-
Interface Summary Interface Description ExpressionEvaluatorTokenTypes HintsConstants Constant values for the XML grammar used for hints.JavaTokenTypes Provides a complete set of token types sufficient to represent any Java program in an AST form.MethodData Interface defining state required for method lookup during conversion or runtime.ParameterConsumer Functional interface to process a given parameter.ProgressParserTokenTypes SymbolResolver.SchemaHelper<V> Functional interface for use with lambdas.TokenDataWrapper A simple wrapper interface to access basic token data in a wrappered object.Variable.AnnotationHelper Provides a mechanism to specify custom annotations logic for a given variable instance. -
Class Summary Class Description AstGenerator Returns an AST for a specified Progress source file by creating this AST (using the preprocessor and parser) or by loading an already existing persisted AST from a file.AstKey A container for an annotated AST which can be used as a hashable key in a hash map or hash set.Callback Encapsulates the data necessary to make a static or instance method call through the services provided byjava.lang.reflect.CallbackResolver Provides a mechanism for storage and retrieval of method callbacks as represented by theCallbackCallGraphGenerator Special-purpose driver for the pattern engine to create a new call graph for one or more root entry points.CallGraphHelper Common support routines for call graph processing.CallGraphWorker Provides a pattern engine service to create a new call graph based on matches found during AST processing.ClassDefinition Contains a dictionary for each type of class resource and provides methods to maintain and lookup in the respective namespaces.DotKludgeReader Implements a simple input reader based on an underlying input reader, which logically appends the dot character to the underlying input in case the latter terminates with anything else.DotKludgeStream Implements a simple input stream based on an underlying input stream, which logically appends the dot character to the underlying input stream in case the latter terminates with anything else.ExpressionEvaluator Recursively walks an AST generated from a valid Progress 4GL expression and evaluates each node to obtain the final result of the expression which is returned to the caller as aBaseDataType(wrapper).ExternalProcNodeFilter This class name can be passed to thePatternEnginevia thegraph-node-filterconfiguration parameter.FrameAstKey Objects of this class are used as keys for a hashtable that match frame definitions with compatible structure that can be used by shared frames partitions.Function A simple wrapper class to contain all related data about a function.FunctionSample Provides an example of how to implement user-defined functions and variables while using the standard Progress expression evaluator on a given Progress 4GL expression.FuzzyMethodCvt Implements the rules to perform fuzzy method lookup, for conversion.FuzzyMethodLookup Implements the rules to perform fuzzy method lookup.JavaAst Provides symbolic token name lookups that are specific to the Java AST, all other function is implemented in the super class.JavaClassDefinition Contains a Java class instance and uses reflection to answer any queries.JavaClassDefinition.FuzzyMatch Store a method and its match criteria in a sortable form.JavaClassDefinition.MethodMatch Store a method.JavaFieldDefinition A simple wrapper class to contain all related data about a Java field.JavaPatternWorker A pattern worker that provides Java AST services and conversion of Java language token names (as defined by theJavaTokenTypes) to their integral types.JavaPatternWorker.WorkArea Context local work area.JavaSymbolResolver Provides symbol resolution services for Java ASTs.Keyword Encapsulates all data associated with a language keyword.KeywordDictionary Provides a mechanism for storage and retrieval of language keywords as represented by theKeywordLegacyBuiltInClassSanitizer This tool allows an automated approach at sanitizing theLegacySignatureannotations for hand-written legacy builtin classes, which exists in thecom.goldencode.p2j.oopackage.LexerDumpFilter Provides a simple mechanism to run the ProgressLexer on a given Progress 4GL source file and to save the resulting stream of tokens while still servicing the needs of the ProgressParser.MatchMetrics Stores metrics state related to the usage of a given class member.MemberData Container to track data associated with a member of a class.MethodSearchResult Returns the result from a method lookup.ParameterKey Container for a parameter's key, including its data type and mode.ProgressAst Provides symbolic token name lookups that are specific to the Progress AST, all other function is implemented in the super class.ProgressLexer Tokenizes a Progress 4GL source file (input as a stream of characters) into a stream of tokens suitable for theProgressParser.ProgressParser Creates an Abstract Syntax Tree (AST) representation of a Progress 4GL source file from an input stream of tokens (provided by theProgressLexer).ProgressPatternWorker A simple implementation of a pattern worker whose purpose is to convert Progress language token names (as defined by theProgressParser) to their integral types.ProgressStatsHelper Helper to copy and link to Progress 4GL source code.RootNodeList Reads a project-specific list of root entry point procedures.ScanDriver Provides a simple harness to scan a user-defined list of files and drive preprocessing and parsing of each file.SignatureKey SupportLevelDocumentationGenerator Generate textile wiki syntax to describe the support levels of 4GL features.SymbolResolver Contains a dictionary for each type of language namespace and provides methods to maintain and lookup in the respective namespaces.SymbolResolver.SearchResult Store the data resulting from a given file system search.SymbolResolver.UsingSpec Store the data in a USING statement.SymbolResolver.WorkArea Container with context-local data.UastHints Loads hints information from a UAST hints XML file into memory and exposes the data in an easily accessible format.UastHintsWorker Provides a pattern engine service to read string, long, double and boolean values using a file-unique key.Variable A simple wrapper class to contain all related data about a variable. -
Enum Summary Enum Description ClassDefinition.DataStoreType Data store identifier.OOType Identifies the possible OO 4GL types.SymbolResolver.UsingType Describes the type of the USING specification.
Package com.goldencode.p2j.uast Description
rovides a lexer, parser, call tree processing and symbol resolution to
create an intermediate form representation (unified abstract syntax
tree or UAST) of a Progress 4GL source tree in a manner that allows
easy programmatic tree walking and manipulation for the purposes of
inspection, analysis, interpretation, translation and conversion.
Lexer
Parser
Call Tree
The term "parser" refers to software that takes the stream of meaningful tokens (provided by the lexer) and performs a syntax analysis of the contents based on its knowledge of the source language. The result of running a parser is a determination of the syntactical correctness of the input stream and a list of the language "sentences" that comprise the source. In other words, while the lexical analyzer operates on the input stream to create a sequential list of the valid tokens, the parser reassembles these tokens back into "sentences" that have meaning that can be evaluated or executed.
To illustrate, if our source file contains the following Progress 4GL source code:
/* this is a
sample program */
MESSAGE
"Hello World!".
Then the lexical analyzer might (the exact output depends on the exact implementation) generate the following list:
/* this is a sample program */
MESSAGE
"Hello World!"
.
You can see that white space (spaces, tabs, new lines) has been removed. Each token is an atomic entity that can be considered on its own or as a part of a larger language specific "sentence" that can be evaluated.
The parser would take this list and piece things back together into a list of sentences that are syntactically correct and are meaningful for evaluation. This is the flat view of the result (a "degenerate tree"):
/* this is a sample program */
MESSAGE "Hello World!".
Typically, these resulting sentences will be provided in a tree structure, sometimes called an intermediate form representation or an abstract syntax tree (AST). The resulting tree might look something like the following:
external_program
|
+--- comment (/* this is a sample program */)
|
+--- statement
|
+--- keyword_message (MESSAGE)
|
+--- string_expression ("Hello World!")
|
+--- dot (.)
Note that the parenthesized text is the original text from the source file. Each tree node is artificially manufactured, having a specific defined "token type" which can be referenced in code that walks the tree.
Client code that uses the output of the parser can walk the tree and inspect, analyze, interpret, transform or convert it as necessary. For example, the tree structure naturally puts expressions in RPN (reverse polish notation), otherwise known as postfix notation. This is required to properly evaluate the expression (and generate results with the correct precedence). This is significantly easier than the interpretation or evaluation of expressions using the human-readable infix notation.
By using a common lexical analyzer and parser, the tricky details of the Progress 4GL language syntax can be centralized and solved properly in one location. Once handled properly, all other elements of the conversion tools can rely upon this service and focus on their specific purpose.
Parser and lexer generators have reached a maturity level that can easily create results to meet the requirements of this project. This creates a savings of considerable development time while generating results that have a structure and level of performance that meets or exceeds the hand-coded approach.
In a generated approach, it is important to ensure that the resulting code is unencumbered from a license perspective.
The current approach is to use a project called ANTLR. This is a public domain (it is not copyrighted which eliminates licensing issues) technology that has been in development for over 10 years. It is used in a large number of projects and seems to be quite mature. It is even used by one of the Progress 4GL vendors in a tool to beautify and enhance Progress 4GL source code (Proparse). The approach is to define the Progress 4GL grammar in a modified Extended Backus-Naur Form (EBNF) and then run the ANTLR tools to generate a set of Java class files that encode the language knowledge. These resulting classes provide the lexical analyzer, the parser and also a tree walking facility. One feeds an input stream into these classes and the lexer and parser generate an abstract syntax tree of the results. Analysis and conversion programs then walk this tree of the source code for various purposes. There are multiple different "clients" to the same set of ANTLR generated classes. Each client would implement a different view and usage of the source tree. For example, one client would use this tree to analyze all nodes related to external or internal procedure invocation. Another client would use this tree to analyze all user interface features.
P2J uses ANTLR 2.7.4. This version at a minimum is required to support the token stream rewriting feature which is required for preprocessing.
Some useful references (in the order in which they should be read):
Building Recognizers By Hand
All I know is that I need to build a parser or translator. Give me an overview of what ANTLR does and how I need to approach building things with ANTLR
An Introduction To ANTLR
BNF and EBNF: What are they and how do they work?
Notations for Context Free Grammars - BNF and EBNF
ANTLR Tutorial (Ashley Mills)
ANTLR 2.7.4 Documentation
EBNF Standard - ISO/IEC 14977 - 1996(E)
Do not confuse BNF or EBNF with Augmented BNF (ABNF). The latter is defined by the IETF as a convenient reference to their own enhanced form of BNF notation which they use in multiple RFCs. The original BNF and the later ISO standard EBNF are very close to the ABNF but they are different "standards".
Golden Code has implemented its own lexical analyzers and parsers before (multiple times). A Java version done for the Java Trace Analyzer (JTA). However, the ANTLR approach has already built a set of general purpose facilities for language recognition and processing. These facilities include the representation of an abstract syntax tree in a form that is easily traversed, read and modified. The resulting tree also includes the ability to reconstitute the exact, original source. These facilities can do the job properly, which makes ANTLR the optimal approach.
The core input to ANTLR is an EBNF grammar (actually the ANTLR syntax is a mixture of EBNF, regular expressions, Java and some ANTLR unique constructs). It is important to note that Progress Software Corp (PSC) uses a BNF format as the basis for their authoritative language parsing/analysis. They even published (a copyrighted) BNF as 2 .h files on the "PEG", a Progress 4GL bulletin board (www.peg.com). In addition, the Proparse grammar (EBNF based and used in ANTLR) can also be found on the web. Thus it is clear that EBNF is sufficient to properly define the Progress 4GL language and that ANTLR is an effective generator for this application. This is the good news.
However, there is a very important point here: the developers have completely avoided even looking at ANY published Progress 4GL grammars so that our hand built grammar is "a clean room implementation" that is 100% owned by Golden Code. The fact that they published these on the Internet does not negate their copyright in the materials, so these have been treated as if they did not exist.
An important implementation choice must be noted here. ANTLR provides a powerful mechanism in its grammar definition. The structure of the input stream (e.g. a Progress 4GL source file) is defined using an EBNF definition. However, the EBNF rules can have arbitrary Java code attached to them. This attached code is called an "action". In the preprocessor, we are deliberately using the action feature to actually implement the preprocessor expansions and modifications. Since these actions are called by the lexer and parser at the time the input is being processed, one essentially is expanding the input directly to output. This usage corresponds to a "filter" concept which is exactly how a preprocessor is normally implemented. This is also valid since the preprocessor and the Progress 4GL language grammars do not have much commonality. Since we are hard coding the preprocessor logic into the grammar, reusing this grammar for other purposes will not be possible. This approach has the advantage of eliminating the complexity, memory footprint and CPU overhead of handling recursive expansions in multiple passes (since everything can be expanded inline in a single pass). The down side to this approach is that the grammar is hard coded to the preprocessor usage and it is more complicated since it includes more than just structure. This makes it harder to maintain because it is not independent of the lexer or parser.
The larger, more complex Progress 4GL grammar is going to be implemented in a very generic manner. Any actions will only be implemented to the extent that is necessary to properly tokenize, parse the content or create a tree with the proper structure. For example, the Progress 4GL language has many ambiguous aspects which require context (and sometimes external input) in order to properly tokenize the source. An example is the use of the period as both a database name qualifier as well as a language statement terminator. In order to determine the use of a particular instance, one must consult a list of valid database names (which is something that is defined in the database schema rather than in the source code itself). Actions will be used to resolve such ambiguity but they will not be used for any of the conversion logic itself. This will allow a generic syntax tree to be generated and then code external to the grammar will operate on this tree (for analysis or conversion). In fact, many different clients of this tree will exist and this allows us to implement a clean separation between the language structure definition and the resulting use of this structure.
The following is a list of the more difficult aspects of the Progress 4GL:
Since most Progress 4GL procedures call other Progress 4GL procedures which may reside in separate files, it is important to understand all such linkages. This concept is described as the "call tree". The call tree is defined as the entire set of external and internal procedures (or other blocks of Progress 4GL code such as trigger blocks) that are accessible from any single "root" or application entry point. It is necessary to process an entire Progress 4GL call tree at once during conversion, in order to properly handle inter-procedure linkages (e.g. shared variables or parameters), naming and other dependencies between the procedures.
One can think of these 2 types of trees (abstract syntax trees and the call tree) as 1 larger tree with 2 levels of detail. The call tree can be considered the higher level root and branches of the tree. It defines all the files that hold reachable Progress 4GL code and the structure through which they can be reached. However as each node in the call tree is a Progress 4GL source file, one can represent that node as a Progress 4GL AST. This larger tree is called the "Unified Abstract Syntax Tree" (Unified AST or UAST). Please see the following diagram:
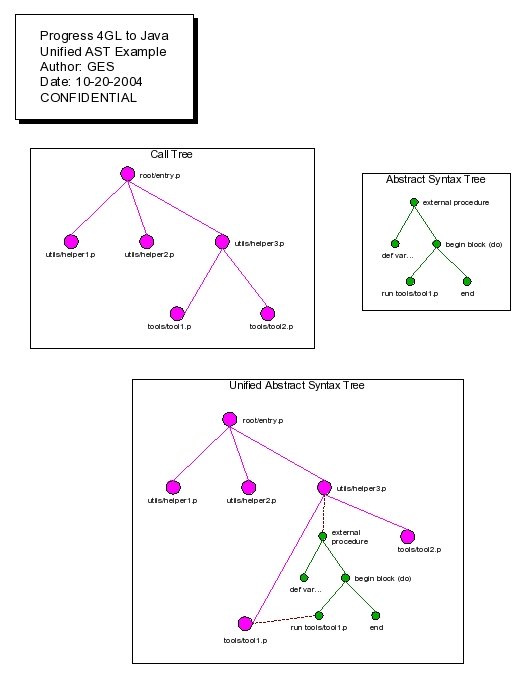
By combining the 2 levels of trees into a single unified tree, the processing of an entire call tree is greatly simplified. The trick is to enable the traversal back and forth between these 2 levels of detail using an artificial linkage. Thus one must be able to traverse from any node in the call tree to its associated Progress 4GL AST (and back again). Likewise one must be able to traverse from AST nodes that invoke other procedures to the associated call tree node (and back).
Note that strictly speaking, when these additional linkage points are added the result is no longer a "tree". However for the sake of simplicity it is called a tree.
This representation also simplifies the identification of overlaps in the tree (via recursion or more generally wherever the same code is reachable from more than 1 location in the tree).
To create this unified tree, the call tree must be generated starting at a known entry point. This call tree will be generated by the "Unified AST Generator" (UAST Generator) whose behavior can be modified by a "Call Tree Hints" file which may fill in part of the call tree in cases where there is no hard coded programmatic link. For example, it is possible to execute a run statement where the target external procedure is specified at runtime in a variable or database field. For this reason, the source code alone is not deterministic and the call tree hints will be required to resolve such gaps.
Note that there will be some methods of making external calls which may be indirect in nature (based on data from the database, calculated or derived from user input). The call tree analyzer may be informed about these indirect calls via the Call Tree Hints file. This is most likely a manually created file to override the default behavior in situations where it doesn't make sense or where the call tree would not be able to properly process what it finds.
The UAST Generator will create the root node in the call tree for a given entry point. Then it will call the lexer/parser to generate a Progress 4GL AST for that associated external procedure (source file). An "artificial linkage" will be made between the root call tree node and its associated AST. It will then walk the AST to find all reachable linkage points to other external procedures. Each external linkage point represents a file/external procedure that is added to the top level call tree and "artificial" linkages are created from the AST to these call tree nodes. Then the process repeats for each of the new files. They each have an AST generated by the lexer/parser and this AST is linked to the file level node. Then additional call tree/file nodes will be added based on this AST (e.g. run statements...) and each one gets its AST added and so on until all reachable code has been added to the Unified AST.
This resulting Unified AST is built based on input that is valid, preprocessed Progress 4GL source code.
For a more detailed diagram, use this link.
One of the more complicated aspects of the lexer is th implementation of language keywords (and their associated abbreviation support). Please see the following reference for why the preprocessor and parser don't implement keyword abbreviation support instead of the lexer.
Some features that may be expected to be implemented in the lexer are actually implemented in the preprocessor. This is done for 2 reasons:
The primary job of the parser is to take the token stream (represented by the Lexer) and match that with the proper sets of rules that converts the flat stream of tokens into a 2 dimensional tree (AST). In addition, there are many ambiguities of the Progress language that could not be resolved at the lexer level since the solution requires knowledge of the parser's context. Due to issues in how the generated code handles lookahead, it is not feasible to share state between the lexer and parser (thus providing feedback to the lexer at the time that the token is created). Instead the parser must rewrite the tokens based on its context. Please see the ProgressLexer overview for more details.
The following sections describe the most critical issues facing the parser. At the end of each subsection is a list of links that should be reviewed to obtain more details. At the end is the implementation plan for the completion of the ProgressParser. Please see this link for a top-level overview of the parser.
Data type support is primarily a function of providing the correct token types for each data type and resolving lvalues (variables and fields form the schema) and function calls to the correct data types. This enables expressions, assignments and other data type specific parsing to occur.
Special abbreviation processing is implemented in the processing of the AS clause since the documented abbreviations (or lack thereof) are not followed in this case. See the table above for the real minimum abbreviations of the data type names.
Variable and field types can optionally be specified as single dimensional arrays (multi-dimensional arrays are not supported in Progress 4GL). The syntax for specifying an array relies upon the use of the EXTENT keyword in a DEFINE VARIABLE statement or in the data dictionary. When defining variables, the INITIAL keyword can be used to with the [,,,] array initializer syntax to provide a list of initial values. If there are fewer values than array elements, then the last value is used to initialize into all remaining uninitialized array elements. In addition the LABEL keyword can be used with the <string>, <string>... syntax to provide separate labels for each element in an array.
To reference an array element, the [ integer_expression ] syntax is used (contrary to some of the documentation, it does not need to be an integer constant). Whitespace can be placed before the opening left bracket or anywhere inside the brackets. The lvalue rule makes an optional (zero or one) rule reference to the subscript rule. An example reference might be hello[ i + 3 ] where i is an integer variable that holds a value that is positive and less than the array size - 2. All Progress array indices are 1 based (the first element is referenced as array[1]).
The subscript rule implements the subscripting syntax. This subscript rule also implements the range subscripting support using the FOR keyword and a following integer constant to specify the ending point to the integer expression's starting point (e.g. hello[1 for 4] references the first 4 elements of the hello array).
Method and attribute support has been added to the lvalue rule. It is tightly bound to variable and field references and can be optionally present in many locations. At this time, the support is highly generic (the correct resulting data types are not determined).
For more details, see:
A built-in is a symbol defined by the Progress language as a set of keywords that represent language statements, functions, widgets, methods and attributes. These keywords can be either reserved or unreserved. In addition, some keywords can be arbitrarily abbreviated down to any number of characters limited by some minimum number. For example, the DEFINE keyword can be shortened to DEFIN, DEFI, or DEF. Not all keywords can be abbreviated. There are examples of both reserved and unreserved keywords supporting abbreviations.
A user-defined symbol is a programmer created name for some application-specific Progress construct that the programmer has created. The symbol naming in this case is quite flexible. Names can be up to 32 characters long, must start with an alphabetic letter and can then contain any alphanumeric character as well as the characters # $ % & - or _. Reserved keywords cannot be used as user-defined symbols, while unreserved keywords can. Keywords referring to entities of like type will be hidden by a user-defined symbol of that type. For example, it is possible to hide certain built-in functions with a user-defined function of the same name. Once defined in a given scope, the original Progress resource that is hidden cannot be accessed.
Types of Symbols:
Each of these types of symbol must be stored in a namespace. That namespace may contain more than one symbol type, or may be unique to a specific type of symbol.
Each namespace is populated with a new symbol name when the associated entity is defined or (in some cases) declared. Once a name is added to the namespace, it can be used in other source code references as long as the namespace is visible to that code. For example, "define variable" statements must always precede all references to the defined symbol.
Some namespaces are flat and some are scoped. A flat namespace is one in which the same names are visible no matter the context from which a namespace query originates. A scoped namespace is essentially a cooperating stack of namespaces, where a new namespace is added to the top of the stack at the start of a new scope and that top of stack namespace is removed at the end of the scope. Lookups start at the top of the stack and work down the stack until the first matching name is found. This scoped approach allows for symbol hiding where names in one scope can be the same as a name in a different scope, but only the instance that is in the closest scope to the top is what is found.
Local symbols generally hide shared scoped/shared global variables. Local symbols in an internal procedure will hide the same names in an external procedure.
Symbol namespaces are different by type of symbol. There is no unified namespace. One of the implications is that functions and variables of the same name must be differentiated (by context) and cannot hide each other.
Built-in functions and language statements of the same name are differentiated in the parser by context. There is no simple rule for detecting this based on syntax alone since there are many Progress built-in functions that do not take parenthesis (when they have no argument list) and likewise there are language statements that can be followed by a parenthesized expression that would appear syntactically like a function (there can be whitespace between function names and the parenthesized parameter list).
User functions and user variables are differentiated by the presence or absence of (). There is never a valid expression that has an lvalue followed immediately by ( ).
Only internal procedures, functions and triggers add scoping levels for variables. Other types of blocks are scoped to the external procedure level, which is the same as saying that any defined variables inside non-procedure blocks (DO, REPEAT, FOR...) are scoped at the same level as global variables from the external procedure's perspective.
Symbol resolution is the process by which a reference to a particular symbol type is queried from the corresponding namespace. The lookup occurs at the point in the parsing at which the reference is made. This lookup may return critical information that is the associated with the node being built in the AST for that reference. For example, when variable references are found in a namespace, the query returns a token type that is assigned to that tree node (e.g. the token type for the node is converted from a generic SYMBOL to a token type that matches the specific variable data type such as VAR_INT).
The SymbolResolver class encapsulates the various namespaces (a.k.a. dictionaries) that are in use. It provides maintenance and lookup services to the lexer and parser. Lookups are inserted at key locations in the parser. In these locations, the token type of the symbol is usually rewritten. This allows the parser's context to drive the decision on which namespace to use and how to interpret the symbol. This is critical since there is no unified namespace.
One unique namespace is that for language keywords. These are the only symbols that do not require an exact match but instead can be abbreviated. This special namespace is implemented by Keyword and the KeywordDictionary classes. This namespace is shared between the lexer and the parser since the keyword lookup is first done by the lexer's mSYMBOL method. To keep the implementation of the parser and also the preprocessor to the simplest implementation, the lexer is the optimal location for this function. Since the preprocessor is implemented with a minimum of knowledge of the Progress language, to handle the abbreviations there would add significantly more complexity (especially since there is a mixture of reserved and and unreserved keywords). The keyword processing cannot be completely put in the parser because the Progress language is so keyword rich that the parser must already see the tokens as language keywords from the topmost parser entry point (all the way down as it recursively descends the tree). The parser then aggregates the language statements back together based on already knowing exactly which keyword has been found. In other words, the lexer will assign a token type to each token found. This token type is what the parser keys off of in determining how to group the tokens into language statements.
Keeping the abbreviations out of the preprocessor has the advantage of exactly duplicating the Progress preprocessor output (which doesn't expand the abbreviations). This is important to be able to test and prove that the preprocessor is 100% correct/compatible.
For more details, see:
Schema names refer to the following schema entities:
database1 -> table1 ---> field1
-> table2 ---> field1
|
+-> field2
database2 -> table2 ---> field1
-> table3 ---> field1
|
+-> field2
All connected databases contribute to the namespace and can be referenced directly. Within a specific part of the tree (at any containing level such as within a single database or within a single table) each contained name must be unique. But between databases and tables, the contained names can be the same (the text is an exact match) because they live in separate parts of the tree. This is a cause of ambiguity when it is not clear which part of the tree is being referenced, such that multiple matches can be made to the same lookup. This means that there can be inherent ambiguity between:
Such ambiguities are resolved by the following:
The schema namespace is something that is predefined at the start of a procedure. This is due to the Progress requirement that all databases to be used by a procedure must be connected at the time of compilation. This means that the database connection (using the CONNECT statement) must be done using command line arguments when starting Progress, must be manually done in the Data Dictionary before running a procedure or must be programmatically done before running a specific procedure that is dependent upon such a connected database. At the start of a Progress procedure, the schema namespace is defined based on all database, table, field, index and sequence names available in the schemas of all connected databases. To mimic this, the P2J parser will need the same information as extracted from the schema during the schema conversion of all schemas that are in use. In addition, the parser will need to know the names of all connected databases. Both of these features will be provided by the SchemaDictionary class in the schema package. This class will use a persistent configuration file or set of files to obtain this information and the SymbolResolver will hide the instantiation and usage of this class from the parser.
Since these schema names are all known before the procedure runs, there are no preceding language statements that allow us to populate the dictionary as the parsing occurs. Instead, such names can be referenced at any time. This is different than how variables work. All variables that can be accessed by a procedure must have a corresponding "define variable", "define parameter" or "parameter clause" that adds the associated name and type to the variable dictionary. In lookups, this variable dictionary has precedence over the schema dictionary since a variable of the same name as an unqualified field will hide the field (one cannot refer to the field without more explicitly qualifying it).
In order to handle partially or fully qualified names, the lexer was made aware of how to tokenize such symbols. This dramatically reduces the effort since the parser would have to lookahead up to 5 tokens:
symbol_or_unreserved_keyword DOT symbol_or_unreserved_keyword DOT symbol_or_unreserved_keyword
Once a match was found, these tokens would have to be combined into a single token. The logic would be very complicated when one considers that this could be needed for tables or fields. It is made even more complicated by the fact that whitespace is lost in the lexer but is relevant to the resolution of which tokens should be combined into a single resulting token. Implementing this in the lexer is a necessity.
To handle qualified names in the lexer, the mSYMBOL rule was modified. This rule is inherently greedy, which is how Progress works as well. This means that Progress will match the largest possible qualified name that is specified and then do a lookup. A non-greedy approach would try a lookup on the first possible name and then extend the symbol to include any DOT and additional symbol, try the lookup again and so on until a match was found. Other critical assumptions are required to implement this rule:
Of course, the matching is limited to 3 part qualified names (separated by 2 DOTs) so the 3rd dot can will always signal the end of the qualified name even without intervening whitespace.
Once a qualified schema name is matched, the token type is set to DB_SYMBOL. Normal keyword lookup is bypassed for such tokens as we have not found any keyword using a DOT character, nor can we use even a reserved keyword as the start of a new statement without intervening whitespace. This means that we know that this is a database symbol and can set it to this generic type to be resolved later in the parser. Of course, unqualified database/table/field names will not be detected as a database symbol and so these will be tokenized as a SYMBOL or as a keyword if there is a match during keyword lookup. The parser handles the conversion of all of these generic forms into the proper data types (e.g. FIELD_INT, FIELD_CHAR...) based on context.
Complicating the schema name resolution is the Progress feature that some schema names can be arbitrarily abbreviated. Field names and table names in particular can be abbreviated to the shorted unique sequence of leftmost characters that unambiguously match a single entry in the namespace being searched.
All lookups (fields/tables/databases) are done on a case-insensitive basis, just like all other Progress symbols.
Taking this into account, the following are the matching processes:
Database names are looked up using a single level, exact match search of the connected databases. A Progress 4GL compiler error would occur if the name being search for does not exist in this list. No abbreviations or qualifiers are in effect during this search.
Table names are looked up with a 4 step process:
Unqualified field references from any kind of record (table, temp-table, work-table, buffer) will collide if they are non-unique, even if the search was done on an exact match, except in such cases where the associated record is in "scope" making that unqualified name unambiguous.
An exact match with a name always supersedes a conflicting abbreviation.
Note that user-defined variable names cannot be abbreviated and database names cannot be abbreviated. The abbreviation processing is only done for fields and tables.
Buffer names cannot be abbreviated but buffer field names can be abbreviated. Temp-table and work-table names cannot be abbreviated, however temp-table and work-table field names CAN be abbreviated.
Given 2 names cust and customer (which could both be tables or both fields) where one is a subset of the other:
No ambiguity is allowed at runtime, ever. If there is more than 1 match found via any of these matching algorithms, then a compile-time error will occur. This means that all source code read by P2J can be assumed to have 1 and only 1 match. There will never be 0 matches nor will there be 2 or more matches. The primary advantage of this fact is that the logic of any search algorithms is insensitive to the order in which the search is made. This means that the P2J environment can be coded using arbitrary search ordering without affecting the outcome. This is true for unqualified name searches and for partially or fully qualified names.
Since the namespace being used depends upon the databases that are connected when a procedure is called, the only time it is completely safe to use unqualified field names is when a specific record scope is in effect, causing normally ambiguous names to be unambiguous. Although the scoping rules are arcane and poorly documented, they can be relied upon.
The schema namespace is not completely static. Dynamic modification of the namespace is possible by defining buffers, temp-tables and work-tables. All of these are equivalent to a table and have field definitions.
Buffers are equivalent (from a schema perspective) to an already existing table. They just represent a different memory allocation in which a record from the referenced table can be stored. From this perspective, one might think of buffers as aliases for a table, at least from the parser's perspective. In reality, there is more going on of which the parser is unaware.
Buffers can be created, referenced or passed into an external procedure AS WELL AS AN internal procedure AND IN A function. Buffers
can only be referenced within the scope that they are defined, so a buffer defined in an external procedure is accessible until that procedure ends. A buffer defined in an internal procedure or function is inaccessible after that internal procedure or function block ends.
Temp-tables and work-tables are both treated like dynamically adding a table to the schema (not associated with any database). This table can optionally copy the entire schema structure of a current table and/or add arbitrary fields to the definition. It appears there is no way to remove fields from the definition if one bases it upon an existing table.
Temp-tables and work-tables can be created inside an external procedure, a shared instance can be accessed inside an external procedure or an instance can be passed in as a parameter. In all cases, such tables can be referenced from the moment of definition/declaration until the end of that external procedure.
When defining or adding temp-tables, work-tables and buffers, these entities can be scoped only for the duration of a do, for or repeat block. They are always scoped to a procedure or function (buffers only).
Temp-table/work-table and buffer names that are added/defined, will hide an unqualified conflicting table name (such that the only way to
reference that database table is with a fully qualified name).
Within a single external procedure (or internal procedure/function in the case of buffers), you can never define duplicate temp-table,
work-table or buffer names.
It is possible to define a buffer FOR a buffer that refers to a temp-table. However, Progress does not allow a buffer FOR a buffer that refers to a table.
The schema namespace must handle these dynamic changes through methods that are called by the parser in specific rules which implement Progress language statements such as define buffer, define temp-table and define work-table.
Another type of namespace modification is the use of aliases. All connected databases have a "logical database name" that is used to qualify table and field names. By using aliases, one can create additional logical names that are equivalent to the original database name. Any references to the alias are treated as references to the original database name. One trick that is often used is that a database is aliased before running another external procedure that uses the same schema by a different logical name. This allows a common procedure to be used against 2 or more databases as long as the schema are identical or at least compatible in the areas in use. The problem in such tricks is that this is done external to the code being run, so the parser must be externally informed or the schema namespace must be prepared to handle all possible aliases. If there are cases in which the same alias is used for different databases then this may be not be statically defined in a configuration file. This area needs additional definition before it can be implemented.
A record scope is the beginning and ending of a buffer (associated with the table or "record" in question) that can be used to store real rows of data. This scope determines many things such as when data is written to the database or when a new record is fetched. However, from the parser's perspective, the only reason why record scope matters is because it affects unqualified field name resolution.
Progress databases are very likely to have a large number of field names that are duplicated between tables. For this reason, these field names are not unique across the database and thus in normal circumstances, they can only be unambiguously referenced when they are qualified. Wherever there are long lists of field names, it is convenient to allow the more liberal usage of unqualified names. This is possible whenever there are one or more record scopes that are active. In this case, the list of unique unqualified fields can be expanded based on the list of those tables in scope at the time. If multiple tables are in scope, then the set of all field names that are unique across that list of tables in scope will be available for searching even if those names would normally be unavailable due to conflicts with other tables. As long as the conflicts are only with tables that are not in scope, those unqualified names can be used. If however, the same field name is used in 2 or more of the tables that are in scope, that name still needs to be qualified on lookup.
Buffers are referenced via a name. That name can have been explicitly defined in the current external procedure, internal procedure or function using one of the following:
DEFINE BUFFER buffername FOR record
DEFINE PARAMETER BUFFER buffername FOR record
FUNCTION ... (BUFFER buffername FOR record, ...)
If not explicitly defined, then the buffer name must be implicit defined based on a reference to a table name (database table, temp-table or work-table) inside a language statement or built-in function.
Buffers can only be scoped to an enclosing block which has the record scoping property. All block types (external procedures, internal procedures, triggers, functions, repeat and for) except DO have the record scoping property by default. Even a DO obtains record scoping when either the FOR or PRESELECT qualifier is added (these are mutually exclusive).
Internal procedures, triggers and functions additionally have namespace scoping properties such that an explicit definition of a buffer name in one of these blocks will hide the same explicit buffer name in the containing external procedure. However, if no "local" definition exists for an explicit buffer name, references in these contained blocks will cause the original definition in the external procedure to be scoped to the external procedure level itself. Please note that any explicit buffer definitions inside an internal procedure, trigger or function cannot be used outside of that block. The external procedure is different in this respect (this is the same behavior as Progress provides for variables).
If a buffer is not explicitly created, then it is created implicitly via a direct table name reference in the source code. For example, if a table named customer exists in the currently connected database, then any of the following language constructs that reference customer (e.g. create customer) cause a buffer of the same name (customer) to be created. This can be confusing since some language constructs use this same name to reference the schema definition of that table, some use the name to reference the table and some use the name as a buffer. This polymorphic usage is considered an "implicit" buffer.
Whether or not a language construct creates a buffer is determined by the type of the reference. The following maps language constructs to the type of record reference:
There are 4 types of record references (to database tables, temp-tables or work-tables) which may cause a buffer to be created. If this reference is implicit, the resulting buffer is named the same as the table to which it refers. It is important to note that even when a reference does create a buffer (allocate memory) only a small subset of the above statements actually fill it with a record (all buffers only hold a single record at a time). Other statements (e.g. FIND, FOR or GET) may handle both the creation of the buffer and the implicit loading of that buffer with the first record.
The following sections describe each of the reference types. 3 of the 4 types can cause the creation of a new buffer. Multiple references to the same buffer are sometimes combined into a single buffer creation and at other times more than 1 buffer can be created. The following describes the rules by which the number of buffers are determined. For each buffer that is created, there is also a "record scope" that corresponds to this buffer. This scope determines the topmost block in which the buffer is available.
In the following rules, the use of "implicit" should not be confused with whether or not a buffer name has been explicitly or implicitly referenced. In many cases, Progress will implicitly create a larger scope for a buffer such that multiple references share the same buffer. This is the sense in which the word implicit should be interpreted. Most importantly, the scoping rules (both the explicit rules and the implicit expansion rules) are applied in the same exact manner for both explicitly defined buffers as for implicitly defined buffers.
No Reference
Some name references can occur in many language statements, even before these scope creating statements. For example, a DEFINE TEMP-TABLE <temp-table-name> LIKE <table_name> statement is such a reference that can occur anywhere in a procedure. No buffer is being referenced here, instead it is the schema dictionary (the data structure of the record) that is being referenced.
Strong Reference
Only two language statements (both are kinds of block definitions) can be a strong reference (DO FOR and REPEAT FOR). A new buffer is created and that buffer is scoped to the block being defined. Strong scopes are explicitly defined by the 4GL programmer and the Progress environment never implicitly changes the scope to be larger (as can happen with the next two reference types). A strong reference doesn't ever implicitly expand beyond the block that defines it.
Other reference types can be nested inside a strong scope and the scope of these references is always raised to the strong scope. Thus every buffer reference within a strong scoped block is always scoped to the same buffer.
Additionally, no free references to the same buffer are allowed outside the block defining a strong scope (the code will fail to compile). Weak references to the same buffer can be placed outside or inside a strong scope.
Weak Reference
Only three language statements (all of which are kinds of block definitions) can be a weak reference (FOR EACH, DO PRESELECT and REPEAT PRESELECT). Depending on other references (or the lack thereof) in a file, a weak reference may create a new buffer and scope that buffer to the block in which the buffer was referenced.
If a weak reference to a buffer is nested inside a block to which the buffer is strongly scoped, then this reference does not create a new buffer and is simply a reference to that same strongly scoped buffer.
If a weak reference is not nested inside a strong scope, it will create a new buffer and scope that buffer to the block definition which made the weak reference, BUT this will only happen if no unbound free references to the same buffer exist (see Free Reference below for details).
With the existence of one or more unbound free references, it is possible that the weak reference will have its scope implicitly expanded to that of a containing scope. For this to occur, the scope of the buffer will be expanded to the nearest block that can enclose the multiple references to this same buffer. The problem is that there are complex rules to determine which references (weak and free) are combined into a single buffer (and its associated scope) and which weak references are left alone.
Free Reference
Anything that is not a "no reference", strong reference or weak reference is a free reference.
If the free reference is contained inside a block to which the referenced buffer is strongly scoped, then this is simply a reference to that same buffer and no buffer creation or scope change will occur.
If the free reference is contained inside a block to which the referenced buffer is weakly scoped, then this is simply a reference to that same buffer and no buffer creation or scope change will occur. Please note that the Progress documentation incorrectly states that "a weak-scope block cannot contain any free references to the same buffer". More specifically, one cannot nest certain free references to a given buffer that is scoped to a FOR EACH block (which is the most common type of weak reference). For example, one cannot use a FIND inside a FOR EACH where both are operating on the same buffer. However, one should note that field access is a form of free reference and this is perfectly valid (as one would expect) inside a FOR EACH.
Contrary to the Progress documentation, if the weak reference is created by a DO PRESELECT or REPEAT PRESELECT, then it is required that one use one or more free references in order to read records since neither of these blocks otherwise provide record reading. In this case, even FIND statements work within such a block.
If the free reference is not nested inside a block to which the same buffer is already scoped, then this free reference may cause the scope of other free references and weak references to be implicitly expanded to a higher containing block.
In two cases (FOR FIRST and FOR LAST), a free reference is part of a block definition. In such a case, if there is no need to implicitly expand the scope for this buffer, it will be scoped to the block definition in which the free reference was made.
Much more common is for a free reference to be a standalone language statement which is not part of a block definition (e.g. any form of FIND). In such cases, whether a buffer is created or not and where that buffer is scoped are decided via a complex series of rules.
It is important to note that in the absence of free references, there will never be any implicit expansion of record scopes. Thus the free reference is the cause of implicit scope expansion.
Implicit Scope Expansion Rules
The following are the rules for scope expansion (Progress does not document these rules, but they have been determined by experience). These rules all assume that all references refer to the same implicit buffer name. The previous rules for scoping are not repeated here as these rules only reflect the logic for implicitly expanding scope. To perform the analysis described here, one must traverse the Progress source AST that the parser creates with "forward" meaning down and/or right from the current node and "backward" meaning up and/or left of the current node. To understand some of the terms in the following rules, one must think of the tree as a list. In other words, one must "flatten" (degenerate) the tree into a simple list (based on the depth first approach of traversing down the tree before traversing right). Using this conceptual list form of the tree, one can see that the "closest prior" (the most recently encountered node that matches some criteria) or "next" (the closest downstream node that matches some criteria) node can be thought of as a simple backward or forward "search" respectively. This is critical to understand these rules since much of the logic is not defined by the nesting of blocks (as would be expected) but is rather defined by the "simple" ordering of the references.
The following are examples to show both the simple/expected behavior as well as each of the more obscure (counter-intuitive) cases. In each example the following explains how to interpret the text:
Nesting Scopes
Scopes can be nested although there are rules against nesting 2 scopes (referring to the same table) that are the same type. So 2 weak scopes for table1 can't be nested and 2 strong scopes of table1 can't be nested. A strong scope cannot be nested inside a weak scope for the same buffer. On the other hand, it is possible to nest a weak scope inside a strong scope where both are referencing the same table. Note that if a weak scope is nested inside a strong scope, that weak scope cannot be expanded by a free reference. The strong scope binds to the specified block and cannot (by definition) ever be expanded.
It is also known that where multiple scopes (to different tables) are active, the subset of unique field names (that are unique across those tables actively in scope) are added to the namespace and any common (non-unique across the active scopes) names are removed from the namespace. This means that as tables are added and removed from the active scope list, each such change can both add and remove from the namespace. Please see the field name lookup algorithm above for more details.
Record scopes create a schema namespace issue because while a record is in scope, unqualified field names resolve which would normally be ambiguous. This is complicated by the fact that the algorithm to decide upon the block to which a given buffer is scoped cannot be implemented in a single-pass parser.
The primary difference between these scopes seems to be in how the scopes get implicitly expanded based on other database references in containing blocks. Normally a scope is limited to the nearest block in which the scope was created. Strong scopes can be removed from namespace consideration as soon as the this block ends. Weak scopes and free references can both be expanded to the containing block depending on a complex set of conditions. Note that within the naturally scoped block, normally ambiguous unqualified field names are made unambiguous. This is straightforward to implement. The problem is that the parser must properly detect when the scope is implicitly expanded and know when to remove the scope. The parser cannot simply leave all weak and free reference scopes in scope permanently. This is because in a complex procedure, as scopes are removed, some names are removed but some names may also be added back! This is due to the fact that adding a scope while other scopes are still active will remove any field names that are in common between all active scopes. So, removing that scope, re-adds those removed names to the namespace. Since the namespace can expand when a scope is removed, it is critical to detect this exact point and implement this removal otherwise the parser will fail to lookup names that should not be ambiguous.
The current approach has been to use the SchemaDictionary namespace to keep track of scopes. At the start of every for, repeat or do block a scope is added and at the end, this scope is removed. This stack of scopes handles the nesting of names properly. Then the parser makes a very big simplifying assumption: every record (table, buffer, work-table or temp-table) reference is automatically "promoted" to the current scope (the top of the stack of scopes). This allows any tables in the current scope to take precedence for unqualified field lookups and then tables in the next scope down take precedence and so on until the name is resolved (remember: valid Progress code will ALWAYS have only unambiguous names so it is only a matter of where one finds it). The problem in this simplistic approach (see the record method) is that Progress may not always promote as we do. Thus in our implementation, there may be promoted tables that wouldn't otherwise be there. This may cause some names that would have been unambiguous (with a more limited set of tables in scope) to now be ambiguous. We don't have an example of such a situation but if it does occur, the implementation may have to get much more smart about when to and when not to promote.
To properly implement scoping support, these conditions must be fully explored and documented. The following list is an incomplete set of testcases which needs to be completed before scoping support can be implemented. In the table, each record that has the same scenario number (in the testcases that have more than 1 row) describes a database reference made inside that scenario. The order of the rows is the same order as used in the testcases. The column entitled "Disambiguates Outside Unqualified Field Name" can be interpreted as whether an unqualified field name can be used outside the block in which the scope was added (it can always be used inside such blocks). This is usually (but not always) just another way of interpreting the "Scoped-To Block" column, since it is the block which the scope is assigned that defines the location of where the scope exits (and thus where unqualified names can no longer be used). There are conditions (see scenarios 6 and 7 below) where the these columns show conflicting results. Note that the LISTING option on the COMPILE statement is used to create a listing file that showed exactly in which block Progress determined the scope to be assigned.
It is very important to note that there is only ever 1 buffer (memory allocation) in each given procedure (internal or external), function or trigger, even though there may be multiple buffer scopes. The scopes affect record-release but the same memory is used for storage of records read in all contained scopes AND Progress doesn't restore the state of the buffer when a nested scope is complete. This means that when a nested scope is added, the record that had been there is released at the end of that scope. Once that record is released, there is no record in the buffer. If there is downstream processing within the outer scope that expects the record to be there, it will find the record missing.
Unless a record is explicitly defined in an internal procedure, function or trigger, the buffer creation will occur at the external procedure level and this same buffer will be in use the entire scope of the external procedure. In the case where an internal procedure, function or trigger does have an explicit buffer defined, this results in namespace hiding and an additional (local) memory allocation. Buffer names can be the same with a buffer in the external procedure, but any explicit definition will create a local instance of that buffer. Nested scopes that operate on that buffer will have no affect on the buffer of the same name in an enclosing external procedure.
Multiple scopes are possible with explicitly defined buffers, just as they are with implicit buffers, even though there is only ever 1 memory allocation per procedure, trigger or function. The exception is for shared buffers that are imported (e.g. DEFINE SHARED BUFFER b FOR customer) rather than allocated locally. In this case, there is only ever a single scope for this buffer and that scope is set to the external procedure. Access to the shared buffer is imported once and is accessible for the lifetime of the procedure. In the cases of NEW SHARED and NEW GLOBAL SHARED buffers, these do cause a memory allocation and they can have multiple scopes just as any other explicit buffer or as the implicit buffers.
Buffer parameters (DEFINE PARAMETER BUFFER bufname FOR table for procedures and (BUFFER bufname FOR table) for functions) cause the resulting buffer:
All field data types are created as token types (there is an imaginary token range) for these. The lvalue rule pulls all possible matches in and has init logic to convert DB_SYMBOL and optionally other symbols (SYMBOL or any unreserved keyword) if they don't match a variable name. The token type is rewritten to one of the valid field types on a match.
There are corresponding rules to match tables (see record) and database names. These rewrite the token types as necessary. At this time, in those places (subrules) where indexes or sequences appear, we implement the symbol rule and after it returns we set the type to INDEX or SEQUENCE respectively.
The SymbolResolver class provides database/table/field symbol lookup against the SchemaDictionary class.
At this time, the following features are not yet implemented:
The following blocks exist in Progress 4GL:
The current parser implements block support for all of the above.
The following flowchart depicts the high level logical flow of the parser. It is this flow that recognizes and enables the block structuring of the resulting tree.
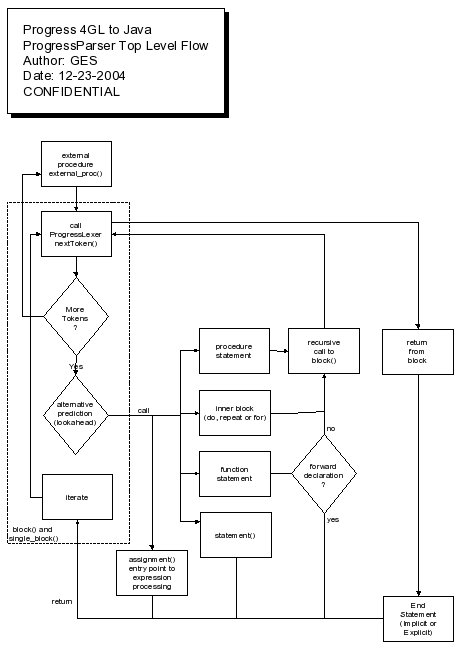
Please see the following for more details:
We handle all numeric data types the same since Progress 4GL "auto-casts" integers into decimals (and vice versa) as needed. Any mixed decimal and integer operations generate a decimal internally. If this is ultimately assigned to an integer, it appears that this conversion is not done until the assignment occurs, which would eliminate rounding errors during the expression evaluation. This seems to be true based on the set of testcases run at this time, but we will need to watch for any deviations from this in practice.
Assignments cannot be made inside an expression. If an lvalue is followed by the EQUALS token, the EQUALS is considered an assignment operator, otherwise the operator is considered a relational operator (equivalence).
The base date for Progress 4GL is 12/31/-4714.
Operator precedence is as follows (in ascending order from lowest to highest):
There are some special built-in functions like IF THEN ELSE which do not follow the generic function call format. For this reason they are implemented as an alternative in a primary expression (see ProgressParser primary-expr()). An example of this can be seen in the ProgressParser if_func() which is the implementation of the IF THEN ELSE.
The only data types that have literal representations are CHARACTER, INTEGER, DECIMAL, LOGICAL and DATE.
Generic support for widget attribute and method references has been added into the ProgressParser primary-expr() rule.
At this time, the P2J parser grammar does not implement operand type checking. This is not feasible to implement using the structure of the grammar itself, however it could be implemented via semantic predicates at some point in the future. Note that the base assumption of this project, that the input files are valid Progress 4GL code makes this somewhat unnecessary. To implement the checks later, use the following list of valid operator/operand combinations based on operand data type:
For more details, see:
Functions
Progress has a wide range of built-in functions. These functions
can support two features that user-defined functions cannot support:
A special return type FUNC_POLY has been created to identify those functions that can implement polymorphic return types.
The function support properly handles the forward declaration form of the FUNCTION statement. This adds the function to the namespace but does not include the defining block that is callable. The block structure of the program is properly maintained in both the forward and normal cases.
The following is the list of supported built-in functions.
ProgressParser function()
ProgressParser func_stmt()
ProgressParser func_call()
ProgressParser reserved_functions()
SymbolResolver lookupFunction()
ProgressParser lvalue()
ProgressParser reserved_variables()
SymbolResolver lookupVariable()
How to Add Keywords:
This interface provides the ability to handle the following:
For the purposes of the rest of this document, it is assumed that all AST nodes are of type AnnotatedAst, even when references as an AST.
For more details, see:
Aast
AnnotatedAst
This multi-step process must be handled in a very specific way and is complex enough that it is best done in a single location. The AstGenerator class provides this service. In addition to managing the generation process, it also provides caching/persistence and file output services for each step. For example, the preprocessor output can be cached in a file and reused upon future runs. The following output is possible:
For more details, see:
AstGenerator
ScanDriver
The AstPersister provides read and write persistence services. It is aware of how to persist an AnnotatedAst including all Aast specific data such as IDs and annotations. The resulting file is an XML file for which the grammar is known only in this class.
For more details, see:
AstPersister
To make such references unique across the project, a registry of files is used. Each file (Progress source or Java target) in the project gets a unique 32-bit integer ID. This ID can be converted into a filename found via the registry. In addition, each node in an AST gets a unique Long ID that is a combination of this file ID (in the upper 32-bits) and an AST-unique node ID (in the lower 32-bits). This long value is persisted into the XML file and is read back in each time the XML file is reloaded. This allows specific AST nodes to be referenced using a single Long value. The AST and the specific node in question can be found, loaded and accessed with nothing more than this Long ID.
The AstRegistry is the core of this implementation.
For more details, see:
AstRegistry
statement [STATEMENT] @0:0
if [KW_IF] @38:1
expression [EXPRESSION] @0:0
if [FUNC_POLY] @38:4
> [GT] @38:9
x [VAR_INT] @38:7
y [VAR_INT] @38:11
then [KW_THEN] @38:13
true [BOOL_TRUE] @38:18
else [KW_ELSE] @38:23
no [BOOL_FALSE] @38:28
then [KW_THEN] @38:31
inner block [INNER_BLOCK] @0:0
do [KW_DO] @39:1
block [BLOCK] @0:0
statement [STATEMENT] @0:0
message [KW_MSG] @40:4
expression [EXPRESSION] @0:0
"then part of if block" [STRING] @40:12
else [KW_ELSE] @42:1
statement [STATEMENT] @0:0
message [KW_MSG] @43:4
expression [EXPRESSION] @0:0
"else part of if block" [STRING] @43:12
Note that the indention level indicates the parent/child relationships. Each line is a different AST node and the file is ordered from the root node to the last child in a depth-first, left-to-right tree walk. The leftmost text on each line is the original text from the source file, the next text (in square brackets) is the symbolic name of the token type and the @x:y is a notation for line number and column number respectively (in the source file). Any entry that has a @0:0 is an artificially created token by the parser which was created to organize the tree for easier processing or searching.
For more details, see:
DumpTree
Call Tree Processing
The table is split into 3 types of entries: invocations, entry points and event processing exits. An invocation is mechanism by which an external linkage is called. An entry point is an exposed target for external linkage which is accessed via an invocation mechanism. An event processing exit is not an entry point and doesn't directly invoke another piece of code but they indirectly allow event code to be called by stopping the normal procedural flow and allowing queued events to be dispatched.
All entries listed as "external file linkage" refer to the fact that these linkages can invoke logic in or be invoked by a separate Progress procedure or a non-Progress executable (e.g. DLL, DDE, external command). This is different from the use of "external control flow" referenced above.
The list of root nodes is prepared manually based on the conversation with the customer and source code review.
There are two possible scenarios. In simple case customer does know all actually used root nodes (main modules) in the application. But for application with a long history of development this is unlikely. They may have unused files which may look like standalone utilities, abandoned ad-hoc procedures and utilities, development-time and test applications. All of them are redundant and should not be included in the list of root nodes. In this case other process is used.
The process of finding root nodes is iterative. Initially potential root nodes are found by review of application sources. The resulting list of root nodes is passed to the call graph generator and resulting call graphs and dead file list provide more information which allows to adjust list of root nodes which is again passed to the call graph generator. When list of root nodes is more or less sustained then it is discussed with the customer in order to determine which root nodes are actually necessary and which are not.
For more details, see:
In order to build the call tree graph, the analysis of the invocation of external modules (files) is performed. The analysis performed in the following way: starting from the the AST of the root node (file), each AST is loaded and scanned in order to determine which external files are invoked by the program. All found files are added into the appropriate node of the call graph as immediate child nodes. If any of these files are not processed, then they are added into the queue of the files which need to be processed. Then processing is repeated for all files in the queue.
Note that the methodology for this analysis is completely based on the list of "root nodes" or "primary entry points" to the application. If the the rootlist.xml (which defines these) is incorrect then the call graphs will be incorrect. The root list may include an entry point which is not actually used or is not part of the application being converted. In this "false positive" case, there will be call graphs generated that are not to be converted. The root list may also be missing an entry point that is used and if so then all files accessible only from such entry points will inappropriately appear in the dead file list.
The analysis of the AST is not as obvious as it may appear. The problem is hidden in the possibilities provided by the language and actively used in the application. In particular, the RUN statement allows calling a file whose name is stored in the variable or which is generated using any expression that returns a character value. The actual value of the variable can be calculated at run time or retrieved from the table. In some cases the variable is shared and assigned in a number of places through the entire application. Invocation is performed by assigning a value to the variable and calling another file which invokes the requested procedure. This case is most complicated because the actual RUN statement invocation and the procedure which is logically the caller are located in different source files.
Another difficult case is the dynamic writing of a Progress source file (at runtime) and then the subsequent invocation of the generated file. This itself is difficult to detect but is made more complicated by the fact that the generated file may call other application files.
Since some forms of external program invocations are not "direct", these expressions can (and usually do) reference runtime data or database fields, the filename often cannot be derived from inspection of the source code. In each instance of this, a hint for that source file is encoded to "patch" the call graph at these points. XML elements are prepared which contain possible values of the variable for each RUN VALUE() statement an associated program file. These hints are stored in a file named using the source filename (including full path) and then adding a ".hints" suffix. These values are then loaded during processing and handled as if they were collected from the AST. Hints files are prepared manually, as a result of analyzing application code, execution paths and real data extracted from the tables.
The call graph is stored as an XML file. The nesting of the XML elements shows the relationship of caller (parent) to called (child). The order of children is the order of the calls. At this time, the call graphs do not represent any duplicate calls or recursive calls. This means that only the first instance of any given file is represented in a call graph. No matter how many times a particular procedure is invoked it will only appear in the graph one time.
All nodes in the call graph are external procedures (Progress .p or .w source files) that are accessible from a particular root entry point. It only reflects the *external* files invoked, internal procedure/function linkage is not reflected. This is by design because these call graphs are essentially lists of ASTs to process (and the order in which the ASTs will be processed). An AST is equivalent to a file. Please note that due to the preprocessing approach of Progress, include files are not necessarily valid source files. All ASTs are created after preprocessing, so the contents of the include files are already embedded/expanded inline. While each file does have a record (a preprocessor hints file that is left behind as an output of the preprocessing step) of exactly which include files were referenced, no include file is represented directly in the call graph itself. Only source files (normally named .p or .w) are represented.
Although many applications make heavy use of execution of operating system specific external processes (e.g. shell scripts, native utility programs), this is not a consideration in terms of generating a call graph of accessible Progress 4GL procedures.
All duplication has been removed from the graph, which transforms the graph into a tree. This is done to make it easy to persist to XML, to make it easy to process and because once an AST is processed it doesn't need to be processed again. In other words, this simplification does not cause any limitations, it only makes things easier.
To create a call graph, the ASTs are walked starting at a root entry point and an in-memory graph is built. The processing dynamically takes into account any added graph nodes as they are added. So the graph continually grows until all ASTs that can be reached are included. The processing of each AST is performed by the Pattern Engine which applies specially designed rule set. The Pattern Engine is started by the specially designed driver CallGraphGenerator.
The rule set in combination with specially designed worker class performs the main part of the processing: it recognizes patterns in the ASTs which represent various invocation methods. The methods provided by the worker class are used to add files not the node and maintain list of ASTs which are processed and waiting for the processing. The rule set consist of two main parts: rules which recognize standard expressions and rules which recognize application-specific patterns. It must be noted that some statements are recognized but no actual processing (adding nodes) is performed. The purpose of these rules is to generate log entries which can be used to detect potential problems during further processing.
The worker class names CallGraphWorker serves following purposes:
The node with file name "./path/root.p" represents root node of the sample call graph. Nodes with file names "./path/referenced1.p" and "./path/referenced2.p" represent files directly called by the code in the "./path/root.p". Files "./path/referenced1_1.p" and "./path/referenced1_2.p" are directly called by "./path/referenced1.p" and so on.
The main Pattern Engine configuration for the call graph generator are located in the generate_call_graph.xml and in a set of .rules files which contain actual rules grouped by the purpose. The set of .rules files includes invocation_reports.rules, run_generated.rules, run_statements.rules and customer_specific_call_graph.rules. First three files contain common rules, while last one contains rules specific for the particular environment.
For more details, see:
If a file appears in any of the call graphs (.ast.graph files), it won't appear in the dead files list and vice versa. The dead files list also identifies include files that are completely unreferenced (in live code).
Any of the dead files may be referenced in other dead code somewhere (either a dead include file or a dead .p or .w file) but they are still inaccessible. At this time there may be (logically) inaccessible code in "live" files and at this time the call graph processing doesn't take such things into account. So if such code adds files to the call graph, they will be treated as "live".
The generation of the dead files list is performed in following way. At startup call graph generator scans entire sources tree and collects all application files. Then, when generator scans AST files, each scanned file is marked as "live" (referenced) in the list of all application files. Also, for each scanned AST file preprocessor hints file is loaded and list of include files is retrieved. All include files also marked as referenced in the list of all application files. When generator finishes scanning of AST files, list of all application files contains all referenced files marked as "live". Files which are not marked a live then printed in resulting report. Since each root node calls only subset of all really used files, correct list can be obtained only after building call graphs for all root nodes. Otherwise some files which are referenced only from one root node will be incorrectly reported as "dead".
For more details, see CallGraphWorker.
| Author(s) |
Greg Shah Sergey Yevtushenko |
| Date |
April 8,
2005 |
| Access Control |
CONFIDENTIAL |
Contents
IntroductionLexical Analyzer and Parser
Primer
Progress 4GL Lexical Analyzer and Parser
4GL Unified Abstract Syntax Tree
Package Class HierarchyProgress 4GL Lexical Analyzer and Parser
4GL Unified Abstract Syntax Tree
Lexer
Parser
Data Type
Support
Symbol Resolution
Schema Names
Block Structuring
Expression Processing
Functions
Known Limitations
Implementation Guide
AST SupportSymbol Resolution
Schema Names
Block Structuring
Expression Processing
Functions
Known Limitations
Implementation Guide
Call Tree
Introduction
Lexical Analyzer and Parser Primer
The term "lexical analyzer" refers to software that can read an input stream of characters (a text file) and based on its knowledge of what the contents should contain (Progress 4GL source code), it will break up the stream into a sequential list of meaningful (Progress 4GL-specific) tokens. These tokens are the smallest meaningful grouping of characters in the input stream. Often a token is the same thing as a word (a grouping of characters delimited by white space and/or language specific delimiters/line termination characters). However, depending on the language definition it may be a single character (e.g. the Progress 4GL language statement end delimiter character is a period '.') or a grouping of characters that includes some white space (e.g. a traditional string literal such as "All work and no play makes Jack a dull boy."). The term lexical analyzer could be replaced with "smart tokenizer" though traditional computer science prefers to obscure the concept. A common shorthand for referring to a lexical analyzer is to call it a lexer.The term "parser" refers to software that takes the stream of meaningful tokens (provided by the lexer) and performs a syntax analysis of the contents based on its knowledge of the source language. The result of running a parser is a determination of the syntactical correctness of the input stream and a list of the language "sentences" that comprise the source. In other words, while the lexical analyzer operates on the input stream to create a sequential list of the valid tokens, the parser reassembles these tokens back into "sentences" that have meaning that can be evaluated or executed.
To illustrate, if our source file contains the following Progress 4GL source code:
/* this is a
sample program */
MESSAGE
"Hello World!".
Then the lexical analyzer might (the exact output depends on the exact implementation) generate the following list:
/* this is a sample program */
MESSAGE
"Hello World!"
.
You can see that white space (spaces, tabs, new lines) has been removed. Each token is an atomic entity that can be considered on its own or as a part of a larger language specific "sentence" that can be evaluated.
The parser would take this list and piece things back together into a list of sentences that are syntactically correct and are meaningful for evaluation. This is the flat view of the result (a "degenerate tree"):
/* this is a sample program */
MESSAGE "Hello World!".
Typically, these resulting sentences will be provided in a tree structure, sometimes called an intermediate form representation or an abstract syntax tree (AST). The resulting tree might look something like the following:
external_program
|
+--- comment (/* this is a sample program */)
|
+--- statement
|
+--- keyword_message (MESSAGE)
|
+--- string_expression ("Hello World!")
|
+--- dot (.)
Note that the parenthesized text is the original text from the source file. Each tree node is artificially manufactured, having a specific defined "token type" which can be referenced in code that walks the tree.
Client code that uses the output of the parser can walk the tree and inspect, analyze, interpret, transform or convert it as necessary. For example, the tree structure naturally puts expressions in RPN (reverse polish notation), otherwise known as postfix notation. This is required to properly evaluate the expression (and generate results with the correct precedence). This is significantly easier than the interpretation or evaluation of expressions using the human-readable infix notation.
Progress 4GL Lexical Analyzer and Parser
Multiple components of the P2J conversion tools will need the ability to process Progress 4GL source code. To do this in a standard way, a Progress 4GL-aware lexical analyzer and parser is provided.By using a common lexical analyzer and parser, the tricky details of the Progress 4GL language syntax can be centralized and solved properly in one location. Once handled properly, all other elements of the conversion tools can rely upon this service and focus on their specific purpose.
Parser and lexer generators have reached a maturity level that can easily create results to meet the requirements of this project. This creates a savings of considerable development time while generating results that have a structure and level of performance that meets or exceeds the hand-coded approach.
In a generated approach, it is important to ensure that the resulting code is unencumbered from a license perspective.
The current approach is to use a project called ANTLR. This is a public domain (it is not copyrighted which eliminates licensing issues) technology that has been in development for over 10 years. It is used in a large number of projects and seems to be quite mature. It is even used by one of the Progress 4GL vendors in a tool to beautify and enhance Progress 4GL source code (Proparse). The approach is to define the Progress 4GL grammar in a modified Extended Backus-Naur Form (EBNF) and then run the ANTLR tools to generate a set of Java class files that encode the language knowledge. These resulting classes provide the lexical analyzer, the parser and also a tree walking facility. One feeds an input stream into these classes and the lexer and parser generate an abstract syntax tree of the results. Analysis and conversion programs then walk this tree of the source code for various purposes. There are multiple different "clients" to the same set of ANTLR generated classes. Each client would implement a different view and usage of the source tree. For example, one client would use this tree to analyze all nodes related to external or internal procedure invocation. Another client would use this tree to analyze all user interface features.
P2J uses ANTLR 2.7.4. This version at a minimum is required to support the token stream rewriting feature which is required for preprocessing.
Some useful references (in the order in which they should be read):
Building Recognizers By Hand
All I know is that I need to build a parser or translator. Give me an overview of what ANTLR does and how I need to approach building things with ANTLR
An Introduction To ANTLR
BNF and EBNF: What are they and how do they work?
Notations for Context Free Grammars - BNF and EBNF
ANTLR Tutorial (Ashley Mills)
ANTLR 2.7.4 Documentation
EBNF Standard - ISO/IEC 14977 - 1996(E)
Do not confuse BNF or EBNF with Augmented BNF (ABNF). The latter is defined by the IETF as a convenient reference to their own enhanced form of BNF notation which they use in multiple RFCs. The original BNF and the later ISO standard EBNF are very close to the ABNF but they are different "standards".
Golden Code has implemented its own lexical analyzers and parsers before (multiple times). A Java version done for the Java Trace Analyzer (JTA). However, the ANTLR approach has already built a set of general purpose facilities for language recognition and processing. These facilities include the representation of an abstract syntax tree in a form that is easily traversed, read and modified. The resulting tree also includes the ability to reconstitute the exact, original source. These facilities can do the job properly, which makes ANTLR the optimal approach.
The core input to ANTLR is an EBNF grammar (actually the ANTLR syntax is a mixture of EBNF, regular expressions, Java and some ANTLR unique constructs). It is important to note that Progress Software Corp (PSC) uses a BNF format as the basis for their authoritative language parsing/analysis. They even published (a copyrighted) BNF as 2 .h files on the "PEG", a Progress 4GL bulletin board (www.peg.com). In addition, the Proparse grammar (EBNF based and used in ANTLR) can also be found on the web. Thus it is clear that EBNF is sufficient to properly define the Progress 4GL language and that ANTLR is an effective generator for this application. This is the good news.
However, there is a very important point here: the developers have completely avoided even looking at ANY published Progress 4GL grammars so that our hand built grammar is "a clean room implementation" that is 100% owned by Golden Code. The fact that they published these on the Internet does not negate their copyright in the materials, so these have been treated as if they did not exist.
An important implementation choice must be noted here. ANTLR provides a powerful mechanism in its grammar definition. The structure of the input stream (e.g. a Progress 4GL source file) is defined using an EBNF definition. However, the EBNF rules can have arbitrary Java code attached to them. This attached code is called an "action". In the preprocessor, we are deliberately using the action feature to actually implement the preprocessor expansions and modifications. Since these actions are called by the lexer and parser at the time the input is being processed, one essentially is expanding the input directly to output. This usage corresponds to a "filter" concept which is exactly how a preprocessor is normally implemented. This is also valid since the preprocessor and the Progress 4GL language grammars do not have much commonality. Since we are hard coding the preprocessor logic into the grammar, reusing this grammar for other purposes will not be possible. This approach has the advantage of eliminating the complexity, memory footprint and CPU overhead of handling recursive expansions in multiple passes (since everything can be expanded inline in a single pass). The down side to this approach is that the grammar is hard coded to the preprocessor usage and it is more complicated since it includes more than just structure. This makes it harder to maintain because it is not independent of the lexer or parser.
The larger, more complex Progress 4GL grammar is going to be implemented in a very generic manner. Any actions will only be implemented to the extent that is necessary to properly tokenize, parse the content or create a tree with the proper structure. For example, the Progress 4GL language has many ambiguous aspects which require context (and sometimes external input) in order to properly tokenize the source. An example is the use of the period as both a database name qualifier as well as a language statement terminator. In order to determine the use of a particular instance, one must consult a list of valid database names (which is something that is defined in the database schema rather than in the source code itself). Actions will be used to resolve such ambiguity but they will not be used for any of the conversion logic itself. This will allow a generic syntax tree to be generated and then code external to the grammar will operate on this tree (for analysis or conversion). In fact, many different clients of this tree will exist and this allows us to implement a clean separation between the language structure definition and the resulting use of this structure.
The following is a list of the more difficult aspects of the Progress 4GL:
- the ability to recognize arbitrarily shortened language keywords as the full equivalent
- some keywords support abbreviations and there is a minimum abbreviation that is valid (e.g. "define" can be shortened at most to "def")
- an arbitrary abbreviation can be chosen if the keyword supports abbreviations (e.g. def, defi, defin and define are all valid forms of the define keyword)
- if the keyword is not "reserved", then all of these forms can
also be used as valid symbol names (e.g. the keyword variable can be
shortened down to a minimum of var but these same forms can be used as
names because variable is not a reserved keyword)
- see "Keyword Index" on page 1795, Progress 4GL Language
Reference Volume 2 for a list of the keywords, whether they can be
abbreviated, the minimum abbreviation and whether the keyword is
reserved or not
- differentiating the use of the period '.':
- end of statement delimiter
- database table.field qualifier format for specifying a specific column in a table
- decimal point in a decimal constant
- a valid character in a filename (e.g. an include file)
- meaningless usage inside comments or a string literal
- distinguishing between functions and language statements of the same name
- ACCUM function and the ACCUMULATE language statement that can be abbreviated down to ACCUM
- CURRENT-LANGUAGE
- CURRENT-VALUE
- ENTRY
- IF THEN ELSE
- PROPATH
- SUBSTRING
- TERMINAL
- how functions are parenthesized
- MOST functions that have parameters take parenthesis
- MOST functions that take parenthesis, always require them EXCEPT for this list which have forms where parenthesis are optional:
- FRAME-COL
- FRAME-DOWN
- FRAME-LINE
- FRAME-ROW
- LINE-COUNTER
- PAGE-NUMBER
- PAGE-SIZE
- USERID
- these functions are exceptions (they take parameters but do not use parenthesis):
- ACCUM aggregate_phrase expression
- AMBIGUOUS record
- AVAILABLE record
- CURRENT-CHANGED record
- record ENTERED
- record NOT ENTERED
- INPUT field
- LOCKED record
- NEW record
- IF expression THEN expr1 ELSE expr2
- these non-parenthesized parameter exceptions are commonly used in conditional expressions such as the IF function so they are certainly implemented as functions
- special cases that take abnormal parenthesized parameters that aren't expressions
- CAN-FIND
- SUPER (optional parens too!)
- functions with no parameters (e.g. OPSYS, TODAY) never take
parenthesis (in other words, built in functions will never have empty
parenthesis) and often act like global variables (some are read-only
and some can be assigned!)
- CURRENT-LANGUAGE
- DBNAME
- NUM-ALIASES
- NUM-DBS
- OPSYS
- PROGRESS
- PROMSGS
- PROPATH
- PROVERSION
- TERMINAL
- TIME
- TODAY
- user defined functions always take parenthesis even if there are no parameters (empty parenthesis in this case)
- some language statements have function syntax and act like
lvalues (they can be assigned to!)
- CURRENT-VALUE() = expression.
- ENTRY() = expression
- LENGTH() = expression
- OVERLAY() = expression
- PUT-*() = expression
- SET-BYTE-ORDER() = expression
- SET-POINTER-VALUE() = expression
- SET-SIZE() = expression
- SUBSTRING() = expression
- postfixing is sometimes used or allowed in surprising locations
- numeric literals can sometimes have a postfixed negative or
positive sign (as long as there is no intervening whitespace)
- 19-
- 5+
- 2 functions are coded with postfixed function names (and no use of parenthesis!)
- field ENTERED
- field NOT ENTERED
- symbol names can include characters that are also used as operators (e.g. the hyphen is also used as a subtraction operator and as the unary negation operator)
- symbol names must start with alpha characters
- subsequent characters can include numeric digits and the special characters # $ % & - _
- symbol lengths
- the maximum variable name is 32 characters (see page 3-30 of the Progress Programming Handbook)
- external procedure names are limited by the operating system rules as well as some unspecified set of rules where Progress applies a least common denominator approach
- internal procedure names are not bounded by any documented rule, but the Handbook suggests there is a limit
- the keyword richness of the language leads to:
- polymorphic usage of the same language keywords for different meaning depending on which language statement is being processed
- the very large number of language keywords means that many or most of these must be left as unreserved keywords (the user may define symbols that hide these keywords)
- the same symbol may appear in multiple different namespaces in the same procedure, yet these different uses are all properly differentiated
4GL Unified Abstract Syntax Tree
An abstract syntax tree (AST) is a hierarchical data structure which represents the semantically significant elements of a language in a manner that is easily processed by a compiler or interpreter. Such trees can be traversed, inspected and modified. They can be directly interpreted or used to generate machine instructions. In the case of P2J, all Progress 4GL programs will be represented by an AST. The AST associated with a specific source file will be generated by the lexer and parser.Since most Progress 4GL procedures call other Progress 4GL procedures which may reside in separate files, it is important to understand all such linkages. This concept is described as the "call tree". The call tree is defined as the entire set of external and internal procedures (or other blocks of Progress 4GL code such as trigger blocks) that are accessible from any single "root" or application entry point. It is necessary to process an entire Progress 4GL call tree at once during conversion, in order to properly handle inter-procedure linkages (e.g. shared variables or parameters), naming and other dependencies between the procedures.
One can think of these 2 types of trees (abstract syntax trees and the call tree) as 1 larger tree with 2 levels of detail. The call tree can be considered the higher level root and branches of the tree. It defines all the files that hold reachable Progress 4GL code and the structure through which they can be reached. However as each node in the call tree is a Progress 4GL source file, one can represent that node as a Progress 4GL AST. This larger tree is called the "Unified Abstract Syntax Tree" (Unified AST or UAST). Please see the following diagram:
By combining the 2 levels of trees into a single unified tree, the processing of an entire call tree is greatly simplified. The trick is to enable the traversal back and forth between these 2 levels of detail using an artificial linkage. Thus one must be able to traverse from any node in the call tree to its associated Progress 4GL AST (and back again). Likewise one must be able to traverse from AST nodes that invoke other procedures to the associated call tree node (and back).
Note that strictly speaking, when these additional linkage points are added the result is no longer a "tree". However for the sake of simplicity it is called a tree.
This representation also simplifies the identification of overlaps in the tree (via recursion or more generally wherever the same code is reachable from more than 1 location in the tree).
To create this unified tree, the call tree must be generated starting at a known entry point. This call tree will be generated by the "Unified AST Generator" (UAST Generator) whose behavior can be modified by a "Call Tree Hints" file which may fill in part of the call tree in cases where there is no hard coded programmatic link. For example, it is possible to execute a run statement where the target external procedure is specified at runtime in a variable or database field. For this reason, the source code alone is not deterministic and the call tree hints will be required to resolve such gaps.
Note that there will be some methods of making external calls which may be indirect in nature (based on data from the database, calculated or derived from user input). The call tree analyzer may be informed about these indirect calls via the Call Tree Hints file. This is most likely a manually created file to override the default behavior in situations where it doesn't make sense or where the call tree would not be able to properly process what it finds.
The UAST Generator will create the root node in the call tree for a given entry point. Then it will call the lexer/parser to generate a Progress 4GL AST for that associated external procedure (source file). An "artificial linkage" will be made between the root call tree node and its associated AST. It will then walk the AST to find all reachable linkage points to other external procedures. Each external linkage point represents a file/external procedure that is added to the top level call tree and "artificial" linkages are created from the AST to these call tree nodes. Then the process repeats for each of the new files. They each have an AST generated by the lexer/parser and this AST is linked to the file level node. Then additional call tree/file nodes will be added based on this AST (e.g. run statements...) and each one gets its AST added and so on until all reachable code has been added to the Unified AST.
This resulting Unified AST is built based on input that is valid, preprocessed Progress 4GL source code.
Package Class Hierarchy
The following is a high level UML class diagram of the UAST package:For a more detailed diagram, use this link.
{kind=link}
Lexer
The UAST lexer is responsible for converting a valid, preprocessed Progress 4GL source file (as represented by a stream of characters) into a stream of tokens with each token containing:- an integer token type
- the text from the original source file
- the line and column numbers that mark the location of this text
in the source file
One of the more complicated aspects of the lexer is th implementation of language keywords (and their associated abbreviation support). Please see the following reference for why the preprocessor and parser don't implement keyword abbreviation support instead of the lexer.
Some features that may be expected to be implemented in the lexer are actually implemented in the preprocessor. This is done for 2 reasons:
- To match the exact processing of the preprocessor to how the Progress preprocessor does it.
- To implement features that would otherwise have required sharing
of information between the preprocessor and the lexer. For
example, to properly handle the tilde escaping of newlines (embedding a
newline that should not be eaten) the preprocessor handles the dropping
of unescaped newlines inside strings. This is exactly how the
Progress implementation works as far as can be practically confirmed by
preprocessor listing files.
Parser
The Progress 4GL parser is significantly more complex than the lexer. This class is aware of the full depth of the Progress 4GL syntax and by definition it must verbosely implement a rule or rules that map at least one to one for each Progress language statement. Thus there is an order of magnitude difference in size and complexity between the lexer and the parser.The primary job of the parser is to take the token stream (represented by the Lexer) and match that with the proper sets of rules that converts the flat stream of tokens into a 2 dimensional tree (AST). In addition, there are many ambiguities of the Progress language that could not be resolved at the lexer level since the solution requires knowledge of the parser's context. Due to issues in how the generated code handles lookahead, it is not feasible to share state between the lexer and parser (thus providing feedback to the lexer at the time that the token is created). Instead the parser must rewrite the tokens based on its context. Please see the ProgressLexer overview for more details.
The following sections describe the most critical issues facing the parser. At the end of each subsection is a list of links that should be reviewed to obtain more details. At the end is the implementation plan for the completion of the ProgressParser. Please see this link for a top-level overview of the parser.
Data Type Support
| Type
Name |
Supported
In P2J |
AS
clause abbreviation |
Documented
Abbreviation |
Reserved
Keyword |
Comments |
| character |
Y |
c |
char |
no |
a string --> there is no representation of a single character that is not a string |
| com-handle |
N |
com-handle |
no |
only used on Windows for
Active-X or COM objects |
|
| date |
Y |
da |
no |
||
| decimal |
Y |
de |
dec |
no |
a floating point number |
| handle |
Y |
handle |
no |
||
| integer |
Y |
i |
int |
no |
|
| logical |
Y |
l |
no |
||
| memptr |
Y |
m |
n/a |
no |
this is an undocumented keyword
(not in the keyword index) |
| raw |
Y |
ra |
no |
||
| recid |
Y |
re |
yes |
||
| rowid |
Y |
row |
yes |
||
| widget-handle |
Y |
widg |
widget-h |
no |
Data type support is primarily a function of providing the correct token types for each data type and resolving lvalues (variables and fields form the schema) and function calls to the correct data types. This enables expressions, assignments and other data type specific parsing to occur.
Special abbreviation processing is implemented in the processing of the AS clause since the documented abbreviations (or lack thereof) are not followed in this case. See the table above for the real minimum abbreviations of the data type names.
Variable and field types can optionally be specified as single dimensional arrays (multi-dimensional arrays are not supported in Progress 4GL). The syntax for specifying an array relies upon the use of the EXTENT keyword in a DEFINE VARIABLE statement or in the data dictionary. When defining variables, the INITIAL keyword can be used to with the [,,,] array initializer syntax to provide a list of initial values. If there are fewer values than array elements, then the last value is used to initialize into all remaining uninitialized array elements. In addition the LABEL keyword can be used with the <string>, <string>... syntax to provide separate labels for each element in an array.
To reference an array element, the [ integer_expression ] syntax is used (contrary to some of the documentation, it does not need to be an integer constant). Whitespace can be placed before the opening left bracket or anywhere inside the brackets. The lvalue rule makes an optional (zero or one) rule reference to the subscript rule. An example reference might be hello[ i + 3 ] where i is an integer variable that holds a value that is positive and less than the array size - 2. All Progress array indices are 1 based (the first element is referenced as array[1]).
The subscript rule implements the subscripting syntax. This subscript rule also implements the range subscripting support using the FOR keyword and a following integer constant to specify the ending point to the integer expression's starting point (e.g. hello[1 for 4] references the first 4 elements of the hello array).
Method and attribute support has been added to the lvalue rule. It is tightly bound to variable and field references and can be optionally present in many locations. At this time, the support is highly generic (the correct resulting data types are not determined).
For more details, see:
- ProgressParser symbol()
- ProgressParser lvalue()
- ProgressParser subscript()
- ProgressParser def_var_stmt()
- ProgressParser as_clause()
- ProgressParser func_call()
- ProgressParser
func_stmt()
Symbol Resolution
There are a wide range of symbols in the Progress 4GL. At a high level, symbols can be considered as 2 broad categories: built-in or user-defined.A built-in is a symbol defined by the Progress language as a set of keywords that represent language statements, functions, widgets, methods and attributes. These keywords can be either reserved or unreserved. In addition, some keywords can be arbitrarily abbreviated down to any number of characters limited by some minimum number. For example, the DEFINE keyword can be shortened to DEFIN, DEFI, or DEF. Not all keywords can be abbreviated. There are examples of both reserved and unreserved keywords supporting abbreviations.
A user-defined symbol is a programmer created name for some application-specific Progress construct that the programmer has created. The symbol naming in this case is quite flexible. Names can be up to 32 characters long, must start with an alphabetic letter and can then contain any alphanumeric character as well as the characters # $ % & - or _. Reserved keywords cannot be used as user-defined symbols, while unreserved keywords can. Keywords referring to entities of like type will be hidden by a user-defined symbol of that type. For example, it is possible to hide certain built-in functions with a user-defined function of the same name. Once defined in a given scope, the original Progress resource that is hidden cannot be accessed.
Types of Symbols:
| Symbol Type |
Namespace |
Scoping Support |
Abbreviation Support |
Notes |
| language keywords | unique |
no |
yes |
Also handles reserved/unreserved
processing. In the P2J implementation this is mostly a feature of
the lexer. |
| variables (global shared, scoped shared and local) | overlapping with database fields, shared with widgets |
yes |
no |
This implementation actually
splits this namespace from that of widgets although in Progress they
are the same namespace. This was done to keep the implementation
simple (no complex, multi-level lookups are needed). |
| database fields | overlapping with variables |
yes |
yes |
See Schema
Names section for details. |
| procedures | shared with functions |
no (cannot be nested) | no |
In the current implementation of
the parser this is a separate namespace, however it should have no
negative effects due to the assumption that only correct Progress 4GL
source files will be processed. |
| functions | shared with procedures |
no (cannot be nested) |
built-in - yes user-defined - no |
In the current implementation of the parser this is a separate namespace, however it should have no negative effects due to the assumption that only correct Progress 4GL source files will be processed. |
| classes, interfaces, enums (user-defined OO) | unique |
TBD | TBD | |
| methods (user-defined OO) | unique |
TBD | TBD | |
| member variables and data members (user-defined OO) | unique |
TBD | TBD | |
| labels |
unique |
yes |
no |
|
| triggers | no |
no |
no |
Triggers are not named and have
no namespace implications. |
| databases | shared with aliases |
no |
no |
|
| aliases | shared with databases |
no |
no |
|
| tables | shared with buffers, temp-tables
and work-tables |
yes |
yes |
|
| indices |
TBD | TBD | TBD | |
| sequences |
TBD | TBD | TBD | |
| buffers | shared with tables, temp-tables and work-tables | yes |
no |
|
| widgets | shared with variables |
yes |
no |
includes browse, button,
combo-box,
editor, fill-ins, literal, radio-set, selection-list, slider, text,
toggle-box This implementation actually splits this namespace from that of variables although in Progress they are the same namespace. This was done to keep the implementation simple (no complex, multi-level lookups are needed). |
| frames, dialogs |
unique |
yes |
no |
Frames can't be named the same
as an existing browse widget that is in scope, even though they DON'T
share the same namespace! Perhaps this is due to an implicit frame created for the browse, but not externally exposed? Windows can't be named so they are not in this list. |
| menus, sub-menus | unique |
TBD |
TBD |
|
| menu-items |
unique |
TBD |
TBD |
|
| queries | unique |
TBD | TBD | |
| datasets | unique |
TBD | TBD | |
| data-sources | unique |
TBD | TBD | |
| streams | unique |
scoped to the procedure |
no |
|
| temp-tables |
shared with buffers, tables and work-tables | yes |
TBD | |
| work-tables (workfiles) | shared with buffers, temp-tables and tables | yes |
TBD |
Each of these types of symbol must be stored in a namespace. That namespace may contain more than one symbol type, or may be unique to a specific type of symbol.
Each namespace is populated with a new symbol name when the associated entity is defined or (in some cases) declared. Once a name is added to the namespace, it can be used in other source code references as long as the namespace is visible to that code. For example, "define variable" statements must always precede all references to the defined symbol.
Some namespaces are flat and some are scoped. A flat namespace is one in which the same names are visible no matter the context from which a namespace query originates. A scoped namespace is essentially a cooperating stack of namespaces, where a new namespace is added to the top of the stack at the start of a new scope and that top of stack namespace is removed at the end of the scope. Lookups start at the top of the stack and work down the stack until the first matching name is found. This scoped approach allows for symbol hiding where names in one scope can be the same as a name in a different scope, but only the instance that is in the closest scope to the top is what is found.
Local symbols generally hide shared scoped/shared global variables. Local symbols in an internal procedure will hide the same names in an external procedure.
Symbol namespaces are different by type of symbol. There is no unified namespace. One of the implications is that functions and variables of the same name must be differentiated (by context) and cannot hide each other.
Built-in functions and language statements of the same name are differentiated in the parser by context. There is no simple rule for detecting this based on syntax alone since there are many Progress built-in functions that do not take parenthesis (when they have no argument list) and likewise there are language statements that can be followed by a parenthesized expression that would appear syntactically like a function (there can be whitespace between function names and the parenthesized parameter list).
User functions and user variables are differentiated by the presence or absence of (). There is never a valid expression that has an lvalue followed immediately by ( ).
Only internal procedures, functions and triggers add scoping levels for variables. Other types of blocks are scoped to the external procedure level, which is the same as saying that any defined variables inside non-procedure blocks (DO, REPEAT, FOR...) are scoped at the same level as global variables from the external procedure's perspective.
Symbol resolution is the process by which a reference to a particular symbol type is queried from the corresponding namespace. The lookup occurs at the point in the parsing at which the reference is made. This lookup may return critical information that is the associated with the node being built in the AST for that reference. For example, when variable references are found in a namespace, the query returns a token type that is assigned to that tree node (e.g. the token type for the node is converted from a generic SYMBOL to a token type that matches the specific variable data type such as VAR_INT).
The SymbolResolver class encapsulates the various namespaces (a.k.a. dictionaries) that are in use. It provides maintenance and lookup services to the lexer and parser. Lookups are inserted at key locations in the parser. In these locations, the token type of the symbol is usually rewritten. This allows the parser's context to drive the decision on which namespace to use and how to interpret the symbol. This is critical since there is no unified namespace.
One unique namespace is that for language keywords. These are the only symbols that do not require an exact match but instead can be abbreviated. This special namespace is implemented by Keyword and the KeywordDictionary classes. This namespace is shared between the lexer and the parser since the keyword lookup is first done by the lexer's mSYMBOL method. To keep the implementation of the parser and also the preprocessor to the simplest implementation, the lexer is the optimal location for this function. Since the preprocessor is implemented with a minimum of knowledge of the Progress language, to handle the abbreviations there would add significantly more complexity (especially since there is a mixture of reserved and and unreserved keywords). The keyword processing cannot be completely put in the parser because the Progress language is so keyword rich that the parser must already see the tokens as language keywords from the topmost parser entry point (all the way down as it recursively descends the tree). The parser then aggregates the language statements back together based on already knowing exactly which keyword has been found. In other words, the lexer will assign a token type to each token found. This token type is what the parser keys off of in determining how to group the tokens into language statements.
Keeping the abbreviations out of the preprocessor has the advantage of exactly duplicating the Progress preprocessor output (which doesn't expand the abbreviations). This is important to be able to test and prove that the preprocessor is 100% correct/compatible.
For more details, see:
- ProgressLexer
mSYMBOL()
- ProgressParser symbol()
- ProgressParser lvalue()
- ProgressParser def_var_stmt()
- ProgressParser as_clause()
- ProgressParser
like_clause()
- ProgressParser func_call()
- ProgressParser func_stmt()
- ProgressParser proc_stmt()
- ProgressParser filename()
- ProgressParser widget()
- SymbolResolver
Schema Names
While schema name processing is really part of the larger problem of symbol resolution, it is complex enough on its own that it deserves a separate section in this document.Schema names refer to the following schema entities:
- database
- table (also often referred to as a "record")
- field
- index
- sequence
database1 -> table1 ---> field1
-> table2 ---> field1
|
+-> field2
database2 -> table2 ---> field1
-> table3 ---> field1
|
+-> field2
Resolving Ambiguity
All connected databases contribute to the namespace and can be referenced directly. Within a specific part of the tree (at any containing level such as within a single database or within a single table) each contained name must be unique. But between databases and tables, the contained names can be the same (the text is an exact match) because they live in separate parts of the tree. This is a cause of ambiguity when it is not clear which part of the tree is being referenced, such that multiple matches can be made to the same lookup. This means that there can be inherent ambiguity between:
- table names in different databases
- field names in different tables
- table names and field names (a field can be named the same name as the containing table or non-containing table names in the same database or different databases)
- database names and table names (a table can be named the same
name as the containing database or non-containing database names)
Such ambiguities are resolved by the following:
- Explicitly qualifying (partially or fully) table and field names such that the section of the tree being searched is reduced. The syntax for such qualifications is to use a '.' character between each part of the name. Thus the following combinations are possible:
- database names are always "unqualified":
- database
- table names can be unqualified or fully qualified:
- table
- database.table
- field names can be unqualified, partially qualified or fully qualified:
- field
- table.field
- database.table.field
- Between different types of names (tables/fields or databases/tables):
- Context can be used to resolve some ambiguity. If the usage of a name is expected to be a table, then a match will be attempted with this first.
- If the ambiguity is based on a partially qualified name, then
search order determines the result. A match with database.table
is tried first, then table.field next.
- Progress creates a record scope upon first creation of a record
buffer in which table data can be actively stored and
dereferenced. This scope typically lasts until the end of the
containing block, yet it can also be enlarged to include enclosing
blocks under certain circumstances. While this scope is in
effect, the lookup of unqualified field names is done against the list
of tables in scope before the name is resolved against the rest of the
tables in the connected databases. This allows field names that
would normally be ambiguous (when assessed against all other field
names in the connected databases) to be made unambiguous in the case
where only a small subset of the tables is in scope to be searched.
The schema namespace is something that is predefined at the start of a procedure. This is due to the Progress requirement that all databases to be used by a procedure must be connected at the time of compilation. This means that the database connection (using the CONNECT statement) must be done using command line arguments when starting Progress, must be manually done in the Data Dictionary before running a procedure or must be programmatically done before running a specific procedure that is dependent upon such a connected database. At the start of a Progress procedure, the schema namespace is defined based on all database, table, field, index and sequence names available in the schemas of all connected databases. To mimic this, the P2J parser will need the same information as extracted from the schema during the schema conversion of all schemas that are in use. In addition, the parser will need to know the names of all connected databases. Both of these features will be provided by the SchemaDictionary class in the schema package. This class will use a persistent configuration file or set of files to obtain this information and the SymbolResolver will hide the instantiation and usage of this class from the parser.
Since these schema names are all known before the procedure runs, there are no preceding language statements that allow us to populate the dictionary as the parsing occurs. Instead, such names can be referenced at any time. This is different than how variables work. All variables that can be accessed by a procedure must have a corresponding "define variable", "define parameter" or "parameter clause" that adds the associated name and type to the variable dictionary. In lookups, this variable dictionary has precedence over the schema dictionary since a variable of the same name as an unqualified field will hide the field (one cannot refer to the field without more explicitly qualifying it).
Lexer Support
In order to handle partially or fully qualified names, the lexer was made aware of how to tokenize such symbols. This dramatically reduces the effort since the parser would have to lookahead up to 5 tokens:
symbol_or_unreserved_keyword DOT symbol_or_unreserved_keyword DOT symbol_or_unreserved_keyword
Once a match was found, these tokens would have to be combined into a single token. The logic would be very complicated when one considers that this could be needed for tables or fields. It is made even more complicated by the fact that whitespace is lost in the lexer but is relevant to the resolution of which tokens should be combined into a single resulting token. Implementing this in the lexer is a necessity.
To handle qualified names in the lexer, the mSYMBOL rule was modified. This rule is inherently greedy, which is how Progress works as well. This means that Progress will match the largest possible qualified name that is specified and then do a lookup. A non-greedy approach would try a lookup on the first possible name and then extend the symbol to include any DOT and additional symbol, try the lookup again and so on until a match was found. Other critical assumptions are required to implement this rule:
- There can be no whitespace inside any qualified symbol
name. Encountering any whitespace (or non-symbol, non-DOT chars)
ends the match. See the rules on symbol
naming for more details.
- Only DOTs that are followed by an alpha character are valid
qualifiers. This allows for a symbol followed by a DOT and
whitespace (which is used as an end of statement delimiter) to be left
as 2 tokens rather than combined. All symbols must start with
alpha characters (numbers and the special chars need not apply), so if
the character is not an alpha character there is no symbol following
the DOT and thus the DOT is not to be matched as part of a qualified
symbol.
Of course, the matching is limited to 3 part qualified names (separated by 2 DOTs) so the 3rd dot can will always signal the end of the qualified name even without intervening whitespace.
Once a qualified schema name is matched, the token type is set to DB_SYMBOL. Normal keyword lookup is bypassed for such tokens as we have not found any keyword using a DOT character, nor can we use even a reserved keyword as the start of a new statement without intervening whitespace. This means that we know that this is a database symbol and can set it to this generic type to be resolved later in the parser. Of course, unqualified database/table/field names will not be detected as a database symbol and so these will be tokenized as a SYMBOL or as a keyword if there is a match during keyword lookup. The parser handles the conversion of all of these generic forms into the proper data types (e.g. FIELD_INT, FIELD_CHAR...) based on context.
Matching Logic
Complicating the schema name resolution is the Progress feature that some schema names can be arbitrarily abbreviated. Field names and table names in particular can be abbreviated to the shorted unique sequence of leftmost characters that unambiguously match a single entry in the namespace being searched.
All lookups (fields/tables/databases) are done on a case-insensitive basis, just like all other Progress symbols.
Taking this into account, the following are the matching processes:
Database names are looked up using a single level, exact match search of the connected databases. A Progress 4GL compiler error would occur if the name being search for does not exist in this list. No abbreviations or qualifiers are in effect during this search.
Table names are looked up with a 4 step process:
- There are 2 possible forms of input: fully qualified (database.table) and unqualified (table). The database and table names are split if it is a qualified name. The database name is used in step 2. The unqualified table name result is what is used in steps 3 and 4.
- If there is a database qualifier, this will be used to reduce the
namespace being searched for a match. This effectively means that
the list of tables to search is reduced to the subset defined for the
specified database (this only matters if there are multiple databases
connected). This optional database qualifier can't be abbreviated
and must be an exact match. This is effectively the same search
as the database name search listed
above. After this step, the namespace will be the list of tables
in the specified database or the list of tables in all connected
databases if the input name was unqualified.
- Within the selected namespace, if the table name submitted is an
exact match for a table name then that match is the one chosen.
- If no exact match is found, then the name is used as an
abbreviation and there will be only one name in the selected namespace
that will begin with this specific sequence. The list of tables
are searched for the single unambiguous table name that is uniquely
begun by the abbreviated search name. Because of the order of
these searches, an exact match overrides any possible matches for the
same name when tested as an abbreviation. Note that the
abbreviation MUST uniquely match a table name in the selected namespace
(step 2). If this is not the case, Progress would signal a
compile error.
- There are 3 possible forms of input: fully qualified (database.table.field),
partially qualified (table.field)
and unqualified (field).
If the name is partially or fully qualified, the database.table (or just the table portion if only partially
qualified) is split from the field name. The table name is used
in step 2. The field name is used in steps 3-4.
- Namespace Reduction
- The namespace starts with all field names that are unique
across all tables in all connected databases. This is the most
general reduction, where all field names from all tables in all
databases are reduced to that set that represents the unambiguous or
unique matches. All entries that are duplicated are removed such
that no match would occur if that name were searched for using an
unqualified name. If no other namespace reduction occurs, this is
the list that will be searched in steps 3-4.
- If there is a database.table and/or a table qualifier, this
will be used to reduce the namespace being searched for a match.
The table name search listed above is
used to find the unabbreviated fully qualified table being
specified. It is important to note that in the input name, the
table name portion can be abbreviated just as it normally would be. The
list of fields to search is reduced to those defined for the specified
table. Note that this can
actually lead to having names to search that would not have otherwise
been available if they were not unique across all tables. As
such, while all the unique names for other tables are removed from the
search namespace, any previously non-unique field names in the
specified table will be added back to the namespace.
- Any record scopes that are active
reduce the field namespace such that any field names that are unique
between those tables that are in scope, will be used to match against
unqualified field names. In
some ways this can and does expand the namespace rather than reduce it,
since any previously non-unique field names in the specified tables
will be added back to the namespace. Note that if multiple
tables are in scope at once (via nesting), any field names that are
common between these tables will not be added to the namespace (any
usage still must be partially or fully qualified to avoid compiler
ambiguity errors).
- Within the selected namespace, if the field name submitted is an
exact match for a field name then that match is the one chosen.
- If no exact match is found, then the name is used as an
abbreviation and there will be only one name in the selected namespace
that will begin with this specific sequence. Because of the order
of
these searches, an exact match overrides any possible matches for the
same name when tested as an abbreviation. Note that the
abbreviation
MUST uniquely match a field name in the selected namespace (step
2).
If this is not the case, Progress would signal a compile error.
- qualified name splitting
- namespace reduction (and sometimes additions)
- exact match search
- begins with search
Unqualified field references from any kind of record (table, temp-table, work-table, buffer) will collide if they are non-unique, even if the search was done on an exact match, except in such cases where the associated record is in "scope" making that unqualified name unambiguous.
An exact match with a name always supersedes a conflicting abbreviation.
Note that user-defined variable names cannot be abbreviated and database names cannot be abbreviated. The abbreviation processing is only done for fields and tables.
Buffer names cannot be abbreviated but buffer field names can be abbreviated. Temp-table and work-table names cannot be abbreviated, however temp-table and work-table field names CAN be abbreviated.
Given 2 names cust and customer (which could both be tables or both fields) where one is a subset of the other:
| Search
Name |
Matches
Nothing (is ambiguous) |
Matches
cust |
Matches
customer |
| c |
yes |
||
| cu |
yes |
||
| cus |
yes |
||
| cust |
yes |
||
| custo |
yes |
||
| custom |
yes |
||
| custome |
yes |
||
| customer |
yes |
Cardinal Rule of Ambiguity
No ambiguity is allowed at runtime, ever. If there is more than 1 match found via any of these matching algorithms, then a compile-time error will occur. This means that all source code read by P2J can be assumed to have 1 and only 1 match. There will never be 0 matches nor will there be 2 or more matches. The primary advantage of this fact is that the logic of any search algorithms is insensitive to the order in which the search is made. This means that the P2J environment can be coded using arbitrary search ordering without affecting the outcome. This is true for unqualified name searches and for partially or fully qualified names.
Since the namespace being used depends upon the databases that are connected when a procedure is called, the only time it is completely safe to use unqualified field names is when a specific record scope is in effect, causing normally ambiguous names to be unambiguous. Although the scoping rules are arcane and poorly documented, they can be relied upon.
Dynamic Namespace
The schema namespace is not completely static. Dynamic modification of the namespace is possible by defining buffers, temp-tables and work-tables. All of these are equivalent to a table and have field definitions.
Buffers are equivalent (from a schema perspective) to an already existing table. They just represent a different memory allocation in which a record from the referenced table can be stored. From this perspective, one might think of buffers as aliases for a table, at least from the parser's perspective. In reality, there is more going on of which the parser is unaware.
Buffers can be created, referenced or passed into an external procedure AS WELL AS AN internal procedure AND IN A function. Buffers
can only be referenced within the scope that they are defined, so a buffer defined in an external procedure is accessible until that procedure ends. A buffer defined in an internal procedure or function is inaccessible after that internal procedure or function block ends.
Temp-tables and work-tables are both treated like dynamically adding a table to the schema (not associated with any database). This table can optionally copy the entire schema structure of a current table and/or add arbitrary fields to the definition. It appears there is no way to remove fields from the definition if one bases it upon an existing table.
Temp-tables and work-tables can be created inside an external procedure, a shared instance can be accessed inside an external procedure or an instance can be passed in as a parameter. In all cases, such tables can be referenced from the moment of definition/declaration until the end of that external procedure.
When defining or adding temp-tables, work-tables and buffers, these entities can be scoped only for the duration of a do, for or repeat block. They are always scoped to a procedure or function (buffers only).
Temp-table/work-table and buffer names that are added/defined, will hide an unqualified conflicting table name (such that the only way to
reference that database table is with a fully qualified name).
Within a single external procedure (or internal procedure/function in the case of buffers), you can never define duplicate temp-table,
work-table or buffer names.
It is possible to define a buffer FOR a buffer that refers to a temp-table. However, Progress does not allow a buffer FOR a buffer that refers to a table.
The schema namespace must handle these dynamic changes through methods that are called by the parser in specific rules which implement Progress language statements such as define buffer, define temp-table and define work-table.
Another type of namespace modification is the use of aliases. All connected databases have a "logical database name" that is used to qualify table and field names. By using aliases, one can create additional logical names that are equivalent to the original database name. Any references to the alias are treated as references to the original database name. One trick that is often used is that a database is aliased before running another external procedure that uses the same schema by a different logical name. This allows a common procedure to be used against 2 or more databases as long as the schema are identical or at least compatible in the areas in use. The problem in such tricks is that this is done external to the code being run, so the parser must be externally informed or the schema namespace must be prepared to handle all possible aliases. If there are cases in which the same alias is used for different databases then this may be not be statically defined in a configuration file. This area needs additional definition before it can be implemented.
A record scope is the beginning and ending of a buffer (associated with the table or "record" in question) that can be used to store real rows of data. This scope determines many things such as when data is written to the database or when a new record is fetched. However, from the parser's perspective, the only reason why record scope matters is because it affects unqualified field name resolution.
Progress databases are very likely to have a large number of field names that are duplicated between tables. For this reason, these field names are not unique across the database and thus in normal circumstances, they can only be unambiguously referenced when they are qualified. Wherever there are long lists of field names, it is convenient to allow the more liberal usage of unqualified names. This is possible whenever there are one or more record scopes that are active. In this case, the list of unique unqualified fields can be expanded based on the list of those tables in scope at the time. If multiple tables are in scope, then the set of all field names that are unique across that list of tables in scope will be available for searching even if those names would normally be unavailable due to conflicts with other tables. As long as the conflicts are only with tables that are not in scope, those unqualified names can be used. If however, the same field name is used in 2 or more of the tables that are in scope, that name still needs to be qualified on lookup.
Buffers are referenced via a name. That name can have been explicitly defined in the current external procedure, internal procedure or function using one of the following:
DEFINE BUFFER buffername FOR record
DEFINE PARAMETER BUFFER buffername FOR record
FUNCTION ... (BUFFER buffername FOR record, ...)
If not explicitly defined, then the buffer name must be implicit defined based on a reference to a table name (database table, temp-table or work-table) inside a language statement or built-in function.
Buffers can only be scoped to an enclosing block which has the record scoping property. All block types (external procedures, internal procedures, triggers, functions, repeat and for) except DO have the record scoping property by default. Even a DO obtains record scoping when either the FOR or PRESELECT qualifier is added (these are mutually exclusive).
Internal procedures, triggers and functions additionally have namespace scoping properties such that an explicit definition of a buffer name in one of these blocks will hide the same explicit buffer name in the containing external procedure. However, if no "local" definition exists for an explicit buffer name, references in these contained blocks will cause the original definition in the external procedure to be scoped to the external procedure level itself. Please note that any explicit buffer definitions inside an internal procedure, trigger or function cannot be used outside of that block. The external procedure is different in this respect (this is the same behavior as Progress provides for variables).
If a buffer is not explicitly created, then it is created implicitly via a direct table name reference in the source code. For example, if a table named customer exists in the currently connected database, then any of the following language constructs that reference customer (e.g. create customer) cause a buffer of the same name (customer) to be created. This can be confusing since some language constructs use this same name to reference the schema definition of that table, some use the name to reference the table and some use the name as a buffer. This polymorphic usage is considered an "implicit" buffer.
Whether or not a language construct creates a buffer is determined by the type of the reference. The following maps language constructs to the type of record reference:
| Language
Construct |
Type |
Reference
Type |
| any field reference in an
expression |
lvalue |
free reference |
| AMBIGUOUS record | built-in function |
free reference |
| AVAILABLE record | built-in function | free reference |
| ASSIGN field = expression |
statement |
free reference |
| ASSIGN record | statement |
free reference |
| BUFFER-COMPARE buffer TO buffer | statement | free reference |
| BUFFER-COPY buffer TO buffer | statement | free reference |
| CAN-FIND( record ... ) |
built-in function | no reference |
| CAN-FIND( ... OF record ) | built-in function | free reference |
| CREATE record |
statement |
free reference |
| CURRENT-CHANGED record |
built-in function | free reference |
| DEFINE BROWSE browse_name QUERY
query_name DISPLAY record WITH ... |
statement |
free reference |
| DEFINE BUFFER buffer-name FOR record | statement |
no reference |
| DEFINE FRAME frame-name record | statement | no reference |
| DEFINE PARAMETER BUFFER
buffername FOR record |
statement |
free reference |
| DEFINE PARAMETER TABLE FOR
temp-table-name |
statement |
no reference |
| DEFINE type PARAMETER
TABLE-HANDLE FOR temp-table-handle |
statement |
unknown |
| DEFINE TEMP-TABLE temp-table-name LIKE record | statement | no reference |
| DEFINE QUERY <queryname>
FOR <tablename> |
statement | free reference |
| DELETE record |
statement |
free reference |
| DISPLAY record |
statement |
free reference |
| DO FOR record |
statement | strong |
| DO PRESELECT record |
statement | weak |
| EMPTY TEMP-TABLE record |
statement |
free reference |
| EXPORT record |
statement |
free reference |
| FIND ... record |
statement | free reference |
| FOR EACH record |
statement | weak |
| FOR FIRST record |
statement | weak |
| FOR LAST record |
statement | weak |
| FORM record |
statement |
no reference |
| FUNCTION func_name RETURNS type
(BUFFER buffername FOR record, ...). |
statement |
free reference |
| FUNCTION func_name RETURNS type (TABLE FOR temp_table_name, ...). | statement |
no reference |
| IMPORT record |
statement |
free reference |
| INSERT record |
statement | free reference |
| LOCKED record |
built-in function | free reference |
| NEW record |
built-in function | free reference |
| ON dbevent OF record |
statement |
free reference |
| OPEN QUERY query ... record ... |
statement | free reference |
| PROMPT-FOR record |
statement |
free reference |
| RAW-TRANSFER buffer TO buffer |
statement |
free reference |
| RECID record |
built-in function | free reference |
| RELEASE record |
statement |
free reference |
| REPEAT FOR record |
statement | strong |
| REPEAT PRESELECT record |
statement | weak |
| ROWID record |
built-in function | free reference |
| RUN procedure (BUFFER record,
...) |
statement |
free reference |
| SET record |
statement |
free reference |
| UPDATE record |
statement | free reference |
| VALIDATE record |
statement |
free reference |
There are 4 types of record references (to database tables, temp-tables or work-tables) which may cause a buffer to be created. If this reference is implicit, the resulting buffer is named the same as the table to which it refers. It is important to note that even when a reference does create a buffer (allocate memory) only a small subset of the above statements actually fill it with a record (all buffers only hold a single record at a time). Other statements (e.g. FIND, FOR or GET) may handle both the creation of the buffer and the implicit loading of that buffer with the first record.
The following sections describe each of the reference types. 3 of the 4 types can cause the creation of a new buffer. Multiple references to the same buffer are sometimes combined into a single buffer creation and at other times more than 1 buffer can be created. The following describes the rules by which the number of buffers are determined. For each buffer that is created, there is also a "record scope" that corresponds to this buffer. This scope determines the topmost block in which the buffer is available.
In the following rules, the use of "implicit" should not be confused with whether or not a buffer name has been explicitly or implicitly referenced. In many cases, Progress will implicitly create a larger scope for a buffer such that multiple references share the same buffer. This is the sense in which the word implicit should be interpreted. Most importantly, the scoping rules (both the explicit rules and the implicit expansion rules) are applied in the same exact manner for both explicitly defined buffers as for implicitly defined buffers.
No Reference
Some name references can occur in many language statements, even before these scope creating statements. For example, a DEFINE TEMP-TABLE <temp-table-name> LIKE <table_name> statement is such a reference that can occur anywhere in a procedure. No buffer is being referenced here, instead it is the schema dictionary (the data structure of the record) that is being referenced.
Strong Reference
Only two language statements (both are kinds of block definitions) can be a strong reference (DO FOR and REPEAT FOR). A new buffer is created and that buffer is scoped to the block being defined. Strong scopes are explicitly defined by the 4GL programmer and the Progress environment never implicitly changes the scope to be larger (as can happen with the next two reference types). A strong reference doesn't ever implicitly expand beyond the block that defines it.
Other reference types can be nested inside a strong scope and the scope of these references is always raised to the strong scope. Thus every buffer reference within a strong scoped block is always scoped to the same buffer.
Additionally, no free references to the same buffer are allowed outside the block defining a strong scope (the code will fail to compile). Weak references to the same buffer can be placed outside or inside a strong scope.
Weak Reference
Only three language statements (all of which are kinds of block definitions) can be a weak reference (FOR EACH, DO PRESELECT and REPEAT PRESELECT). Depending on other references (or the lack thereof) in a file, a weak reference may create a new buffer and scope that buffer to the block in which the buffer was referenced.
If a weak reference to a buffer is nested inside a block to which the buffer is strongly scoped, then this reference does not create a new buffer and is simply a reference to that same strongly scoped buffer.
If a weak reference is not nested inside a strong scope, it will create a new buffer and scope that buffer to the block definition which made the weak reference, BUT this will only happen if no unbound free references to the same buffer exist (see Free Reference below for details).
With the existence of one or more unbound free references, it is possible that the weak reference will have its scope implicitly expanded to that of a containing scope. For this to occur, the scope of the buffer will be expanded to the nearest block that can enclose the multiple references to this same buffer. The problem is that there are complex rules to determine which references (weak and free) are combined into a single buffer (and its associated scope) and which weak references are left alone.
Free Reference
Anything that is not a "no reference", strong reference or weak reference is a free reference.
If the free reference is contained inside a block to which the referenced buffer is strongly scoped, then this is simply a reference to that same buffer and no buffer creation or scope change will occur.
If the free reference is contained inside a block to which the referenced buffer is weakly scoped, then this is simply a reference to that same buffer and no buffer creation or scope change will occur. Please note that the Progress documentation incorrectly states that "a weak-scope block cannot contain any free references to the same buffer". More specifically, one cannot nest certain free references to a given buffer that is scoped to a FOR EACH block (which is the most common type of weak reference). For example, one cannot use a FIND inside a FOR EACH where both are operating on the same buffer. However, one should note that field access is a form of free reference and this is perfectly valid (as one would expect) inside a FOR EACH.
Contrary to the Progress documentation, if the weak reference is created by a DO PRESELECT or REPEAT PRESELECT, then it is required that one use one or more free references in order to read records since neither of these blocks otherwise provide record reading. In this case, even FIND statements work within such a block.
If the free reference is not nested inside a block to which the same buffer is already scoped, then this free reference may cause the scope of other free references and weak references to be implicitly expanded to a higher containing block.
In two cases (FOR FIRST and FOR LAST), a free reference is part of a block definition. In such a case, if there is no need to implicitly expand the scope for this buffer, it will be scoped to the block definition in which the free reference was made.
Much more common is for a free reference to be a standalone language statement which is not part of a block definition (e.g. any form of FIND). In such cases, whether a buffer is created or not and where that buffer is scoped are decided via a complex series of rules.
It is important to note that in the absence of free references, there will never be any implicit expansion of record scopes. Thus the free reference is the cause of implicit scope expansion.
Implicit Scope Expansion Rules
The following are the rules for scope expansion (Progress does not document these rules, but they have been determined by experience). These rules all assume that all references refer to the same implicit buffer name. The previous rules for scoping are not repeated here as these rules only reflect the logic for implicitly expanding scope. To perform the analysis described here, one must traverse the Progress source AST that the parser creates with "forward" meaning down and/or right from the current node and "backward" meaning up and/or left of the current node. To understand some of the terms in the following rules, one must think of the tree as a list. In other words, one must "flatten" (degenerate) the tree into a simple list (based on the depth first approach of traversing down the tree before traversing right). Using this conceptual list form of the tree, one can see that the "closest prior" (the most recently encountered node that matches some criteria) or "next" (the closest downstream node that matches some criteria) node can be thought of as a simple backward or forward "search" respectively. This is critical to understand these rules since much of the logic is not defined by the nesting of blocks (as would be expected) but is rather defined by the "simple" ordering of the references.
- No scope is ever expanded without the presence of more than 1 reference to the same buffer where at least one of the references is a free reference.
- Any free or weak reference that is nested inside a weak or strong
scope per the above rules, is not considered in this analysis.
Such references are effectively ignored.
- Once (due to a match with one of the following rules) an implicit scope has been assigned (expanded) to a block, this is considered an active scope. Since at least one of the references that triggered the expansion must have been a free reference, this reference is now considered bound and no longer affects any further implicit expansion decisions.
- The block to which a scope expansion has occurred will be called
an expanded scope in
subsequent rules.
- Weak and free references that are positioned later than
statements triggering the scope expansion but which are nested inside
an active scope will use that active scope and will not affect or
cause
any further expansions. Such free references are considered bound free references.
- When an unbound free reference (any free reference that is not defined as bound as noted above) is encountered, an implicit scope expansion will occur. Unbound free references are greedy since they will "reuse" or "borrow" the buffer defined elsewhere if at all possible. A backward "search" is made for the first match to any of the following (to which to "bind" the free reference):
- The most recent prior weak reference (at the current or a higher nesting level).
- The most recent prior expanded scope (at any nesting level).
- If a nested block is encountered, the first (in order of occurrence, no matter its sub-nesting depth) weak reference of that block.
- Whichever of these backward
references is found first is the reference or scope that is
used to determine the enclosing block that will be the target for the
expansion. If no prior weak references or prior expanded scopes exist to which to
bind, then the next weak reference after the unbound free reference will be the
bind target. By definition, an expanded scope can only be found by searching backward
since the source tree is processed top to bottom/left to right and it
is this current processing which creates expanded scopes.
- Once a bind target is found, the nearest block that encloses both
references (or the one free reference and the expanded scope) and which has the record scoping property will form
the target of an expanded scope.
This means that at a minimum, the two references (or the one free
reference and the expanded scope)
will both use a common buffer that is associated with the target block.
- A special case exists when there is 1 or more unbound free references and no weak
references or expanded scopes
to the same buffer. This means that the only references to this
buffer are free references and there are no buffers to
"borrow". Instead a buffer is created and scoped based only on
the free reference(s). The result is that all of these free
references will be combined into a single expanded scope at the nearest block
that encloses all free references and which has the record
scoping property.
- An expanded scope's block target can be very close to the free reference (the currently enclosing block) or it can be located at any enclosing block up to and including the external procedure block itself. The target is calculated as described in rule 8 above. No matter which block is the target it is possible that there are prior weak references and expanded scopes that are contained within the scope of the target block. The following sub-rules must be used to determine which of these weak references or expanded scopes will have their scope raised or rolled up to the new enclosing target block and which of them will retain their own independent scope. If conditions cause some of the references or expanded scopes to remain separate, then the result is a nested island which uses a separate buffer referencing the same table by the same name.
- This processing must be done in a backwards walk of the tree
with the results heavily based on block nesting.
- Only weak scopes and expanded
scopes will be encountered in such a backward walk, because the
forward walk to this point has by its nature, already bound all free references into expanded scopes.
- The rollup process starts with the first prior weak reference or expanded scope which was not the bind target (see rules 6 and 7 above) and which is directly enclosed by the target block. In other words, the starting point must be a weak reference or expanded scope that is a direct child node of the target block.
- The rollup process
ends at (and including) the closest prior expanded scope (whether or not this is a direct child of
the target block, no matter how deeply nested it may be) or when there
are no more weak references or expanded scopes to rollup (whichever condition comes first). This means that only 1 prior
expanded scope will ever have its scope raised in a given rollup process. The other (counter-intuitive)
result of this is that any direct children of the target block that are
weak references or expanded scopes but which precede the closest prior expanded scope, are never rolled up. In other
words, they become islands of
unique scope nested inside a larger scope but remaining separate.
The closest prior expanded scope thus forms a kind of firewall before which all previous
scopes (within the same enclosing target block) are forever
fixed. In other words, once this firewall
has been created (just another name for an expanded scope), certain prior
scopes can never be rolled up.
- All weak references that are directly enclosed by the target
block and are located between the start and end points of the rollup process, will have their
scope raised to the target block. They are essentially "merged"
with that scope. Weak references that are more deeply nested
(i.e. they are not direct child nodes of the target block) are not
merged, with the single exception noted in the next sub-rule (10f).
- Besides weak references and expanded scopes that exist as direct child nodes of the target block, this rollup process can cause a counter-intuitive scope merger for weak references that are more deeply nested. This only happens if there is a block nested directly inside the target block AND there are no expanded scopes (at any level) in that nested block. In this case (where the nested block has only weak references), the first (in order of occurrence) weak reference in that nested block (even if that weak reference is deeply nested inside that nested block) will have its scope raised while all other following weak references in the nested block will remain islands. This is really a side effect of or related processing for how nested blocks are processed in rule 6 above.
- This rollup of the first weak reference in a nested block does not stop the rollup process. This means that multiple directly nested blocks in a target scope will each have their first weak reference's scope raised (assuming that each nested block contains no expanded scope). If one of these blocks contains an expanded scope, then the sub-rule (10d) above takes precedence and the first weak reference DOES NOT have its scope raised.
The following are examples to show both the simple/expected behavior as well as each of the more obscure (counter-intuitive) cases. In each example the following explains how to interpret the text:
- Ignore the fact that these examples are completely useless
(mostly just infinite loops), they are illustrative only.
- Only the "customer" buffer is being used. All scoping
decisions are relative to this buffer and decisions are always
independent between buffers with different names (even if they refer to
the same table).
- Any text that is left in the color black has no record scope assigned at all. That means that the buffer(s) shown are invalid at those locations.
- Non-black colors are used to show scopes. Since scopes are
associated with an entire block, the whole block will be colored the
same except in the case where there are nested islands of different
scope. In such cases the islands will be distinguished using
multiple colors.
| Progress
Source Code |
Notes |
| message "hello". find first customer. |
This is the most simple
case. There is 1 free reference and the buffer created is
associated with the external procedure. |
| message "hello". repeat: find first customer. end. |
Another simple case with a
single free reference. The scope is assigned at the nearest
enclosing block that holds all references (and which has the record
scoping property). In this case, the scope is associated with the
repeat block instead of the external procedure. |
| repeat: repeat: repeat: repeat: repeat: find first customer. end. repeat: repeat: find first customer. end. end. end. end. end. end. |
In the absence of weak
references, 2 or more free references will all combine into a single
scope at the at the nearest enclosing block that holds all references
(and which has the record scoping property). Note that the level of nesting has no impact on this result. |
| do for customer: for each customer: end. find first customer. end. for each customer: end. |
Here, the DO FOR block
establishes a strong scope. All customer references within this
block are all scoped to the block. In this example, the free
reference is not considered unbound because it is within the strong
scope. Also note that no free references external to the same
buffer are allowed outside this strong scope. The weak reference within the strong scope is part of that scope, but the weak reference outside of the strong scope has its own buffer/record scope. No implicit scoping will occur, everything is fixed and explicit. |
| message
"hello". for each customer: end. |
This weak reference is the
simple case where the buffer created is associated with the FOR block. No implicit scoping changes will occur. |
| message "hello". for each customer: end. for each customer: end. |
These 2 weak references each
have their own scope where the buffer created is associated with each
FOR block. No implicit scoping changes will occur. |
| message "hello". do preselect each customer: find first customer. find next customer. end. for each customer: end. |
This is an example of two weak
scopes that are sequential. Please note that while it is not
possible to have a free reference inside a FOR EACH block, the
PRESELECT blocks must by their nature use free references to read
records. |
| message
"hello". repeat: for each customer: end. find first customer. end. |
This is the
most simple type of implicit scope expansion. The default scope
for the weak reference is raised to the enclosing REPEAT block due to
the presence of the FIND free reference. The REPEAT block in this case would be considered an expanded scope in the text above. |
| message "hello". repeat: repeat: for each customer: end. end. end. find first customer. |
This implicit scope expansion
shows that the default
scope for the weak reference is raised to the external procedure due to
the presence and location of the FIND free reference. An
important note is that the nesting level of the FOR EACH weak reference
makes no difference with this behavior. Likewise, whether or not
the FIND was deeply nested has no impact. The decision to
implicitly expand scope is based on the presence of an unbound free reference and the order
in which the buffer references occur. |
| message
"hello". repeat: find first customer. repeat: repeat: for each customer: end. end. end. end. |
This implicit scope expansion
shows that the default
scope for the weak reference is raised to the REPEAT block even though
it follows the FIND free reference. In this case, there is no
prior weak reference or expanded scope
to which to bind. |
| repeat: repeat: repeat: for each customer. end. repeat: repeat: find first customer. end. repeat: repeat: find first customer. end. end. end. end. end. end. |
In this case when the first free
reference is encountered there is a prior weak reference AND it is at a
different (higher in this case) nesting level so that changes the
target block chosen. It is important to note that following free references that are enclosed in this active scope (see rules 3 and 5 above) are automatically scoped to this same level and do not have any further impact. |
| repeat: repeat: repeat: repeat: repeat: find first customer. end. repeat: repeat: find first customer. end. end. end. end. for each customer. end. end. end. |
As the tree is walked, when an unbound free reference is encountered (the first FIND), a backward search will be made. In this case, no weak references or expanded scopes are found. So the free reference will bind to the next weak reference encountered. This expands the scope to the 2nd level REPEAT block. |
| repeat: repeat: for each customer: end. find first customer. end. repeat: for each customer: end. find first customer. end. end. |
An example of 2 expanded scopes that never
combine. This separation is due to the nesting levels of the
scopes. |
| repeat: repeat: for each customer: end. find first customer. end. repeat: for each customer: end. for each customer: end. repeat: repeat: for each customer: end. end. end. repeat: repeat: find first customer. end. find first customer. end. end. end. |
A more complex example that
shows that nesting may stop two expanded
scopes from combining at a higher level, but that no matter how
deeply nested the original unbound free
reference and the weak reference to which it binds, the rollup process
stops at the end of the expanded scope.
If no subsequent free references occur outside of the expanded scope, such that it is
rolled up further, this condition holds. |
| repeat: repeat: for each customer: end. find first customer. end. repeat: for each customer: end. for each customer: end. repeat: repeat: for each customer: end. end. end. repeat: repeat: find first customer. end. find first customer. end. end. end. find first customer. |
A more complex example that
shows that nesting may stop two expanded
scopes from combining at a higher level, even when there are
subsequent free references that occur outside of the parent block of
both expanded scopes, such
that the last one (forming a firewall)
it is rolled up further while the first one is left separate. |
| message
"hello". repeat: repeat: for each customer: end. find first customer. end. repeat: find first customer. end. repeat: for each customer: end. for each customer: end. repeat: repeat: for each customer: end. end. end. repeat: repeat: find first customer. end. find first customer. end. end. end. |
The introduction of an
intermediate free reference between what would have been 2 separate expanded scopes causes the first expanded scope to be raised up (as
the bind target) and the entire contents of the 4th REPEAT block
automatically have their scope raised because they are inside of an active scope. |
| repeat: repeat: repeat: repeat: repeat: find first customer. end. repeat: repeat: find first customer. end. end. end. end. for each customer. end. for each customer. end. for each customer. end. end. end. |
Another example of active scope processing. The
number or order of subsequent enclosed references does not make any
difference. |
| message "hello". repeat: for each customer: end. for each customer: end. for each customer: end. repeat: repeat: for each customer: end. end. repeat: repeat: find first customer. end. end. end. for each customer: end. end. |
This demonstrates the effect
that nesting has (and doesn't have) on implicit scope expansion.
All of the weak references in the top level REPEAT block never have
their scope expanded because there is no unbound free reference at a nesting
level that can affect them. However, the nested weak reference
inside the 3rd level REPEAT block is the bind target for the single
FIND free reference. The 2nd level REPEAT block is the nearest
enclosing scope that can contain both weak and free references AND
which has record scoping properties (see the next example). So
the resulting expanded scope
is never expanded again due to no additional unbound free references. It is important to note that the relative nesting of the weak and free referneces within the 2nd level REPEAT block only affects the target block to which the scope is expanded. The relative nesting of the weak and free references does NOT affect the choice of which weak reference is bound to the free reference! Rather, this is primarily a sequence issue (it is almost always determined by the order or occurrence). The only exception is noted in rules 6a and 10f above. |
| message "hello". repeat: for each customer: end. for each customer: end. for each customer: end. do: repeat: for each customer: end. end. repeat: repeat: find first customer. end. end. end. for each customer: end. end. |
The only difference between this
example and the previous one is that the 2nd level REPEAT block has
been changed to a DO block. Since the DO block has no record
scoping property by default, this means that the nearest enclosing
block which has this property is the top level REPEAT block. Once
the scope expands to this level (due to the FIND free reference), the
previous weak references that are direct children of the target REPEAT
block have their scope expanded too. Once that expanded scope is active, the subsequent weak
references (the last one in the file) is automatically expanded too. |
| message "hello". repeat: for each customer: end. for each customer: end. for each customer: end. repeat: repeat: for each customer: end. end. repeat: repeat: find first customer. end. end. end. for each customer: end. find first customer. end. |
This is an example of the
exception in rule 10f above. 2 expansions occur, in series.
The first is due to the deeply nested FIND free reference. This
expands scope to the 2nd level REPEAT block and binds to the 4th
instance of FOR EACH. Then when the 2nd FIND free reference is
encountered, it binds to the 5th FOR EACH, raises scope to the
top-level REPEAT block and then searches backward to expand the scope
of prior weak or expanded scopes.
In this case it stops its search when it encounters the first expanded scope (this is an example
of the firewall described in
rule 10d above). This means that the previous weak scopes each
remain separate and independent (islands)
but enclosed within a larger scope of the same buffer name. |
| message "hello". repeat: for each customer: end. repeat: for each customer: end. find first customer. end. for each customer: end. for each customer: end. repeat: repeat: for each customer: end. end. repeat: repeat: find first customer. end. end. end. find first customer. end. |
This demonstrates that a free
reference can bind to the closest prior expanded scope. That expanded scope also performs the firewall function, causing all prior
weak references and expanded scopes
at that level to remain scoped as they are (no expansion of their scope
to a higher level). |
| message "hello". repeat: for each customer: end. repeat: for each customer: end. find first customer. end. repeat: for each customer: end. for each customer: end. repeat: repeat: for each customer: end. end. repeat: repeat: find first customer. end. end. end. end. find first customer. end. |
This demonstrates that the
closest prior expanded scope
can be inside a nested block. That expanded scope still performs the firewall function, causing all prior
weak references and expanded scopes
at that level to remain scoped as they are (no expansion of their scope
to a higher level). In the backwards search, the prior expanded scope is found before the weak reference (the 4th FOR EACH), which is why the prior expanded scope is the bind target for the last FIND free reference and why the nested FOR EACH weak references are their own independent scopes. |
| message "hello". repeat: for each customer: end. repeat: for each customer: end. find first customer. end. repeat: for each customer: end. for each customer: end. repeat: repeat: for each customer: end. end. repeat: repeat: find first customer. end. end. end. for each customer: end. end. find first customer. end. |
The closest prior weak reference
in this case is the bind target for the final free reference.
However we can still see that the rollup process forces the closest
prior expanded scope to be
raised and that expanded scope
performs the firewall
function. Thus all prior weak references and expanded scopes in the nested 2nd
level REPEAT block AND at the 1st level REPEAT block level to remain
scoped as they are (no expansion of their scope to a higher level). In the backwards search, the nested prior expanded scope is found as the first bind target. This is because a nested weak reference (except for the rule 10f above) cannot be a bind target. |
| repeat: for each customer: end. repeat: for each customer: end. find first customer. end. for each customer: end. for each customer: end. repeat: for each customer: end. for each customer: end. for each customer: end. repeat: repeat: for each customer: end. end. end. end. find first customer. end. |
This shows that the last free
reference binds to the first weak reference in a nested block (the 3rd
REPEAT block, see rule 6c above). But also note that the all
prior weak references and the closest prior expanded scope also get rolled up. That expanded scope
forms a firewall which leaves
the 1st FOR EACH as an island. All weak references in the nested block (the 3rd REPEAT block) after the first one, are not rolled up. The key points here are:
|
| repeat: for each customer. end. for each customer. end. repeat: repeat: for each customer. end. repeat: for each customer. end. find first customer. end. repeat: for each customer. end. find first customer. end. repeat: for each customer. end. find first customer. end. for each customer. end. end. for each customer. end. end. for each customer. end. find first customer. end. |
Another example of how the rollup process stops processing when
it encounters the closest prior expanded
scope, even if this is deeply
nested in sub-blocks. |
| message "hello". repeat: for each customer: end. find first customer. repeat: for each customer: end. find first customer. end. for each customer: end. for each customer: end. repeat: repeat: for each customer: end. end. repeat: repeat: find first customer. end. end. end. find first customer. end. |
The introduction of a free
reference early (the first FIND on line 8) in a program which causes
the scope to be expanded early to the top-level REPEAT. All
subsequent references within this top-level REPEAT block will scope to
this level no matter the order or sub-nesting depth. This is an
example of the effect of an active
scope as described by rules 3 and 5 above. Note that without this early free reference, the firewall effect that is seen in the previous example. |
| message "hello". repeat: for each customer: end. find first customer. repeat: for each customer: end. end. for each customer: end. for each customer: end. repeat: repeat: for each customer: end. end. for each customer: end. end. for each customer: end. for each customer: end. end. |
Another example of the active scope effect. Note that
in this case only a single free reference exists in the entire program,
but the result is the same. Also note that the sub-nesting level
has no impact on whether the contained weak references (or expanded scopes if any had existed
in this example) would have their scope expanded. |
| repeat: for each customer. end. for each customer. end. repeat: repeat: repeat: for each customer. end. end. for each customer. end. repeat: for each customer. end. end. repeat: for each customer. end. end. for each customer. end. end. for each customer. end. end. for each customer. end. repeat: for each customer. end. for each customer. end. end. for each customer. end. find first customer. end. |
This is an important example of
the rollup process.
There is only a single free reference (the FIND statement at the end)
and it binds to the FOR EACH just prior to it. The rollup process occurs from there,
and since there is no prior expanded
scope to act as a firewall,
the rollup continues all the
way up to the top of the enclosing top-level REPEAT. Both direct
child weak references and the first occurring weak references in 2
nested blocks are rolled up.
Note that due to nesting 6 weak scopes do NOT get rolled up. |
| repeat: for each customer: end. for each customer: end. repeat: repeat: repeat: find first customer. end. end. repeat: for each customer: end. end. end. for each customer: end. end. |
This helps demonstrate the
sequential nature of the bind target decision. The 1st free
reference is encountered deeply nested inside the 4th REPEAT
block. It searches backward and binds to the 2nd FOR EACH (just
inside the top-level REPEAT block). The rollup process then raises the
scope for the 1st FOR EACH to the same top-level REPEAT block and
ends. Now the last 2 weak references are both contained inside an
active scope, so they
automatically get their scope raised too. If the FIND free reference and the 3rd FOR EACH were transposed in sequence, the result would have been 4 separate scopes, rather than 1 single scope. Note that nesting in this case has no affect, only the sequence mattered. |
Nesting Scopes
Scopes can be nested although there are rules against nesting 2 scopes (referring to the same table) that are the same type. So 2 weak scopes for table1 can't be nested and 2 strong scopes of table1 can't be nested. A strong scope cannot be nested inside a weak scope for the same buffer. On the other hand, it is possible to nest a weak scope inside a strong scope where both are referencing the same table. Note that if a weak scope is nested inside a strong scope, that weak scope cannot be expanded by a free reference. The strong scope binds to the specified block and cannot (by definition) ever be expanded.
It is also known that where multiple scopes (to different tables) are active, the subset of unique field names (that are unique across those tables actively in scope) are added to the namespace and any common (non-unique across the active scopes) names are removed from the namespace. This means that as tables are added and removed from the active scope list, each such change can both add and remove from the namespace. Please see the field name lookup algorithm above for more details.
Record scopes create a schema namespace issue because while a record is in scope, unqualified field names resolve which would normally be ambiguous. This is complicated by the fact that the algorithm to decide upon the block to which a given buffer is scoped cannot be implemented in a single-pass parser.
The primary difference between these scopes seems to be in how the scopes get implicitly expanded based on other database references in containing blocks. Normally a scope is limited to the nearest block in which the scope was created. Strong scopes can be removed from namespace consideration as soon as the this block ends. Weak scopes and free references can both be expanded to the containing block depending on a complex set of conditions. Note that within the naturally scoped block, normally ambiguous unqualified field names are made unambiguous. This is straightforward to implement. The problem is that the parser must properly detect when the scope is implicitly expanded and know when to remove the scope. The parser cannot simply leave all weak and free reference scopes in scope permanently. This is because in a complex procedure, as scopes are removed, some names are removed but some names may also be added back! This is due to the fact that adding a scope while other scopes are still active will remove any field names that are in common between all active scopes. So, removing that scope, re-adds those removed names to the namespace. Since the namespace can expand when a scope is removed, it is critical to detect this exact point and implement this removal otherwise the parser will fail to lookup names that should not be ambiguous.
The current approach has been to use the SchemaDictionary namespace to keep track of scopes. At the start of every for, repeat or do block a scope is added and at the end, this scope is removed. This stack of scopes handles the nesting of names properly. Then the parser makes a very big simplifying assumption: every record (table, buffer, work-table or temp-table) reference is automatically "promoted" to the current scope (the top of the stack of scopes). This allows any tables in the current scope to take precedence for unqualified field lookups and then tables in the next scope down take precedence and so on until the name is resolved (remember: valid Progress code will ALWAYS have only unambiguous names so it is only a matter of where one finds it). The problem in this simplistic approach (see the record method) is that Progress may not always promote as we do. Thus in our implementation, there may be promoted tables that wouldn't otherwise be there. This may cause some names that would have been unambiguous (with a more limited set of tables in scope) to now be ambiguous. We don't have an example of such a situation but if it does occur, the implementation may have to get much more smart about when to and when not to promote.
To properly implement scoping support, these conditions must be fully explored and documented. The following list is an incomplete set of testcases which needs to be completed before scoping support can be implemented. In the table, each record that has the same scenario number (in the testcases that have more than 1 row) describes a database reference made inside that scenario. The order of the rows is the same order as used in the testcases. The column entitled "Disambiguates Outside Unqualified Field Name" can be interpreted as whether an unqualified field name can be used outside the block in which the scope was added (it can always be used inside such blocks). This is usually (but not always) just another way of interpreting the "Scoped-To Block" column, since it is the block which the scope is assigned that defines the location of where the scope exits (and thus where unqualified names can no longer be used). There are conditions (see scenarios 6 and 7 below) where the these columns show conflicting results. Note that the LISTING option on the COMPILE statement is used to create a listing file that showed exactly in which block Progress determined the scope to be assigned.
| Scenario |
Scope
Type |
Statement |
Table |
Scoped-To Block | Disambiguates
Outside Unqualified Field Name |
| 1 |
free |
FIND FIRST |
table1 |
external proc |
Y |
| 2 |
weak |
FOR EACH |
table1 |
FOR |
n/a (since there are no
conditions outside the naturally enclosing block that cause an implicit
expansion of scope, there are also no outside references to
disambiguate) |
| 3 |
strong |
DO FOR |
table1 |
DO |
n/a |
| 4 |
weak |
FOR EACH |
table1 |
external proc |
Y |
| 4 |
free |
FIND FIRST |
table1 |
external proc | Y (the weak and free scopes are
combined into a larger scope) |
| 5 |
strong |
DO FOR |
table1 |
fails compile |
n/a |
| 5 |
free |
FIND FIRST |
table1 |
fails compile |
n/a |
| 6 |
weak |
FOR EACH |
table1 |
external proc |
Y |
| 6 |
weak |
FOR EACH |
table1 |
external proc |
Y |
| 6 |
free |
FIND FIRST |
table1 |
external proc |
Y (all 3 references have the
same scope) |
| 7 |
weak |
FOR EACH |
table1 |
external proc |
N |
| 7 |
weak |
FOR EACH |
table2 |
FOR |
N |
| 7 |
free |
FIND FIRST |
table1 |
external proc |
N (even though the first weak
reference scope is expanded to the external proc and combined with this
free reference, the unqualified field names are not supported outside
of the FOR block!) |
| 8 |
strong |
DO FOR |
table1 |
DO |
N |
| 8 |
weak |
FOR EACH |
table2 |
external proc |
Y |
| 8 |
free |
FIND FIRST |
table2 |
external proc |
Y (the weak and free scopes are combined into a larger scope) |
| 9 |
strong |
DO FOR |
table1 |
fails compile |
n/a |
| 9 |
strong |
DO FOR |
table2 |
fails compile |
n/a |
| 9 |
free |
FIND FIRST |
table2 |
fails compile |
n/a (see scenario 5 of which
this is simply a variant) |
| 10 |
free |
FIND LAST (inside non-scoped DO
block) |
table1 |
external proc |
Y |
| 10 |
free |
FIND FIRST (outside non-scoped
DO block) |
table1 |
external proc |
Y (both free scopes are combined into a larger scope) |
| 11 |
free |
FIND LAST (inside non-scoped DO block) | table1 |
external proc |
N |
| 11 |
free |
FIND FIRST (outside non-scoped DO block) | table2 |
external proc |
N (different scopes can't be
combined, no unqualified field names are added to the namespace) |
It is very important to note that there is only ever 1 buffer (memory allocation) in each given procedure (internal or external), function or trigger, even though there may be multiple buffer scopes. The scopes affect record-release but the same memory is used for storage of records read in all contained scopes AND Progress doesn't restore the state of the buffer when a nested scope is complete. This means that when a nested scope is added, the record that had been there is released at the end of that scope. Once that record is released, there is no record in the buffer. If there is downstream processing within the outer scope that expects the record to be there, it will find the record missing.
Unless a record is explicitly defined in an internal procedure, function or trigger, the buffer creation will occur at the external procedure level and this same buffer will be in use the entire scope of the external procedure. In the case where an internal procedure, function or trigger does have an explicit buffer defined, this results in namespace hiding and an additional (local) memory allocation. Buffer names can be the same with a buffer in the external procedure, but any explicit definition will create a local instance of that buffer. Nested scopes that operate on that buffer will have no affect on the buffer of the same name in an enclosing external procedure.
Multiple scopes are possible with explicitly defined buffers, just as they are with implicit buffers, even though there is only ever 1 memory allocation per procedure, trigger or function. The exception is for shared buffers that are imported (e.g. DEFINE SHARED BUFFER b FOR customer) rather than allocated locally. In this case, there is only ever a single scope for this buffer and that scope is set to the external procedure. Access to the shared buffer is imported once and is accessible for the lifetime of the procedure. In the cases of NEW SHARED and NEW GLOBAL SHARED buffers, these do cause a memory allocation and they can have multiple scopes just as any other explicit buffer or as the implicit buffers.
Buffer parameters (DEFINE PARAMETER BUFFER bufname FOR table for procedures and (BUFFER bufname FOR table) for functions) cause the resulting buffer:
- To be explicitly defined.
- To be assigned based on a parameter rather than causing a new memory allocation.
- To be scoped to the procedure or function to which they
apply.
This means that there will not be multiple scopes inside this block
(for that buffer).
List of Database-Related 4GL
Constructs
- ASSIGN <field_or_table>
- AMBIGUOUS table
- AVAILABLE record
- BROWSE query
- BUFFER-COPY buffer TO buffer
- BUFFER-COMPARE buffer TO buffer
- CAN-FIND( record )
- CHOOSE field
- CLOSE QUERY query
- CONNECT database
- CONNECTED( database )
- CREATE record
- CREATE ALIAS alias
- CREATE BUFFER handle FOR table
- CREATE DATABASE database
- CREATE QUERY query
- CREATE TEMP-TABLE temp-table
- CURRENT-CHANGED record
- CURRENT-RESULT-ROW( string )
- CURRENT-VALUE( sequence, database )
- DBCODEPAGE( database )
- DBCOLLATION( database )
- DBPARAM( database )
- DBRESTRICTIONS( database )
- DBTASKID( database )
- DBTYPE( database )
- DBVERSION( database )
- DEFINE BROWSE ... QUERY query
- DEFINE BUFFER buffer FOR table
- DEFINE PARAMETER BUFFER buffer FOR table
- DEFINE PARAMETER TABLE handle FOR temp-table
- DEFINE PARAMETER ... LIKE field
- DEFINE QUERY query FOR table
- DEFINE TEMP-TABLE work-table LIKE table FIELD field
- DEFINE VARIABLE ... LIKE field
- DEFINE WORK-TABLE work-table LIKE table FIELD field (note that WORKFILE is a synonym for WORK-TABLE)
- DELETE record
- DELETE ALIAS alias
- DISABLE field_list
- DISABLE TRIGGERS ... FOR table
- DISCONNECT database
- DISPLAY <record_or_fields> EXCEPT field
- DO FOR
- DO PRESELECT
- EMPTY TEMP-TABLE temp-table
- ENABLE field_list
- field ENTERED
- EXPORT record
- FIND record
- FIRST( breakgroup )
- FIRST-OF( breakgroup )
- FOR
- FORM <record_or_fields>
- FORMAT phrase LIKE field
- GET query
- IMPORT record
- INSERT record
- LAST( breakgroup )
- LAST-OF( breakgroup )
- LDBNAME( database )
- LOCKED record
- MESSAGE ... SET | UPDATE field LIKE field
- NEW record
- NEXT-VALUE( sequence, database )
- NEXT-PROMPT field
- field NOT ENTERED
- NUM-ALIASES
- NUM-DBS
- NUM-RESULTS( query )
- ON event OF <table_or_field>
- OPEN QUERY query
- PDBNAME( database )
- PROMPT-FOR <record_or_field>
- QUERY-OFF-END( query )
- RAW-TRANSFER buffer
- RECID( record )
- RECORD-LENGTH( buffer )
- RELEASE record
- REPEAT FOR
- REPEAT PRESELECT
- REPOSITION query
- ROWID( record )
- SAVE CACHE database
- SDBNAME( database )
- SET <record_or_field>
- SETUSERID( ... database )
- TO-ROWID( string )
- TRIGGER PROCEDURE FOR event OF <table_or_field>
- UNDERLINE field
- UPDATE field
- USERID( ... database )
- VALIDATE record
- WIDGET phrase field
Parser Support
All field data types are created as token types (there is an imaginary token range) for these. The lvalue rule pulls all possible matches in and has init logic to convert DB_SYMBOL and optionally other symbols (SYMBOL or any unreserved keyword) if they don't match a variable name. The token type is rewritten to one of the valid field types on a match.
There are corresponding rules to match tables (see record) and database names. These rewrite the token types as necessary. At this time, in those places (subrules) where indexes or sequences appear, we implement the symbol rule and after it returns we set the type to INDEX or SEQUENCE respectively.
The SymbolResolver class provides database/table/field symbol lookup against the SchemaDictionary class.
At this time, the following features are not yet implemented:
- index namespaces (possibly not needed)
- sequence namespaces (possibly not needed)
- ProgressLexer
mSYMBOL()
- ProgressParser symbol()
- ProgressParser lvalue()
- ProgressParser record()
- ProgressParser
database()
- ProgressParser def_var_stmt()
- ProgressParser
like_clause()
- ProgressParser do_repeat_stmt()
- ProgressParser for_stmt()
- ProgressParser record_phrase()
- SymbolResolver
- SchemaDictionary
Block Structuring
The Progress language is "statement oriented but block structured". What this means is that everything in Progress (other than assignments) starts and ends using a language statement. This includes blocks of all types.The following blocks exist in Progress 4GL:
| Block
Type |
Nestable |
Can Contain | Affects
Symbol Scope |
Provides Iteration |
Notes |
| external procedure | no |
any block |
yes |
no |
This is implicitly defined at
the beginning and end of a source file. This is the only block
that does not correspond with any language statement. |
| internal procedure |
no |
trigger editing do repeat for |
yes |
no |
|
| user-defined function |
no |
trigger editing do repeat for |
yes |
no |
Only in the case where the FUNCTION statement is not a
forward declaration (using the FORWARD
keyword). |
| trigger |
yes |
trigger editing do repeat for |
yes |
no |
Triggers can be nested inside
any other block and can be nested inside other triggers. Internal
procedures and functions cannot be nested inside triggers. |
| editing |
yes |
trigger do repeat for |
no |
no |
Editing blocks can be nested
inside any other block EXCEPT for another editing block. |
| do |
yes |
trigger editing do repeat for |
no |
yes |
Only unqualified schema symbol
scope can be affected by these blocks. |
| repeat |
yes |
trigger editing do repeat for |
no |
yes |
Only unqualified schema symbol scope can be affected by these blocks. |
| for | yes |
trigger editing do repeat for |
no |
yes |
Only unqualified schema symbol scope can be affected by these blocks. |
The current parser implements block support for all of the above.
The following flowchart depicts the high level logical flow of the parser. It is this flow that recognizes and enables the block structuring of the resulting tree.
Please see the following for more details:
- ProgressParser external_proc()
- ProgressParser block()
- ProgressParser single_block()
- ProgressParser procedure()
- ProgressParser function()
- ProgressParser inner_block()
- ProgressParser statement()
- ProgressParser assignment()
Expression Processing
The expression processing in Progress is quite similar to that of Java. The following notes highlight some key design points.We handle all numeric data types the same since Progress 4GL "auto-casts" integers into decimals (and vice versa) as needed. Any mixed decimal and integer operations generate a decimal internally. If this is ultimately assigned to an integer, it appears that this conversion is not done until the assignment occurs, which would eliminate rounding errors during the expression evaluation. This seems to be true based on the set of testcases run at this time, but we will need to watch for any deviations from this in practice.
Assignments cannot be made inside an expression. If an lvalue is followed by the EQUALS token, the EQUALS is considered an assignment operator, otherwise the operator is considered a relational operator (equivalence).
The base date for Progress 4GL is 12/31/-4714.
Operator precedence is as follows (in ascending order from lowest to highest):
- OR
- AND
- NOT
- =, EQ, <>, NE, <, LT, >, GT, <=, LE, >= GE,
MATCHES, BEGINS, CONTAINS
- binary +, binary -
- *, /, MODULO
- unary +, unary -
- ( )
There are some special built-in functions like IF THEN ELSE which do not follow the generic function call format. For this reason they are implemented as an alternative in a primary expression (see ProgressParser primary-expr()). An example of this can be seen in the ProgressParser if_func() which is the implementation of the IF THEN ELSE.
The only data types that have literal representations are CHARACTER, INTEGER, DECIMAL, LOGICAL and DATE.
Generic support for widget attribute and method references has been added into the ProgressParser primary-expr() rule.
At this time, the P2J parser grammar does not implement operand type checking. This is not feasible to implement using the structure of the grammar itself, however it could be implemented via semantic predicates at some point in the future. Note that the base assumption of this project, that the input files are valid Progress 4GL code makes this somewhat unnecessary. To implement the checks later, use the following list of valid operator/operand combinations based on operand data type:
| Left Operand
Type |
Operator |
Right
Operand Type |
Result Type |
Notes |
| date |
+ |
numeric |
date |
right operand represents # of
days to add to the left operand |
| string |
+ |
string |
string |
string concatenation |
| numeric |
+ |
numeric |
see notes for multiplication |
|
| n/a |
+ |
numeric |
same as right operand |
unary plus is a NOP |
| date |
- |
date |
integer |
returns a number of days
difference |
| date |
- |
numeric |
date |
right operand represents # of
days to subtract from the left operand |
| numeric |
- |
numeric |
see notes for multiplication | |
| n/a |
- |
numeric |
same as right operand |
unary minus is the negation
operator |
| numeric |
* |
numeric |
see notes |
dec * dec = dec dec * int = dec int * dec = dec int * int = int |
| numeric |
/ |
numeric | decimal |
|
| numeric (cast to integer, after
cast it must be > 0) |
MODULO |
numeric (cast to integer, after cast it must be > 0) | integer |
|
| any type |
EQ or = |
same type as left operand |
boolean |
|
| any type | NE or <> |
same type as left operand | boolean | |
| any type | LT or < | same type as left operand | boolean | |
| any type | GT or > | same type as left operand | boolean | |
| any type | LE or <= |
same type as left operand | boolean | |
| any type | GE or >= | same type as left operand | boolean | |
| n/a |
NOT |
boolean |
boolean |
|
| boolean |
OR |
boolean |
boolean | |
| boolean |
AND |
boolean |
boolean | |
| string |
MATCHES |
pattern |
boolean | pattern is a Progress 4GL string
that follows is similar in nature to a regular expression. however the
syntax is different |
| string |
BEGINS |
string |
boolean | |
| lvalue (database field) of
character type |
CONTAINS |
word list |
boolean | this is a list of words with
custom logical AND and OR operators, please see page 960 in the
Progress Language Reference for details; note that this operator is only valid in a WHERE clause but is implemented in the primary expression processing to greatly reduce complexity (and more importantly, parser ambiguity) |
For more details, see:
- ProgressParser
expr() - top level entry point for expressions, implements
1st (lowest) level of operator precedence
- ProgressParser log_and_expr() - implements 2nd level of operator precedence
- ProgressParser compare_expr() - implements 3rd level of operator precedence
- ProgressParser sum_expr() - implements 4th level of operator precedence
- ProgressParser prod_expr() - implements 5th level of operator precedence
- ProgressParser un_type() - implements 6th level of operator precedence
- ProgressParser primary-expr() - implements 7th (highest) level of operator precedence
- ProgressParser literal()
- ProgressParser func_call()
- ProgressParser
if_func()
- ProgressParser lvalue()
- ProgressParser symbol()
Functions
Progress has a wide range of built-in functions. These functions
can support two features that user-defined functions cannot support:- Variable length argument lists. MAXIMUM and MINIMUM are examples.
- Polymorphic return data types. Usually these are driven by
the data type of the input parameters. MAXIMUM and MINIMUM are examples.
A special return type FUNC_POLY has been created to identify those functions that can implement polymorphic return types.
The function support properly handles the forward declaration form of the FUNCTION statement. This adds the function to the namespace but does not include the defining block that is callable. The block structure of the program is properly maintained in both the forward and normal cases.
The following is the list of supported built-in functions.
- functions with no parameters (implemented as built-in variables)
- CURRENT-LANGUAGE
- DATASERVERS
- DBNAME
- FRAME-DB
- FRAME-FIELD
- FRAME-INDEX
- FRAME-NAME
- FRAME-VALUE
- GATEWAYS
- GET-CODEPAGES
- GO-PENDING
- IS-ATTR-SPACE
- LASTKEY
- MESSAGE-LINES
- NUM-ALIASES
- NUM-DBS
- OPSYS
- OS-DRIVES
- OS-ERROR
- PROC-HANDLE
- PROC-STATUS
- PROPATH
- PROVERSION
- PROMSGS
- PROGRESS
- RETRY
- RETURN-VALUE
- SCREEN-LINES
- TERMINAL
- TIME
- TODAY
- TRANSACTION
- functions that do have parameters (actually those in bold have
optional parenthesis)
- ABSOLUTE
- ALIAS
- ASC
- CAN-DO
- CAN-QUERY
- CAN-SET
- CAPS
- CHR
- CODEPAGE-CONVERT
- COMPARE
- COUNT-OF
- CURRENT-RESULT-ROW
- CURRENT-VALUE
- DATE
- DAY
- DBCODEPAGE
- DBCOLLATION
- DBPARAM
- DBRESTRICTIONS
- DBTASKID
- DBTYPE
- DBVERSION
- DECIMAL
- DYNAMIC-FUNCTION
- ENCODE
- ENTRY
- ETIME
- EXP
- EXTENT
- FILL
- FIRST
- FIRST-OF
- FRAME-COL
- FRAME-DOWN
- FRAME-LINE
- FRAME-ROW
- GET-BITS
- GET-BYTE
- GET-BYTE-ORDER
- GET-BYTES
- GET-COLLATIONS
- GET-DOUBLE
- GET-FLOAT
- GET-LONG
- GET-POINTER-VALUE
- GET-SHORT
- GET-SIZE
- GET-STRING
- GET-UNSIGNED-SHORT
- INDEX
- INTEGER
- IS-LEAD-BYTE
- KBLABEL
- KEYCODE
- KEYFUNCTION
- KEYLABEL
- KEYWORD
- KEYWORD-ALL
- LEFT-TRIM
- LAST
- LAST-OF
- LC
- LDBNAME
- LENGTH
- LIBRARY
- LINE-COUNTER
- LIST-EVENTS
- LIST-QUERY-ATTRS
- LIST-SET-ATTRS
- LIST-WIDGETS
- LOG
- LOOKUP
- MAXIMUM
- MEMBER
- MINIMUM
- MONTH
- NEXT-VALUE
- NUM-ENTRIES
- NUM-RESULTS
- OS-GETENV
- PAGE-NUMBER
- PAGE-SIZE
- PDBNAME
- PROGRAM-NAME
- QUERY-OFF-END
- R-INDEX
- RAW
- RANDOM
- RECORD-LENGTH
- REPLACE
- RGB-VALUE
- RIGHT-TRIM
- ROUND
- SDBNAME
- SEARCH
- SEEK
- SETUSERID
- SQRT
- STRING
- SUBSTITUTE
- SUBSTRING
- TO-ROWID
- TRIM
- TRUNCATE
- USERID
- VALID-EVENT
- VALID-HANDLE
- WEEKDAY
- WIDGET-HANDLE
- YEAR
- record oriented functions
- AVAILABLE
- AMBIGUOUS
- CURRENT-CHANGED
- INPUT
- LOCKED
- NEW
- RECID
- ROWID
- other special case functions
- ACCUM
- CAN-FIND
- ENTERED
- IF THEN ELSE
- NOT ENTERED
- SUPER
ProgressParser function()
ProgressParser func_stmt()
ProgressParser func_call()
ProgressParser reserved_functions()
SymbolResolver lookupFunction()
ProgressParser lvalue()
ProgressParser reserved_variables()
SymbolResolver lookupVariable()
Known Limitations
The following are limitations or deviations of the P2J parser from the Progress runtime:- Function call signature processing:
- does not check the signature of the call against the function's signature definition
- does not check the function definition's signature against the
signature of any forward declaration that may have existed
- The END language statement parsing of the optional "documentation" keyword is tolerant of:
- keyword abbreviations
- using keywords that don't match the keyword of the statement that opened the block
- Array subscripting:
- no range checking is done
- to ensure that the initial expression results in a value that is > 0 and <= the size of the array
- to ensure that the range form of the subscript (e.g. FOR integer_constant) remains within the bounds of the array
- no checking is done to ensure that the variable or field being subscripted was defined as an array
- no checking is done to ensure that the subscript expression has an integer type
- DEFINE statements:
- the following statements will accept the GLOBAL keyword when they shouldn't (because the matching is combined with that for DEF VAR, DEF STREAM and DEF TEMP-TABLE)
- BROWSE
- BUFFER
- FRAME
- MENU
- QUERY
- SUB-MENU
- WORK-TABLE/WORKFILE
- DEFINE VARIABLE
- the options are implemented such that they can be specified in any order (as in Progress) but there is no check to make sure that only 1 of any given option is specified
- the INITIAL clause may include literals that do not match in type with the type of the variable (specified in the AS clause)
- DEFINE PARAMETER
- matching for TABLE and TABLE-HANDLE variants is combined which allows for some syntax to be accepted that is not legal in Progress, no checking is done for these conditions
- the INPUT, INPUT-OUTPUT, OUTPUT and RETURN prefixes are made optional to accommodate the DEFINE PARM BUFFER form (when it is mandatory for other forms)
- other forms can match the INPUT, INPUT-OUTPUT, OUTPUT and RETURN prefixes that would not otherwise be possible, no checking is done for these conditions
- has all the same limitations as DEFINE VARIABLE
- DEFINE BUTTON
- IMAGE and IMAGE-UP clauses can both appear in the same define button statement
- no check for multiple instances of the same clause
- DEFINE SUB-MENU
- Since the syntax of this statement is virtually identical with the DEFINE MENU statement, these statements are implemented using the same rule. This means that the DEF SUB-MENU can match the NEW and SHARED keywords though it would never occur in Progress.
- Likewise it is possible to have a simple TITLE clause or the MENUBAR keywords when they wouldn't match in Progress.
- DEFINE MENU
- Since the syntax of this statement is virtually identical with the DEFINE SUB-MENU statement, these statements are implemented using the same rule. This means that the DEF MENU can match the SUB-MENU-HELP keyword though it would never occur in Progress.
- DEFINE WORK-TABLE/WORKFILE
- Since the implementation is shared with DEFINE TEMP-TABLE,
the use of a LIKE table clause can match the USE-INDEX subclause even
though this wouldn't be possible in valid Progress code.
- Built-in functions with no parameters are implemented as predefined variables. Note that this is the correct semantics for Progress, except in Progress these are read-only! No such distinction is made in P2J.
- The individual components of date literals are not checked for validity. See the NUM_LITERAL rule in the lexer for more details on how these are implemented. In particular:
- more than 2 digits can be placed in the month without error
- months = 0 or > 13 can be used
- days = 0 or > maximum possible for the month can be used
- a '-' can be used as the month and day separator in an
expression (Progress normally errors on this and forces you to use a
'/')
- no year 0 checking is used
- Numeric and decimal literals do not support the negative sign (it is generally processed as a unary minus in the expression processing). This probably needs to be changed, by adding support into the NUM_LITERAL rule in the lexer.
- A quirk of the Progress 4GL lexer/parser is that it supports postfixing the unary operators '-' and '+' on numeric and decimal literals (in some conditions and without intervening whitespace). In the P2J lexer/parser, numeric and decimal literals do not currently support the unary postfix '-' and '+' operations. The project has been determined to be free of those, so there is no immediate need to implement them. If such changes were required in the future, the changes can probably be implemented inside the NUM_LITERAL rule of the lexer. See limitation 7 above.
- Schema name lookups have the following limitations:
- No ambiguity checking is done at this time. All names are assumed to be unique, within the namespace being selected by record scope and qualifiers.
- When the BREAK keyword is present in a FOR statement or PRESELECT phrase, the following clauses are not checked to confirm that a BY is present.
- Progress defines the FIELD and FIELDS language keywords.
FIELD cannot be abbreviated, but FIELDS can be abbreviated as
FIELD! This breaks the lexer's keyword lookup mechanism since
both cannot be matched by the same input. Any usage of these
keywords must take this into account and handle the ridiculous
ambiguity that is left behind by such a poor design decision.
- The following are not yet implemented:
- record scoping and the implicit table namespace selection that results
- dynamic namespace modification (aliases, buffers, temp-tables, work-tables)
- index namespace
- sequence namespace
- FIND statement
- the record phrase is allowed to contain LEFT and OUTER-JOIN keywords when they otherwise would be invalid, no checking is done here to ensure valid code
- the record phrase is allowed to contain a field list when it otherwise would be invalid, no checking is done here to ensure valid code
- when using the CURRENT keyword, the core of the record phrase (WHERE, OF...) is still possible when it otherwise would be invalid, no checking is done here to ensure valid code
- DO and REPEAT statement
- the PRESELECT phrase is allowed to contain NO-WAIT and NO-ERROR keywords when they otherwise would be invalid, no checking is done here to ensure valid code
- RUN statement
- parameter processing can accept INPUT-OUTPUT and OUTPUT as optional keywords when this is not possible in Progress, no checking is done for this case
- the internal and external procedure cases are combined, leading to some options or clauses that can occur in both but normally should be specific to one or the other, no checking is done for these cases
- the expression specified in the VALUE() construct is not evaluated so the result is not known
- since the result from the VALUE() doesn't exist, it can't be tested for whether it is an internal or external procedure etc...
- no filesystem checking is done (using PROPATH or any other approach) to determine if a filename reference is valid
- FUNCTION statement
- parameter processing can accept INPUT, INPUT-OUTPUT and OUTPUT as optional keywords when this is not possible in Progress, no checking is done for this case
- a 1st token of BUFFER will be matched when it isn't possible
- an expression will be matched as an alternative
- all of these limitations stem from using a common rule for both
run and function parameters, however in practice valid Progress code
should never violate these limitations so it probably is not an issue
- color phrase
- no support for Windows colors or DOS hex attributes
- at phrase
- loose rules for construction of the location specification (e.g. a COL can be followed by a Y or an X can be followed by a ROW), this is a superset of the Progress constructs but no checking is done for these invalid constructs
- shell command processing (UNIX, DOS, OS2, BTOS, VMS and OS-COMMAND statements)
- Progress can accept an unmatched double quotes character (which is probably just automatically ended at the end of the file). The P2J parser does not accept this syntax.
- Progress has a limitation against using a colon followed by whitespace, which is a compile error. This limitation does not exist in the P2J parser and is not checked for by this rule.
- widget phrase
- Does not support the direct column or cell references in a
browse widget (these are just variable or field names but they
naturally conflict with widget names and widgets should probably take
precedence). To handle this it might be necessary to keep a
namespace of all widgets in any browse so that this list can be checked
first to eliminate ambiguity.
- editor phrase
- does not enforce that the phrase requires a mandatory size
phrase
- radio-set phrase
- does not enforce that the phrase requires a mandatory radio-buttons clause
- All rules that process options in any order are implemented such that there is no checking on whether a particular construct appears more than once. In cases where Progress does implement such a check, the P2J parser is less strict and will not provide a warning.
- All namespace processing generally does not check to ensure that the same name does not get defined twice. The last one defined will define the token type, though in valid Progress code this should never be an issue.
- SET statement
- To resolve conflict between the field list and field = expression constructs that are peer alternatives in this statement, a common implementation was used with left factoring. This utilizes a generic rule (field_clause) that can include some matching that would not otherwise be possible in a SET statement.
- The editing phrase is implemented in the same rule that
implements DO, REPEAT and FOR blocks. This was done because the
syntax is identical. It has the side effect that one could embed
and match a DO, REPEAT or FOR block instead of an EDITING block.
No checking is done for this case but it should not occur in valid
Progress code.
- UPDATE statement
- This shares the same implementation as SET, so it shares the same limitations (see above).
- In addition, there is an UNLESS-HIDDEN keyword that can only occur in a SET and not in an UPDATE, when processing records. This can still be matched though it is not valid Progress.
- Keyword implementation sometimes differs from Progress docs due to lack of documentation (the keywords exist but are not documented) or the documentation is wrong.
- The as_clause, as_field_clause and color_phrase all provide "special" abbreviation processing that extends unusual levels of abbreviations support (e.g. 'logical' can be abbreviated to 'l'). In particular, shorter abbreviations can be used in these locations than can be used elsewhere. This abbreviation support supplements the standard support implemented in the lexer's mSYMBOL rule.
- The func_return clause allows logical to be abbreviated down to
log though this is not documented. This conflicts with the log
keyword (which is a function). The KW_LOGICAL keyword has been
forced to abbreviate down to 4 chars and then in this rule and in the
handle_to rule, both KW_LOG and KW_LOGICAL are matched. In the case of
a match to KW_LOG, it is rewritten to KW_LOGICAL. This is
separate from the other (more extensive) special abbreviation support
for data/field type keywords, since other data/field type keyword
abbreviations DO NOT work here. Go figure.
- Undocumented keywords (warning: some of our implemented keywords are undocumented and not in this list yet):
- ABORT
- BACKSPACE
- BACK-TAB
- BOTH
- BOTTOM
- COMPARE
- CURSOR-DOWN
- CURSOR-LEFT
- CURSOR-RIGHT
- CURSOR-UP
- DELETE-CHARACTER
- END-ERROR
- ENTER-MENUBAR
- GET-BITS
- GET-BYTES
- GET-BYTE-ORDER
- GO
- HOME
- INSERT-MODE
- LEFT
- LEFT-END
- MEMPTR
- MESSAGES
- NEXT-FRAME
- NORMAL
- OBJECT
- PREV-FRAME
- PUT-BITS
- PUT-UNSIGNED-SHORT
- RECALL
- RESULT
- RIGHT
- RIGHT-END
- SCROLL-MODE
- SERVER-SOCKET
- SOCKET
- TAB
- TOP
- USER (a reserved keyword, that is an abbreviation for USERID
which is a function, though USERI is NOT valid!)
- X-DOCUMENT
- X-NODEREF
- Some keywords describe the wrong prefix for an abbreviation in the docs, where it is different (e.g. RIGHT-ALIGNED specifies that the minimum abbreviation is RETURN-ALIGN which is obviously absurd) the obvious abbreviation has been substituted (e.g. RIGHT-ALIGN for RIGHT-ALIGNED).
- Some keywords describe the wrong prefix for an abbreviation in the docs, WHERE THERE IS NO abbreviation at all (e.g. IS-LEAD-BYTE states that IS-ATTR is the abbreviation which is simply wrong plus IS-LEAD-BYTE CAN'T be abbreviated at all in practice).
- Some keywords have minimum abbreviations that can conflict with other keywords, even though the unabbreviated version cannot be used in the same location as the keyword with which it conflicts.
- WIDTH and WIDTH-CHAR (minimum abbreviation 5 chars)
- Some keywords are described as reserved when they are not in fact reserved:
- PARENT
- Some keywords don't describe an abbreviation at all, but in fact Progress allows them to be abbreviated:
- TRANSACTION can be abbreviated to TRANS (at least it can be
in the REPEAT statement).
- Key label processing is done very generically (it uses the symbol rule). In the future, one could make an exhaustive list of the labels using the PROTERMCAP file as input.
- The key_function rule matches a limited set as defined on p. 785 in the language reference and on p. 6-25 of the programming handbook. This is what is documented to work, but during experiments it was found that the larger set of key functions list on p. 6-19 of the programming handbook are also accepted. We did not find an easy way to prove whether the key functions so defined would actually work. Since these are not needed at this time, this is deferred until such time as it becomes more useful.
- Trigger block support is implemented using the single_block rule
which allows procedures to be nested (although only 1 level).
This is not valid in Progress and should not be seen in practice.
- ON statement
- In order to use a single rule for this statement, multiple forms where condensed down to the minimum definition. This allows some constructs to be matched that would not otherwise be allowed in valid Progress code. This should not be a problem.
- WAIT-FOR
- The "FOCUS widget" option may not match correctly in the case where the FOCUS system handle is used contiguously with the widget list after the OF keyword. In this case the FOCUS will be matched as a widget not as an option. If this is encountered in practice, the parser will require changes and the rules for matching will need to be more clearly defined.
- OPEN QUERY statement
- This implementation supports the full, standard record phrase
syntax even though this differed slightly from the record phrase as
documented in the reference manual entry for OPEN QUERY. For
example, there is no literal form and no OUTERJOIN keyword that would
follow the LEFT keyword. It is not known if these are just errors
in the docs or if this is a real issue.
- REPOSITION statement
- TO RECID can match multiple RECID expressions even though this is not possible in valid Progress.
- Record Scoping
- Tables may be promoted to the current scope too eagerly! This may cause an obscure problem, although no instances of this problem have been found yet. Watch for this carefully. See above for more details.
- INPUT THROUGH/THRU, INPUT-OUTPUT THROUGH/THRU and OUTPUT THROUGH/THRU
- All of these are implemented using a common rule and this rule uses a rule reference that includes options for the INPUT FROM and OUTPUT TO rule. This means that there are cases that can match that wouldn't be able to match in valid Progress code.
- RAW-TRANSFER statement
- Due to the choice of implementation it is possible to match a
field to field copy, which is not normally possible in valid Progress
source.
- RELEASE statement
- No changes to record scoping occur during this statement, though it is possible that the scope should be deleted. This is not as simple as just calling the SymbolResolver.deleteSchemaScope() since the ProgressParser.inner_block() must be notified not to delete the same scope. This is complicated (it can't be done with a simple state variable) because of nesting. Watch for any obscure problems that might arise because of this.
- Unimplemented Language Statements
- CALL
- CLOSE STORED-PROCEDURE
- CREATE automation object
- DDE ADVISE
- DDE EXECUTE
- DDE GET
- DDE INITIATE
- DDE REQUEST
- DDE SEND
- DDE TERMINATE
- DEFINE IMAGE
- DISABLE TRIGGERS
- GET-KEY-VALUE
- LOAD
- LOAD-PICTURE
- PUT-KEY-VALUE
- RAW
- RELEASE-EXTERNAL
- RELEASE-OBJECT
- RUN STORED-PROCEDURE
- RUN SUPER
- SET-BYTE-ORDER
- SET-POINTER-VALUE
- SUBSCRIBE
- SYSTEM-DIALOG COLOR
- SYSTEM-DIALOG FONT
- SYSTEM-DIALOG GET-FILE
- SYSTEM-DIALOG PRINTER
- SYSTEM-HELP
- TRANSACTION-MODE AUTOMATIC
- TRIGGER-PROCEDURE
- UNLOAD
- UNSUBSCRIBE
- USE
Implementation Guide
This section provides a simple guide that describes how to add features to the parser. This guide may also help one trying to understand how the parser works, by noting the places that must change to add new function.How to Add Keywords:
- Determine if the keyword is reserved and what the minimum abbreviation is (if any).
- Define a new token type name with a prefix of "KW_" and a keyword
specific string. For example, KW_DEFINE is the name of the token
type for the DEFINE keyword. This name cannot already be in use
(it must be unique). By convention, these names are all uppercase
and have a maximum of 11 characters (including the standard KW_ prefix).
- Add this name (followed by a semicolon char) into the "tokens { }" section of the ProgressParser (progress.g). If the keyword is reserved, make sure it is added in between the BEGIN_RESERVED and END_RESERVED types. Otherwise add the name between BEGIN_UNRESERVED and END_UNRESERVED.
- Add an entry to the Keyword[] array in the initializeKeywordDictionary()
method of the ProgressLexer. That method's javadoc describes this
process in more detail.
- Make a list of all keywords that can be used in all variants of the statement.
- For each keyword, use the above process to add these to the parser and lexer.
- Define a new rule name for the rule to implement the statement's function. The convention is to use all lowercase characters, with a descriptive name appended with "_stmt". For example, the DEFINE VARIABLE rule name is def_var_stmt.
- Add this name as an alternative in the stmt_list rule of the ProgressParser.
- Add a new rule with this name. Use the defined keywords and other rules as needed. In many cases, common rules can be used from multiple locations in the parser.
- Choose the root of the subtree built from this rule. This
must either be an artificially created node (note: this can be tricky
to implement properly and their usage entails limitations) or a token
reference that is postfixed with the caret ^ symbol. If there is
a set of alternative tokens, each can/should be specified with the
caret so that whichever of them is matched is the subtree root.
Rule references cannot be made the root using a caret but they can be
explicitly forced into the root manually. See the ANTLR
references (and most importantly the sample grammars) for more
details. Usually, the primary language keyword defining the
statement is an explicit token reference and is made the subtree
root. Only one given node can effectively be made the root using
the caret because "the last one wins". This means that if 2
tokens are both present and matched, and both are specified as tree
roots, then the last one matched is the top root and the other is a
child that has all tokens previously matched as children. Most
language constructs don't fit into this model well.
- Consider using other "helper" rules by reference. These can be created as needed and are highly useful even if they are only used in one place. The primary reason is to allow ANTLR to generate the code to naturally build the tree structure the way you want. In many language statements there are clauses or options that have associated data or even lists of data (e.g. the INITIAL or LABEL options to the DEFINE VARIABLE statement). The best tree structure for these options is to root the associated data at the option keyword. If the option syntax is implemented "inline" with the language statement rule, then the option keywords and associated data would be siblings that are all rooted as children of the primary language keyword for the rule. This is not optimal for subsequent processing. Instead, if the definition is "pushed down" into a separate rule, then one can specify a more natural root for that rule (e.g. the option keyword) and all other tokens would naturally be children of that root. Then that subtree would be a child of the main language statement's keyword, which is most likely what you want.
- If the statement is a multi-word statement (e.g. "define
variable"), create a single artificial token to uniquely represent that
multi-word statement. Create an artificial root or replace the
root token's type with this special token to make tree processing
easy. In particular, it is critical that the single child token
of the "STATEMENT" token is the unique token that identifies this
language statement.
- For the variable/function name, use the above process to add this keyword to the parser and lexer.
- Determine the return data type of the function or the type of the variable. This data type must be mapped into one of the token types prefixed by FUNC_ or VAR_. See Data Type Support for more details. In the case where a function has different return types based on the input parameters, the type should be set to FUNC_POLY.
- Add the variable/function name and the data type to the list of addGlobalVariable() calls in initializeVariableDictionary() or addFunction() in initializeFunctionDictionary() in the ProgressParser. These methods preload the respective dictionaries with the variable and function definitions for built-ins.
- If the variable or function name is a reserved keyword, add this keyword as an alternative in the reserved_variables or reserved_functions rules as appropriate.
AST Support
A variety of support has been built to customize and complete processing of ASTs. The support built into ANTLR serves as a base, but is incomplete for any real or complex processing of such syntax trees.Aast and AnnotatedAst
An interface has been created to provide a generic set of services for AST node processing, this is the Aast interface. The only implementation of this interface is in the AnnotatedAst class. All AST nodes generated in the parser are created as AnnotatedAst instances and can be accessed for most purposes using the Aast interface.This interface provides the ability to handle the following:
- Query a Long ID that is a project-unique reference to this specific AST, even after the AST has been persisted to file and reread back into memory.
- Query the parent AST node and other tree metrics such as the
depth of the node from the root, the number of children and the path
string from this node to the root.
- Remove this AST from the parent's list of children.
- Get the source filename from which this node was derived.
- Convert the token type into a symbolic name (e.g. FUNC_INT).
- Obtain an iterator to the entire subtree rooted at this node.
- Get and put Long, Double, Boolean and String annotations into a
node-specific map.
For the purposes of the rest of this document, it is assumed that all AST nodes are of type AnnotatedAst, even when references as an AST.
For more details, see:
Aast
AnnotatedAst
Generator
The process of creating an AST can be complex as it involves multiple steps. The original source file must be found, then preprocessed. The preprocessed source is then read by the lexer which tokenizes the file into a stream of tokens. The parser reads this stream of tokens and generates an AST. The parent links and unique IDs of this AST are then generated/fixed up in each AST node using a recursive tree walk. The resulting AST root node (with all necessary linkages...) is returned to the user for processing.This multi-step process must be handled in a very specific way and is complex enough that it is best done in a single location. The AstGenerator class provides this service. In addition to managing the generation process, it also provides caching/persistence and file output services for each step. For example, the preprocessor output can be cached in a file and reused upon future runs. The following output is possible:
- Preprocessor output is cached in a <source_filename).cache
file. Subsequent runs will read from this file if it exists and
is newer in timestamp than the source file. This caching saves a
significant amount of processing time on some source files.
- Lexer output is written to a <source_filename>.lexer file. It is for debugging/development purposes only and will be overwritten on each run.
- Parser output is written to a <source_filename>.parser file. It is for debugging/development purposes only and will be overwritten on each run.
- The resulting AST can be persisted into a
<source_filename>.ast XML file. This file will be used in
lieu of lexing/parsing if it exists and is newer in timestamp than the
source file. This persistence saves a significant amount of time
on all files and is valid until the source file changes or the parser
generated AST results change in structure or content. The
persistence is handled by the AstPersister
class.
For more details, see:
AstGenerator
ScanDriver
Persister
The generation of ASTs can be a time consuming process. Since it is deterministic (the results do not change from one run to another unless the inputs or the processing changes), storing the resulting AST in a file is a significant time savings for future processing. This can be done one time and then the AST can be read back from file very quickly. Processing this way also avoids the need to ever have all ASTs for an entire project in memory at once since any AST can be obtained and/or saved off quickly.The AstPersister provides read and write persistence services. It is aware of how to persist an AnnotatedAst including all Aast specific data such as IDs and annotations. The resulting file is an XML file for which the grammar is known only in this class.
For more details, see:
AstPersister
Registry
In order to provide the ability to link or cross-reference between nodes in 2 or more separate ASTs, a project-unique persistable ID mechanism has been created. This provides the benefits of a Unified AST model without requiring multiple ASTs to be linked by object references in memory. It also provides the ability to link or cross-reference between Progress generated AST nodes and Java AST nodes in a seamless manner.To make such references unique across the project, a registry of files is used. Each file (Progress source or Java target) in the project gets a unique 32-bit integer ID. This ID can be converted into a filename found via the registry. In addition, each node in an AST gets a unique Long ID that is a combination of this file ID (in the upper 32-bits) and an AST-unique node ID (in the lower 32-bits). This long value is persisted into the XML file and is read back in each time the XML file is reloaded. This allows specific AST nodes to be referenced using a single Long value. The AST and the specific node in question can be found, loaded and accessed with nothing more than this Long ID.
The AstRegistry is the core of this implementation.
For more details, see:
AstRegistry
DumpTree
For debugging, reporting and other development purposes, it is important to be able to generate a human readable text representation of any AST. A helper class DumpTree has been created to provide such a service. This is used to generate "parser output" in both ParserTestDriver and AstGenerator. The following is an example of the output:statement [STATEMENT] @0:0
if [KW_IF] @38:1
expression [EXPRESSION] @0:0
if [FUNC_POLY] @38:4
> [GT] @38:9
x [VAR_INT] @38:7
y [VAR_INT] @38:11
then [KW_THEN] @38:13
true [BOOL_TRUE] @38:18
else [KW_ELSE] @38:23
no [BOOL_FALSE] @38:28
then [KW_THEN] @38:31
inner block [INNER_BLOCK] @0:0
do [KW_DO] @39:1
block [BLOCK] @0:0
statement [STATEMENT] @0:0
message [KW_MSG] @40:4
expression [EXPRESSION] @0:0
"then part of if block" [STRING] @40:12
else [KW_ELSE] @42:1
statement [STATEMENT] @0:0
message [KW_MSG] @43:4
expression [EXPRESSION] @0:0
"else part of if block" [STRING] @43:12
Note that the indention level indicates the parent/child relationships. Each line is a different AST node and the file is ordered from the root node to the last child in a depth-first, left-to-right tree walk. The leftmost text on each line is the original text from the source file, the next text (in square brackets) is the symbolic name of the token type and the @x:y is a notation for line number and column number respectively (in the source file). Any entry that has a @0:0 is an artificially created token by the parser which was created to organize the tree for easier processing or searching.
For more details, see:
DumpTree
Call Tree Processing
Progress Linkage Types
A Progress application has 2 types of control flow changes: internal and external. Internal control flow is all contained within a single procedure, function or trigger block. Such control flow uses language constructs such as IF/THEN/ELSE, CASE, LEAVE, NEXT and the block processing statements FOR, REPEAT and DO. External control flow is when the running procedure/function/trigger transfers control to a different procedure/function/trigger/process. Such a change of external control flow is done by means of a "linkage mechanism". The following is the complete list of all possible linkage mechanisms by which Progress code can transfer external control. Please note that despite the use of the term "external", the transfer of control from (for example) an internal procedure in one source file to a function in the same source file is still considered an external control flow change as it transfers control to something external to the current procedure/function/trigger.The table is split into 3 types of entries: invocations, entry points and event processing exits. An invocation is mechanism by which an external linkage is called. An entry point is an exposed target for external linkage which is accessed via an invocation mechanism. An event processing exit is not an entry point and doesn't directly invoke another piece of code but they indirectly allow event code to be called by stopping the normal procedural flow and allowing queued events to be dispatched.
All entries listed as "external file linkage" refer to the fact that these linkages can invoke logic in or be invoked by a separate Progress procedure or a non-Progress executable (e.g. DLL, DDE, external command). This is different from the use of "external control flow" referenced above.
| Mechanism |
Type |
External File Linkage |
Supported |
Description |
| APPLY statement | invocation |
Y |
Y |
Invokes a specific event in a
procedure and/or on a widget. This event can be defined in a separate procedure (identified by a user-defined handle or possibly a system handle or something returned from method/attribute access) OR can be invoked upon a shared widget (something defined in another source file and passed in for usage in this procedure) which would cause the event definition in the original source file to be executed. There is no way to use the APPLY statement to cause a new procedure to be loaded. Instead APPLY inherently requires that any externally referenced widget or procedure must already have been loaded (and is still on the procedure stack). |
| BTOS | invocation | Y |
Y |
Executes command via the BTOS command processor. |
| CALL statement | invocation | Y |
N |
Invokes a user defined external C function. |
| DDE * statements | invocation | Y |
N |
Interfaces with Windows DDE. |
| DOS | invocation | Y |
Y |
Executes command via the DOS/Windows command processor. |
| DYNAMIC-FUNCTION function | invocation | Y |
N |
Executes a user defined function, possibly in an external procedure (identified by a user-defined handle or possibly a system handle or something returned from method/attribute access). |
| EDITING phrase/block | entry point |
N |
Y |
Defines a block that executes on each key press event; it is called in-line with the update, set or prompt-for statements and serves to modify/expose the key processing where otherwise only the default processing would occur; this is a specialized type of callback which is only in scope for the duration of the enclosing language statement, so it is not callable directly by user-written Progress code. |
| EVENT-PROCEDURE phrase |
entry point |
N |
N |
Defines a call back for when a procedure executed via RUN ASYNCHRONOUS completes. |
| FUNCTION | entry point | Y |
Y |
Defines a user defined function
with a specific name (if it is not a FORWARD declaration). If this is declared as "IN procedure_handle" or "IN SUPER", the function actually resides in another source file. |
| function call |
invocation |
Y |
Y |
An invocation of a known
user-defined function or built-in function as part of an
expression. It is possible that the definition resides in another
source file. See FUNCTION. |
| INPUT THROUGH (INPUT THRU) | invocation | Y |
Y |
Executes an external program and obtains Progress procedure input from the stdout of the external program. |
| INPUT-OUTPUT THROUGH
(INPUT-OUTPUT THRU) |
invocation | Y |
Y |
Executes an external program and pipes Progress procedure output to the stdin for the external program and obtains Progress procedure input from the stdout of the external program. |
| method call |
invocation |
N |
Y |
An invocation of a built-in method as part of an expression. |
| ON statement |
entry point | Y |
Y |
Defines a block associated with a specific event. |
| OS2 | invocation | Y |
Y |
Executes command via cmd.exe. |
| OS-COMMAND |
invocation | Y |
Y |
Executes command via an OS specific command processor. |
| OUTPUT THROUGH (OUTPUT THRU) |
invocation | Y |
Y |
Executes an external program and
pipes Progress procedure output to the stdin for the external program. |
| PROCEDURE statement |
entry point | Y |
Y |
Defines an internal
procedure. It is possible to invoke this from another source file
using "RUN procedure IN handle". |
| PROCESS-EVENTS statement |
event processing exit |
N |
N |
Synchronously dispatch pending events, then continue. |
| PROMPT-FOR statement |
event processing exit | N |
Y |
Executes a WAIT-FOR internally. |
| PUBLISH statement |
invocation | Y |
N |
Generates a named event. |
| RUN path-name<<member-name>> | invocation | Y |
N |
Runs a specific member in an r-code library. |
| RUN procedure_name | invocation | Y |
Y |
Runs an internal procedure or calls an entry point in a shared library (e.g. a Windows DLL). |
| RUN procedure_name in handle | invocation | Y |
N |
Runs an internal procedure defined in another file that is in scope on the stack or which has previously been run with the persistent option. |
| RUN STORED-PROCEDURE statement |
invocation | Y |
N |
Executes a stored procedure on a SQL-based dataserver. |
| RUN SUPER statement |
invocation | Y |
N |
Runs the super procedure version of the current internal procedure. |
| SET |
event processing exit | N |
Y |
Executes a WAIT-FOR internally. |
| SUBSCRIBE statement | entry point | Y |
N |
Requests notification of a named event. |
| SUPER function | invocation | Y |
N |
Executes SUPER version of a user defined function. |
| TRIGGERS phrase | entry point | Y |
N |
Associates a block with a specific event. |
| UNIX |
invocation | Y |
Y |
Executes command via sh. |
| UPDATE |
event processing exit | N |
Y |
Executes a WAIT-FOR internally. |
| VMS |
invocation |
Y |
Y |
Executes command via VMS command
shell. |
| WAIT-FOR statement |
event processing exit | N |
Y |
Dispatch all events until a specific stop event occurs. |
Root Nodes List
All files consisting the application source tree can be separated into two categories. The vast majority of the files provide some functionality used by other files in the application, but some files do not provide any functionality to other files. The purpose of these files is to be the primary entry point for an applications. These files are called root files (nodes). Only those files are considered in creating call graphs and there will be exactly one call graph created for each root node.The list of root nodes is prepared manually based on the conversation with the customer and source code review.
There are two possible scenarios. In simple case customer does know all actually used root nodes (main modules) in the application. But for application with a long history of development this is unlikely. They may have unused files which may look like standalone utilities, abandoned ad-hoc procedures and utilities, development-time and test applications. All of them are redundant and should not be included in the list of root nodes. In this case other process is used.
The process of finding root nodes is iterative. Initially potential root nodes are found by review of application sources. The resulting list of root nodes is passed to the call graph generator and resulting call graphs and dead file list provide more information which allows to adjust list of root nodes which is again passed to the call graph generator. When list of root nodes is more or less sustained then it is discussed with the customer in order to determine which root nodes are actually necessary and which are not.
For more details, see:
Call Tree Graph
The call tree graph provides information about possible execution/invocation paths in the application.In order to build the call tree graph, the analysis of the invocation of external modules (files) is performed. The analysis performed in the following way: starting from the the AST of the root node (file), each AST is loaded and scanned in order to determine which external files are invoked by the program. All found files are added into the appropriate node of the call graph as immediate child nodes. If any of these files are not processed, then they are added into the queue of the files which need to be processed. Then processing is repeated for all files in the queue.
Note that the methodology for this analysis is completely based on the list of "root nodes" or "primary entry points" to the application. If the the rootlist.xml (which defines these) is incorrect then the call graphs will be incorrect. The root list may include an entry point which is not actually used or is not part of the application being converted. In this "false positive" case, there will be call graphs generated that are not to be converted. The root list may also be missing an entry point that is used and if so then all files accessible only from such entry points will inappropriately appear in the dead file list.
The analysis of the AST is not as obvious as it may appear. The problem is hidden in the possibilities provided by the language and actively used in the application. In particular, the RUN statement allows calling a file whose name is stored in the variable or which is generated using any expression that returns a character value. The actual value of the variable can be calculated at run time or retrieved from the table. In some cases the variable is shared and assigned in a number of places through the entire application. Invocation is performed by assigning a value to the variable and calling another file which invokes the requested procedure. This case is most complicated because the actual RUN statement invocation and the procedure which is logically the caller are located in different source files.
Another difficult case is the dynamic writing of a Progress source file (at runtime) and then the subsequent invocation of the generated file. This itself is difficult to detect but is made more complicated by the fact that the generated file may call other application files.
Since some forms of external program invocations are not "direct", these expressions can (and usually do) reference runtime data or database fields, the filename often cannot be derived from inspection of the source code. In each instance of this, a hint for that source file is encoded to "patch" the call graph at these points. XML elements are prepared which contain possible values of the variable for each RUN VALUE() statement an associated program file. These hints are stored in a file named using the source filename (including full path) and then adding a ".hints" suffix. These values are then loaded during processing and handled as if they were collected from the AST. Hints files are prepared manually, as a result of analyzing application code, execution paths and real data extracted from the tables.
The call graph is stored as an XML file. The nesting of the XML elements shows the relationship of caller (parent) to called (child). The order of children is the order of the calls. At this time, the call graphs do not represent any duplicate calls or recursive calls. This means that only the first instance of any given file is represented in a call graph. No matter how many times a particular procedure is invoked it will only appear in the graph one time.
All nodes in the call graph are external procedures (Progress .p or .w source files) that are accessible from a particular root entry point. It only reflects the *external* files invoked, internal procedure/function linkage is not reflected. This is by design because these call graphs are essentially lists of ASTs to process (and the order in which the ASTs will be processed). An AST is equivalent to a file. Please note that due to the preprocessing approach of Progress, include files are not necessarily valid source files. All ASTs are created after preprocessing, so the contents of the include files are already embedded/expanded inline. While each file does have a record (a preprocessor hints file that is left behind as an output of the preprocessing step) of exactly which include files were referenced, no include file is represented directly in the call graph itself. Only source files (normally named .p or .w) are represented.
Although many applications make heavy use of execution of operating system specific external processes (e.g. shell scripts, native utility programs), this is not a consideration in terms of generating a call graph of accessible Progress 4GL procedures.
All duplication has been removed from the graph, which transforms the graph into a tree. This is done to make it easy to persist to XML, to make it easy to process and because once an AST is processed it doesn't need to be processed again. In other words, this simplification does not cause any limitations, it only makes things easier.
To create a call graph, the ASTs are walked starting at a root entry point and an in-memory graph is built. The processing dynamically takes into account any added graph nodes as they are added. So the graph continually grows until all ASTs that can be reached are included. The processing of each AST is performed by the Pattern Engine which applies specially designed rule set. The Pattern Engine is started by the specially designed driver CallGraphGenerator.
The rule set in combination with specially designed worker class performs the main part of the processing: it recognizes patterns in the ASTs which represent various invocation methods. The methods provided by the worker class are used to add files not the node and maintain list of ASTs which are processed and waiting for the processing. The rule set consist of two main parts: rules which recognize standard expressions and rules which recognize application-specific patterns. It must be noted that some statements are recognized but no actual processing (adding nodes) is performed. The purpose of these rules is to generate log entries which can be used to detect potential problems during further processing.
The worker class names CallGraphWorker serves following purposes:
- Stores and maintains dynamically changing list of ASTs which are already processed and such that are waiting for processing in the queue. Maintains iterator for this list.
- Implements dead files list processor (see below for the more details).
- Provides methods which can are invoked from the rules in set and provide interface to the list of ASTs and dead files list processor.
<?xml version="1.0"?>
<!--Persisted CallGraph-->
<graph-root>
<call-graph-node filename="./path/root.p">
<call-graph-node filename="./path/referenced1.p">
<call-graph-node filename="./path/referenced1_1.p" />
<call-graph-node filename="./path/referenced1_2.p" />
</call-graph-node>
<call-graph-node filename="./path/referenced2.p">
<call-graph-node filename="./path/referenced2_1.p" />
<call-graph-node filename="./path/referenced2_2.p">
<call-graph-node filename="./path/referenced2_2_1.p" />
<call-graph-node filename="./path/referenced2_2_1.p" />
</call-graph-node>
</call-graph-node>
</call-graph-node>
</graph-root>
The node with file name "./path/root.p" represents root node of the sample call graph. Nodes with file names "./path/referenced1.p" and "./path/referenced2.p" represent files directly called by the code in the "./path/root.p". Files "./path/referenced1_1.p" and "./path/referenced1_2.p" are directly called by "./path/referenced1.p" and so on.
The main Pattern Engine configuration for the call graph generator are located in the generate_call_graph.xml and in a set of .rules files which contain actual rules grouped by the purpose. The set of .rules files includes invocation_reports.rules, run_generated.rules, run_statements.rules and customer_specific_call_graph.rules. First three files contain common rules, while last one contains rules specific for the particular environment.
For more details, see:
- CallGraphGenerator
- CallGraphWorker
- CallGraphPersister
- Pattern Engine
- p2j/rules/callgraph/generate_call_graph.xml
- p2j/rules/callgraph/invocation_reports.rules
- p2j/rules/callgraph/run_generated.rules
- p2j/rules/callgraph/run_statements.rules
- pattern/customer_specific_call_graph.rules
Dead File List
As a part of call graph generation, information about invoked files is collected, and along with the full list of application files, is used to build a report about orphaned ("dead") files which are not reachable in the real application via any of the existing call paths.If a file appears in any of the call graphs (.ast.graph files), it won't appear in the dead files list and vice versa. The dead files list also identifies include files that are completely unreferenced (in live code).
Any of the dead files may be referenced in other dead code somewhere (either a dead include file or a dead .p or .w file) but they are still inaccessible. At this time there may be (logically) inaccessible code in "live" files and at this time the call graph processing doesn't take such things into account. So if such code adds files to the call graph, they will be treated as "live".
The generation of the dead files list is performed in following way. At startup call graph generator scans entire sources tree and collects all application files. Then, when generator scans AST files, each scanned file is marked as "live" (referenced) in the list of all application files. Also, for each scanned AST file preprocessor hints file is loaded and list of include files is retrieved. All include files also marked as referenced in the list of all application files. When generator finishes scanning of AST files, list of all application files contains all referenced files marked as "live". Files which are not marked a live then printed in resulting report. Since each root node calls only subset of all really used files, correct list can be obtained only after building call graphs for all root nodes. Otherwise some files which are referenced only from one root node will be incorrectly reported as "dead".
For more details, see CallGraphWorker.
Copyright (c) 2004-2005, Golden Code
Development Corporation.
ALL RIGHTS RESERVED. Use is subject to license terms.
ALL RIGHTS RESERVED. Use is subject to license terms.