteObject.registerStaticNetworkServer(Class[] iface, Class impl)
In both cases, the list of interface classes define the full set of exported methods (everything that is public, which in an interface is everything). In the case of a static server, the given implementation class is searched for static versions of every method in the list of interfaces. There is no such thing as a "static interface" in Java but this export process behaves as if this were the case. In the case of the non-static server, the given implementation object must actually implement all interfaces in the list. Either way, the java.lang.reflect.Method objects for each exported API are gathered and for each one a routing key is generated and the method is registered for export. At that point, the exported interfaces may be called.
No matter how many sessions exist on this node, the above registration code is enough to export the APIs for the entire node. This is because the EIR is a per-node resource, not a per-session resource.
On the remote node, to obtain a local object that represents the remote service, one uses the following:
Object RemoteObject.obtainNetworkServer(Class iface, Queue queue, int timeout)
The returned object will implement the given interface and will be a local representation of the remote service on the peer end of the given queue. Convenience forms of this are available to use the default queue for the current session. Just cast the returned object to the interface and then make method calls. Everything else is transparently handled by the RemoteObject implementation.
Remote Method Call Flow
In all the following discussion, there is no requirement that the direction of the call be from client to server or from leaf node to routing node as the protocol is designed to be completely symmetric.Standard Mode
The following diagram shows the high level flow of a synchronous call between two nodes (in multi-threaded mode).
The sequence starts with a Java application on system 1. This application has previously established a session and obtained a RemoteObject which represents an exported interface on the remote node. The application calls someExampleExportedMethod() on that RemoteObject.
The RemoteObject obtains the routing key associated with the someExampleExportedMethod() on the remote node. It then creates a Message with the method parameters marshaled as the payload.
The message is then sent using Queue.transact() method. Inside the queue, a unique requestID is generated and assigned to the message. Then the message is placed into the outbound queue. A new WaitingThread instance is created. Then waitingThread is registered in the PWT using the requestID assigned to the message as a key and the calling thread is suspended by calling the waitingThread.wait() method.
The protocol driver's writer thread retrieves the message from the outbound queue and serializes it onto the stream (an instance of ObjectOutputStream created from the Socket at startup) by calling the stream.writeObject() method.
At the remote side, the protocol driver reader thread restores the message from the stream (an instance of ObjectInputStream created from the Socket at startup) by calling the stream.readObject() method. Then it passes the message to the queue using the queue.enqueueInbound() method. The message is placed into the inbound queue.
A thread from the Dispatcher thread pool retrieves the inboundRequest from the inbound queue using queue.dequeueInbound() method and processes it. Processing includes the following steps:
- Set the security context. If incoming request is from directly connected node (this can be decided by comparing source address from the message and remote node address from the queue which received the message) then set security context which is assigned to the queue. If incoming request is from "far" node then find security context in the Dispatcher's context map using security context ID from the message.
- Using the routing key from the message, locate the instance of the exported method in the Exported Interfaces Registry.
- Using the obtained java.lang.reflect.Method instance call Method.invoke(). Use any registered object instance (from the EIR) and the parameters (from the message payload) to make the invocation.
- When that call returns, store the returned value (if any) or generated exception (if any) in a REPLY or REPLY_EXCEPTION message as the payload.
- Copy requestID from the source message to the new one. Place the reply message into the outbound queue using the queue.enqueuOutbound() method.
- Drop the current user's security context and restore the original context.
- Try to dequeue the next message from the inbound queue (this is an infinite loop).
The protocol driver reader thread restores the message from the stream (an instance of ObjectInputStream created from the Socket at startup) by calling the stream.readObject() method. Then it passes the message to the queue using queue.enqueueInbound() method. This is a reply message so it is processed as follows:
- The WaitingThread instance is located in the PWT using the requestID from the message as a key.
- Message is assigned to the appropriate field of waitingThread.
- The suspended thread is resumed by calling the waitingThread.notify() method.
- When the thread resumes work in Queue.transact(), it reads the return value (or exception) from the message payload and returns this (or throws an exception).
- The RemoteObject method returns this value (unless an exception is thrown at step 4) to the application.
If the Message is a synchronous request, then any returned data from the called method is packaged into a REPLY or REPLY_EXCEPTION message and is enqueued on the correct queue for transmission. The thread then drops its security context (if this is a server system) and tries to read the next incoming message. If there are no messages to read, the thread blocks on reading the incoming queue. Note that the incoming queue in every Queue object is actually a singleton object which allows the Dispatcher to greatly simplify its processing since it only needs to monitor a single incoming queue for all request messages. When it dequeues a message it has access to the Queue reference of the node that originated the message, which is needed to allow the SecurityManager to set its security context AND for the knowledge of where to enqueue any responses.
Since each thread processing a request on a server has its security context set to that of the calling user or process, all security decisions for any resource accessed by that thread can be made in a very natural way since that thread is now the proxy for that user or remote process.
Any response messages that are sent back eventually enter the Queue through the enqueueInbound() method. In multi-threaded mode, this method identifies REPLY and REPLY_EXCEPTION messages and finds the matching descriptor in the waiting threads map. It then stores a reference to the returned data or exception and unblocks the thread (using notify()). The calling thread obtains the return data and returns this to the RemoteObject caller as if the entire transaction had been local. In conversation mode, the reply is posted to the Conversation thread, unblocking that thread and allowing it to return the result naturally (as part of the call stack).
Conversation Mode
The following diagram shows the high level flow of a synchronous call between two nodes (in single-threaded mode).
In single-threaded (conversation) mode, both sides have a Conversation object that handles all synchronous messages for the session.
In this mode, any asynchronous messages are still handled by the Dispatcher (see above). The Conversation has a thread that is dedicated to processing all messages for the associated session. The thread has a permanent security context assigned so it does not need to set or drop context for each message as does the normal Dispatcher processing. Other than this, incoming synchronous messages are handled by the Conversation object, exactly as described for the Dispatcher. This thread is also responsible for waiting on responses to synchronous requests that where sent out by this node to the remote node. This is quite different from the Dispatcher approach since in the Dispatcher, only incoming requests are handled.
The conversation mode is useful because it does not require any resources from the Dispatcher's thread pool. The thread pool is a static resource created at startup and then never changed. The Conversation thread, in contrast, is created when a session is initialized and it is dedicated to only that session's processing. When that session terminates, the Conversation thread also terminates. This allows for a dynamic allocation of just those resources needed. When sessions are long-running entities, this approach makes sense.
In any design which is inherently single threaded, the conversation mode is especially valuable. This is because the multi-threaded mode can easily handle the semantics of a single-threaded model BUT it handles nested calls in a manner that is wasteful of resources. Consider the case where node1 calls node2, then node2 (before returning from node1's request) has a nested call back to the node 1. In the multi-threaded model, node1 will have 1 blocked thread waiting on the original request and 1 active thread executing the nested call from node2. node2 has a single thread blocked waiting on the nested call to node2. So for each level of nesting N, multi-threaded mode will require N+1 threads to process BUT ONLY ONE OF THESE THREADS IS ACTIVE AT ANY MOMENT ANYWAY! Conversation mode solves this nesting problem by simply having only a single thread on each side. This works as long as the processing is truly single threaded. If that is not a valid assumption, then conversation mode cannot be used.
Routing and Address Space
In order to support building of the large distributed data processing
systems, the protocol provides a message routing facility.
Message
routing allows delivering of the messages between nodes in the
situations
where nodes have no direct connection.The routing mechanism is built with two levels. The first layer consists of leaf nodes (clients and servers) which actually process data. The second layer consists of routing nodes or routers. Routers can establish and drop connections to other routers as necessary, routes messages and handle other related tasks.
It should be noted that this layering is a logical architecture. A server which is a leaf node can (and usually does) support the functionality of both layers (i.e. leaf and routing nodes). Each leaf node can have connections to one or more routing node(s). If more that one connection to a router is present then the leaf node can perform load balancing and failover and use some algorithm to choose the router to which a message will be sent for delivery. A leaf node can connect only to routing nodes, it does not connect to other leaf nodes directly.
Provisions have been made to allow an arbitrarily complex distributed system. This is enabled by the concept of addressing and routing. A Router processes messages stored in the Routing Queue, handles them or forwards them to remote nodes. The routing queue is the 3rd queue in every Queue object and is also a singleton queue. This allows the Router to read from a single queue that is fed from multiple connections. The Router handles all aspects of the address space partitioning/distribution, name lookups, firewall support, remote access enablement (remote authentication) and of course the actual forwarding of messages between nodes.
The following diagram shows a simplified view of a node with a Router:
The blue arrows show inbound flows and the green arrows show outbound flows.
Node Address
Each node (regardless of the layer) has a node address. One system may have more than one node address. For example, if a leaf node has connections to more than one routing node, each routing node assigns a unique address to the leaf node. In order to deliver messages and replies, the router requires information about source and destination node addresses. This information is stored in the RoutingKey which is part of each message.
Address Distribution
Each routing node has a set of addresses which belong to that routing node. In that address space, the first address is assigned to the routing node itself and the last address is a special broadcast address. A Message sent to the broadcast address is delivered to all leaf nodes connected to the routing node. It is not delivered to other routing nodes that are connected. The Routing node assigns an address from its address space to each client which connects. When the connection is closed, the address is released and can be assigned to another leaf node.
When two nodes establish a connection they exchange address information. For this purpose the node which establishes the connection sends an INIT_STANDARD message (to request a multi-threaded mode session) or INIT_CONVERSATION message (to request a conversation or single-threaded mode session). If the node that initiates the connection is a routing node, this message contains the router's address. If the connecting node is a leaf node, no address is sent to the routing node since at connection the leaf node has no address assigned. This tells router that it must assign an address to the client. When routing node connects other routing node, it already has an assigned address, so it just informs remote node about its address. Presence of the address in the INIT_STANDARD or INIT_CONVERSATION message from a routing node informs the remote node that an address is already assigned and there is no need to allocate one from the routers' address space. A leaf node may neither request nor require a particular address using this facility. Any address specified in this message by a leaf node will be ignored.
Address Partitioning
Taking into account that the routing mechanism has exactly two layers and in order to simplify address space management, each node address consists of two logical parts: the high bits of the address represent the address of the routing node to which a particular address belongs while the low bits represent the specific address in the routing node's address space. An address with low bits set to 0 is assigned to the routing node itself and the address with all low bits set to 1 represents the broadcast address. The broadcast address is used to send s message to all nodes connected to a particular routing node.
For example:
If the node address contains 32 bits and the address is split into two parts with 16 bits each, then the system can have up to 65536 routing nodes and each routing node can have up to 65534 clients (two addresses are dedicated for the routing node address and the broadcast address). Each routing node in this case has an address like 0x00010000, 0x00020000, etc. The broadcast address which belongs to these nodes will be 0x0001FFFF, 0x0002FFFF, etc. Clients of the routing node 0x00010000 will get addresses in the range 0x00010001-0x0001FFFE.
This approach simplifies address maintenance because the node address also encodes the router's node address, the broadcast address, the range of addresses assigned to the routing node and even the node type.
Address Server
In addition to leaf and routing nodes, an important part of the routing mechanism is the address server. The purpose of the address server is to hold and process address information. All routing nodes use the address server to request information about other routing nodes, to translate node addresses into names and vice versa, etc. A particular implementation can have a real or virtual address server. If the address server is virtual, it is most likely that the Router implementation provides the address server functionality as well.
The address server represents a centralized approach to the maintenance and access of routing tables. This makes it unnecessary to dynamically exchange routing tables between routers at runtime. This is a great simplification to the protocol.
At this time, the design of this centralized registry is not complete nor is there more than a cursory interface implemented.
Virtual Session Support
In order to communicate with "far" nodes (i.e. nodes which do not belong to the local router's address space) the router supports a Remote Node Registry. This registry contains a list of all local queues (connected leaf nodes) which have sent at least one request message to "far" nodes. For each such session, the router maintains a list of addresses of "far" nodes and the security context ID for each address. The security context ID is used to help the "far" node maintain its associated security context during the processing of request messages. Since there is no direct connection between a "far" node and the node which sends a request message, it is impossible to perform direct authentication (and therefore create a security context) and drop security context when connection is closed. In order to resolve this problem the following mechanism is introduced:
When a client sends it's first message to a "far" node, the router finds that there is no appropriate record in the Remote Node Registry. Then it performs the following steps:
- Retrieve identity information from the SecurityManager using the queue from which message arrived as a key.
- Transact a call to following exported method at "far" node:
int authenticateRemote(String identity);
Result of the call is a security context ID. - Appropriate entry in the Remote Node Registry is filled and security context ID in the RoutingKey is filled in the original message. The entry contains the address of the "far" node and the assigned security context ID. When the queue is placed in the Remote Node Registry the first time, the Router adds itself to the list of SessionListeners in the queue.
void terminateSession(int ID);
The security context ID entry points mentioned above are implemented by the Dispatcher class and must be exported by all nodes which support processing of "far" requests (such nodes MUST have a security manager). In order to access these entry points there is no need to request RoutingKey at "far" node, appropriate instances of RoutingKey can be generated locally with a special constructor.
Security Considerations
In some cases, a leaf node will need to make requests to a remote system on which it is not authenticated. By definition, this can only happen in cases where there is no direct connection and all messages will be forwarded through the Router. In order to process requests in this case the "home" routing node (i.e. routing node to which the leaf node belongs) during processing of the first message sent to the target remote node, provides authentication information about the client to the target remote node. This authentication information is obtained from the local SecurityManager and is forwarded to the target remote node. If the remote node accepts the forwarded identity, it generates the appropriate security context for its own use (the context is used during processing of requests from the leaf node) and returns a security context identifier to the client's "home" routing node. The security context identifier is transparently inserted into messages by the "home" routing node during routing of messages between the client and the remote node. The context identifier is removed from the message (before delivery to the client) when the remote node sends reply messages to client. Handling security context identifiers in this way hides potentially sensitive security information from the client.
The routing node maintains a list of addresses of remote nodes to which each client sends requests. When a client closes its connection for any reason, routing node notifies those associated remote nodes that a particular security context identifier is no longer used and that the appropriate security context can be deleted.
As a part of the message processing, the router node may provide a firewall. The concept of a firewall is based on the idea that each incoming message should be checked against firewall rules. Each rule has a type (or action) and a boolean expression. The purpose of the expression is to check message properties and provide a boolean result: a particular message matches the rule conditions or it doesn't. If the message does not match the rule then the firewall tries the next rule or performs the default action when the list of rules is exhausted. The default action is to silently drop the message. If the message matches the rule then the firewall's resulting action depends on the rule type. The rule type may cause the firewall to silently drop the message, send an artificial reply, forward message to another destination, change message content, etc. The firewall functionality is tightly coupled with security. For this reason it closely cooperates with the SecurityManager, in particular the firewall rules and actions would be implemented as a SecurityManager plugin.
Session Startup
Before any processing can occur, one must establish a session with the
remote node. The processing that occurs is different for leaf
nodes and router nodes. Leaf nodes initiate a socket connection
to router nodes. Router nodes and servers bind to a socket to
listen for incoming connections. In this section, the terms
client and server will be used. Generally client can be
interchanged for leaf. Server can be interchanged for router.It should be noted that the session startup or "bootstrapping" is very different depending on the node type.
Client bootstrapping has minimal runtime requirements and the data needed is primarily necessary simply to connect to the server and to properly authenticate with the security manager. Since client's can have non-interactive sessions (e.g. a batch process or remote application accessing the server's resources), there are provisions for authenticating without any interactive prompts. Such an approach relies upon encryption keys and certificates to work.
Server bootstrapping has more requirements for the runtime initialization (the DirectoryService, the SecurityManager, logging and other non-network facilities must be initialized). For this reason, there is much more information needed to bootstrap a server.
Create the Bootstrap Configuration
The BootstrapConfig is an object that stores the configuration values necessary for the startup of the runtime system and the session. This "database" is a list of values each of which is arranged with a 3-part name (category:group:key).
A properly configured instance of this class is needed to provide the session initialization with enough information to succeed. There are 2 ways to create an instance:
- By passing a properly encoded bootstrap configuration file to the constructor. This file is parsed and the database is initialized from that file.
- By constructing an empty in-memory instance and then programmatically setting the values needed.
| Category | Group | Key | Default Value | Example Value | Type | Required on Server | Required on Client | Purpose |
| net | server | port | -1 | 3333 | int | yes | yes | The TCP port on which the server will listen or which the client will use to contact the server. |
| net | server | host | null | localhost | string | n/a | yes | Specifies the hostname or IP address on which the server resides. |
| net | server | timeout | 600000 | 30000 | int | no | no | The number of milliseconds that a sender of the an initialization request will wait for the associated reply. |
| net | server | nodeAddr | 0x00010000 | 65536 | int | no | n/a | The DAP node address of a router node. All leaf nodes connected to this node will have addresses assigned from the low word while the high word will be identical. |
| net | dispatcher | threads | 2 | 10 | int | no | no | The size of the dispatcher's thread pool. |
| net | router | threads | 2 | 2 | int | no | n/a | The size of the router's thread pool. |
| net | queue | conversation | false | true | boolean | n/a | no | Enable/disable conversation mode for the associated client. Note that the server's session is automatically configured based on the mode of the client. |
| net | queue | start_thread | false | true | boolean | n/a | no | If true, a daemon thread will be started to drive conversation mode. If conversation mode is disabled, this value is ignored. |
| security | server | id | null | server1 | string | yes | n/a | This is the server's name, used to find the associated configuration for that server in the directory. |
| security | certificate | validate | false | true | boolean | n/a | no | If true, then the server's certificate must be present in the truststore for authentication to succeed. This is a way of authenticating the server. |
| security | truststore | alias | null | server1 | string | no | no | Used
when security:certificate:validate is true to
identify the certificate in the truststore to be used for
validation. Used on the client and on the server only during the
creation of a virtual session (in which case the server acts like a
client). |
| security | keystore | alias | null | server1 | string | no | n/a | Required to find the server's private key if there are multiple aliases in the keystore. |
| security | keystore | useralias | null | client1 | string | n/a | no | Required to find the client's private key if there are multiple aliases in the keystore. This should not be specified if a processalias has been specified. It should only be used for interactive clients. |
| security | keystore | processalias | null | batch_process_1 | string | n/a | no | Used to enable process (non-interactive) authentication
instead of the normal interactive authentication. If this value
is non-null, then a non-interactive authentication type is used. In addition, the SecurityManager uses this to find the client's private key if there are multiple aliases in the keystore. |
| security | keystore | filename | null | custom_keys.store | string | yes | no | Specifies the filename or URL from which a custom keystore can be read. |
| security | truststore | filename | null | custom_trust.store | string | n/a | no | Specifies the custom trust store for the client to use for validation of server certificates. Note that the server dynamically builds a truststore from the directory so this is not needed for servers. |
| access | password | keystore | null | kjhdsa | string | no | no | Specifies the password to be used to read/decrypt the custom keystore. |
| access | password | keyentry | null | ytfryu | string | no | no | Specifies the password to be used to read/decrypt the in-memory key manager. |
| access | password | truststore | null | ohjuou | string | n/a | no | Specifies
the password to be used to read/decrypt the custom truststore
(file). Since the server doesn't use a file-based trust-store,
this is not needed and will not be used on the server. |
| access | password | user | null | asjakkl | string | n/a | no | If the standard SecurityManager client authentication hook is used, this will override the password instead of forcing the user to be prompted via stdin. |
| access | subject | id | null | user1 | string | n/a | no | If the standard SecurityManager client authentication hook is used, this will override the userid instead of forcing the user to be prompted via stdin. |
| directory | backend | type | null | xml | string | yes | n/a | Specifies either of the 2 back-end types that are available in the directory package: xml or ldap. |
| directory | backend | class | null | com.acme.directory.MyBackEnd | string | no | n/a | Specifies the class name of the directory back-end to use. This class must implement the Remapper interface. |
| directory | xml | filename | null | directory.xml | string | no | n/a | Required if using the XML back-end. Defines the xml file that provides persistent storage for the directory. |
| directory | ldap | mapping | null | string | no | n/a | Required if the LDAP back-end is in use. | |
| directory | ldap | mode | null | file | string | no | n/a | Required if the LDAP back-end is in use. Must be one of these mapping modes: FILE, URL, ATTRIBUTE, SUBTREE. |
| directory | ldap | url | null | string | no | n/a | Required if the LDAP back-end is in use. Defines the LDAP provider's URL. |
|
| directory | ldap | auth | null | string | no | n/a | LDAP security authentication. | |
| directory | ldap | principal | null | string | no | n/a | LDAP security principal. | |
| directory | ldap | credentials | null | string | no | n/a | LDAP security credentials. | |
| directory | ldap | keystore | null | string | no | n/a | Required if using the LDAP back-end AND LDAPS (TLS transport for LDAP). | |
| directory | ldap | truststore | null | string | no | n/a | Required if using the LDAP back-end AND LDAPS (TLS transport for LDAP). | |
| directory | ldap | keypasswd | null | string | no | n/a | Required if using the LDAP back-end AND LDAPS (TLS transport for LDAP). | |
| directory | ldap | trustpasswd | null | string | no | n/a | Required if using the LDAP back-end AND LDAPS (TLS transport for LDAP). | |
| directory | ldap | alias | null | string | no | n/a | Required if using the LDAP back-end AND LDAPS (TLS transport for LDAP). | |
| directory | ldap | aliaspasswd | null | string | no | n/a | Required if using the LDAP back-end AND LDAPS (TLS transport for LDAP). |
As an example of a minimal interactive client configuration:
BootstrapConfig bc = new BootstrapConfig();
bc.setServer(false);
bc.setConfigItem("net", "server", "port", "3333");
bc.setConfigItem("net", "server", "host", "localhost");
If one was needing a non-interactive client configuration, these are the other minimum values needed:
bc.setConfigItem("security", "keystore", "processalias", "batch_process_43");
bc.setConfigItem("security", "keystore", "filename", "custom_keystore.store");
bc.setConfigItem("access", "password", "keystore", "kjhdsa");
bc.setConfigItem("access", "password", "keyentry", "ytfryu");
These values allow the bootstrapping process to find its private key and use that to authenticate with the server. Note that the keystore file needs to be properly setup (which is beyond the scope of this document).
Implement SessionListener If Needed
SessionListener is an interface which provides session-related notifications. It is sometimes useful to hook these notifications for initialization or termination purposes.
In particular, the initialize() hook is a safe moment to export entry points because the session has not yet started but the minimum runtime environment (for entry point registration) is available. As an example, the RemoteObject.registerNetworkServer() could be safely used at that time.
An instance of the class implementing this interface must be passed to the bootstrapping process to obtain this service. Note that use of this is optional. It is perfectly valid to ignore notifications.
As an example implementation:
public void initialize()
{
MyServer myserver = new MyServer();
RemoteObject.registerNetworkServer(MyExportedInterfaceInMyServer.class, myserver);
}
public void terminate(Queue queue)
{
// clean up resources here
}
Initialize the Session
The initialization of the session is only a single method call, but it differs depending on whether a client or server session is being created.
For the client:
Queue queue = ClientBootstrap.connect(bootstrapConfig, mySessionListener);
The resulting queue object can be used to directly send messages, but of greater interest would be using it to obtain a local proxy object for a remote interface. This can be done in this way (assuming you have a remote object registered on the peer node with an interface named MyPowerfulService):
MyPowerfulService mprs = (MyPowerfulService) RemoteObject.obtainNetworkServer(MyPowerfulService.class, queue);
Then use this returned object as if it was a local object:
mprs.firstPowerfulMethodCall(parm1, parm2, parm3);
boolean success = mprs.secondPowerfulMethodCall();
Remote methods can be void or can return any serializable type (or any of the primitives). They can take any list of parameters including all primitive types. They can also throw exceptions and the client code will have to put try/catch/finally blocks in place just as if it was a local call. The calling code has no understanding that the calls are not being locally serviced.
For the server:
ServerBootstrap.bootstrap(bootstrapConfig, mySessionListener);
In this case, the method does not return until the server is terminating. This is because the thread that calls into this bootstrap method eventually enters an infinite loop where it blocks listening for inbound connections. For each new connection, it launches a new thread to authenticate and initialize that session and loops back around to wait for the next incoming session. If there is some fatal problem with the server or the server is told to terminate, this loop ends and the thread returns. At that point the server is no longer running.
Session Authentication and Final Setup
In both the client and server session startup cases, each new session will be authenticated using the SecurityManager before allowing the session to be used. In addition, all of the authentication processing is hidden inside the call to ClientBootstrap.connect() or ServerBootstrap.bootstrap() respectively.This is why the bootstrap configuration of the client must contain enough information to properly identify the client and allow authentication to occur. Very little configuration is needed in the case of an interactive authentication, since there will be a prompt to the user for authentication credentials. More configuration is needed for batch processes since no interactive prompt will occur.
The SecurityManager is responsible for authentication and certificate management so setup of the TLS connection is tightly coupled with the SecurityManager.
For example, SSL socket factories and key/trust stores are setup. The security package contains all classes needed to process keystores such that SSL sockets are instantiated using protected and well known keys/certificates. As a result, on the client side a connected SSL socket is obtained. On the server side, a bound SSLServerSocket is obtained.
Before the new session can be used on the client, the security package provides methods to handle the authentication handshake with the server. The SecurityManager will own and use the SSL socket throughout the authentication process. The result is that authentication will occur before the protocol is started for a given connection. For this reason, the protocol does not have any embedded knowledge of the basic authentication process other than how to request that the security manager initiate/handle authentication. For the client, the authentication process is invoked after the SSL socket is connected but before the DAP network transport and queue implementation is instantiated.
On the server, the bootstrap process has a more substantial initialization process since features such as the directory and security manager need to be fully initialized. Once the SSLServerSocket is bound, an infinite "listener" loop is started. For each accepted incoming connection, a new thread is started which will do the following:
- Authenticate client by calling SecurityManager.authenticateLocal(SSLSocket) method. This interacts with the client's authentication processing (the ClientBoostrap.connect() method calls SecurityManager.authenticateClient(SSLSocket)). Cooperatively, they handle interactive or non-interactive authentication.
- If authentication fails for any reason, both sides throw exceptions and abort.
- If authentication succeeds, on the server a unique security context is obtained.
- Create a new Queue object using client connection socket.
- Assign server node address as queue local address.
- Associate the security context with this queue.
- The Queue is then started and this initializer thread exits.
At this point, ClientBootstrap.connect() returns and the session is ready for use.
Terminating a Session
The protocol uses several interacting threads to accomplish
tasks.
This causes problems informing the application thread about an
exception thrown on another thread involved in processing a
request. As a result an application thread may get wrong
information
about the problem (for example, null pointer exception or timeout
exception) or would not get information about the problem at all.
In particular, an abnormal end may occur if the process at the
remote side crashed or in the case of a network failure. In
order to resolve this, any fatal failure will cause Queue.stop()
method to be invoked with the exception as a parameter. This represents the reason of
the queue shutdown. This parameter is then passed to all waiting
threads and thrown in behalf of the calling application threads.
This allows application handle this exception just like other
exceptions. Since this approach does not inform an application which has no waiting threads inside the PWT (this is normal situation for the server application for example), a parallel mechanism is introduced. After delivering of the exception to the waiting threads the Queue.stop() method stores reference to this exception for further use. Any registered SessionListener instances will have their terminate() method called. The queue parameter to this call can be examined using getException(). If that method returns null, then this is a normal termination. If it is an exception, then that is the termination reason.
The application may stop the session intentionally at any time using Queue.stop(null).
In addition, a special case exists for complete shutdown on the server. This is a condition in which all connections must be cleanly terminated at the same time. This is accomplished via the special export Dispatcher.stop().
State Synchronization Hooks
DAP provides hooks for objects which manage incremental and bidirectional synchronization of state between two sides of a DAP session. This is useful to avoid "notification" trips which maintain state synchronously on the other side of the connection but which doesn't need to trigger any actual processing that has end-user impact. In other words, if the state change can be deferred until the next time a real trip is needed to the other side of the connection, then the state changes can be "batched" up and "piggybacked" on the next real message. This can have large performance advantages in cases where the notification trips are frequent (e.g. possibly because they are done in tight loops) but where the real worker trips are infrequent.To take advantage of this, one must implement the StateSynchronizer interface. Then an instance of this implementation class (if it is symmetric or two classes if they are asymmetric in design) is registered on each side of the session using Queue.registerSynchronizer().
After that moment, every time any message is about to be serialized onto the socket by the protocol driver's writer thread, a call will be made to StateSynchronizer.getChanges(). This method packages all state changes up (however you like) and returns them as a single serializable object. The protocol driver "attaches" this extra hidden payload to the message and sends the entire message and piggybacked state out the socket.
On the reading side, when any message is read, any piggybacked state is detached and the protocol driver's reader thread will pass it was a parameter to the registered synchronizer's StateSynchronizer.applyChanges() method. This method handles any update to the state BEFORE the message ever gets processed. This means that any state updates are always applied in the same logical order as they would have if they were synchronously applied through remote method calls instead of being deferred and batched in this piggybacking mechanism.
In single threaded (conversation) mode, this represents a very powerful way to minimize round trips to the remote node without losing any of the value of keeping state synchronized.
Limitations:
- Only one state synchronizer may be registered with the session at a time.
- The state synchronizer on each side of the session must be compatible. This compatibility is provided by being able to produce (getChanges()) and consume (applyChanges()) a common Serializable object. This object must be a shared definition between the two instances.
Asynchronous Session Interruption
Some applications have the need to honor an asynchronous interrupt request. One example is an interactive application which allows the user to press a key combination (e.g. CTRL-C) to abort any current work. Implementing this interruption when processing is local to the event source is not too hard. Implementing this when the current processing is remote, is quite difficult.The Control class implements a sort of "interrupt manager". It tracks the location of current processing in any single threaded environment (where the application only is active on one thread on one node at a time). This can be simulated with multi-threaded mode or it can be forced in conversation mode. Either way, the Control class is notified whenever control flow shifts from one side to the other. In particular, the Queue notifies Control before and after every synchronous message is sent. Likewise, the Dispatcher (or Conversation if single threaded mode is in use) notifies Control before and after it processes an inbound request. This means that on each side of the session, there is a Control instance that knows whether the application is processing locally or remotely.
When another thread notifies the Control instance that an interrupt has occurred, the Control object uses Thread.interrupt() on the thread that is currently processing if processing is currently local. If processing is remote, a special interrupt message is sent asynchronously and on the other side the Control instance picks up that interrupt and calls Thread.interrupt() on the remote thread.
As can be expected, there are inherent race conditions in such an implementation. Control has been written to safely and reliably handle such conditions.
This support is enabled by calling Control.init() on both sides of the session. A user defined action can be triggered in response to the interrupt notification. This interrupt handler can throw an exception in the target thread's context or otherwise respond to the interrupt.
Performance Hints
The protocol has been found to scale well with larger message sizes. This means that the total round trip time for very small messages (a few bytes of payload) is very close to that of quite large messages. While the results may vary, on older hardware it has been found that until message payloads get into the 32KB range, the increase in round trip time is negligible. Associated with this finding is the fact that even a single round trip over the transport and back has a certain amount of overhead that is costly enough to be a non-zero value. The implication of this finding is that batching up data and minimizing the number of round trips is an effective way to improve performance. So it is important to design remote interfaces to be less "chatty" and to pass more data in a single payload.State synchronization can be used as one way to reduce overhead.
Although this protocol benefits from the Java Serialization technology in many ways, those benefits come at a cost. Serialization is one of the most expensive parts of the overhead of each round trip. Combine this high expense with the fact that for message send the message (with payload) is serialized on node1, encrypted, transmitted, received, decrypted then deserialized on node2. This "one way" processing happens twice in each round trip. This means that objects are serialized twice and deserialized twice for every round trip. This means that another important performance improvement can be achieved by reducing the cost of serialization. This is possible by using the java.io.Externalizable interface instead of Serializable. Serializable is a super-interface of Externalizable, so an Externalizable can be used anywhere that a Serializable can be used. The difference is that the object graph being serialized is manually written to or read from the given stream. Normal techniques for doing this are over twice as efficient as the "dynamic" techniques the Serializable implementation uses to walk the object graph and flatten each object. Some of this savings comes from hard coding the flattening processing versus using reflection. Other savings comes by hard coding the order and type of what is transmitted such that less data is written. For example, serialization has to document the type and member name of each serialized object but manual use of externalizable does not require this.
Exported Interface Access Control
NetResource class implements a plugin that controls the
"net" resource. The net resource is a set of all exportable server methods
that are potentially callable by client applications.The naming rule for the net resource forms a two-level name space. The top level name is a group name. The group names form their own flat subspace where names have to be unique. The bottom level name is a method, also known as API, name. Within group, method names form their own flat subspace, where names have to be unique. Between groups, methods may have identical names.
The external syntax for coding net resource instance names is
group:method.
Two-level nature of net resource names allows hierarchical access
control. If no access rights are specified for the method specified as group:method,
the group is checked next and the result is used as if it
was found for the full name. This is an example of the tree propagation
of rights.The protection model for the exported APIs is based on these access modes:
- read - getting the routing key for a known group:method;
- write - adding a group:method pair to the EIR (export);
- execute - calling a method by specified routing key.
Thus, the access rights for the net resource are coded using one field, which is a bitfield of 4 bits: RWXN.
There is one predefined
system group of methods. Methods
of this group are exported automatically by the net package. They are
required for proper functioning of the protocol. However, if left
unprotected, they may become the target of denial of service type
attacks. Methods of the system groups are described below.| Method |
Use |
Recommended protection for server account |
Recommended protection for other accounts |
system.route |
Used by peers to resolve exported symbolic API names into EIR indexes | RWX |
RX |
system.authenticate |
Used internally by the net package to do remote subject authentication in a routed configuration | RWX |
N |
system.terminate |
Used internally by the net
package to do remote session termination in a routed configuration |
RWX |
N |
system.shutdown |
Used to request the net package shutdown, which normally also initiates the server shutdown | RWX |
RX or N 1) |
Notes
- The Admin may want to expose or to hide this API. This is independent
from
systemresourceshutdowninstance. Both permissions are required for a remote client to shutdown the server. -
Other groups of methods are exposed as the result of the server's
application process activity. To check the exported groups and methods,
use either the debugging features of the server, or turn on the audit for
netresource instances with the access mode W.
Backward Compatibility
The design of the protocol simplifies maintenance of compatibility between different versions of the protocol. As long as the format of the message remains unchanged, the protocol will be compatible between versions.New types of messages can be safely added since unknown types of messages can be skipped before they are ever enqueued. This is done during the initial processing of messages in the enqueueInbound() method of Queue.
Nevertheless compatibility problems are possible, because a new protocol implementation may include instances of new classes as a message payload. In this case, an old application will be unable to instantiate these new messages from the network and an exception will be thrown. It may be possible to resume work with the object stream (in the Protocol class) after such an exception but this issue requires further investigation.
TODO List
- Cleanup
- Refactor Queue.java into the public API (as an interface named Session) and the package private implementation named Queue. Remove any features from the interface that should not be public. Return an instance of this interface (that contains a reference to the real Queue and redirects calls there as needed) from the bootstrap process. This will allow all currently public interfaces in Queue to be made package private. The external interface that is actually available allows full control over which portions of Queue are exposed publicly.
- Move non-network related startup out of the bootstrap classes and back into the main package. Abstract this into a new, common class that can be used by client, servers and other apps. DirectoryService, Logging, SecurityManager... standard setup is what must be moved out. When done, the bootstrap processing should really only be network related.
- Rename and refactor bootstrap processing to be focused on leaf/router node rather than the current client/server nomenclature. The server processing in general may be something we can live with since it is probably still quite accurate. So perhaps the real issue is the "client" nomenclature.
- Allow null payloads or at least make such null payloads easier. Today the creator of a message must make sure that the message has at least an Object[0] as a proxy for a null payload.
- Refactor the EIR (and maybe the SCM) out of the Dispatcher. There is no reason for those to be implemented by a single class.
- The PWT may be better as a separate class (refactored out of the Queue).
- Implement N as the default access permission when no NetResource is available. Today, if no NetResource is available then all entry points are accessible. See Dispatcher.processInbound().
- Complete routed node support:
- Complete the design for dynamic routing table management. Update or replace the address server interface to properly support the needs of dynamic routing table management.
- Implement an address server and full multi-node routing support. Integrate this with the remote authentication and context management support that already exists.
- Implement a firewall (filtering support) based on the security manager's plugin technology (and the associated expression engine used for processing ACLs and rights) (see Router.route()).
- Implement virtual session support using new bootstrap processing and return an instance of the Session interface (documented above) backed by a VirtualQueue instance. Then any processing that uses a queue can use a virtual session based queue.
- Implement broadcast support.
- Implement multicast support.
- Investigate versioning issues.
Copyright (c) 2004-2010, Golden Code Development Corporation.
ALL RIGHTS RESERVED. Use is subject to license terms.