-
Interface Summary Interface Description DataModelTokenTypes Token types necessary to represent a data model as an AST.DmoAsmTypes Common constants needed when assembling DMO proxy method implementations with ASM.SchemaParserTokenTypes -
Class Summary Class Description DataModelAst Provides symbolic token name lookups that are specific to a data model AST.DataModelWorker A pattern worker that provides services to support the conversion of Progress schema data into a relational data model AST.DataModelWorker.ClassComparator Comparator implementation which sorts ASTs which represent data model object (DMO) classes.DataModelWorker.PropertyComparator Comparator implementation which sorts ASTs which have an "order" annotation into ascending order, according to the numeric value of that attribute.DmoAsmWorker A pattern worker which provides services to support the in-memory compilation of DMO interface and implementation classes using ASM.DmoAsmWorker.Library An API of library functions available to TRPL to provide services to assemble DMO interface and implementation classes using ASM.EntityName Representation of a qualified Progress schema entity name, reflecting the qualified name hierarchy represented by the Progress language naming conventions for schema entity references.ExtentHintField Container for name, label and description of hint for custom denormalization of field with extent.FieldInfo A read-only bean which exposes schema-related information associated with a database field which is referenced in source code.ImportWorker A pattern worker that provides batch data import services.ImportWorker.QueryHelper A helper class to manage the information necessary to compose and execute a database query using HQL (Hibernate Query Language).ImportWorker.QueryHelper.NameType Simple container which holds a parameter's property name and its Hibernate type, for purposes of substituting parameter values into queries at runtime.ImportWorker.SqlRecordLoader Helper class which manages all aspects of the mapping between a Progress data export file and the DMO which corresponds with a particular database table.MetaTableRelation A representation of a primary-foreign key relation between two Progress metaschema tables.NameNode A single node in a Progress database entity's name, which represents a database, a table, or a field entity.NameNode.AbbreviationComparator Comparator which will report twoNameNodeobjects as equivalent if the second node's name represents an abbreviation for the first node's name.NameNode.ExactMatchComparator Comparator which requires the name portion of theNameNodes being compared lexically to match exactly for the nodes to be reported as equivalent (return value of0fromcomparemethod).Namespace A namespace is used for unambiguous lookups of schema entity names.P2OAccessWorker A pattern worker that provides services to support the retrieval of information from previously created, persisted, P2O ASTs.P2OLookup A helper class which exposes information stored in P2O ASTs for access during source conversion processing.P2OLookup.WorkArea Container with user-specific data.PropertyMapper Maps a DMO class property to a data value read at a specific position in a data export file.PropertyMapper.CharacterMapper A concretePropertyMapperimplementation for properties which are mapped to thecharacterdata type.PropertyMapper.DateMapper A concretePropertyMapperimplementation for properties which are mapped to thedatedata type.PropertyMapper.DatetimeMapper A concretePropertyMapperimplementation for properties which are mapped to thedatetimedata type.PropertyMapper.DatetimetzMapper A concretePropertyMapperimplementation for properties which are mapped to thedatetimetzdata type.PropertyMapper.DecimalMapper A concretePropertyMapperimplementation for properties which are mapped to thedecimaldata type.PropertyMapper.Int64Mapper A concretePropertyMapperimplementation for properties which are mapped to theint64data type.PropertyMapper.IntegerMapper A concretePropertyMapperimplementation for properties which are mapped to theintegerdata type.PropertyMapper.LogicalMapper A concretePropertyMapperimplementation for properties which are mapped to thelogicaldata type.PropertyMapper.RawMapper A concretePropertyMapperimplementation for properties which are mapped to a byte array data type.PropertyMapper.RowIDMapper A concretePropertyMapperimplementation for properties which are mapped to therec-idorrow-iddata types.RecordLoader Helper class which manages all aspects of the mapping between a Progress data export file and the record object which corresponds with a particular database table record.RelationAnalyzer Examines implicit relations between database tables following Progress rules for table joins.RelationNode A node in a tree of table relation dependencies.SchemaConfig Schema configuration information.SchemaConfig.Metadata Encapsulates information about the project's use of database metadata, including the name of the metadata schema and the metadata tables used by the application, if any.SchemaConfig.NsConfig Encapsulates information about a namespace configuration, including name, XML file, and whether namespace should be loaded into the schema dictionary by default.SchemaConfig.NsConfig.DialectParam Helper class to read and set the dialect parameter.SchemaDictionary A dictionary used bySymbolResolverto perform lookups of database entity names.SchemaLoader Manages the import and loading of schema information, to make this data available to theSchemaDictionary.SchemaParser Parser for a token stream generated by theProgressLexer, as part of the process of interpreting Progress schema dump (*.df) files.SchemaStatsHelper Helper to copy and link to Progress 4GL schema source files.SchemaStatsHelper.SourceSpec Simple data structure to store key data for reverse mapping purposes.SchemaWorker A pattern worker which exposes schema dictionary and table relation analysis functionality to the pattern engine.TableHints Describes a variety of hint information for a single schema table.TableRelation A representation of a natural relation between two Progress tables. -
Exception Summary Exception Description AmbiguousSchemaNameException Exception thrown when a lookup of a schema entity name produces more than one match within a namespace.SchemaException An exception to encapsulate information about errors which occur during schema analysis and conversion tasks.
Package com.goldencode.p2j.schema Description
Provides services to extract database schema information from a
Progress schema dump file (
Package Class Hierarchy
High Level Flow
Inputs
Outputs
Conversion Considerations
This package produces a skeleton, logical mapping of Java objects to the tables and columns of the resulting relational schema (an Object to Relational Mapping or "ORM"). This logical mapping is an input to a separate process (package(s) TBD) whose purpose it is to fully implement the ORM data model by creating data-aware Java-objects and Data Access Objects (DAOs). It is the DAO's role to encapsulate the details of data access behind a natural object interface.
TBD Note: At the time of writing, this package is partially implemented. Currently, it provides services to inspect a Progress schema dump file and to generate a summary report and namespace dictionary document. In addition, it provides schema symbol name resolution services used by the
Package Class Hierarchy
(TBD: update - obsolete)
The following is a high level UML class diagram of the
There are three primary areas of interest:
These functional areas are discussed in more detail below.
The primary inputs to the schema conversion process are:
The lexing/parsing/tree-walking pipeline operates as follows:
The primary outputs of the schema conversion process are:
Hints are structured in an XML grammar (TBD). Hints are loaded by the
These documents are inputs to the
By using Hibernate's mapping document format and syntax, we gain the advantage of a set of abstract data types and an XML grammar which can be applied across a wide range of relational databases. Since Hibernate is aware of numerous database "dialects", the same mapping documents can be used regardless of the target database.
The grammar is essentially divided into two sections: one which describes a "forward" mapping of Progress schema constructs onto relational constructs, and the other which provides an inverse view of this mapping. An early prototype of this grammar follows (whitespace added for clarity):
TBD Note: the above grammar needs to be extended to capture additional information regarding the specific nature of relations between tables, and to accommodate specific refactoring scenarios, as discussed in the Hint Document(s) section.
Incident Report (TBD). An output from the conversion process which reports any problems or oddities encountered during conversion. This might include invalid type conversions, duplication of entity names or other naming conflicts, orphaned hints (hints which could not be applied, indicating possible mismatches and invalid results).
Log File (TBD). A detailed activity log for debugging purposes.
The schema namespace hierarchy is organized as follows:
Each database, table, and field depicted in the diagram above is represented as a
There are three layers of global namespaces:
Scopes are searched from the top of the stack downward. Either one or two complete passes through all scopes are performed. The first pass looks only for exact matches. If and only if all scopes have been searched and no exact match has been found, then the second pass is performed. The second pass permits abbreviated names to match.
Given a name reference using one of the naming conventions listed above, symbol resolution begins at the topmost (i.e., outermost or broadest), logical scope with a search at the first global namespace for which a component exists in the name. If no match is found at this level, the lookup within the current scope has failed. If a matching node is found, however, a search for the next component of the name in the matching node's private namespace is performed, and so on, until either a namespace level search fails, or the entire name symbol has been resolved. If no match is found at all within the current scope, the next scope in the stack is searched, and so on, until the name is resolved, or there are no more scopes to search.
Within each scope then, if we are searching for a name in the form
The search at each namespace level takes place in
If no match is found in a namespace search, the symbol resolution has failed
Data Types (TBD - obsolete)
Hibernate defines a set of database vendor-neutral data types, which
are mapped to specific database dialects transparently by the Hibernate
framework. Most P2R type mappings can be handled by default conversions
(e.g.,
Some type mappings may require non-default conversions. For instance, a field of type
For instance, there is no
A single Progress table will convert to a primary table in the target database, with zero or more secondary tables in which the extent fields are mapped. Fields of like extents in the Progress table are removed from the primary table and are re-mapped to a common secondary table. A separate secondary table is defined for each grouping of like extents. The secondary table is associated with the primary table by a foreign key which references the primary table's surrogate, primary key column. The naming convention for such a secondary table is
For example, consider a Progress table
This table is refactored during conversion into a primary table and two secondary tables as follows.
Note: the data types indicated in the converted table are representative only, as data type names vary among database vendors. Widths are intentionally omitted to simplify the example.
Each secondary table contains a multiple of the number of rows in table
The following example, which builds off the
Table
0 <=
An
In this case, there is only one field of extent 3 (
Generally, it is not necessary for application code to use these inner classes directly, as public access to their data is provided by the indexed getter and setter methods of the top level class. Thus, these inner classes have package private access. Hibernate accesses them directly through reflection to do its work.
Hibernate Mappings (TBD)
A top level class such as Vendor in the above sections is mapped by
Hibernate to one or more database tables using an XML mapping document.
Progress has no concept of an explicit primary key to foreign key relationship defined at the schema level. All table relations are defined in Progress source code, rather than in the database schema. A relational database, on the other hand, typically defines these relationships in the schema, by assigning a primary key in one table and a corresponding foreign key in another. Since a relational database relies heavily on such relations, it is important to determine to the degree possible, how to infer such relations from a Progress schema. Nevertheless, the introduction of key constraints between tables where there are none defined today in the Progress schema may introduce unwanted restrictions on data insert and update in the resulting application. As a result, we introduce only those key constraints which can be positively inferred from the existing Progress schema and application codebase. The following techniques are used for this analysis:
A goal of conversion is to define a primary key for every table in the relational database schema. A primary key must be non-nullable and unique. In the converted schema, the primary key will be a single-column, surrogate key; that is, a column which has no business meaning, but is used only for database purposes. Where possible, the same name is used across tables to indicate the primary key column. A new column is introduced for this purpose.
Where a foreign key relationship has been established, the Progress field(s) which enabled the association in the referencing table are dropped. These are duplicative with the corresponding fields in the referenced table. The association which they enable with the referenced table is now maintained with a single column foreign key which references the surrogate, primary key in the referenced table. In the referenced table, these corresponding fields remain, and the referencing table must now access these columns via a join. In this case, data integrity is maintained during data import, by ensuring that records in referencing tables are correctly fixed up to use the new surrogate primary key instead of the existing, referencing field(s). An illustration of this concept follows.
In the old relation, columns 1, 2, and 3 represent a multi-column primary key in Table A and columns 1', 2', and 3' in Table B a multi-column foreign key:
Post-conversion, a surrogate primary key has been added to Table A; a referencing foreign key column has been added to Table B. Columns 1', 2', and 3' have been dropped from Table B. Access to this data is now achieved via a join between the tables:
If one or more indexes are defined for a Progress table, one of them must be designated as the primary index. This designation does not connote an analog for a primary key; instead, it simply defines the index to use as the default index for purposes of retrieving and sorting records in a query. The designation of a Progress index as unique is more useful when attempting to determine primary key candidates. If only one unique index is defined for a Progress table, the fields in that index essentially define a primary key. If a table defines multiple, unique indexes, it is ambiguous from this analysis alone as to which index should be used as a primary key. However, since we are introducing surrogate primary keys, this point is largely moot, except in cases where we can infer a foreign key relation from another table. Additional analysis must be performed to make this determination. In such cases, the foreign key column introduced into the "foreign" table must contain the correct surrogate key from the "primary" table. It is necessary when importing Progress data into the new relational schema, to correctly match records using values found in the field or fields which define the join between the two tables involved in such a relation.
Because of the significant difference in purpose, the conversion does not carry over Progress indexes per se. New indexes are created for the relational schema as follows:
The conversion also considers index redundancy. Two Progress indexes are considered redundant with one another if they:
Once redundant indexes have been dropped, the final disposition of Progress indexes is one of the following:
For a natural join to occur, the following conditions must be met:
This has an interesting implication for schema conversion, in that not all relational databases behave the same way. The value
In the case where the backing database supports multiple NULL values past a unique constraint, the conversion approach is to leverage the unique constraint capability of the backing database to enforce the constraints imposed by Progress' unique index. In the case where the backing database does not support multiple NULL values past a unique constraint, the conversion approach is to use a check constraint with an SQL expression to enforce the required uniqueness. Support for the latter case will not be implemented in the first release.
Determining Query Sorting
Introduction
In order to accurately duplicate the behavior of the Progress 4GL single record reading approach, one must dynamically select each record of the specified table in the same traversal order which Progress would generate. This problem is complicated by the feature provided by Progress where the same record may be visited more than once if its data is changed in a manner that reorders it later (or earlier if the walk is backwards) in the sequence of records. This is very different from SQL's set oriented approach where one can be sure that the set returned is of a static size. Besides the obvious danger of creating infinite loops or otherwise non-intuitive behavior, this requirement means that each "next" or "previous" record retrieval must be based on a relative movement between records instead of a walk of a static list.
In order to duplicate the traversal order of Progress, the relative movement from one record to the next/previous must be based on knowledge of the exact sorting criteria used by Progress. As with many of the behaviors of the Progress language, there is a mixture of explicit and implicit factors that determine the exact sorting criteria used for each query.
The Progress database accesses all records via an index, via the combined use of multiple indexes or via a table scan. When a single index is used, to the degree that the requested sorting criteria doesn't exist or in some cases where the sort criteria doesn't fully specify an unambiguous ordering (but is compatible with the index), the index used determines the order that the records are returned. In other words, the index in use can and often does determine (or partially determine) the real sort order.
In the multiple index and table scan approaches, if no explicit sort order is specified, the sort order is undefined. In addition, even in cases where the sort order is explicitly specified, it is possible that records can be ambiguously ordered. When this occurs, the "secondary" sort order is undefined.
The BY phrase is used to explicitly specify a sort order. It is especially important to note that the sort order can be completely implicit (if no BY clause is provided), partially implicit (if the BY clause does not unambiguously specify an exact ordering) or completely explicit (if the BY clause results in an unambiguous order). For this reason, it is possible (and even likely) that a given Progress application will have ordering dependencies built in, possibly without the specific intention of the original author. This may appear as the order of records in a report or the order in which records are displayed in the user interface.
Implicit sort behavior in the single index case is dependent upon the selected index. For this reason, one must duplicate the implicit index selection that the Progress compiler makes. This is driven by analysis of query predicates (WHERE, OF and USING clauses), sort specification (BY clause) and explicit index specifications (USE-INDEX clause). These rules may be used for both FIND and FOR EACH type queries. Since there are differences in what can be done with these two query methods, some rules may not apply to both types. Of most importance, BY clauses can only occur in a FOR statement (FIND statement sort order is always based only on the selected index).
The following text describes the rules by which the sorting criteria are determined in Progress.
Single versus Multiple Index Selection
As noted above, some ambiguity in sorting is resolved using the index selected for record reading. This point really assumes that a single index is in use. Multiple indexes can be selected and are used together to read the specified records. In the multiple index case, all non-explicit sorting behavior is undefined. It is documented that in the single index cases, the 4GL developer can sometimes rely upon secondary sort behavior based on the index.
The FIND statement only ever uses a single index. The FOR EACH statement, GET statement and usage of PRESELECT all use multiple indexes whenever possible (assuming the -v6q command line option is not active). This multiple index support appeared in Progress v7 and applications that had a dependency on single index selection (an implicit sorting dependency) needed the v6 query compatibility mode (the -v6q command line option).
Even though certain language constructs are enabled for multiple indexes, it is the query predicate which determines if a single index or multiple indexes are chosen. In particular:
When a single index is used and there is no explicit sort order, the sort order is defined by the index. This is something that is relied upon by 4GL developers.
An important point is that when multiple indexes are selected any implicit sort order is undefined. It is documented that the 4GL developer should not rely upon any particular sort order that may be implicitly provided in the multiple index case since this may change in future releases. One is expected to explicitly specify BY clause in this case OR the code should be independent of the resulting sort order.
To the extent that a BY clause does not specify an unambiguous sort order, the sorting within the "buckets" defined in the BY is usually undefined. In other words, if multiple records have the same data in the given set of fields specified in the BY clause, the sort order of these records will be undefined even though the overall sort order of the query is defined. This is called the secondary sort order.
The exception to this is the case where there is a single index used for record access AND there is an explicit BY clause whose fields, the order of those fields and the direction of each field's sort (ascending or descending) all match the leading subset of the index in use. In this case, the index and the sort criteria are compatible and the sorting is completely specified (and implemented) by the index on the Progress database server. This means that in such cases, there will be a reliable secondary sort ordering based on the additional (more specific) fields in the index that were not part of the BY clause.
Otherwise, all secondary sorting behavior (for both single and multiple index cases) is undefined.
Some simple tests of explicit sorting have shown the following behavior:
It is possible to imagine a situation where the sort order in the multiple index case makes an important difference in an application:
Since the resulting data imported into the P2J system will be based on the .d export files (which are in primary index order), all physical location information is lost in this export/import. To the extent that this is important, the current approach cannot guarantee this order.
None of the undefined cases will be supported at this time, but all the defined cases will be supported. The following are the defined cases (which can be relied upon by the 4GL programmer):
Due to this set of rules, the single index used to select records must be calculated. If in Progress, the result would have been a multiple index, in P2J it will be calculated as a single index. This may approximate some of the behavior of Progress, though it is not expected to completely match the undefined behavior. The rest of this document describes this index selection process.
Implicit WHERE Clause Components
As with many things in Progress, a query predicate (i.e. record selection criteria) can be specified explicitly (WHERE clause) or implicitly (through OF or USING clauses and through the special unqualified constant form of FIND). Before analyzing the query predicate, one must add any implicit portions to get the complete expression used to select records.
Since it is the WHERE clause that largely drives the selection of the index, all implicit portions of the WHERE must be made explicit before the index selection process occurs.
Unqualified Constant:
A FIND with a single constant (literal value) instead of a standard record phrase is the same as making an addition to the WHERE clause referencing a primary index (which must have only a single field) in an equality match. Thus:
FIND customer 1 WHERE country = "USA".
Assuming the customer table has a primary key which has the single index component cust-num, this is actually the same as:
FIND customer WHERE (country = "USA") AND cust-num = 1.
OF clause:
The usage of the OF clause causes an *addition* of an equality match for each field in the common index (an index that is common between the two tables and unique in at least one of them). These equality matches are connected via an AND operator. If the common index between two tables is comprised of fields A, B and C:
FIND customer OF order WHERE name = "Bogus"
is converted into:
FIND customer WHERE (name = "Bogus") AND customer.A = order.A AND customer.B = order.B AND customer.C = order.C
Note that due to the join-like nature of the OF clause, the OF itself implicitly defines the index which is used to select records in the target table based on equality matches with those common fields in the preceding table. This means that this case actually does not require any WHERE clause analysis since the index is predetermined. This case is documented here for completeness but the WHERE clause will not be rewritten.
Direct Logical Field References
A logical field that is directly referenced as the entire predicate or as a direct operand of a logical operator is actually considered to be the same as an equality comparison with the literal true (thus it will affect the index selection process described below). This means that:
WHERE logicalField
is the same as
WHERE logicalField = true
Interestingly enough, the use of the NOT operator in this case does not get translated into the corresponding equality comparison (so it does not affect index selection as described below):
WHERE NOT logicalField
is not the same as
WHERE logicalField = false
USING clause:
The usage of USING causes an *addition* of an equality match for each field referenced with the instance of that field in the default or specified screenbuffer (FRAME). These equality matches are connected via an AND operator. So:
PROMPT-FOR customer.cust-num.
FIND customer USING cust-num WHERE country = "finland".
is converted into:
PROMPT-FOR customer.cust-num.
FIND customer WHERE (country = "finland") AND cust-num = INPUT customer.cust-num.
An alternate form of USING usage exists for any field that is defined as an abbreviated field in an index. In this case:
PROMPT-FOR customer.cust-num.
FIND customer USING cust-num WHERE country = "finland".
is converted into:
PROMPT-FOR customer.cust-num.
FIND customer WHERE (country = "finland") AND cust-num BEGINS INPUT customer.cust-num.
The difference is that the "=" operator is converted into a "BEGINS" operator.
From the Progress documentation:
Indexes are selected based on explicit and implicit criteria. In the absence of an explicit index specification (USE-INDEX), the Progress compiler makes an implicit index selection. This selection is based on an analysis of the query predicate. The idea is that the Progress database server is completely driven by index processing (or table scans if no index can be used). There are a very limited set of operations that can be specified in a predicate which can be translated into index operations. Anything that can be translated into an index operation can be resolved by the database server without the Progress client evaluating expressions to determine if a given record matches.
In other words, a single query predicate can be processed completely on the client, completely on the database server or in both places. The degree with which the predicate can be processed on the server has a great impact on the performance of the database access since it is highly inefficient to read many records from the server only to reject them at the client when they do not match the predicate. This is a statement of data transfer volume (a less visible factor in shared memory implementations than on network implementations). More importantly it is a statement of the efficiency of general purpose interpreted 4GL expression performance compared to a database server that is tuned for such processing.
Client side operations are anything:
An operation is specified by a logical comparison operator. The set of operators known by the database server is limited:
Any other comparison operator than noted in this list, is unknown to the database server. That means that NE (<>), NOT, MATCHES cannot be processed on the database server.
This means that when any of the above operators are encountered, the compiler is allowed to examine the two operands to determine if one of them is an index component. If either of the operands (it does not have to be on the left side only) is an index component, then this may modify the index selected (based on the rules below). For example, if one encountered a sub-expression indexField = 5, then this would be considered an "equality match" on the indexField field.
The only other operators that are recognized during this analysis are the conjunction and precedence operators. In the single index case, the AND operator allows the compiler to analyze both operands for index selection purposes, but the OR operator does not allow operand analysis. This makes sense when one considers that in a single index case, the best fit index will naturally be able to reduce the result set based on an AND condition. But the OR operator makes it significantly harder (or sometimes impossible) to ensure that the results of a single index can fulfill all possible conditions.
In the multiple index case, the AND and OR operators may both have some support however this has not been explored or documented.
Parenthesis (the precedence operator) neither hinders nor helps the analysis process since it merely ensures that the structure/precedence of the expression is forced into a known pattern. This resulting structure is what is analyzed, after the parenthesis have already been applied.
Any operand of one of the above operators that is not a recognized operator or an index component (field) will be ignored and it (and its children) will not have any impact on the index selection. This means that all other expression features (and their operands) are ignored. Another way of saying this is that these are not matches as termed above, they have no impact on the index selection. This is the list:
A sort match is a special type of match that is determined based on analysis of a BY clause rather than by analyzing the WHERE predicate. Identifying sort matches using BY clause analysis is complicated by 2 factors:
This list of rules is specified in priority order (1 is the highest priority). Each priority level is checked in turn, from highest to lowest. At the start of processing, there is a "selectable" list that includes all possible indexes for the given table. As each priority level is processed, indexes that are selectable based on the criteria at that level will remain in the selectable list and all other indexes will be removed. If the selectable list contains a single matching index after a given priority level is evaluated, that index will be the selected index. If there are multiple matching indexes at a given priority level, then the reduced selectable list is used in subsequent priority levels to provide a "tie breaking" process to determine which index is selected. This general rule does have some exceptions which are noted below.
The selection rules:
The order of index components in a predicate makes no difference in index selection. This means that the following two constructs are identical in result.
A = ___ AND B = ___
B = ___ AND A = ___
Assuming that there is an index with sequential leading components A followed by B, this index would be selected in either case.
Likewise, a field reference as an operand can appear on the left or right side of a supported operator and it is still honored EXCEPT in the case where both operands of a supported operator are direct field references (to the given table) or contain nested field references (to the given table). In this case, both field references are ignored (do not affect index selection).
So of the following examples:
field = 4
4 = field
field = field2
field = entry(1, field2)
field = field2 + 5
field + 5 = field2
The first two examples both result in field being used in index selection. In the third, fourth and fifth examples, both field and field2 are ignored even though one or both field references are direct operands of a supported operator!
Field references (which are index components that would normally affect the index selection) will be ignored if they are operands of unsupported operators. Likewise, such field references that occur inside an ignorable sub-expression are also ignored. Only field references that are direct operands of a supported operator will be considered.
A supported operator is only honored if it is the deciding/controlling operator for the expression or if it is an operand of an AND conjunction which is accessible. To be accessible, the AND operator cannot be contained within or an operand of an ignorable sub-expression or ignorable operator (including OR).
This means that in the following:
(field = 64) = (field2 < 100)
Both field and field2 are ignored since their respective operators are not operands of an AND operator nor are they the controlling decision of the expression.
The following is a summary of the interactions between index component references on both sides of each supported operator:
Index Selection Special Case
A FIND lookup by recid/rowid does not use an index.
*.df) for the purposes of
inspection and analysis; combines this data with programmatically and
manually generated conversion hints in order to create an analogous
relational database schema and a skeleton mapping of data-aware Java
objects to the resulting schema. | Author(s) |
Eric Faulhaber Greg Shah Rod Gaither |
| Date |
October 21, 2005 |
| Access Control |
CONFIDENTIAL |
Contents
IntroductionPackage Class Hierarchy
High Level Flow
Inputs
Outputs
Progress Schema Namespace
Dictionary
Hibernate Mapping Documents
P2R Mapping Document
Secondary Outputs
Schema Name Symbol ResolutionHibernate Mapping Documents
P2R Mapping Document
Secondary Outputs
Conversion Considerations
Schema
Property Mappings
Data Types
Converted Table Structure
Data Model Objects
Hibernate Mappings
Key Constraints
Progress Table Indexes
Natural Join Analysis
Uniqueness and the Unknown Value
Determining Query Sorting
Data Types
Converted Table Structure
Data Model Objects
Hibernate Mappings
Key Constraints
Progress Table Indexes
Natural Join Analysis
Uniqueness and the Unknown Value
Determining Query Sorting
Introduction
The purpose of this package is to inspect and analyze a Progress database schema in order to manage its conversion to an analogous relational database schema. The ultimate result of this process is a working database schema in a specific vendor's relational database. However, since relational database schema implementations and creation techniques vary from vendor to vendor, a design principle is to produce an intermediate, logical mapping which is agnostic to the particular implementation of the target database. The mapping must be applicable to a variety of commercial and free relational databases. It comprises a primary input into the data conversion process, implemented separately (package(s) TBD).This package produces a skeleton, logical mapping of Java objects to the tables and columns of the resulting relational schema (an Object to Relational Mapping or "ORM"). This logical mapping is an input to a separate process (package(s) TBD) whose purpose it is to fully implement the ORM data model by creating data-aware Java-objects and Data Access Objects (DAOs). It is the DAO's role to encapsulate the details of data access behind a natural object interface.
TBD Note: At the time of writing, this package is partially implemented. Currently, it provides services to inspect a Progress schema dump file and to generate a summary report and namespace dictionary document. In addition, it provides schema symbol name resolution services used by the
uast
package. However, the assimilation of hints with this data to produce
a functional relational schema and ORM is not yet implemented.Package Class Hierarchy
(TBD: update - obsolete)
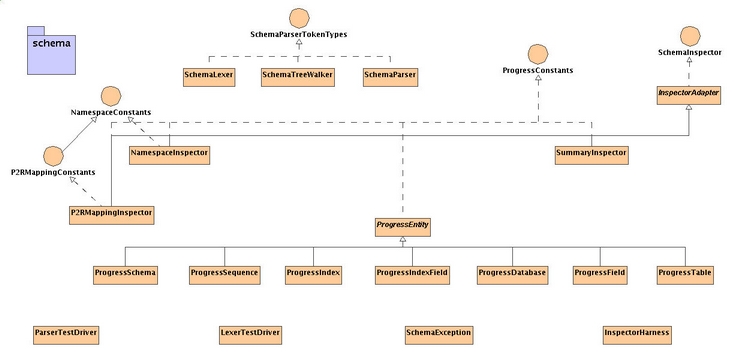
The following is a high level UML class diagram of the schema
package in its current implementation:There are three primary areas of interest:
- The lexing/parsing/tree-walking classes which all implement
SchemaParserTokenTypesrepresent the ANTLR-generated classes which are responsible for lexing, parsing, and understanding the Progress schema dump file. - The set of
ProgessEntitysubclasses are used to represent the Progress schema in a more accessible form for further inspection and analysis. - The
SchemaInspectorinterface and its various implementations are used to inspect and analyze the schema for the purpose of conversion.
These functional areas are discussed in more detail below.
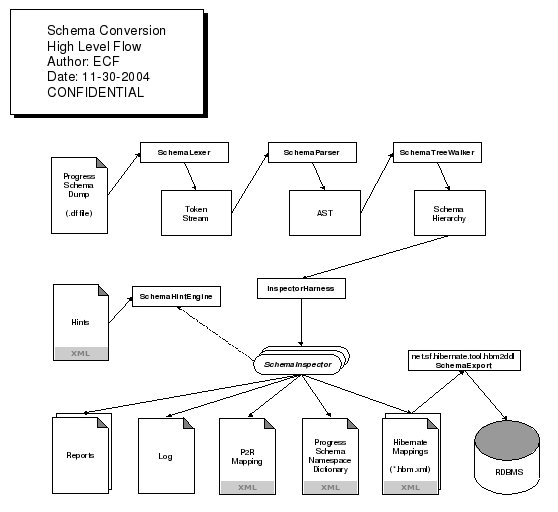
High Level Flow (TBD: update - obsolete)
The primary inputs to the schema conversion process are:
- the Progress schema dump file;
- an XML document containing conversion hints.
uast
package summary for a useful primer on this technology.The lexing/parsing/tree-walking pipeline operates as follows:
- The Progress schema dump file is fed to the
SchemaLexer, which generates on output a stream of tokens specific to the dump file format. - This stream of tokens is input to the next stage in the pipeline,
the
SchemaParser. This class subjects the stream of tokens to a set of grammar rules which are used to generate an Abstract Syntax Tree (AST). This is a tree of token-based nodes which abstracts away the dump file syntax and produces a normalized, hierarchical representation of the dump file contents. - The AST is input into the next stage of the pipeline, the
SchemaTreeWalker. This object walks the tree of nodes, and as it encounters tokens which represent logical schema entities (e.g., database, table, field, etc.), it constructs Java objects which represent those entities in their proper context with respect to one another (e.g., database contains tables, table contains fields, etc.).
SchemaInspector
interface.The primary outputs of the schema conversion process are:
- a cross-referenced Progress to Relational ("P2R") mapping document;
- a dictionary of the Progress schema namespace (see
NamespaceInspector); - a set of XML mapping documents used by the open source ORM technology Hibernate (www.hibernate.org) to generate and apply the resulting schema to an existing, relational database;
- a functional schema applied to a relational database.
- various reports;
- a log file (for debugging purposes).
Inputs
Progress Schema Dump File
This file is programmatically generated in a well-structured and consistent format by the Progress data dictionary. Its syntax consists of a series of phrases which describe various, logical schema constructs, organized hierarchically: the database, its sequences, its tables, their fields and indexes. A snippet of a hypothetical customer service database follows:UPDATE DATABASE "?"Each phrase provides the name of the entity it describes, as well as the properties, if any, which have been defined for it. Entities are always defined after the entity which logically contains them. For example, table fields and indexes are always defined after the table which contains them.
ADD SEQUENCE "next-cust-num"
INITIAL 0
INCREMENT 1
CYCLE-ON-LIMIT no
MIN-VAL 0
ADD TABLE "customer"
AREA "Schema Area"
DESCRIPTION "Customer Data"
VALMSG "SERVICE APP 1.0"
DUMP-NAME "customer"
ADD FIELD "acct-num" OF "customer" AS integer
FORMAT "9"
INITIAL "0"
LABEL "Account Number"
POSITION 2
SQL-WIDTH 4
ORDER 10
ADD FIELD "first-name" OF "customer" AS character
FORMAT "X(12)"
INITIAL ""
LABEL "First Name"
POSITION 10
SQL-WIDTH 130
ORDER 20
ADD FIELD "last-name" OF "customer" AS character
FORMAT "X(12)"
INITIAL ""
LABEL "Last Name"
POSITION 10
SQL-WIDTH 130
ORDER 30
ADD FIELD "since" OF "customer" AS date
FORMAT "99/99/9999"
INITIAL ?
LABEL "Customer Since"
POSITION 5
SQL-WIDTH 4
ORDER 40
ADD INDEX "idx-acct" ON "customer"
AREA "Schema Area"
UNIQUE
PRIMARY
INDEX-FIELD "cust-num" ASCENDING
Hint Document(s)
Hints are an important input into the database conversion process, since the information provided by the Progress schema dump file is not a one for one match with the information needed to produce a relational schema. In particular, critical information regarding the data integrity relations between tables and subtle cues needed for proper conversion of types is missing. This information must be gathered by automated and/or manual code analysis, and possibly by an analysis of the actual data residing in the Progress database, to determine where standard type conversion may not apply.Hints are structured in an XML grammar (TBD). Hints are loaded by the
SchemaHintEngine
(TBD). This engine makes hints accessible to the classes which require
them in order to produce their respective
output files.Outputs
Progress Schema Namespace Dictionary (TBD: update - obsolete)
This document is used by the code conversion process to enable a schema namespace lookup to resolve unknown variables to database field references. It is produced by theNamespaceInspector and
requires no hints, since it is based completely on the Progress schema
dump file.
<?xml version="1.0"?>This information is used by the
<!--Progress schema namespace dictionary-->
<!--Generated Tue Nov 30 10:51:29 EST 2004-->
<schema source="junk.df">
<database name="custsvc">
<table name="customer">
<field name="acct-num" type="integer" />
<field name="first-name" type="character" />
<field name="last-name" type="character" />
<field name="since" type="date" />
</table>
</database>
</schema>
NamespaceLoader
to load entries into the SchemaDictionary,
in order to enable symbol
resolution of schema entity names during Progress source code
parsing.Hibernate Mapping Documents
These XML files are produced by theHibernateMappingInspector
(TBD), based upon the Progress schema, with a strong reliance upon
hints
about field type conversions and table relations. Alternately, they may
be produced by a set of classes which uses the P2R mapping document as
an input (TBD).These documents are inputs to the
org.hibernate.tools.hbm2ddl.SchemaExport
tool provided with the Hibernate toolset. This tool produces data
definition language ("DDL"), which is applied against the target
relational database to create the schema. The DDL optionally can be
saved off separately for reference and debugging purposes, batch use or
database recovery.By using Hibernate's mapping document format and syntax, we gain the advantage of a set of abstract data types and an XML grammar which can be applied across a wide range of relational databases. Since Hibernate is aware of numerous database "dialects", the same mapping documents can be used regardless of the target database.
P2R Mapping Document (TBD: update - obsolete)
This XML document describes how the Progress schema is mapped to a relational schema. It is used to create a cross-linked reference document for end-user use and may provide an input into the creation of Hibernate mapping documents if this information is not compiled directly by an inspector implementation (TBD).The grammar is essentially divided into two sections: one which describes a "forward" mapping of Progress schema constructs onto relational constructs, and the other which provides an inverse view of this mapping. An early prototype of this grammar follows (whitespace added for clarity):
<?xml version="1.0"?>Each database, table, and field entity within the
<!-- Progress/Relational schema cross-referenced mapping -->
<schema>
<!--Progress schema-->
<progress source="custsvc.df">
<database name="custsvc" ref="CUSTSVC">
<sequence name="next-cust-num" ref="nextCustNum">
<property name="INITIAL" value="0" />
<property name="INCREMENT" value="0" />
<property name="CYCLE-ON-LIMIT" value="no" />
<property name="MIN-VAL" value="0" />
</sequence>
<table name="customers" ref="CUSTOMERS">
<property name="AREA" value="Schema Area" />
<property name="DESCRIPTION" value="Customer service database" />
<property name="VALMSG" value="SERVICE APP 1.0" />
<property name="DUMP-NAME" value="customer" />
<field name="acct-num" ref="ACCT_NUM" type="integer">
<property name="FORMAT" value="999999" />
<property name="INITIAL" value="0" />
<property name="LABEL" value="Account Number" />
<property name="POSITION" value="2" />
<property name="SQL-WIDTH" value="4" />
<property name="ORDER" value="10" />
</field>
<field name="first-name" ref="FIRST_NAME" type="character">
<property name="FORMAT" value="X(12)" />
<property name="INITIAL" value="" />
<property name="LABEL" value="First Name" />
<property name="POSITION" value="10" />
<property name="SQL-WIDTH" value="130" />
<property name="ORDER" value="20" />
</field>
<field name="last-name" ref="LAST_NAME" type="character">
<property name="FORMAT" value="X(12)" />
<property name="INITIAL" value="" />
<property name="LABEL" value="Last Name" />
<property name="POSITION" value="10" />
<property name="SQL-WIDTH" value="130" />
<property name="ORDER" value="30" />
</field>
<field name="since" ref="SINCE" type="date">
<property name="FORMAT" value="99/99/9999" />
<property name="INITIAL" value="?" />
<property name="LABEL" value="Customer Since" />
<property name="POSITION" value="5" />
<property name="SQL-WIDTH" value="4" />
<property name="ORDER" value="40" />
</field>
<primary-key>
<field name="acct-num" />
</primary key>
</table>
<table name="invoices" ref="INVOICES">
<property name="AREA" value="Schema Area" />
<property name="DESCRIPTION" value="Invoices for customer orders" />
<property name="VALMSG" value="SERVICE APP 1.0" />
<property name="DUMP-NAME" value="invoices" />
<field name="invoice-num" ref="INVOICE_NUM" type="integer">
<property name="FORMAT" value="999999" />
<property name="INITIAL" value="0" />
<property name="LABEL" value="Invoice Number" />
<property name="POSITION" value="2" />
<property name="SQL-WIDTH" value="4" />
<property name="ORDER" value="10" />
</field>
<field name="cust-num" ref="CUST_NUM" type="integer">
<property name="FORMAT" value="999999" />
<property name="INITIAL" value="0" />
<property name="LABEL" value="Customer Account Number" />
<property name="POSITION" value="2" />
<property name="SQL-WIDTH" value="4" />
<property name="ORDER" value="20" />
</field>
<primary-key>
<field name="invoice-num" />
</primary key>
<foreign-key table="customers">
<field local="cust-num" foreign="acct-num" />
</foreign-key>
</table>
</database>
</progress>
<!--Relational schema-->
<relational>
<database name="CUSTSVC" ref="custsvc">
<table name="CUSTOMERS" ref="customers">
<column name="ACCT_NUM" ref="acct-num" type="integer">
<property name="format" value="000000" />
</column>
<column name="FIRST_NAME" ref="first-name" type="string" />
<column name="LAST_NAME" ref="last-name" type="string" />
<column name="SINCE" ref="since" type="date">
<property name="format" value="MM/dd/yyyy" />
</column>
<primary-key>
<column name="ACCT_NUM" />
</primary key>
</table>
<table name="INVOICES" ref="invoices">
<column name="INVOICE_NUM" ref="invoice-num" type="integer" />
<column name="cust-num" ref="CUST_NUM" type="integer" />
<primary-key>
<column name="INVOICE_NUM" />
</primary key>
<foreign-key table="CUSTOMERS">
<column local="CUST_NUM" foreign="ACCT_NUM" />
</foreign-key>
</table>
</database>
</relational>
</schema>
<progress>
element has an analog within the <relational> element. The ref
attribute in each of these tags refers to the name of that entity's
analog. Progress properties which do not change in the conversion are
not represented on the relational side, as these values can be looked
up
as necessary. Properties that do change (e.g., format clauses) or that
are necessarily different on the relational side (e.g., data type) are
represented by an appropriate tag or attribute.TBD Note: the above grammar needs to be extended to capture additional information regarding the specific nature of relations between tables, and to accommodate specific refactoring scenarios, as discussed in the Hint Document(s) section.
Secondary Outputs
Summary Report. This is a very simple overview report generated by theSummaryInspector. Its
primary purpose is to give a more compact overview of the Progress
schema than is easily gleaned from reading the dump file. This report
is
useful for early analysis of a Progress schema.Incident Report (TBD). An output from the conversion process which reports any problems or oddities encountered during conversion. This might include invalid type conversions, duplication of entity names or other naming conflicts, orphaned hints (hints which could not be applied, indicating possible mismatches and invalid results).
Log File (TBD). A detailed activity log for debugging purposes.
Schema Name Symbol Resolution
As the UAST parses Progress source code, it will encounter references to Progress database schema entities, such as databases, tables (records), and fields. Progress is extremely flexible in the way these references can be written, in terms of allowing names to be abbreviated in certain cases, and requiring qualifiers to "parent" entities only when necessary to avoid ambiguity. This flexibility requires a somewhat complex mechanism for symbol resolution of database, table, and field references. The following naming conventions for schema entities exist in Progress, and must be supported in P2J's symbol resolution facility:<database_name>.<table_name>.<field_name>(a fully qualified field reference)<database_name>.<table_name>(a fully qualified table reference)<table_name>.<field_name>(a partially qualified field reference)<database_name>(a unique reference to a database)<table_name>(an unqualified reference to a table)<field_name>(an unqualified reference to a field)
uast
package summary.Scopes and the Schema Namespace Hierarchy
TheSchemaDictionary
is responsible for loading schema namespace information, for managing
multiple scopes, and for providing an API to resolve schema names. A
default lookup scope is created upon construction of this object. It
relies upon the SchemaConfig
to determine which, if any, databases it should load by default into
this outermost scope. Calling code may create additional scopes "on
top" of this scope and load arbitrary database names, table names, and
field names into these scopes to augment the default lookup behavior,
as blocks are traversed during source code parsing. In a namespace lookup, more recently added
scopes will always be searched before older scopes. Thus, the
default scope added by the SchemaDictionary constructor
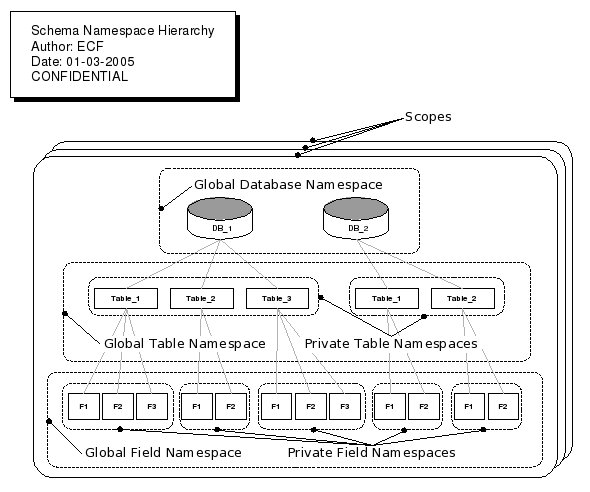
will always be searched last.The schema namespace hierarchy is organized as follows:
Each database, table, and field depicted in the diagram above is represented as a
NameNode
object. Each NameNode contains a Namespace
object representing that entity's private namespace for its child
entities. For instance, a database NameNode has a private
namespace of table nodesNameNode
has a private namespace of field nodes; a field NameNode
has an empty namespace.There are three layers of global namespaces:
- the Global Database Namespace containing all databases;
- the Global Table Namespace containing all tables across all databases;
- the Global Field Namespace containing all fields across all tables across all databases.
The Search Algorithm
A schema namespace hierarchy such as the one depicted above exists in each scope defined within theSchemaDictionary. These
scopes are implemented as a stack; calling code can push a new logical
scope onto the top of the stack with SchemaDictionary's addScope
method as it enters a new scope during parsing. Later, it should pop
the logical scope off the top of the stack with the removeScope
method, as it exits the corresponding scope in Progress source code.Scopes are searched from the top of the stack downward. Either one or two complete passes through all scopes are performed. The first pass looks only for exact matches. If and only if all scopes have been searched and no exact match has been found, then the second pass is performed. The second pass permits abbreviated names to match.
Given a name reference using one of the naming conventions listed above, symbol resolution begins at the topmost (i.e., outermost or broadest), logical scope with a search at the first global namespace for which a component exists in the name. If no match is found at this level, the lookup within the current scope has failed. If a matching node is found, however, a search for the next component of the name in the matching node's private namespace is performed, and so on, until either a namespace level search fails, or the entire name symbol has been resolved. If no match is found at all within the current scope, the next scope in the stack is searched, and so on, until the name is resolved, or there are no more scopes to search.
Within each scope then, if we are searching for a name in the form
<database_name>.<table_name>.<field_name>,
for instance (using names from the diagram above), DB_2.Table_1.F2DB-2 in the Global Database
Namespace. Upon finding the name DB_2, we look next for
the name Table_1 in the DB_2 Private Table Namespace.
Upon finding the name Table_1, we look next for the name F2
in the DB_2F2, we return the NameNode
found. If the DB_2 qualifier component of the name were
missing, the search would begin at the Global Table Namespace level. If
both the DB_2 and the Table_1 qualifier
components of the name were missing, the search would begin (and end)
at the Global Field Namespace level. This portion of the algorithm is
implemented in the SchemaDictionary.Scope.findNode
method.The search at each namespace level takes place in
Namespace's
find
method. Namespace contains a java.util.List
of NameNode objects which is sorted lazily when a search
is requested. The binary search implemented by
java.util.Collections is used. For database name searches, this
binary search uses a comparator which requires an
exact match of all characters in the name component being resolved
(since database symbol names may not be abbreviated). For table and
field name searches (for which abbreviated symbol names are allowed),
both exact matches and abbreviated name matches are permitted. The
abbreviated name binary search is
performed using a comparator
which is more lenient: it permits comparisons between a full name
and a matching abbreviation to test as equivalent. Only one type of
search -- exact match or abbreviated match -- is performed at a time by
Namespace's find method.If no match is found in a namespace search, the symbol resolution has failed
Namespace.
If a single match is found, it has
succeeded. However, ambiguous matches must also be considered. To
handle this, a successful match is followed up by a test of the NameNodes
which immediately surround the matching node in the namespace's NameNode
pool. If more than one match is found, the resolution is ambiguous, and
an AmbiguousSchemaNameException
is thrown. This exception contains a list of all the matching NameNode
objects.Conversion Considerations
Schema Property Mappings
Many properties defined in a Progress schema have a fairly clean mapping to a similar construct in a relational schema. Others do not. The following table summarizes the disposition of these properties with regard to schema conversion. Italicized Progress property names are implicit; others are keywords from the DF export file.| Progress
Property |
Context |
Purpose |
P2J
Use |
|||||||||||||||||||||||||||||||||
| NAME |
database |
Logical name of the database. |
Always appears as "?" in the DF
file, so this value is provided in the P2J configuration. |
|||||||||||||||||||||||||||||||||
| NAME | sequence |
Logical name of the sequence. |
TBD |
|||||||||||||||||||||||||||||||||
| INITIAL |
sequence |
Initial value of the sequence. |
TBD |
|||||||||||||||||||||||||||||||||
| INCREMENT | sequence |
Amount by which sequence is
incremented to generate a new, unique value. |
TBD |
|||||||||||||||||||||||||||||||||
| CYCLE-ON-LIMIT | sequence |
Whether sequence wraps when it
reaches its limit. |
TBD |
|||||||||||||||||||||||||||||||||
| MIN-VAL | sequence |
Minimum sequence value. |
TBD |
|||||||||||||||||||||||||||||||||
| NAME |
table |
Name of the table. |
Translated to replace invalid
characters. Becomes basis for relational table name and Java data
model class name. Value may be overridden by hints. |
|||||||||||||||||||||||||||||||||
| AREA |
table |
Progress housekeeping - table's
storage area. |
Discarded. |
|||||||||||||||||||||||||||||||||
| DESCRIPTION |
table |
Table description. This
value does not appear to be used at runtime, but is rather for the
convenience of developers and administrators. |
Comment in the hibernate
configuration files where table is defined. |
|||||||||||||||||||||||||||||||||
| VALEXP |
table |
Validation expression to be applied against record deletions for this table. This expression must ultimately evaluate to true or false, but it can contain any valid Progress code, including preprocessor file includes. | Converted into valid Java
code and triggered on record deletes, possibly via a stored procedure. Implementation TBD. Note: There are no instances of table-level validation expressions in any of the schema dumps we have processed. |
|||||||||||||||||||||||||||||||||
| VALMSG | table |
Message to display to user if
validation expression fails. |
Converted to a Java string
resource and displayed to the user upon a failure of the converted
(Java) validation expression. Implementation TBD. |
|||||||||||||||||||||||||||||||||
| DUMP-NAME | table |
Progress housekeeping - name of
file to which table definition is dumped on export. |
Discarded. It is assumed
third party tools will be used to manage the relational database after
conversion. |
|||||||||||||||||||||||||||||||||
| FROZEN | table |
Progress housekeeping -
indicates table definition is read-only in data dictionary. |
Discarded. | |||||||||||||||||||||||||||||||||
| HIDDEN | table |
Indicates whether table is
hidden. The implications of this are currently unknown. |
TBD |
|||||||||||||||||||||||||||||||||
| NAME |
field |
Name of the field. |
Translated to replace invalid
characters. Becomes basis for relational column name, Java data
model instance variable name, and names of accessor/mutator methods in
data model class. Value may be overridden by hints. If no field LABEL property is provided, the unmodified Progress field name is stored as this column's label (see below). |
|||||||||||||||||||||||||||||||||
| OF | field |
Name of table for which this
field is defined; a housekeeping vestige of the DF file format. |
Used as a reality check during
DF file parsing only. Discarded thereafter, since a column's
containing table is implicit. |
|||||||||||||||||||||||||||||||||
| AS | field |
Data type of field. |
Converted to the appropriate
P2J data wrapper type (see com.goldencode.p2j.util)
or Hibernate type, from which the appropriate SQL type and Java data
type
are inferred. The mapping is as follows:
|
|||||||||||||||||||||||||||||||||
| FORMAT | field |
Default format string used to
display field's value in UI. |
Translated to a compatible Java
format string and used when updating the UI. Implementation TBD. |
|||||||||||||||||||||||||||||||||
| LABEL | field |
Label which appears by default
when this field appears in UI and in printed reports. |
Stored verbatim and used as the
field's default label in the UI and in printed reports.
Implementation TBD. This information is used to help generate XML comments in the Hibernate mapping documents and JavaDoc comments in the Java Data Model Object class definitions. If no label is provided, the Progress field's name (unmodified), must be used as its label, to maintain a compatible look and feel. |
|||||||||||||||||||||||||||||||||
| POSITION | field |
Unknown. Possibly an
indicator of the order in which fields are displayed in the table
editor of the data dictionary. |
TBD |
|||||||||||||||||||||||||||||||||
| SQL-WIDTH | field |
Indicates width for visual
representation of a field; highly related for format
phrase. For fields with extent > 0, this value must first be
divided by the extent size. |
Stored and used in calculating
the length in bytes of a character or binary column, but only if larger than the length
calculated using a statistical analysis of existing data for a given
column. |
|||||||||||||||||||||||||||||||||
| ORDER | field |
Default order in which the UI
widget which displays this field's value is drawn in relation to other
fields' widgets, when multiple fields from a table are displayed.
Also the order in which table fields are exported to Progress export
files. The order assigned to a given field is compared with that
assigned to other fields in the table to determine the current field's
relative position (in ascending order). |
Stored and used to reorder
properties within a class in the P2O schema document. The order
is critically important when importing data from Progress export files,
as the data must be read from these files in this order. |
|||||||||||||||||||||||||||||||||
| EXTENT | field |
If greater than 0, indicates the
field holds an array of values of the field's data type, rather than a
single value of that type. The value of the extent is the size of
the array. |
Array values are stored in a
secondary table. The secondary table contains a foreign key
column related to the primary key of the table containing the array
column. An index column in the secondary table maintains the
appropriate indexing of the array values. If multiple columns in
the same table use the same extent value, they are all be stored in the
same, secondary table, each in a separate column. Otherwise, a
separate, secondary table exists for each occurrence of a new extent
value within the same Progress table. The number of rows in a secondary table equals the number of rows in the primary table times the size of the extent which the secondary table manages. For example, a table containing 1000 rows which manages four fields, each with an extent of 12 will be related to a secondary table containing (1000 * 4 * 12), or 48,000 rows. The data model object which maps to a table containing array columns provides access methods to make this backing implementation transparent. See also Converted Table Structure. |
|||||||||||||||||||||||||||||||||
| DECIMALS | field |
|||||||||||||||||||||||||||||||||||
| COLUMN-LABEL | field |
Text which overrides LABEL when
the field is displayed in columns. |
Stored verbatim and used as the field's default column label in the UI and in printed reports. Implementation TBD. | |||||||||||||||||||||||||||||||||
| INITIAL | field |
Initial value of the field. |
Translated into a value
appropriate for use in Java. Used to initialize the instance
variable which corresponds with this field upon construction of the
appropriate Java data model class. If no initial value is
defined, use the default for the field's data type. |
|||||||||||||||||||||||||||||||||
| HELP | field |
Help text to display to user
when the UI widget which represents this control gains input focus. |
TBD. |
|||||||||||||||||||||||||||||||||
| MANDATORY | field |
Indicates whether the field may
contain the unknown value. If set, the unknown value is
disallowed. |
Maps to NOT NULL or the
appropriate equivalent. |
|||||||||||||||||||||||||||||||||
| CASE-SENS |
field |
Indicates the field is case
sensitive (it is not, by default). This refers to the field's
data, not its name. |
TBD. |
|||||||||||||||||||||||||||||||||
| VALEXP | field |
Validation expression to be applied against record-level inserts and updates when the current field's value is saved from the record buffer to the database. This expression must ultimately evaluate to true or false, but it can contain any valid Progress code, including preprocessor file includes. | TBD. |
|||||||||||||||||||||||||||||||||
| VALMSG |
field |
Message to display to user if
field's validation expression fails. |
TBD. |
|||||||||||||||||||||||||||||||||
| VIEW-AS |
field |
Overrides the default widget
type used to display the current field in the UI. |
TBD. |
|||||||||||||||||||||||||||||||||
| NAME |
index |
Logical name of the index. |
Translated into an
SQL-compatible name and used as the name of an analogous index defined
on the relational table associated with the Progress index' table. |
|||||||||||||||||||||||||||||||||
| ON |
index |
Name of the table for which the
index is defined. |
Used as a reality check during DF file parsing only. Discarded thereafter, since an index' containing table is implicit. | |||||||||||||||||||||||||||||||||
| UNIQUE |
index |
Indicates that the field or
fields comprising the index must be unique for each row. In the
case of multiple field indexes, the combination of all fields in the
index must be unique. |
Translated to a unique
constraint which is applied to the table for which the index is defined. |
|||||||||||||||||||||||||||||||||
| PRIMARY |
index |
Indicates that the index is used
as the default for query purposes. |
TBD. |
|||||||||||||||||||||||||||||||||
| WORD |
index |
Indicates that the index is a
lexical index on the individual words in the values of a character
field. |
Not used in initial
project; implementation will be deferred. |
|||||||||||||||||||||||||||||||||
| DIRECTION | index field |
Indicates sort direction for the
index: ascending or descending. |
TBD. |
|||||||||||||||||||||||||||||||||
| ABBREVIATED |
index field |
TBD. |
TBD. |
Data Types (TBD - obsolete)
Hibernate defines a set of database vendor-neutral data types, which
are mapped to specific database dialects transparently by the Hibernate
framework. Most P2R type mappings can be handled by default conversions
(e.g., character becomes the Hibernate string
type, integer remains integer, etc.).Some type mappings may require non-default conversions. For instance, a field of type
character which in practice contains
very
lengthy data must be mapped to type text (which
ultimately
is mapped by Hibernate to a database vendor-specific type such as LONGVARCHAR).
In the event of refactoring a single field to multiple columns, or
multiple columns to a single field, type is represented in the hints
document by a non-standard identifier. This causes the conversion logic
to look up a class to handle the mapping in a custom way (TBD).For instance, there is no
time type in Progress, but
there
is a Hibernate time data type. For consistent use of time
information across tables, it may make sense to refactor all
multi-field
time representations from a Progress schema into a single relational
database column defined as Hibernate's time type. A
hypothetical set of four Progress integer fields
representing hours, minutes, seconds, and milliseconds would in this
case be mapped into a single column of type time. This
would result in a special type descriptor (perhaps an XML attribute of type="specialtime1")
being defined in a hint and backed by a custom converter class.Converted Table Structure
The conversion process of a Progress database table to a relational database table is not necessarily a one-to-one affair. While simple fields will map directly to a counterpart of similar data type on the other side, the Progress feature of extent fields (i.e., data columns which actually represent an array of data values of any of the supported data types), calls for some refactoring during conversion for certain tables.A single Progress table will convert to a primary table in the target database, with zero or more secondary tables in which the extent fields are mapped. Fields of like extents in the Progress table are removed from the primary table and are re-mapped to a common secondary table. A separate secondary table is defined for each grouping of like extents. The secondary table is associated with the primary table by a foreign key which references the primary table's surrogate, primary key column. The naming convention for such a secondary table is
<converted
table name>__<extent size>.For example, consider a Progress table
vendor which
contains several simple fields (name and address),
as well as several fields (order, invoice,
and widget), which have extents greater than 0.| Table vendor |
| character name |
| character address |
| integer[5] order_number |
| character[5] invoice |
| character[3] widget |
This table is refactored during conversion into a primary table and two secondary tables as follows.
| Table vendor (primary) |
Table vendor__3 (secondary) |
Table vendor__5 (secondary) |
||
| integer primary_key |
integer parent__id (references
vendor.primary_key) |
integer parent__id (references
vendor.primary_key) |
||
| varchar name |
varchar widget |
integer order_number |
||
| varchar address |
integer list__index |
varchar invoice |
||
| integer list__index |
Note: the data types indicated in the converted table are representative only, as data type names vary among database vendors. Widths are intentionally omitted to simplify the example.
Each secondary table contains a multiple of the number of rows in table
vendor, where the multiplier is the extent size
represented by that secondary table. So, for instance, if table vendor
has 50 rows, table vendor__3 has 150 (50 * 3) rows, and
table vendor__5 has 250 (50 * 5) rows. Each
secondary table has a foreign key parent__id which
references primary_key in table vendor.
A secondary table's primary key is a composite of parent__id
and list__index, where the value of the latter represents
a record's zero-based index of its position in the original Progress
extent field's array. In other words, the data at each index in
the original extent field is distributed among <extent size> records in the
new, secondary table, as the following example indicates. The
order of the data values in the original, Progress extent field is
strictly maintained.| name | address |
order_number |
invoice |
widget |
| Vendor ABC |
123 Main Street, Anytown, USA,
etc... |
5 22 86 87 190 |
65-ABGD-001 78-FFFE-005 12-UIOP-002 56-B8TY-099 72-MNQW-62 |
W8 W3 W6 |
|
|
|
Data Model Objects
Converted tables are mapped via Hibernate to Data Model Object (DMO) classes. DMO classes are relatively simple, Java bean-like constructs which generally have:- instance variables of a P2J data wrapper type (i.e., from
com.goldencode.p2j.util) to represent each simple field; Lists of these wrappers to represent an extent field with an extent greater than 0 (in the case there is only one such field); and- static, composite inner classes to represent multiple columns with like extents greater than 0.
The following example, which builds off the
vendor table
in the previous section,
illustrates the core of the DMO class definition (sans JavaDoc
comments). This example assumes the initial value is specified as
the unknown value (?) in the Progress schema for each of
the table's fields.
import java.util.*; |
Table
vendor maps to a DMO class named Vendor.
The vendor's name and address properties
are accessible via simple getter and setter methods. The
properties associated with extent fields (widget, orderNumber,
and invoice) are accessible via specialized getter and
setter methods which accept an index parameter. The
index parameter is zero-based; therefore it must
fall within the range0 <=
index < extent sizeAn
ArrayIndexOutOfBoundsException will be thrown for index
values outside of this range.In this case, there is only one field of extent 3 (
widget)
in the original Progress table. This maps to a simple List
of character objects in the DMO. However, there are
two fields of extent 5 (order_number and invoice)
in the Progress table. These are grouped together into a static
inner class (Composite5) of the top level class Vendor.
The mapping of fields with a common extent as properties of an inner
class allows Hibernate to manage these properties as a single,
secondary table (vendor__5 -- see previous section) mapped to a
single class (inner class Vendor$Composite5). The
naming convention for such inner classes is always:<converted table name>$Composite<extent
size>Generally, it is not necessary for application code to use these inner classes directly, as public access to their data is provided by the indexed getter and setter methods of the top level class. Thus, these inner classes have package private access. Hibernate accesses them directly through reflection to do its work.
Hibernate Mappings (TBD)
A top level class such as Vendor in the above sections is mapped by
Hibernate to one or more database tables using an XML mapping document.Key Constraints
Primary and foreign keys constrain the relationship between database tables to enforce data integrity in a relational database. In general, tables can be related in the following ways:- not at all;
- one-to-one relationship: one record in table A corresponds to exactly one record in table B (example: a "home-address" field in a customer profile record in one table might correspond to a single record in a table of mailing addresses);
- one-to-many relationship: one record in table A corresponds to zero or more records in table B (example: a single customer profile record in one table might correspond to many records in a table of customer orders);
- many-to-one relationship: the inverse perspective on a one-to-many relationship;
- many-to-many
relationship: one record in table A corresponds to zero or more
records in table B and vice versa. Note: conversion
currently does not support this type of relation at the schema level.
Progress has no concept of an explicit primary key to foreign key relationship defined at the schema level. All table relations are defined in Progress source code, rather than in the database schema. A relational database, on the other hand, typically defines these relationships in the schema, by assigning a primary key in one table and a corresponding foreign key in another. Since a relational database relies heavily on such relations, it is important to determine to the degree possible, how to infer such relations from a Progress schema. Nevertheless, the introduction of key constraints between tables where there are none defined today in the Progress schema may introduce unwanted restrictions on data insert and update in the resulting application. As a result, we introduce only those key constraints which can be positively inferred from the existing Progress schema and application codebase. The following techniques are used for this analysis:
- Analyzing Progress table indexes to detect fields which are
primary key candidates
- Analyzing natural joins between Progress tables
A goal of conversion is to define a primary key for every table in the relational database schema. A primary key must be non-nullable and unique. In the converted schema, the primary key will be a single-column, surrogate key; that is, a column which has no business meaning, but is used only for database purposes. Where possible, the same name is used across tables to indicate the primary key column. A new column is introduced for this purpose.
Where a foreign key relationship has been established, the Progress field(s) which enabled the association in the referencing table are dropped. These are duplicative with the corresponding fields in the referenced table. The association which they enable with the referenced table is now maintained with a single column foreign key which references the surrogate, primary key in the referenced table. In the referenced table, these corresponding fields remain, and the referencing table must now access these columns via a join. In this case, data integrity is maintained during data import, by ensuring that records in referencing tables are correctly fixed up to use the new surrogate primary key instead of the existing, referencing field(s). An illustration of this concept follows.
In the old relation, columns 1, 2, and 3 represent a multi-column primary key in Table A and columns 1', 2', and 3' in Table B a multi-column foreign key:
| Referenced
Table (A) |
Referencing
Table (B) |
|
| column
1 |
column
1' |
|
| column
2 |
column
2' |
|
| column
3 |
column
3' |
|
| additional columns... |
additional columns... |
Post-conversion, a surrogate primary key has been added to Table A; a referencing foreign key column has been added to Table B. Columns 1', 2', and 3' have been dropped from Table B. Access to this data is now achieved via a join between the tables:
| Referenced
Table (A) |
Referencing
Table (B) |
|
| surrogate
primary key |
surrogate
primary key |
|
| column
1 |
foreign
key to table A |
|
| column
2 |
additional columns... |
|
| column
3 |
||
| additional columns... |
Progress Table Indexes
The term index in Progress does not have exactly the same meaning as it does in a relational database context. In Progress, and index is used for multiple purposes:- to aid in performance during data access, including in joins between tables;
- to enforce uniqueness constraints;
- to allow the database to perform natural joins between tables;
- to determine the sort order to be applied to the results of a query.
If one or more indexes are defined for a Progress table, one of them must be designated as the primary index. This designation does not connote an analog for a primary key; instead, it simply defines the index to use as the default index for purposes of retrieving and sorting records in a query. The designation of a Progress index as unique is more useful when attempting to determine primary key candidates. If only one unique index is defined for a Progress table, the fields in that index essentially define a primary key. If a table defines multiple, unique indexes, it is ambiguous from this analysis alone as to which index should be used as a primary key. However, since we are introducing surrogate primary keys, this point is largely moot, except in cases where we can infer a foreign key relation from another table. Additional analysis must be performed to make this determination. In such cases, the foreign key column introduced into the "foreign" table must contain the correct surrogate key from the "primary" table. It is necessary when importing Progress data into the new relational schema, to correctly match records using values found in the field or fields which define the join between the two tables involved in such a relation.
Because of the significant difference in purpose, the conversion does not carry over Progress indexes per se. New indexes are created for the relational schema as follows:
- Foreign key columns are indexed at schema conversion time (these are always single column indexes, since we use a single column surrogate primary key). Primary key columns are not explicitly indexed, as these are implicitly indexed already by the RDBMS.
- The first column in a Progress index on a large table, which
index is referenced by the Progress
use-indexdirective, is indexed. This assists the performance of the SQLorder byphrase when sorting results.
- Simple indexes are created at code conversion time based upon actual data access logic and statistics gathered during data conversion/import. The following rules of thumb apply:
- small tables are not indexed, since the RDBMS query planner
generally will empoy table scans in this case anyway;
- boolean columns are not indexed, since the range of possible values is so low;
- large text columns are not indexed, since most data access consists of unanchored text searches which do not benefit from indexes;
- given a data access search condition detected in Progress code, the first column to pass the above screening tests is indexed.
The conversion also considers index redundancy. Two Progress indexes are considered redundant with one another if they:
- both have the same uniqueness characteristic (i.e., they are both unique or both non-unique); and
- both define the same leading components.
- if they differ in component count, the less specific index (i.e., the one containing fewer elements) is dropped; otherwise
- if one is the primary index, the other is dropped; otherwise
- if one is referenced by use-index and the other is not, the other is dropped; otherwise
- if neither is referenced by use-index, one is dropped arbitrarily.
use-index
or is the primary index, the dropped index is flagged to delegate
references (including default references to the primary index) to the
surviving index.Once redundant indexes have been dropped, the final disposition of Progress indexes is one of the following:
- they are converted to unique constraints (unique indexes) - only fields surviving the conversion are considered for the constraint;
- they are used for composing SQL
order byclauses (primary indexes and those referenced in source code by ause-indexstatement) - all fields are considered for sorting; - they are dropped as dead entities.
Natural Join Analysis
A Progress schema can be analyzed to detect the potential existence of what we will term natural joins between tables. However, these are only potential relations, which do not really exist unless realized in the source code through actual join operations. Thus, an analysis of the schema only yields many false positives. Natural joins are realized in the source code using theof language keyword within a record phrase, as
in: ...tableA [outer-join] of tableB...
For a natural join to occur, the following conditions must be met:
- Both tables must contain at least one field with the same name and data type. Additional common fields are permitted.
- There must exist a unique index in at least one of the two tables whose index fields are the common fields of condition 1, or some subset thereof. The index must not contain any fields which are not held in common between the tables.
tableA and tableB,
the following information can be gleaned from the outcome of this
test. Assuming condition 1 is met...- If
tableAmeets condition 2, buttableBdoes not, a one-to-many relation betweentableAandtableBis implied. Furthermore, a primary key to foreign key relation betweentableAandtableBis implied. The field (or composite of fields) defined for the index which meets condition 2 is essentially the equivalent of a primary key. The matching field (or composite of fields) in the other table is essentially the equivalent of a foreign key. - If both
tableAandtableBcontain a unique index which meets condition 2, and both indexes define the identical set of index fields, the relation between the tables is one-to-one. The set of fields in the common, unique index form the primary/foreign key relation. Essentially, this set acts as both a primary and foreign key in both tables. - If both tableA and tableB contain a unique index which meets
condition 2, but both indexes do not
define the identical set of index fields, it is ambiguous as to which
end represents the primary and which the foreign end of the
relation. In this case, an error is reported (with the intent of
triggering a manual review), but no join is created.
Uniqueness and the Unknown Value
For purposes of the uniqueness constraint imposed by a Progress table index, two instances of the unknown value (?) are not
considered equal to one another. That is, for a unique index
containing a field fieldA, which is not declared mandatory, two records containing
identical data in all other fields and the unknown value in fieldA
are each considered unique, and are both permitted in the table.This has an interesting implication for schema conversion, in that not all relational databases behave the same way. The value
NULL
in SQL is the equivalent for Progress' unknown value. Some
relational databases (e.g., PostgreSQL), consider two NULL
values inequal, which lends itself to a clean mapping between the
unknown value and NULL. Other databases allow only
a single NULL value for a column with a unique constraint.In the case where the backing database supports multiple NULL values past a unique constraint, the conversion approach is to leverage the unique constraint capability of the backing database to enforce the constraints imposed by Progress' unique index. In the case where the backing database does not support multiple NULL values past a unique constraint, the conversion approach is to use a check constraint with an SQL expression to enforce the required uniqueness. Support for the latter case will not be implemented in the first release.
Determining Query Sorting
IntroductionIn order to accurately duplicate the behavior of the Progress 4GL single record reading approach, one must dynamically select each record of the specified table in the same traversal order which Progress would generate. This problem is complicated by the feature provided by Progress where the same record may be visited more than once if its data is changed in a manner that reorders it later (or earlier if the walk is backwards) in the sequence of records. This is very different from SQL's set oriented approach where one can be sure that the set returned is of a static size. Besides the obvious danger of creating infinite loops or otherwise non-intuitive behavior, this requirement means that each "next" or "previous" record retrieval must be based on a relative movement between records instead of a walk of a static list.
In order to duplicate the traversal order of Progress, the relative movement from one record to the next/previous must be based on knowledge of the exact sorting criteria used by Progress. As with many of the behaviors of the Progress language, there is a mixture of explicit and implicit factors that determine the exact sorting criteria used for each query.
The Progress database accesses all records via an index, via the combined use of multiple indexes or via a table scan. When a single index is used, to the degree that the requested sorting criteria doesn't exist or in some cases where the sort criteria doesn't fully specify an unambiguous ordering (but is compatible with the index), the index used determines the order that the records are returned. In other words, the index in use can and often does determine (or partially determine) the real sort order.
In the multiple index and table scan approaches, if no explicit sort order is specified, the sort order is undefined. In addition, even in cases where the sort order is explicitly specified, it is possible that records can be ambiguously ordered. When this occurs, the "secondary" sort order is undefined.
The BY phrase is used to explicitly specify a sort order. It is especially important to note that the sort order can be completely implicit (if no BY clause is provided), partially implicit (if the BY clause does not unambiguously specify an exact ordering) or completely explicit (if the BY clause results in an unambiguous order). For this reason, it is possible (and even likely) that a given Progress application will have ordering dependencies built in, possibly without the specific intention of the original author. This may appear as the order of records in a report or the order in which records are displayed in the user interface.
Implicit sort behavior in the single index case is dependent upon the selected index. For this reason, one must duplicate the implicit index selection that the Progress compiler makes. This is driven by analysis of query predicates (WHERE, OF and USING clauses), sort specification (BY clause) and explicit index specifications (USE-INDEX clause). These rules may be used for both FIND and FOR EACH type queries. Since there are differences in what can be done with these two query methods, some rules may not apply to both types. Of most importance, BY clauses can only occur in a FOR statement (FIND statement sort order is always based only on the selected index).
The following text describes the rules by which the sorting criteria are determined in Progress.
Single versus Multiple Index Selection
As noted above, some ambiguity in sorting is resolved using the index selected for record reading. This point really assumes that a single index is in use. Multiple indexes can be selected and are used together to read the specified records. In the multiple index case, all non-explicit sorting behavior is undefined. It is documented that in the single index cases, the 4GL developer can sometimes rely upon secondary sort behavior based on the index.
The FIND statement only ever uses a single index. The FOR EACH statement, GET statement and usage of PRESELECT all use multiple indexes whenever possible (assuming the -v6q command line option is not active). This multiple index support appeared in Progress v7 and applications that had a dependency on single index selection (an implicit sorting dependency) needed the v6 query compatibility mode (the -v6q command line option).
Even though certain language constructs are enabled for multiple indexes, it is the query predicate which determines if a single index or multiple indexes are chosen. In particular:
- Having OR criteria makes this much more likely. For block queries if an OR operator is involved multiple indexes will be selected even if there is only a subset of the index components that are involved in equality or range matches.
- With AND criteria an index must have all index components referenced in the predicate in equality matches (see below). This means that indexes that have only one component and predicates that reference a superset of fields in multiple indexes are more likely to trigger this condition.
- Is mostly important when there is no BY clause.
When a single index is used and there is no explicit sort order, the sort order is defined by the index. This is something that is relied upon by 4GL developers.
An important point is that when multiple indexes are selected any implicit sort order is undefined. It is documented that the 4GL developer should not rely upon any particular sort order that may be implicitly provided in the multiple index case since this may change in future releases. One is expected to explicitly specify BY clause in this case OR the code should be independent of the resulting sort order.
To the extent that a BY clause does not specify an unambiguous sort order, the sorting within the "buckets" defined in the BY is usually undefined. In other words, if multiple records have the same data in the given set of fields specified in the BY clause, the sort order of these records will be undefined even though the overall sort order of the query is defined. This is called the secondary sort order.
The exception to this is the case where there is a single index used for record access AND there is an explicit BY clause whose fields, the order of those fields and the direction of each field's sort (ascending or descending) all match the leading subset of the index in use. In this case, the index and the sort criteria are compatible and the sorting is completely specified (and implemented) by the index on the Progress database server. This means that in such cases, there will be a reliable secondary sort ordering based on the additional (more specific) fields in the index that were not part of the BY clause.
Otherwise, all secondary sorting behavior (for both single and multiple index cases) is undefined.
Some simple tests of explicit sorting have shown the following behavior:
- The BY clause is honored as the primary sort criteria.
- The selected indexes can affect the secondary sorts. Other
than the exception noted above, the rules by which this occurs are
undefined.
- In some cases a secondary sort is based on the record create or
recid/rowid order. Without further tests, the actual criteria
here is not
visible in since the current tests used records that had been added
sequentially. This means that the create order is the same as
rowid order in the current tests. A more
active set of data with volumes of deletes and adds might be able to
differentiate
this last
rule grey area.
It is possible to imagine a situation where the sort order in the multiple index case makes an important difference in an application:
- Report sort or record navigation visible to end user.
- A situation where which record gets processed first is important.
Since the resulting data imported into the P2J system will be based on the .d export files (which are in primary index order), all physical location information is lost in this export/import. To the extent that this is important, the current approach cannot guarantee this order.
None of the undefined cases will be supported at this time, but all the defined cases will be supported. The following are the defined cases (which can be relied upon by the 4GL programmer):
| Sort Case |
Result |
| explicit sort using BY + incompatible index selection | The sort will be completely
defined by the BY criteria. The index has no affect. |
| explicit sort using BY + compatible single index selection cases (implicit or explicit) for secondary sort | Index driven sort. The BY
clause is only a subset so the index itself specifies the complete sort. |
| explicit single index choice using USE-INDEX (with no explicit sort) | Index driven sort. |
| implicit single index choice (with no explicit sort) | Index driven sort. |
Due to this set of rules, the single index used to select records must be calculated. If in Progress, the result would have been a multiple index, in P2J it will be calculated as a single index. This may approximate some of the behavior of Progress, though it is not expected to completely match the undefined behavior. The rest of this document describes this index selection process.
Implicit WHERE Clause Components
As with many things in Progress, a query predicate (i.e. record selection criteria) can be specified explicitly (WHERE clause) or implicitly (through OF or USING clauses and through the special unqualified constant form of FIND). Before analyzing the query predicate, one must add any implicit portions to get the complete expression used to select records.
Since it is the WHERE clause that largely drives the selection of the index, all implicit portions of the WHERE must be made explicit before the index selection process occurs.
Unqualified Constant:
A FIND with a single constant (literal value) instead of a standard record phrase is the same as making an addition to the WHERE clause referencing a primary index (which must have only a single field) in an equality match. Thus:
FIND customer 1 WHERE country = "USA".
Assuming the customer table has a primary key which has the single index component cust-num, this is actually the same as:
FIND customer WHERE (country = "USA") AND cust-num = 1.
OF clause:
The usage of the OF clause causes an *addition* of an equality match for each field in the common index (an index that is common between the two tables and unique in at least one of them). These equality matches are connected via an AND operator. If the common index between two tables is comprised of fields A, B and C:
FIND customer OF order WHERE name = "Bogus"
is converted into:
FIND customer WHERE (name = "Bogus") AND customer.A = order.A AND customer.B = order.B AND customer.C = order.C
Note that due to the join-like nature of the OF clause, the OF itself implicitly defines the index which is used to select records in the target table based on equality matches with those common fields in the preceding table. This means that this case actually does not require any WHERE clause analysis since the index is predetermined. This case is documented here for completeness but the WHERE clause will not be rewritten.
Direct Logical Field References
A logical field that is directly referenced as the entire predicate or as a direct operand of a logical operator is actually considered to be the same as an equality comparison with the literal true (thus it will affect the index selection process described below). This means that:
WHERE logicalField
is the same as
WHERE logicalField = true
Interestingly enough, the use of the NOT operator in this case does not get translated into the corresponding equality comparison (so it does not affect index selection as described below):
WHERE NOT logicalField
is not the same as
WHERE logicalField = false
USING clause:
The usage of USING causes an *addition* of an equality match for each field referenced with the instance of that field in the default or specified screenbuffer (FRAME). These equality matches are connected via an AND operator. So:
PROMPT-FOR customer.cust-num.
FIND customer USING cust-num WHERE country = "finland".
is converted into:
PROMPT-FOR customer.cust-num.
FIND customer WHERE (country = "finland") AND cust-num = INPUT customer.cust-num.
An alternate form of USING usage exists for any field that is defined as an abbreviated field in an index. In this case:
PROMPT-FOR customer.cust-num.
FIND customer USING cust-num WHERE country = "finland".
is converted into:
PROMPT-FOR customer.cust-num.
FIND customer WHERE (country = "finland") AND cust-num BEGINS INPUT customer.cust-num.
The difference is that the "=" operator is converted into a "BEGINS" operator.
From the Progress documentation:
"Abbreviate" is an index option that lets you conveniently search for a partial match based on the first few characters of a field (like usingBEGINS) in the FIND ... USING statement. This option is only availableon indexes that have a character field as their last index component.Single Index Selection Rules
Indexes are selected based on explicit and implicit criteria. In the absence of an explicit index specification (USE-INDEX), the Progress compiler makes an implicit index selection. This selection is based on an analysis of the query predicate. The idea is that the Progress database server is completely driven by index processing (or table scans if no index can be used). There are a very limited set of operations that can be specified in a predicate which can be translated into index operations. Anything that can be translated into an index operation can be resolved by the database server without the Progress client evaluating expressions to determine if a given record matches.
In other words, a single query predicate can be processed completely on the client, completely on the database server or in both places. The degree with which the predicate can be processed on the server has a great impact on the performance of the database access since it is highly inefficient to read many records from the server only to reject them at the client when they do not match the predicate. This is a statement of data transfer volume (a less visible factor in shared memory implementations than on network implementations). More importantly it is a statement of the efficiency of general purpose interpreted 4GL expression performance compared to a database server that is tuned for such processing.
Client side operations are anything:
- with no functional counterpart on the server (e.g. arithmetic
operators like +)
- which operates on a database field that is not an index component
(only index components can be used to traverse a table, otherwise the
table must be sequentially scanned)
- which accesses data/state that only exists on the client
An operation is specified by a logical comparison operator. The set of operators known by the database server is limited:
| Operator |
Match
Type |
| EQ, = |
Equality |
| LT, < | Range |
| GT, > | Range |
| LE, <= | Range |
| GE, >= | Range |
| BEGINS | Begins (this plays a dual roal
in both rules 4 and 5 below) |
| CONTAINS | Word |
Any other comparison operator than noted in this list, is unknown to the database server. That means that NE (<>), NOT, MATCHES cannot be processed on the database server.
This means that when any of the above operators are encountered, the compiler is allowed to examine the two operands to determine if one of them is an index component. If either of the operands (it does not have to be on the left side only) is an index component, then this may modify the index selected (based on the rules below). For example, if one encountered a sub-expression indexField = 5, then this would be considered an "equality match" on the indexField field.
The only other operators that are recognized during this analysis are the conjunction and precedence operators. In the single index case, the AND operator allows the compiler to analyze both operands for index selection purposes, but the OR operator does not allow operand analysis. This makes sense when one considers that in a single index case, the best fit index will naturally be able to reduce the result set based on an AND condition. But the OR operator makes it significantly harder (or sometimes impossible) to ensure that the results of a single index can fulfill all possible conditions.
In the multiple index case, the AND and OR operators may both have some support however this has not been explored or documented.
Parenthesis (the precedence operator) neither hinders nor helps the analysis process since it merely ensures that the structure/precedence of the expression is forced into a known pattern. This resulting structure is what is analyzed, after the parenthesis have already been applied.
Any operand of one of the above operators that is not a recognized operator or an index component (field) will be ignored and it (and its children) will not have any impact on the index selection. This means that all other expression features (and their operands) are ignored. Another way of saying this is that these are not matches as termed above, they have no impact on the index selection. This is the list:
- literals
- arithmetic operators
- builtin functions
- user-defined functions
- variables references
- methods
- attributes
- field references to fields external to the current table
A sort match is a special type of match that is determined based on analysis of a BY clause rather than by analyzing the WHERE predicate. Identifying sort matches using BY clause analysis is complicated by 2 factors:
- There is a specificity to the order in which the BY clauses
occur. The first BY clause is the least specific component of the
sort order (the least granular which forces the overall ordering of the
results). Each subsequent BY clause only changes the sort order
within the larger/broader categories created by the previous sort
specification. Thus subsequent BY clauses are increasingly
specific sort criteria. This order must be preserved in the list
of sort matches and any comparisons must take this order into account.
- There is a direction component to the BY clause (implicitly this is ASCENDING but it can be explicitly specified as DESCENDING). One would think that if a BY clause references an index component field BUT the sorting direction is not compatible with the index component's definition, then that field reference would not be a sort match. In fact, Progress still does count this as a sort match (based on index selections reported in the compiler's XREF output). The exact meaning here is unknown and this index selection is likely to be useless since it seems that the Progress client would be forced to ignore the ordering provided by the server index and handle sorting itself in this case.
- The expression in a BY clause can be more complex than a simple
field reference. Only a simple field reference can be counted as
a
sort match as more complicated expressions must be resolved on the
client at runtime (and thus they cannot be used with an index so they
do not affect index selection). This idiom means that the *result*
of the BY expression is sorted. In other words, one can use a n
arbitrary expression such as the built-in function substring(...) to
extract, derive or otherwise transform the data and get a string or
integer... that then defines the sort order.
This list of rules is specified in priority order (1 is the highest priority). Each priority level is checked in turn, from highest to lowest. At the start of processing, there is a "selectable" list that includes all possible indexes for the given table. As each priority level is processed, indexes that are selectable based on the criteria at that level will remain in the selectable list and all other indexes will be removed. If the selectable list contains a single matching index after a given priority level is evaluated, that index will be the selected index. If there are multiple matching indexes at a given priority level, then the reduced selectable list is used in subsequent priority levels to provide a "tie breaking" process to determine which index is selected. This general rule does have some exceptions which are noted below.
The selection rules:
- An index that was specified in
USE-INDEX. The use of the
USE-INDEX phrase overrides any compiler efforts at
selecting the index(es) to use and limits the selection to that single
index. This is the (one and only) explicit index case. Only
one USE-INDEX
clause can be present in any record phrase, so there is never a need
for a tie
breaker for this priority level.
- A unique index with all components in equality matches. When each and every index component of a unique index is involved in an equality match that index will be selectable. Since there can be more than one unique index and the predicate could cause the selection of multiple unique indexes, the unique index that has the most components will be the one chosen. If there are multiple unique indexes that are selectable with the same number of components, then this list of selectable choices will be further processed starting at rule 7 below (this is a tie breaker). In other words, if there is more than 1 unique index that is selectable, rules 3 - 6 are bypassed. If only one unique index is selectable, that index is used. If no unique indexes are selectable, then processing continues with rule 3.
- A word index referenced through
contains. When a word index is referenced through a
contains operator, that
index is selectable. Since there can be more than one word index
and the predicate could
select multiple word indexes, then this list of selectable choices will
be further processed starting
at rule 7 below (this is a tie breaker). In other words, if there
is
more than 1 word index that is selectable, rules 4 - 6 are
bypassed.
If
only one word index is selectable, that index is used. If no word
indexes are selectable, then processing continues with rule 4. A
word index cannot be used in FIND statements.
- Most sequential leading equality matches. Due to the special nature of rules 2 and 3, when this rule is evaluated, it always processes starting with the full list of all possible indexes as the potential indexes. The indexes that have the most sequential leading components with equality matches are selectable. Most is interpreted in an absolute sense, not a relative or percentage sense. For example, if 1 index has the first 4 index components all involved in equality matches, and no other index has 4 or more leading index components in equality matches then this index is chosen. If no indexes were selectable via this rule, then the full list of all possible indexes will be checked using rule 5. If more than 1 index has the same number of leading index components in equality matches, then this reduced list of selectable indexes further refined:
- The
next index component (after those already known to be involved in an
equality match) of each selectable index must be evaluated to see if it
has a BEGINS match in this component. For example, an index with
its first 3
components with equality matches and the 4th component as a BEGINS
match will be selected
over an index with 3 equality matches (only).
- The equality matches must all occur before the begins matches and all equality/begins matches must still be sequential (the first index component without any match ends the calculation). Only one component after the equality matches is checked for a begins match.
- If only 1 index is selectable after the begins match check, this index is chosen.
- If more than 1 selectable index is still selectable after the begins test (i.e. if multiple indexes have the next component as a begins match), then this reduced list of selectable indexes is evaluated by rule 6.
- If none of the selectable indexes were matched via this begins tie breaker, processing continues in the next sub-rule (f).
- The
next index component (after those already known to be involved in an
equality match) of each selectable index must be evaluated to see if it
has a range match in this component.
- There is no concept of "most
additional sequential range
matches" to which the PSC documentation (the Monographs at least) are
referring when they list "most range matches" as an index selection
criteria. Only 1 range match is ever considered.
- If only 1 index is selectable after the range match check, this index is chosen.
- If there are still more than 1 selectable indexes that the next component in a range match, then this reduced list of selectable indexes is evaluated by rule 6.
- If none of the selectable indexes were matched via this range tie breaker, processing of the selected indexes (all with the same number of equality matches) continues in rule 6.
- An index with its first component involved in a range or begins match. All indexes that have their leading component in a range or begins match are selectable. There is no concept of "most sequential leading" matches when it comes to range/begins matches (contrary to the PSC documentation/Monographs). Range/begins matches to fields other than the first index component are ignored for index selection purposes. If more than 1 index is selectable, then the reduced list of selectable indexes is evaluated by the rule 6.
- Most sequential leading sort
matches. The indexes that have the most sequential leading
components with sort
matches (an index component directly
specified in a BY clause rather than the WHERE) are
selectable. For a sort match to be valid, the index components
must be matched in index component name, specificity and sort
direction. Most is interpreted in an absolute sense, not
a relative or percentage sense. For example, if 1 index has the
first
4 index components all involved in sort matches, and no other index
has 4 or more leading index components in sort matches then this
index is chosen. If more than 1 index has the same number of
leading
index components in sort matches, then this reduced list of selectable
indexes is evaluated by rule 7.
- The primary index. This rule is special because it can be "directly" reached from multiple rules above. When this rule is evaluated, the selectable list may include all possible indexes (if no rule above was matched) or it may include a reduced set of selectable indexes (if one or more of the rules above selected indexes). Whichever is the case, this list is searched for the primary index. If the primary index is selectable, then this index is selected. There can be only one primary index and even if there are no indexes defined for a table there is an implicit primary index that is the same as the rowid order. There can never be a "tie" here but in the case where the primary index is not selectable, rule 8 is used.
- The index with the alphabetically first name. In general, the index name (from the selectable list) that is lexicographically first (case insensitive) is the index chosen. The only exception is if this is being used as a tie breaker for unique indexes (rule 2), where the lexicographically last (case insensitive) index name is the index chosen. Since all index names must be different (in more than just case) within a given table, this rule will always result in a single index choice.
The order of index components in a predicate makes no difference in index selection. This means that the following two constructs are identical in result.
A = ___ AND B = ___
B = ___ AND A = ___
Assuming that there is an index with sequential leading components A followed by B, this index would be selected in either case.
Likewise, a field reference as an operand can appear on the left or right side of a supported operator and it is still honored EXCEPT in the case where both operands of a supported operator are direct field references (to the given table) or contain nested field references (to the given table). In this case, both field references are ignored (do not affect index selection).
So of the following examples:
field = 4
4 = field
field = field2
field = entry(1, field2)
field = field2 + 5
field + 5 = field2
The first two examples both result in field being used in index selection. In the third, fourth and fifth examples, both field and field2 are ignored even though one or both field references are direct operands of a supported operator!
Field references (which are index components that would normally affect the index selection) will be ignored if they are operands of unsupported operators. Likewise, such field references that occur inside an ignorable sub-expression are also ignored. Only field references that are direct operands of a supported operator will be considered.
A supported operator is only honored if it is the deciding/controlling operator for the expression or if it is an operand of an AND conjunction which is accessible. To be accessible, the AND operator cannot be contained within or an operand of an ignorable sub-expression or ignorable operator (including OR).
This means that in the following:
(field = 64) = (field2 < 100)
Both field and field2 are ignored since their respective operators are not operands of an AND operator nor are they the controlling decision of the expression.
The following is a summary of the interactions between index component references on both sides of each supported operator:
| Operand Reference Summary |
Right Operand | |||||||||
| no
reference |
direct
reference |
nested
reference |
||||||||
| Left
Operand |
no
reference |
|
|
|
||||||
| direct
reference |
|
|
|
|||||||
| nested
reference |
|
|
|
|||||||
Index Selection Special Case
A FIND lookup by recid/rowid does not use an index.