-
Interface Summary Interface Description HintsTags Defines tags used in preprocessor hints XML documents.PreprocTokenTypes -
Class Summary Class Description ArgumentHint Keeps information about an include file argument.BracesLexer Tokenizes the input stream of characters from the portion of Progress source file between braces and returns tokens to the caller according to the needs of preprocessor.BracesParser Parses all the preprocessor constructs coded in braces which are argument references, preprocessor builtin variable references, defined variable references and the include files.BuiltinSymbol Represents a built-in preprocessor variable which can resolve its value dynamically rather than being set to a static text value.BuiltinVariable Represents the pool of Progress preprocessor builtin variables.BuiltinVariable.BatchMode Produces the BATCH-MODE value.BuiltinVariable.FileName Produces the FILE-NAME value.BuiltinVariable.LineNumber Produces the LINE-NUMBER value.BuiltinVariable.Opsys Produces the OPSYS value.BuiltinVariable.Sequence Produces the SEQUENCE value, incrementing the value each time it is referenced.BuiltinVariable.WindowSystem Produces the WINDOW-SYSTEM value.ClearStream Implements an intelligent input stream for the Preprocessor which handles alternative codings, various escape sequences with tildes and the {} constructs internally.Environment Encapsulates the shared environment for parsers, lexers and drivers.FileScope Represents the data associated with Progress files from the preprocessor perspective, such as file name and arguments.Hints Keeps information about elementary hints and organizes them into the tree.HintsTreeNode A preprocessor hints tree node which is an extenstion of TreeNode class.IncludeHint Keeps information about an include file and how it maps to the preprocessor output.Options Represents all the Progress preprocessor options.Preprocessor Implements the external entry points into the Progress 4GL compatible preprocessor and a collection of static utility methods.PreprocessorHints Loads hints information from a preprocessor hints XML file into memory and exposes the data in an easily accessible format.PreprocessorHintsWorker Provides a pattern engine service to query the preprocessor hints linked to an AST.ReferenceHint Keeps information about a symbol reference.Symbol Represents a Progress preprocessor variable put into one of the scopes of the scoped symbol dictionary.SymbolHint Keeps information about a symbol definition.TextLexer Tokenizes the input stream of characters from the Progress source file and returns tokens to the caller according to the needs of preprocessor.TextParser Declares the entry point class of this grammar. -
Exception Summary Exception Description PreprocessorException An extension of the Exception that signals fatal preprocessing errors.
Package com.goldencode.p2j.preproc Description
Implements a full set of classes including lexers, parsers, utility
classes and command line driver code that constitute a stand alone
Progress 4GL compatible language preprocessor.
Preprocessor Tasks
Package Class Hierarchy
ClearStream Class
TextLexer
TextParser
StatLexer
StatParser
BracesLexer
BracesParser
Command Line Driver
Developer Technical Notebook
Known Issues
The further analysis shows that even inside of the preprocessor, there are multiple views of the input that can be naturally described using more than one grammar.
There is a main grammar that starts preprocessing. It works as a filter and transforms the input on the fly, without creating a syntax tree. All regular Progress language constructs as well as conditional statements are processed there.
As soon as this grammar recognizes other preprocessor statements, it activates another grammar specific to preprocessor statements. This grammar is coded to handle easily all line-oriented preprocessor statements.
Finally, a third grammar is designed to process exclusively the preprocessor references of all kinds, which are coded as a text enclosed in braces.
Preprocessor Tasks
The preprocessor itself is designed to handle a single external
procedure (and an arbitrary number of included files). To
feasibly preprocess the thousands of 4GL source files in a given
project, a Preprocessor Harness will be created.
The Preprocessor is created based on grammars which are used by ANTLR to create a set of lexers and parsers. These grammara are being implemented with all of the preprocessor logic embedded in Java based actions attached to specific rules as necessary. This usage of ANTLR is considered proper for the implementation of a filter. A preprocessor is simple enough to be implemented as a filter.
The Preprocessor conceptually does the following:
Supported operators:
Supported functions:
Useful References to the Progress Language Reference Manual can be found below:
For a more detailed diagram, use this link.
The I/O subsystem of the preprocessor builds on the MultiStream and the ClearStream classes. The MultiStream class provides a generic switchable input stream implementation. This functionality is required for the transparent include files support. The ClearStream class functionality is discussed later.
To keep references to multiple objects the preprocessor needs during its lifetime, an instance of the Environment class is created.
The preprocessor constructor takes a FileScope instance as a parameter. This object represents the top level source file to be preprocessed. The constructor also creates the dictionary with the global scope and associates the given FileScope with it.
An instance of the BuiltinVariable class is created. This automatically populates the global scope of the dictionary with all known builtin variables.
Finally, the parsers and lexers are created and the TextParser is called to start the preprocessing.
See Preprocessor class description for more details.
This approach makes it possible to apply the ANTLR tool to the preprocessor. A separate grammar, braces.g, is created to process the references from inside the ClearStream class. It will be used as many times recursively as there are nested braces on input.
On output from the ClearStream, a regular lexer and parser defined in text.g do their work as if there were no references at all.
This is a rough description of the process. The ClearStream class does more than eliminating references. For full details, see ClearStream class description.
This lexer recognizes:
TextLexer maintains state information of these two kinds:
To make sure the shared state information works properly even though there are known generic problems , every use of this information has to be certified for correctness. The following sections do that for all uses of the shared state information in the TextLexer and ClearStream.
4GL comments generate two signals: entering a comment and leaving a comment. TextLexer sends these signals using
4GL strings also generate two signals: entering a string and leaving a string. TextLexer sends these signals using
The string termination needs both lookahead buffers, however. This is so because strings allow doubled opening character as part of their contents. The lookahead buffer 2 is used to check if it is a doubled opening character (meaning no string closure) or the closing character. Thus, when the recognition is made, both lookahead buffers are used, but the lookahead buffer 2 contains a character which does not belong to the string. When the "leaving a string" signal is sent, it comes exactly one character late to the ClearStream. This constitutes a late signal problem. The problem, however, can be solved through some additional cooperation between the TextLexer and the ClearStream.
The way this shared state signal is used in the ClearStream limits the scope of the problem to just one case: if a Progress 4GL escape sequence which encodes either CR (carriage return) or NL (new line) character immediately follows the string closing character. This is the only troublesome combination, because the ClearStream normally inserts another CR character in front of every converted CR and NL while inside a string. In this case, a CR is inserted due to the late signal problem. But the TextLexer can easily detect this failure in the mSTRING method and fix it right away by consuming this extra character.
See TextLexer,ClearStream, mSTRING for details.
It starts looking at the tokens on input assuming they belong to a block which has to be interpreted. Occasionally it may see &IF - &THEN - &ELSEIF - &THEN - &ELSE - &ENDIF constructs. Those require their expressions to be evaluated.
Expression evaluation is done in three steps:
Skipped blocks are ignored completely leaving no trace on the preprocessor output. Interpreted blocks are made of either 4GL code tokens or the preprocessor statements. TextParser copies the 4GL tokens to the output and activates another grammar, stat.g, to conclude parsing and interpretation of the preprocessor statements.
For details, see TextParser, CallbackResolver, Keyword, ProgressExpressionEvaluator.
This lexer recognizes:
See StatLexer for details.
&GLOBAL-DEFINE and &SCOPED-DEFINE statements create a new preprocessor variable and put it in the appropriate scope. For discussion of scopes implementation, see ScopedSymbolDictionary class description. The defined variable may have an empty string as a value.
&UNDEFINE statement removes the nearest definition of the variable.
&MESSAGE statement outputs the given text to the error stream.
&ANALYZE-SUSPEND and &ANALYZE-RESUME are simply ignored.
The processed statement is then deleted from the input. Comments within the statement, if any, are copied to the output stream.
See StatParser for details.
BracesLexer tokenizes a portion of the input within braces. These are preprocessor references.
This lexer recognizes:
This parser recognizes and properly handles the following constructs:
As the result of an include file reference parsing, no immediate substitute string is produced. Rather, another instance of FileScope is created and chained to the new dictionary scope. For details, see Preprocessor.includeFile.Command Line Driver
The Preprocessor class includes the main method so it can be run from
the command line. The syntax to run the preprocessor is:
This is a sample hints file:
To see the notebook, use this link.
Tab Expansion Issue
The tabs expansion is particularly sensitive to the internal order of
actions. If a line of a source file contains both a Progress reference
{...} of any kind and tabs, then the result would vary depending on the
order of tabs expansion and reference resolution. Here comes a sample
line:
Another known case where the tab expansion issue can be seen is preprocessor variables if their definitions contain tabs.
| Author |
Nick Saxon Greg Shah |
| Date |
September 10, 2007 |
| Access Control |
CONFIDENTIAL |
Contents
IntroductionPreprocessor Tasks
Package Class Hierarchy
Conceptual
Description
Special Character Support
Operator and Function Support
What Is Not Implemented
Useful References
Preprocessor Entry PointSpecial Character Support
Operator and Function Support
What Is Not Implemented
Useful References
ClearStream Class
TextLexer
TextParser
StatLexer
StatParser
BracesLexer
BracesParser
Command Line Driver
Developer Technical Notebook
Known Issues
Introduction
Lexers, Parsers and ANTLR
A good introduction into the field of lexical analysis and parsing can be found here. The implementation of the lexers and parsers for the Progress preprocessor is based on a project called ANTLR.Progress Preprocessor ANTLR grammars
A preprocessor to a programming language has to deal with quite different tasks than the language itself. The view of the input from the preprocessor perspective is different, too. In fact, it is so different, that there are just a few commonalities. Therefore, creating a separate grammar describing the preprocessor's view of the Progress source file makes good sense.The further analysis shows that even inside of the preprocessor, there are multiple views of the input that can be naturally described using more than one grammar.
There is a main grammar that starts preprocessing. It works as a filter and transforms the input on the fly, without creating a syntax tree. All regular Progress language constructs as well as conditional statements are processed there.
As soon as this grammar recognizes other preprocessor statements, it activates another grammar specific to preprocessor statements. This grammar is coded to handle easily all line-oriented preprocessor statements.
Finally, a third grammar is designed to process exclusively the preprocessor references of all kinds, which are coded as a text enclosed in braces.
Preprocessor Tasks
The preprocessor itself is designed to handle a single external
procedure (and an arbitrary number of included files). To
feasibly preprocess the thousands of 4GL source files in a given
project, a Preprocessor Harness will be created.The Preprocessor is created based on grammars which are used by ANTLR to create a set of lexers and parsers. These grammara are being implemented with all of the preprocessor logic embedded in Java based actions attached to specific rules as necessary. This usage of ANTLR is considered proper for the implementation of a filter. A preprocessor is simple enough to be implemented as a filter.
The Preprocessor conceptually does the following:
- Uses an ANTLR generated set of 3 Lexers (to tokenize) and 3 Parsers (to syntactically check and structure the input).
- Implements a filter approach where the input stream (a text file) is preprocessed and written to an output stream (stdout or an output file).
- At a high level, it is byte for byte compatible with the following Progress Preprocessor features:
- special character combinations are expanded wherever they appear in the source files
- each one converts into a replacement symbol
- these are also referred to as alternative codings
- see this table for a list of
the supported chars
- comments
- nested comments are supported
- comments are passed through to the output unchanged
- comments can be placed inside preprocessor directives without
causing a failure
- string literals
- preprocessor references (using curly braces) are expanded
- tilde prefixed escape sequences are left behind
- the resulting string is pass through to the output
- preprocessor variables are created and destroyed using:
- &GLOBAL-DEFINE name replacement_string
- can be abbreviated down to &GLOB
- handles line continuations using tildes
- creates a variable in the global preprocessor namespace
- &SCOPED-DEFINE name replacement_string
- can be abbreviated down to &SCOP
- handles line continuations using tildes
- creates a variable in the scoped preprocessor namespace
- &UNDEFINE name
- include file or run statement arguments are added to the
namespace but are only accessible from the current scope (as in Progress)
- a scoped symbol dictionary is maintained with these names
- argument references are expanded
- named
- {&name}
- {&*}
- positional
- {0}
- {n}
- {*}
- null
- {}
- special preprocessor symbols are replaced
- these are essentially like global preprocessor variables that always exist
- the following are supported:
- BATCH-MODE (boolean value can be controlled via hints)
- FILE-NAME
- LINE-NUMBER
- OPSYS (string value can be controlled via hints)
- SEQUENCE
- WINDOW-SYSTEM (string value can be controlled via hints)
- SpeedScript / WebSpeed related "built-in" variables are supported (but may be redefined which is different from how real built-ins work):
- DISPLAY
- END
- OUT
- OUT-FMT
- OUT-LONG
- OUT-FILE
- OUT-STREAM
- WEBSTREAM
- AMP
- LT
- GT
- QUOT
- preprocessor name references are expanded
- the form they use is {&name}
- The only difference between named argument reference and preprocessor name reference is the origin of the name. The origin of a name is returned via DEFINED(name) preprocessor builtin function. Besides the origin, these two kinds of references work identically.
- deferred expansion is fully implemented using ~{&name} constructs
- include file references
- are expanded into the contents of the include file (if it exists)
- the contents are preprocessed recursively, including any
includes or expansions it may have and so on
- a space character is appended to the contents of the include file
- the following forms are recognized:
- {filename}
- {filename arg1 arg2}
- {filename &arg1=val1 &arg2=val2}
- any other form that cannot be taken as a syntactically correct argument reference
- &MESSAGE and other preprocessor directives are processed
(including abbreviation support)
- tabs are expanded into spaces on output
- all name/variable/argument references are implemented using the dictionary, while honoring the global and non-global scope of each reference.
- conditional inclusion directives are supported
- &IF expression &THEN..block..[&ELSEIF expression &THEN..block..&ELSE..block..]&ENDIF
- conditionals can be nested and can cross newline boundaries
- expressions using the listed operators and functions are fully supported
- decimal, integer, character, date and logical data types are all supported
- all forms of constants (literals) are supported, including unknown value
- the only known feature of the preprocessor that is not implemented is this list of unsupported functions
- all valid preprocessor expression types are supported
- numeric (integer or decimal) which is always cast to an
integer on return and compared to 0 (0 is false, non-zero is true)
- string which is not empty (true) or empty (false)
- boolean which is true or false
- based on the result of the expression evaluation, the blocks of code are either passed through to the output or not
- line continuations are processed so that the preprocessed output looks like made of single lines
- documented combinations like '~', newline
- undocumented combinations like '\', newline
- all documented escape sequences with the tilde '~' character as
well as all undocumented escape sequences with the backslash '\'
character are processed.
- Everything else is unrecognized and is assumed to be the
Progress 4GL language.
- This unrecognized input is supposed to be unchanged and is copied directly to output.
- The preprocessor optionally produces a hints file. The hints file
is a XML file where information about included files, their arguments,
argument usage and reference substitutions is kept.
| Input |
Output |
| ;& | @ |
| ;< | [ |
| ;> | ] |
| ;* | ^ |
| ;' | ' |
| ;( |
{ |
| ;% |
| |
| ;) |
} |
| ;? | ~ |
Supported operators:
| Operator/Function |
Type |
| + |
operator |
| - |
operator |
| * |
operator |
| / |
operator |
| = or EQ |
operator |
| <> or NE |
operator |
| < or LT |
operator |
| > or GT |
operator |
| <= or LE |
operator |
| >= or GE |
operator |
| AND |
operator |
| OR |
operator |
| NOT |
operator |
| BEGINS |
operator |
| MATCHES |
operator |
| MODULO |
operator |
| ( ) |
operator |
| DEFINED() |
Preprocessor symbol dictionary
function |
Supported functions:
- ABSOLUTE
- ASC
- DATE
- DAY
- DECIMAL
- ENCODE
- ENTRY
- ETIME
- EXP
- FILL
- INDEX
- INTEGER
- LEFT-TRIM
- LC
- LENGTH
- LOG
- LOOKUP
- MAXIMUM
- MINIMUM
- MONTH
- NUM-ENTRIES
- OPSYS
- PROPATH
- PROVERSION
- R-INDEX
- RIGHT-TRIM
- RANDOM
- REPLACE
- ROUND
- SQRT
- STRING
- SUBSTITUTE
- SUBSTRING
- TIME
- TODAY
- TRUNCATE
- WEEKDAY
- YEAR
- INT64
- KEYWORD
- KEYWORD-ALL
- LIBRARY
- MEMBER
Useful References to the Progress Language Reference Manual can be found below:
| Reference
Manual Page # |
Contents |
| 9 |
argument reference |
| 12 |
include file reference |
| 17 |
preprocessor name reference |
| 22 |
&GLOBAL-DEFINE directive |
| 24 |
&IF-&THEN-&ELSEIF-&ENDIF
directive |
| 26 |
expression operators |
| 27 |
preprocessor functions |
| 28 |
&MESSAGE directive |
| 29 |
&SCOPED-DEFINE directive |
| 30 |
&UNDEFINE directive |
| 393 |
DEFINED() function |
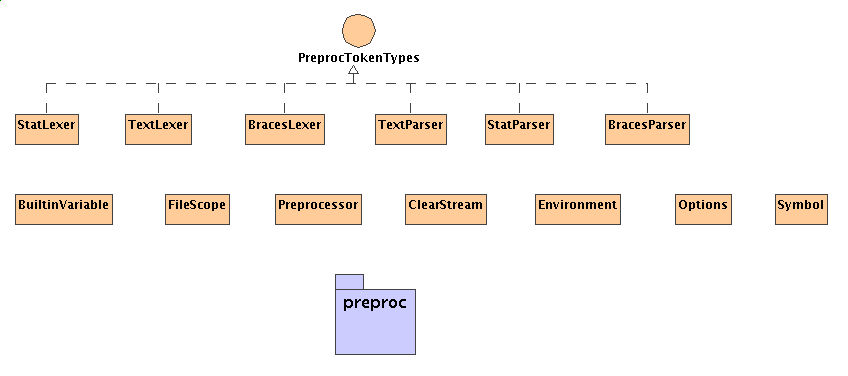
Package Class Hierarchy
The following is a high level UML class diagram of the preproc package:For a more detailed diagram, use this link.
{kind=link}
Preprocessor Entry Point
The main entry point into the preprocessor is its only constructor. The preprocessor is invoked by creating an instance of the class and does its work while in the constructor.The I/O subsystem of the preprocessor builds on the MultiStream and the ClearStream classes. The MultiStream class provides a generic switchable input stream implementation. This functionality is required for the transparent include files support. The ClearStream class functionality is discussed later.
To keep references to multiple objects the preprocessor needs during its lifetime, an instance of the Environment class is created.
The preprocessor constructor takes a FileScope instance as a parameter. This object represents the top level source file to be preprocessed. The constructor also creates the dictionary with the global scope and associates the given FileScope with it.
An instance of the BuiltinVariable class is created. This automatically populates the global scope of the dictionary with all known builtin variables.
Finally, the parsers and lexers are created and the TextParser is called to start the preprocessing.
See Preprocessor class description for more details.
Options
Preprocessor options are represented by Options class. An instance of Options has to be created and initialized before the preprocessor is called. See Options class description for details.ClearStream
The requirement for rescanning of the substitutions for the preprocessor references of all kinds makes it impossible to use ANTLR generated lexers right on the input files. ANTRL generated lexers simply cannot rescan what is a dynamic input. This is where the ClearStream class helps. It creates a static input stream which needs no rescanning. This only can be done by performing transparent substitutions for the references inside the ClearStream and producing another stream where there are no references.This approach makes it possible to apply the ANTLR tool to the preprocessor. A separate grammar, braces.g, is created to process the references from inside the ClearStream class. It will be used as many times recursively as there are nested braces on input.
On output from the ClearStream, a regular lexer and parser defined in text.g do their work as if there were no references at all.
This is a rough description of the process. The ClearStream class does more than eliminating references. For full details, see ClearStream class description.
TextLexer
TextLexer tokenizes the input for the purpose of preprocessing it. This requirement is much weaker than the full tokenization of the source for compilation etc.This lexer recognizes:
- white spaces
- Progress 4GL strings
- single and nested comments
- preprocessor statements
- abbreviated preprocessor statements
- generic 4GL code
TextLexer maintains state information of these two kinds:
- processing 4GL comment
- processing 4GL string
To make sure the shared state information works properly even though there are known generic problems , every use of this information has to be certified for correctness. The following sections do that for all uses of the shared state information in the TextLexer and ClearStream.
4GL comments generate two signals: entering a comment and leaving a comment. TextLexer sends these signals using
setInComment(true)
and setInComment(false) calls. Both opening and closing
sequences are exactly two characters: "/*" and "*/". The rule for
comments does the recognition using the lookahead buffers 1 and 2. When
the positive recognition is made, the signal is sent to the
ClearStream. In both cases, this
happens just in time - no character following comment opening/closing
sequence has been read yet.4GL strings also generate two signals: entering a string and leaving a string. TextLexer sends these signals using
setInString(true)
and setInString(false). With the strings the situation is
different. Opening character is either apostrophe or double quote, but
just a single character. The recognition is made based on the lookahead
buffer 1 only. So the "entering a
string" signal is sent in time - no character following the opening
character has been read yet. The string termination needs both lookahead buffers, however. This is so because strings allow doubled opening character as part of their contents. The lookahead buffer 2 is used to check if it is a doubled opening character (meaning no string closure) or the closing character. Thus, when the recognition is made, both lookahead buffers are used, but the lookahead buffer 2 contains a character which does not belong to the string. When the "leaving a string" signal is sent, it comes exactly one character late to the ClearStream. This constitutes a late signal problem. The problem, however, can be solved through some additional cooperation between the TextLexer and the ClearStream.
The way this shared state signal is used in the ClearStream limits the scope of the problem to just one case: if a Progress 4GL escape sequence which encodes either CR (carriage return) or NL (new line) character immediately follows the string closing character. This is the only troublesome combination, because the ClearStream normally inserts another CR character in front of every converted CR and NL while inside a string. In this case, a CR is inserted due to the late signal problem. But the TextLexer can easily detect this failure in the mSTRING method and fix it right away by consuming this extra character.
See TextLexer,ClearStream, mSTRING for details.
TextParser
TextParser is the top level recognizer of the preprocessor input. Its primary function is to process the conditional blocks of input interpreting only those blocks which have to be interpreted and skipping those which do not.It starts looking at the tokens on input assuming they belong to a block which has to be interpreted. Occasionally it may see &IF - &THEN - &ELSEIF - &THEN - &ELSE - &ENDIF constructs. Those require their expressions to be evaluated.
Expression evaluation is done in three steps:
- The parser simply gathers all relevant tokens into a string and calls the Preprocessor.evaluate() method.
- The latter instantiates necessary objects to interface with the real expression evaluator and registers various callbacks that resolve function names and variables in case they are referenced in the expression and calls the ProgressExpressionEvaluator.evaluateExpression() method.
- ProgressExpressionEvaluator.evaluateExpression() does all the evaluation work.
Skipped blocks are ignored completely leaving no trace on the preprocessor output. Interpreted blocks are made of either 4GL code tokens or the preprocessor statements. TextParser copies the 4GL tokens to the output and activates another grammar, stat.g, to conclude parsing and interpretation of the preprocessor statements.
For details, see TextParser, CallbackResolver, Keyword, ProgressExpressionEvaluator.
StatLexer
StatLexer tokenizes a portion of the input that makes a preprocessor statement extending through the end of line. This makes it a very simple lexer.This lexer recognizes:
- spaces and tabs as white spaces
- newline character
- single and nested comments
- generic code
See StatLexer for details.
StatParser
StatParser is the recognizer and the executor of the preprocessor statements. This parser recognizes and properly handles the following statements:&GLOBAL-DEFINE;&SCOPED-DEFINE;&UNDEFINE;&MESSAGE;&ANALYZE-SUSPEND;&ANALYZE-RESUME.
&GLOBAL-DEFINE and &SCOPED-DEFINE statements create a new preprocessor variable and put it in the appropriate scope. For discussion of scopes implementation, see ScopedSymbolDictionary class description. The defined variable may have an empty string as a value.
&UNDEFINE statement removes the nearest definition of the variable.
&MESSAGE statement outputs the given text to the error stream.
&ANALYZE-SUSPEND and &ANALYZE-RESUME are simply ignored.
The processed statement is then deleted from the input. Comments within the statement, if any, are copied to the output stream.
See StatParser for details.
BracesLexer
BracesLexer is special. It is called (indirectly) from the ClearStream class rather than from the TextParser. Together with the ClearStream driver code, they provide a transparent, non-dynamic input stream implementation for the rest of the preprocessor.BracesLexer tokenizes a portion of the input within braces. These are preprocessor references.
This lexer recognizes:
- white spaces
- equal character
- asterisk
- ampersand
- quote
- group of successive digits
- the closing brace character
- generic code (anything else)
BracesParser
The only task of the BracesParser is to recognize a type of reference coded in braces and replace it with the evaluation. Once the original reference is evaluated, it gets deleted from the input stream and replaced with the evaluation. The evaluation is pushed back into the input stream. That is the reason why the ClearStream class builds on the PushbackInputStream. The next read() call would reread the pushed back data again. This is how rescanning of the substitutions is implemented.This parser recognizes and properly handles the following constructs:
- argument references
{0}, {n}, {*}, {&*}, {&name}, {}; - defined variable references
{&name}; - preprocessor builtin variable references
{&name}; - include file references
{file}, {file pos}, {file &name=value}etc;
As the result of an include file reference parsing, no immediate substitute string is produced. Rather, another instance of FileScope is created and chained to the new dictionary scope. For details, see Preprocessor.includeFile.
Command Line Driver
The Preprocessor class includes the main method so it can be run from
the command line. The syntax to run the preprocessor is:java com.goldencode.p2j.preproc.Preprocessor [-option ...] filename [ file-arguments ]where
-optionis one or more of the following:
-
-debug
-
-keeptildes
-
-out output-file-name -
-propath path:path:... -
-pushback n -
-lexonly
-marker n
-hints hints-file-name
-debug option turns on the debug output.-keeptildes option preserves
the tildes used in the escape sequences on the output . -out option
directs the preprocessor output to a specific file instead of stdout.
-propath lis the equivalent of the Progress' PROPATH
string. -pushback
specifies a different pushback buffer size for the input stream. The
default is 1024 and should be sufficient for most runs of the
preprocessor.-lexonly is a special mode when the preprocessor only
tokenizes the
input file and outputs the stream of tokens without any modification.
Useful for debugging the lexer.-marker option tells the Preprocessor what byte is used as
a special internal marker. The default value 1 is likely to be
appropriate for the most cases. In general, any value in the ranges 1
to 7, 16 to 32 and 128 to 255 can be used as long as the input file
does not produce this byte. If that happens, however, an exception will
be raised.-hints option specifies the filename for the hints file.This is a sample hints file:
<?xml version="1.0"?>
<!--Preprocessor hints-->
<!--Created Mon May 16 16:22:07 EDT 2005-->
<hints>
<preprocessor-output>
<include file="g-permit.i" start-line="57"
start-column="1" end-line="99" end-column="2">
<reference name="{1}" type="argument"
value=""General Ledger Financial Rpts"" line="85"
column="20" />
<reference name="{1}" type="argument"
value=""General Ledger Financial Rpts"" line="95"
column="53" />
<argument name="{1}" position="1"
value=""General Ledger Financial Rpts"" used="yes"
/>
</include>
<include file="can-run.i" start-line="100"
start-column="1" end-line="127" end-column="2" />
<include file="can-lupd.i" start-line="128"
start-column="1" end-line="154" end-column="2" />
</preprocessor-output>
</hints>Developer Technical Notebook
The data in this "Developer's Notebook" represent a running log of various investigations which went on during the development of the Golden Code implementation of its preprocessor for Progress source code. Please note that this document is relatively unstructured, since items were appended as they were encountered during development. It is not intended to be formal documentation, but may be helpful for anyone trying to understand specific details about the implementation.To see the notebook, use this link.
Known Issues
Due to the undocumented nature of the Progress internals, it is generally impossible to guess everything right. That leaves room to some subtle issues. They will be mostly related to the order of actions that the Progress takes internally to preprocess a source file.Tab Expansion Issue
The tabs expansion is particularly sensitive to the internal order of
actions. If a line of a source file contains both a Progress reference
{...} of any kind and tabs, then the result would vary depending on the
order of tabs expansion and reference resolution. Here comes a sample
line: {11} /* comment */
This line has three tabs following the reference {11}. Let's assume the
positional argument 11 has the value of '.'. First, let's resolve the
reference:. /* comment */Now, let's expand tabs:
. /* comment */Now let's try the same two actions in the reverse order. First, let's expand the tabs:
{11} /* comment */
Now let's resolve the reference:. /* comment */If we compare the results side by side, we will find a different number of spaces that replaced tabs:
. /* comment */Currently, the P2J Preprocessor does all the processing in one pass, producing the first line. The Progress, apparently, does it in multiple passes, expanding tabs in a pass before resolving references. This produces the second line.
. /* comment */
Another known case where the tab expansion issue can be seen is preprocessor variables if their definitions contain tabs.
Copyright (c) 2004-2007, Golden Code
Development Corporation.
ALL RIGHTS RESERVED. Use is subject to license terms.
ALL RIGHTS RESERVED. Use is subject to license terms.