Feature #1757
update ANTLR to latest version
0%
Related issues
History
#1 Updated by Greg Shah over 13 years ago
The primary work is to change all the grammars (preprocessor, embedded 4GL, progress lexer/parser, trpl if it still exists). Any Java classes (e.g. AST implementations) that are dependent, must be updated. The jar is updated and any build issues must be addressed.
#2 Updated by Greg Shah over 13 years ago
- Target version set to Code Improvements
#3 Updated by Greg Shah over 9 years ago
- Target version deleted (
Code Improvements)
#4 Updated by Greg Shah about 7 years ago
There is a suggestion that moving to ANTLRv4 will improve performance.
On the other hand, we know that tree building is massively different in v3 and I have heard that they are de-emphasizing actions (which we rely upon extensively). This will not be a trivial task.
#5 Updated by Greg Shah over 4 years ago
ANTLR v3 is dead at this point and was replaced by ANTLR v4. Whether it makes sense or not to move to ANTLR v4 is not obvious.
These are useful guides:
https://tomassetti.me/migrating-from-antlr2-to-antlr4/
https://theantlrguy.atlassian.net/wiki/spaces/ANTLR3/pages/2687070/Migrating+from+ANTLR+2+to+ANTLR+3#MigratingfromANTLR2toANTLR3-ChangesinANTLRSyntax
Please note that ANTLR v4 does not build an AST (an abstract representation of the syntax), it builds a concrete "parse tree" which is the exact grammar structure. Building an AST (which is needed for a transformation of the scale of FWD) is something we would have to do manually.
Actions are discouraged as "advanced features" because the authors want to encourage using the same grammar in different target languages. We will ignore this advice since a different target is not needed and (more importantly) we cannot parse 4GL without actions.
These two areas will make ANTLR v4 a poor match to our needs. Upgrading the ANTLR version may not be a good idea.
#6 Updated by Greg Shah over 3 years ago
- Related to Feature #3883: eclipse plug for developing 4GL code using FWD including editing, syntax checks, running conversion added
#7 Updated by Greg Shah over 3 years ago
- Related to Feature #6319: IntelliJ plugin added
#8 Updated by Greg Shah over 3 years ago
- Estimated time deleted (
120.00)
#9 Updated by Greg Shah over 3 years ago
Our IDE support will need features such as auto-completion and syntax checking. These features are not suited to batch parsing runs where the parser runs for an entire input and then reports its results. Instead, the design must be able to answer questions like "Given a current cursor position and a list of edits to this source code, what are the possible valid completions to display for the user?".
That idea is discussed in relation to ANTLR, in these articles:
Implementing Code-Completion for VS Code with ANTLR
Universal Code Completion using ANTLR3
How to Implement ANTLR4 Autocomplete
Building autocompletion for an editor based on ANTLR
Java autosuggest engine for ANTLR4 grammars
Older ANTLR versions (v3 which is far beyond our current version) do not easily support this kind of processing. ANTLRv4 exposes the meta-model of the grammar itself in a way that allows these kinds of dynamic questions to be answered. It also has a far superior error handling approach that offers much more customization capabilities. This is a potentially good reason to move to ANTLRv4, though the cost is going to be high because of all the capabilities they removed along the way (actions, AST building vs parse trees...).
#10 Updated by Greg Shah over 3 years ago
Areas that will cause some problems in ANTLRv4:
- Actions in lexers have been removed except for at the end of the rule. We will have to rework our approach in several of the 4GL lexer rules (symbols, numbers/dates, strings). It should be possible but may be tricky. Semantic predicates can still be used (thank goodness).
- The Adaptive
LL(*)approach means that there is nok(fixed lookahead) value. The parsing is completely dynamic instead of statically determined at parser generation time. This means it is much more dependent upon being able to execute the prediction logic of each rule. They do this by exposing (at runtime) the "ATN" (Augented Transition Network) of the grammar. This is basically a graph network of the parsing or lexing rules where you can track the current state of the parse/lex and call the prediction logic of each rule as needed. This logic was hard coded using fixed lookahead, prediction "rollup" and sometimes "backtracking" in prior ANTLR versions. Now it is dynamic at runtime. There are implementation implications:- Predicates must be carefully written to:
- Avoid any side effects. (We probably already do this but it needs to be checked)
- Be executed without access to any rule-local state or really anything that would be detected by ANTLR as "context dependent" which would mean it cannot be executed except when actually matching.
- Be "visible". Any predicates that don't implement the following rules cannot be used for prediction because they are "hidden" (excluded) from the prediction engine.
- This means that they must not follow an action. Any action "in between" the current parsing location (a calling rule) and a predicate will hide that predicate because the code in the action is opaque to the prediction engine, so it assumes following predicates cannot be used for prediction. Among other implications, this probably means we must not have init actions, which will be a problem.
- They cannot reference the current token (
LT(1)) or tokens relative to the current token (LT(2)orLT(3)). The reason is that when the prediction logic is used in the calling rule, the current token is potentially very different than the state of the parse at the moment that something downstream is matched. The prediction engine may be looking arbitrarily far ahead in the token stream to determine if a particular alternative is the correct match. We do this kind of thing all over the place, so rework here is needed too.
- We need to avoid any token rewriting in init actions. We do this in multiple ways:
- Rewriting the type on the fly based on some lookup.
- Merging tokens together to fix lexer limitations based on parsing context.
- Predicates must be carefully written to:
- All AST building now needs to be done separated from the grammar. We will need to build our own AST implementation, using the existing ANTLRv2 ASTs has negative value since they are not an efficient implementation. I think the generated listeners/visitors is not a nice implementation. This is much more work for us and I fear it is going to be some very repetitive logic that used to be very small/clean in the grammar.
- It may be slower (at runtime) than older ANTLR versions. I'm not sure about this, but several sources suggested this could be the case.
I will expand this list as I find any other issues.
Some very good things about ANTLRv4:
- Exposes the ATN for our own usage. This will be critical for implementing proper IDE support and for syntax checking. IDE support in particular requires us to be highly dynamic in our parsing, which cannot be done in the old style approach.
- Exposes a much richer error handling model, with better customization options. This is also critical to the IDE support and syntax checking.
- Handles left recursive grammars (actually, only direct left recursion, we still need to avoid indirect left recursion). This will make it possible to match a range of features which we had to handle in a more awkward way before.
- The Adaptive
LL(*)approach means that we no longer have problems with ambiguity or with having to bend the parser's lookahead limitations to match the4GL behavior. It is likely this will reduce the complexity of the parsing. - The new lexer modes feature may allow us to greatly simplify:
- Our preprocessor lexing to a single lexer with modes instead of two lexers and the
ClearStreamlexer switching approach. - Our Progress lexer which today does not match things properly when the 4GL goes into its special modes. We make up for that with rewriting in the parser. That rewriting needs to go away for prediction reasons so cleaner lexer, here we come!
- Our preprocessor lexing to a single lexer with modes instead of two lexers and the
- Grammar imports may be useful to share some rules. We will have to see if the limitations are a problem.
- There is better IDE tooling for writing and testing grammars in v4.
- We can generate railroad diagrams for our grammars in v4, which will be super useful for documentation. My previous approach was to migrate our parser to ANTLRv3, strip out the actions and use a 3rd party tool to generate the diagrams. It was painful and I don't want to do it again. The new approach is possible because in ANTLRv4, you design things so that the prediction logic is all visible/callable and can be exposed in the ATN. That means that a diagramming tool can be written to walk the ATN (which is just a representation of the grammar at runtime) and render it. I think this tool already exists so that is a benefit.
- I suspect that processing for IDE support and syntax checking will be easier from the parse tree than from the AST, since we literally need to provide feedback tightly coupled to the text. For our other use cases, the AST is essential but for the language server, it will probably work at the parse tree level.
There are some tricky parts but I do think it is the right thing to move to ANTLRv4.
ANTLR v4 Documentation
ANTLR v4 Grammar Examples
ANTLR v4 Java Grammar
#11 Updated by Greg Shah over 3 years ago
- Related to Feature #3882: changes to allow the front-end to be used for 4GL syntax checking added
#12 Updated by Greg Shah over 3 years ago
- Related to Support #6409: generate "railroad style" syntax diagrams for the progress parser added
#13 Updated by Greg Shah over 1 year ago
We have these 9 ANTLR grammars which need to be migrated:
com/goldencode/expr/expression.g- standalone lexer and parser
- the grammar is not too complicated but there are some tricky integrated actions
com/goldencode/p2j/persist/orm/fql.g- standalone lexer and parser
- more complicated than hql.g
com/goldencode/p2j/persist/hql/hql.g- standalone lexer and parser
- the most basic of our grammars
com/goldencode/p2j/e4gl/e4gl.g- standalone lexer and parser
- the parser does inline transformation that has a complex state machine
- does not need AST processing!
com/goldencode/p2j/preproc/text.g- lexer and parser
- dependent upon braces.g vocab
- stream switching with ClearStream
- does not need AST processing!
com/goldencode/p2j/preproc/braces.g- lexer and parser
- vocab is shared with text.g
- stream switching with ClearStream
- does not need AST processing)!
com/goldencode/p2j/uast/progress.g- contains both ProgressLexer and ProgressParser
- uber-complex and the world depends on this
com/goldencode/p2j/uast/expression_evaluator.g- this is only a TreeParser
- it depends upon both ProgressLexer and ProgressParser and then walks the AST
- this will shift to a hand coded evaluator
com/goldencode/p2j/schema/schema.g- parser that depends on the ProgressLexer
#14 Updated by Eric Faulhaber over 1 year ago
I thought hql.g was deprecated and replaced by fql.g. Ovidiu, do you recall?
#15 Updated by Ovidiu Maxiniuc over 1 year ago
I do, but they are not the same.
The former is used by FQLPreprocessor for preprocessing the 'original' FQLs from converted code, while the latter is used by FqlToSqlConverter for parsing the intermediary FQLs and generate the final SQL statements. The grammar is pretty much the same, because the result of preprocessing is only doing some augmentations, but the difference is that the final FQL may contain additional nodes like JOINS && ORDER BY added by query processing.
#16 Updated by Eric Faulhaber over 1 year ago
Is fql.g then a superset of hql.g, or is using fql.g to parse from FQLPreprocessor likely to result in problems? It would be nice if we didn't have to upgrade/port hql.g to a newer ANTLR and maintain it.
Then again, if we've figured out the migration for fql.g and hql.g is largely the same, I guess it wouldn't represent a monumental effort. It just seems that fewer grammars going forward is better and easier to maintain, if the problem domain allows it.
#17 Updated by Ovidiu Maxiniuc over 1 year ago
I compared the two grammars. Indeed, fql.g is (almost) a superset of hql.g. In order to avoid breaking the preprocessor and unknowing how deep I will need to adjust the grammar I preferred to create a fork instead of forcing at that moment the re-usage. In the end, there are just a few places where the differences are not additive in favour of fql.g.
So, with a help of a flag or two, I think we can unify them easily enough.
#19 Updated by Greg Shah over 1 year ago
Here are some notes about potential lexer changes during the upgrade. As mentioned above, ANTLR v4 has a switchable lexer modes feature that allows "island grammars" to be supported (and more). An island grammar is one in which there are different lexing rules based on some context in the language, so you can't have a single set of lexing rules and need to switch back and forth based on some kind of sentinel values.
The Progress 4GL absolutely has this feature.
Areas that will likely benefit greatly from this:
- The entire preprocessor concept has been implemented as multiple separate lexers with our own glue to swap them. This can be reimplemented in a simpler way with a single lexer using modes.
- ProgressLexer has multiple of these:
OS-COMMANDand similar shell statements (seecommand_token_list)CONNECTstatement options (search onconnect_options)- Unquoted (non-string) filenames (see
filenamerule). RUNstatement- Filename processing (weird grammar before the parameter list; this is separate from the
filenameissue above). - Preprocessor arguments in a RUN statement (weird grammar after the parameter list).
- Filename processing (weird grammar before the parameter list; this is separate from the
- Any of the usage of
malformed_symbol(procedure names, function names, frame names...) can have a wide range of characters in a symbol even though these are completely undocumented and have no value. My guess: someone wrote some poor matching code in their compiler and now thye have to live with it forever. Normal symbols like variables or field names don't allow this variety. (We need to check to see if the 4GL lexes all symbols this way and then detects a problem only with some symbols or if this is truly a separate set of lexing rules for some symbols). - UI event names (search on
fixupKeyboardModifiers(),go_on_clause). Is this just another case that should usemalformed_symbol? - Label names (see
isProperLabel(),isMalformedLabel()andreassembleMalformedSymbol()and the embedded label case for editing blocks inset_or_update_or_prompt_for_stmt; check if this is an overlap withmalformed_symbol) - Field name quirk (putting whitespace in some parts of a qualified field reference). This one might need too much context from the parser to implement fully in the lexer. But we should consider the question: canwe match field and table names in the lexer?
- Initializer Constants (this is a kind of type coercion where strings can be used as initializers for other types and vice versa).
- Weird "dot prefixed" junk that is ignored (see
crap_to_ignorein parser). - Synonym support (e.g.
KW_FORMandKW_FORMAT)
In a related note: make sure we move as much of the whitespace processing into the lexer as possible. This will simplify the parser in a big way. Look for usage of followedByWhitespace().
Unrelated note: we need to check the pre/postfixing of sign operators in the lexer. This is inconsistent and needs to more closely match the OE approach. We have fixup code downstream and probably existing bugs to fix. Part of the problem is that we don't keep the integrity of these sign chars in the lexer.
Some jenky parts of the parser to try to fix:
- at-base fields
- multiple format phrases in one statement (is a little related to at-base fields)
- multiple frame phrases in one statement
- usage of
allowSymbolMatchandallowStringMatch
#20 Updated by Greg Shah over 1 year ago
- Related to Support #6860: lexer tests added
#21 Updated by Greg Shah over 1 year ago
- Related to Support #6859: preprocessor tests added
#22 Updated by Greg Shah over 1 year ago
- Related to Support #6861: tests for valid and invalid 4GL syntax (parsing) added
#23 Updated by Florin Eugen Rotaru about 1 year ago
- Related to Support #10231: Document the code style guidelines for ANTLR grammars, based on progress.g added
#24 Updated by Florin Eugen Rotaru about 1 year ago
- Related to Feature #10190: Prototype the changes to the build to add ANTLR v4 added
#25 Updated by Paula Păstrăguș 9 months ago
I had an in-depth discussion with Alex, and we agreed to start working on upgrading ANTLR 2 to ANTLR 4. For now, I’ll focus on exploring the differences between the two versions. Once I have a good understanding, I’ll begin migrating the schema.g grammar to make it compatible with ANTLR 4. We’ll need to implement an adapter, since our TRPL currently relies on the ANTLR v2-style AST. With this approach, no Java changes will be required in the existing logic, the adapter will simply take the ANTLR 4 parse tree and convert it into the annotated AST format expected by our current system.
We’ll also need to evaluate how this affects performance. While I would expect ANTLR 4 to be faster and more optimized, we’ll have to verify that through testing.
Alex, please let me know if I’ve misunderstood anything, or feel free to add any additional details or clarifications you think are important.
#26 Updated by Alexandru Lungu 9 months ago
the adapter will simply take the ANTLR 4 parse tree and convert it into the annotated AST format expected by our current system.
To clarify, this should be as automatic as possible. I wonder if we can deliver this without changing the grammar or adding a very specific "converter". I would imagine that a "magic converted" would do the trick, so we can reuse it for the other grammars.
I would also want to add the need to understand if the IDE part will only need the ParseTree from the parser.the adapter will simply take the ANTLR 4 parse tree and convert it into the annotated AST format expected by our current system.
- Ideally, the ParseTree will be used by IDE directly and any Java code or TRPL from FWD will use the adapted ASTs.
- If the IDE will require more information that we actually retrieve through ASTs (in TRPL or from Java), then this will be quite bad.
- I would want to avoid completely the need to duplicate logic we do for AST in Java/TRPL to ParseTree, just to expose that logic to the IDE.
- If this is the case, we should consider porting a small part of logic to the ParseTree level to be shared to IDE and propagated to AST for Java/TRPL.
- Examples:
- parser context (line/column). The logic in ANTLR2 and ANTLR4 for line/column is different - we need a unified way of detecting that (most probably from ParseTree and propagate that info to ANTLR2 AST)
- peerid: what if we want to map the 4GL token to Java token in the IDE. We will need the peer mapping to be available to the IDE. I suppose we can always store a mapping between the ParseTree used by IDE to AST used by FWD. ***
#27 Updated by Ovidiu Maxiniuc 9 months ago
Paula Păstrăguș wrote:
We’ll also need to evaluate how this affects performance. While I would expect ANTLR 4 to be faster and more optimized, we’ll have to verify that through testing.
The performance is important since this will also be needed at runtime, for dynamic queries, but also other intermediary internal conversions and (pre)processing.
#28 Updated by Paula Păstrăguș 9 months ago
- File antlrv2-v4.png added
Alex, I used the expression 2 + 3 * 4 to generate a simple AST and a ParseTree using ANTLR v2 and ANTLR v4:
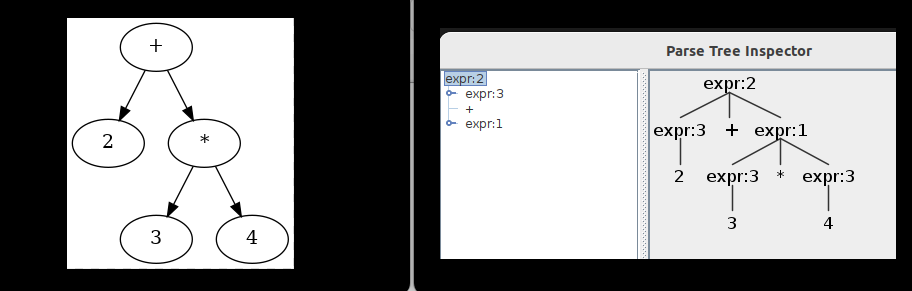
If we compare the two images, we can see that the tree generated by ANTLR v4 is deeper (depth 4) and more detailed than the one from ANTLR v2 (depth 3). From the image on the left, it looks more like a skeleton representation, a simpler AST, while the one on the right feels richer and more informative.
Just one question, isn’t the grammar also responsible for adding annotations in ANTLR v2? I think I’ve found the answer:) ,for the image on the left, I used a CommonAST, but in FWD we actually have our own implementation, the Aast, which should be used instead, right?
#29 Updated by Greg Shah 9 months ago
I had an in-depth discussion with Alex,
I appreciate this, but please note that I am leading this effort directly. I wrote 95% of our preprocessing/lexing/parsing code. I can help us avoid wrong turns. I'm also worried that if we try to move ahead without a plan that address the overall vision we are trying to achieve, then we will duplicate a lot of work as we redo work over time.
and we agreed to start working on upgrading
ANTLR 2toANTLR 4.
We're not ready to work on this part yet. We have to answer some questions about approach AND we need to build some supporting code. Then we will work on the grammars.
For now, I’ll focus on exploring the differences between the two versions. Once I have a good understanding,
Please carefully read my notes from #1757-10. I've already summarized the differences between versions there.
We’ll need to implement an adapter, since our TRPL currently relies on the ANTLR v2-style AST. With this approach, no Java changes will be required in the existing logic, the adapter will simply take the ANTLR 4
parse treeand convert it into theannotated ASTformat expected by our current system.
We won't go this route. The AnnotatedAst extends the ANTLR 2 CommonAST class and I do not want any dependencies on the ANTLR 2 classes. Those class are not a good long term fit for us. Relying upon them would avoid downstream changes but would yield a poor overall result.
#30 Updated by Greg Shah 9 months ago
Let me provide some additional context about our work here.
1. Our requirements will likely be set by the 4GL processing. 6 of the 9 grammars are directly related to 4GL oer E4GL preprocessing/lexing/parsing. Some query processing (hql and fql) and schema parsing is separate but we won't take a different approach just for those.
2. Any grammar will be common code for all of our different use cases. In other words, we aren't going to have duplicated grammars. We have a wide range of usage that is far more extensive than you would expect for most parsers. This means we will often do things that may not be common but which are needed for us.
Broadly speaking, our usage falls into multiple categories.
- Conversion
- Full and Incremental Modes
- 4GL Code
- External Procedures (
.w,.p...) - Classes/Interfaces/Enums (
.cls) - WebSpeed (a.k.a. Embedded 4GL or SpeedScript,
.htmor.html)
- External Procedures (
- Database Schemata (
.df) - Preprocessor Directives and Include Files (
.i...)- All of the above 4GL code and schemata cases can have preprocessing (yes, even the schemata!).
- ProxyGen (
.xprgand various artifacts)
- Analytics
- Predefined Reports
- Custom Search (via Report Server web UI)
- Custom Reports (via Report Server web UI)
- Detailed Source Code and AST views
- Callgraph
- Full and Incremental Callgraph Generation
- Reports
- Visualization (via Report Server web UI)
- Runtime
- Dynamic Queries (e.g.
QUERY-PREPARE()) - Dynamic Temp-Tables (e.g.
CREATE TEMP-TABLE) - Just-In-Time Code Conversion (e.g.
RUN some-not-yet-converted-code.p; this isn't implemented yet but will be in the future)
- Dynamic Queries (e.g.
- IDE
- MVP which is mostly defined by the existing "core" OEPDS features. See #9703 and OpenEdge IDE Features. We will ignore most of the "wizard" features and will also not provide visual builders initially. We must provide core features (e.g. navigation, view, edit, convert/compile, run, unit test and debug).
- Multiple IDEs using common code in LSP and DAP servers.
- Our approach will have a kind of dual-perspectives.
- 4GL Code Views
- Fully Preprocessed (the equivalent of our
.cachetoday) - Direct Source
- programs like procedures or classes
- include files
- all of these are displayed in non-preprocessed mode (directly as they would appear in the filesystem)
- Fully Preprocessed (the equivalent of our
- Java Code View
- Converted Code (read-only)
- Other Java Code (editable)
- Hand Written Java
- Converted Code that has been removed from the conversion list
- The various 4GL views and the converted Java code will be cross-linked so that it is easy for 4GL devs to understand the Java code and for Java devs to understand the 4GL code.
- 4GL Code Views
- Other Features (post-MVP)
- Advanced Features (many of which don't exist in OEPDS)
- exposing properties (even implicit ones) for blocks and transactions
- resource scoping (frames, buffers...)
- index selection
- project-wide linking from resource definitions to references (e.g. field or table usage)
- The idea here is that we will make this support a far better development environment that exists with any environment today.
- #10700 expose analytics features in our IDE support
- #3703 implement TRPL based linting support
- #10726 calculate and report code quality metrics
- #10701 implement support for generative AI code assist
- Advanced Features (many of which don't exist in OEPDS)
3. The 4GL language has more syntax than any modern language. Actually, I don't know of any language that has as much unique syntax or as many keywords. In addition to this terrible design decision, they added more features which create unprecedent levels of ambiguity and irregularity. On top of all of these serious problems, the code is preprocessed (and every project we've ever seen uses preprocessing heavily). This adds extra problems, especially for IDE support.
My point with the above is that we are dealing with problems and complexity far beyond most projects. Using common strategies for modern languages will not necessarily fit our needs.
#31 Updated by Greg Shah 9 months ago
Alexandru Lungu wrote:
the adapter will simply take the ANTLR 4 parse tree and convert it into the annotated AST format expected by our current system.
To clarify, this should be as automatic as possible. I wonder if we can deliver this without changing the grammar or adding a very specific "converter". I would imagine that a "magic converted" would do the trick, so we can reuse it for the other grammars.
This is not a practical idea. First, we aren't keeping ANTLR 2 around so our existing code will need to change. More importantly, there is a great deal of tree building logic in our ANTLR 2 grammars. Some of this is implicit based on how we structured the rules. Some of it is explicit tree building in the grammar. Some of it is explicit tree building in helper code like the SymbolResolver. All of this is very specific to the particular syntax being processed. There is no "general rule" that can be applied to automatically build the tree. Instead we have often spent a lot of time thinking about how the tree should look. In other cases, we haven't pent that time but the current code does depend on the exiting behavior.
We must plan for an approach where we can implement this same logic in a clean way. In a perfect world we would actually be able to drive this from matching logic itself. If we have to split it off, it will make the overall code much more difficult to write and support.
I would also want to add the need to understand if the IDE part will only need the ParseTree from the parser.
- Ideally, the ParseTree will be used by IDE directly and any Java code or TRPL from FWD will use the adapted ASTs.
- If the IDE will require more information that we actually retrieve through ASTs (in TRPL or from Java), then this will be quite bad.
I don't think we can use the parse tree for this. We will indeed need quite a lot of the knowledge that we store in the AST to render things properly. At least the advanced features will need this.
I will also say the the heavily typed programming interfaces for parse trees in ANTLR 4 is poor, we should stay away from using that. I'm not a fan of the idea of basing everything on the parse trees.
#32 Updated by Greg Shah 9 months ago
If we compare the two images, we can see that the tree generated by ANTLR v4 is deeper (depth 4) and more detailed than the one from ANTLR v2 (depth 3). From the image on the left,
ANTLR 4 is not creating an AST at all. It is creating a "parse tree", which is NOT EQUIVALENT to an AST. Please note that the parse tree is just lexer tokens structured in a tree form with no cleanup (see below). In our normal AST we store a lot of extra information (as annotations) which won't exist in the parse tree.
it looks more like a skeleton representation, a simpler AST, while the one on the right feels richer and more informative.
The point of an AST is to have a cleaner representation of the semantics (i.e. meaning) of the code. We remove the syntactic sugar, resolve ambiguity/irregularity and leave behind a cleaner tree that can be used for many different purposes.
#33 Updated by Greg Shah 9 months ago
- Related to Feature #10804: create replacement AST implementation for use with ANTLR 4 added
#34 Updated by Greg Shah 9 months ago
We will continue to discuss and consider this issue of how we handle the IDE (from the parse tree or the AST...) but it will likely be decided during our work on the LSP, not now. For now we already know that we need to implement a way to encode the AST creation, so we should focus on that.
#35 Updated by Paula Păstrăguș 3 months ago
I will continue the discussion here. For context, previous relevant notes include #10804-218, #10804-220, #10804-221.
#36 Updated by Greg Shah 3 months ago
We have a big decision to make.
It is not clear to me that ANTLR4 is the best choice. It has been optimized to make writing parsers faster instead of writing faster parsers. That is a poor design choice, in my opinion. You spend the time once to write a parser. But it is run millions or billions of times. Why would you want all of those times to be slower just so that you could save a little time up front?
But the ATN and improved error handling are both things that make ANTLR4 much better designed for IDE support than ANTLR2.
Give me some time to think on this.
#37 Updated by Paula Păstrăguș 3 months ago
Sure, I'm currently measuring the parsing time of standard.df using ANTLR4 and comparing it with the old ANTLR2 implementation. Since schema.g4 is less complex than progress.g4, I expect similar or faster performance.
#38 Updated by Paula Păstrăguș 3 months ago
Also, there is an optimized fork of ANTLR4 available here: https://github.com/tunnelvisionlabs/antlr4/blob/master/doc/optimized-fork.md
It's not the official reference implementation and comes with added complexity, limited documentation, and extra configuration requirements, as noted in the repository. Still, it might be worth exploring to see if it could help us.
#39 Updated by Paula Păstrăguș 3 months ago
Paula Păstrăguș wrote:
Sure, I'm currently measuring the parsing time of
standard.dfusing ANTLR4 and comparing it with the old ANTLR2 implementation. Since schema.g4 is less complex than progress.g4, I expect similar or faster performance.
ANTLR4 parsed the standard.df file in 1235103542 ns, which is about 1.23 seconds, while ANTLR2 completed the same parse in 372159450 ns, or about 0.37 seconds. Based on this result, ANTLR4 is roughly 3 to 4 times slower..
#40 Updated by Greg Shah 3 months ago
I'm not surprised. Consider how truly awful that result is. The content we are parsing in the .df is trivial. There is nothing ambiguous or difficult about the grammar. There is nothing deeply nested. If this performs badly, then full 4GL programs will be horrific.
#41 Updated by Greg Shah 3 months ago
Paula Păstrăguș wrote:
Also, there is an optimized fork of ANTLR4 available here: https://github.com/tunnelvisionlabs/antlr4/blob/master/doc/optimized-fork.md
It's not the official reference implementation and comes with added complexity, limited documentation, and extra configuration requirements, as noted in the repository. Still, it might be worth exploring to see if it could help us.
Unfortunately, I don't see much there that would solve our problem.
#42 Updated by Greg Shah 3 months ago
ANTLR3 supports LL(k). But it is old and not supported and doesn't have ATN support.
There is this interesting article on implementing code completion in an ANTLR3 parser (Universal Code Completion using ANTLR3). I am NOT suggesting we go down this route, but it is useful to know about.
#43 Updated by Alexandru Lungu 3 months ago
ANTLR4 parsed the standard.df file in 1235103542 ns, which is about 1.23 seconds, while ANTLR2 completed the same parse in 372159450 ns, or about 0.37 seconds. Based on this result, ANTLR4 is roughly 3 to 4 times slower..
Does some profiling help here? Maybe there is an obvious bottleneck that can be easily fixed.
#44 Updated by Paula Păstrăguș 3 months ago
Yes, it helped a bit.
I enabled ANTLR4 profiling to see how much time is spent in each parser decision:
A few important numbers stand out:- [java] Total decision time (ns) = 63454905, aprox 0.06 sec
- [java] Total parse time (ns): 1011482463, aprox 1.0 sec
At first I suspected the parser decisions themselves might be the main bottleneck, but these numbers suggest otherwise. The total time spent in ANTLR4 prediction is only a small fraction of the full parse time. This makes me think the missing time is likely spent outside the prediction engine, for example in token consumption or especially in embedded Java actions and AST-building work. The next step is probably to measure or temporarily reduce the actions and AST-related work, to see how much of the remaining time comes from parser-side custom logic rather than ANTLR prediction itself.
#45 Updated by Paula Păstrăguș 3 months ago
I'm also reminded of Sam's advice from some forum: "Do not assume the lexer is fast." It might be worth profiling the lexer as well.
#46 Updated by Paula Păstrăguș 3 months ago
As for the SLL lookahead, I wouldn't worry about the larger numbers, they represent the total lookahead across all invocations. If you divide by the number of invocations, the actual lookahead per call is quite small (around 3 at most).
#47 Updated by Paula Păstrăguș 3 months ago
Tokens generation time: 873586 ns = 0.000873586 seconds. The lexer is clearly not the issue.
#49 Updated by Alexandru Lungu 3 months ago
Paula, do you profile the actual read from disk? I am aware that ANTLR has a token stream that can be set-up from disk. I am not sure about its buffering. The point is: avoid skewing results with the actual I/O done on disk to read the df file.
#50 Updated by Paula Păstrăguș 3 months ago
Paula Păstrăguș wrote:
Tokens generation time:
873586ns = 0.000873586 seconds. The lexer is clearly not the issue.
Wait! That is not the total time for standard.df token generation, this is the actual one: 648738251 = 0.6 seconds!
#52 Updated by Paula Păstrăguș 3 months ago
I only measured tokens.fill(), which generates all the tokens.
#53 Updated by Paula Păstrăguș 3 months ago
long start = System.nanoTime();
Token t;
do {
t = lexer.nextToken();
} while (t.getType() != Token.EOF_TYPE);
long end = System.nanoTime();
System.out.println("Lexer time: " + (end - start));
These measurements were done with ANTLR2. It takes only about 0.09 seconds to generate all tokens for the standard.df file, so I think the lexer is the main contributor to the poor performance. Please correct me if I'm wrong.
#54 Updated by Paula Păstrăguș 3 months ago
Paula Păstrăguș wrote:
Paula Păstrăguș wrote:
Tokens generation time:
873586ns = 0.000873586 seconds. The lexer is clearly not the issue.Wait! That is not the total time for standard.df token generation, this is the actual one:
648738251= 0.6 seconds!
The small value was in fact for fwd.df, not standard.df. I had misread the logs:)
#55 Updated by Paula Păstrăguș 3 months ago
For further profiling I'll use YourKit profiler.
#56 Updated by Greg Shah 22 days ago
A wiki page with guidance on how we migrate from ANTLR2 to ANTLR4 is in ANTLR Migration Guide.