Support #6709
track nested FIND inside a related FOR loop
80%
report-nested-find.png (581 KB)
6709-rpt.diff  (9.08 KB)
(9.08 KB)
6709-rpt-20221125.diff
(9.64 KB)
6709-rpt-20221205.diff
(10.9 KB)
6709-rpt-20221208.diff
(11.1 KB)
6709-20221216.patch
(10.5 KB)
6709-20221222.diff
(11 KB)
6709-20230106.patch
(18.7 KB)
chui-nestedfind-report.png (81.4 KB)
Related issues
History
#1 Updated by Greg Shah almost 4 years ago
We have the perception that we have a problem with nested FINDs that reference a buffer or buffers controlled by a containing FOR loop. We should track how often this happens and if it is really as prevalent as we think, then we should measure the alternative joined approach to see what we could expect from such an optimization. This may be a first step in deciding the importance of #3194.
#3 Updated by Alexandru Lungu over 3 years ago
- Assignee set to Dănuț Filimon
#4 Updated by Dănuț Filimon over 3 years ago
From what I understood, we want to test if either nested find or joined approach is better. After a few tests using two temporary tables, tt1 and tt2 with the same structure, I found out the following cases:
- If the record in tt2 is not found, the code inside the for loop will not be executed. An error is thrown for failing to find a record.
FOR EACH tt1. FIND FIRST tt2 WHERE tt2.field-tt21 = tt1.field-tt11. tt1.field-tt11 = RANDOM(1, 10) MODULO 10. END. - If the record in tt2 is not found, the code inside the for loop is still executed because
NO-ERRORis used.FOR EACH tt1. FIND FIRST tt2 WHERE tt2.field-tt21 = tt1.field-tt11 NO-ERROR. tt1.field-tt11 = RANDOM(1, 10) MODULO 10. END. - The code is executed only if a record is found.
FOR EACH tt1, FIRST tt2 WHERE tt2.field-tt21 = tt1.field-tt11. tt1.field-tt11 = RANDOM(1, 10) MODULO 10. END.
There is a big difference between using nested finds and join. Case 3 is similar to case 1, but there are instances where the user wants to run code when a record doesn't exist (case 2). I want to know if I addressed the problem correctly and if I should continue to research the issue. I don't think that it will take much long if what I found until now proves helpful.
#5 Updated by Dănuț Filimon over 3 years ago
- Status changed from New to WIP
#6 Updated by Greg Shah over 3 years ago
This is a good analysis. It certainly highlights the differences in control flow and danger of refactoring such code.
However, the core questions for this task are:
- We are trying to evaluate how often in real 4GL code does this condition occur? Getting a measurement of this for different applications will help us evaluate the importance of optimizations in this area. As your findings above prove, such optimizations would have to be done carefully. Without some measurement of how often this occurs, we are just speculating that this "nested related FIND in a FOR" is a common problem.
- If this is as common as we think, then we would like to know if refactoring of the nested FIND as a multi-table FOR could be used to consistently improve performance.
#7 Updated by Dănuț Filimon over 3 years ago
- File report-nested-find.png added
Greg Shah wrote:
We are trying to evaluate how often in real 4GL code does this condition occur? Getting a measurement of this for different applications will help us evaluate the importance of optimizations in this area. As your findings above prove, such optimizations would have to be done carefully. Without some measurement of how often this occurs, we are just speculating that this "nested related FIND in a FOR" is a common problem.
Thank you for your explanation.
I created a new report for tracking nested FIND occurrences. After running the ant rpt command, we can check how many times this type of operation appeared in the report interface. I decided to track both nested FIND FIRST and FIND LAST and display them as categories, it will also show the percentage for each one which is very useful. Here is a screenshot of a simple 4GL program with 2 nested FIND LAST and 1 nested FIND FIRST.
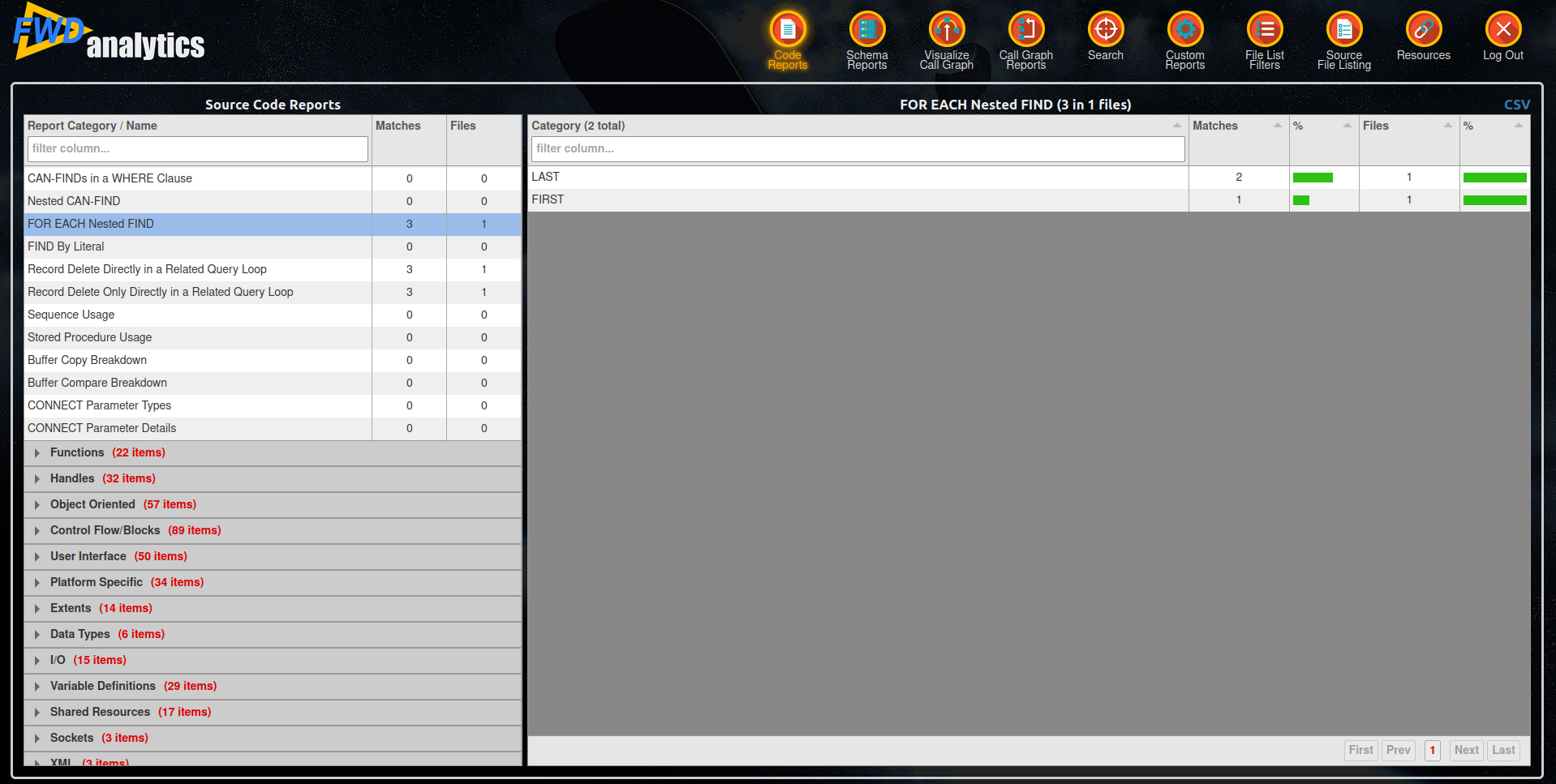
#8 Updated by Greg Shah over 3 years ago
Nice! Please post the diff so I can review the approach. It can be tricky to do this kind of static analysis because:
- The nesting can happen at an arbitrarily deep block level but the relationship may still be there.
- The nesting can be inside of called procedures, functions, methods.
- The linking might be done through a passed buffer parameter instead of a more direct linkage.
One other note: I think we also need to match the "FIND unique match" case. This is where the FIND has no FIRST/LAST/NEXT/PREV@/CURRENT qualifier keyword. Instead, it is a match to a unique record based on a literal or the WHERE clause.
Due to the complexities noted above, we would need to do this analysis in some prior step and cannot easily calculate this in a single expression or function. I was thinking that for this purpose it might be easier to implement some runtime tracking that could detect this no matter how the linkage occurs. We discuss this more in #3194. Please read that task and post questions as needed. This #6709 task is meant to implement the tracking/measurement of the #3194 problem so that we can determine if we should work on a solution.
#9 Updated by Dănuț Filimon over 3 years ago
- File 6709-rpt.diff added
I took a different approach after taking a look at #3194 and modified how the report is made. I created a new rule set which adds a new annotation at conversion time using walk and ascending rules. In the walk rules, I keep track of FOR EACH occurrences using a stack. In the ascending rules, the annotation is added when a FIND FIRST/LAST/NEXT/PREV/CURRENT/unique match is found and the stack element is removed only when meeting another FOR EACH.
- nested find in a deep block level
- multiple nested finds in the same FOR EACH
- finds that are not nested
Greg Shah wrote:
- The nesting can be inside of called procedures, functions, methods.
The current approach won't work at conversion time, but it should be possible at runtime.
I attached the diff. Please review.
#10 Updated by Greg Shah over 3 years ago
Code Review 6709-rpt.diff
Neither annotations/annotations.xml and annotations/annotations_prep.xml can't be used for the nested_find.rules because it is not executed when we run analytics/reporting. You would need to use annotations/early_annotations.xml for anything that needs to be used in reporting.
There is a flaw in the nested_find.rules logic. The only time where there is a nested find is when the FIND is referencing the same exact buffer as the containing FOR. Otherwise, these are unrelated queries and should not be linked.
The current approach won't work at conversion time, but it should be possible at runtime.
Agreed. Since the analytics approach won't be able to detect the wider range of cases, I think the report is not needed. I think it is best to focus on the runtime approach.
#11 Updated by Dănuț Filimon over 3 years ago
Greg Shah wrote:
Neither annotations/annotations.xml and annotations/annotations_prep.xml can't be used for the nested_find.rules because it is not executed when we run analytics/reporting. You would need to use annotations/early_annotations.xml for anything that needs to be used in reporting.
Got it.
There is a flaw in the nested_find.rules logic. The only time where there is a nested find is when the FIND is referencing the same exact buffer as the containing FOR. Otherwise, these are unrelated queries and should not be linked.
This is my intent, but I wanted to share my work until now. Also, I guess you mean referencing the same buffer in the where clause. FOR EACH tt: FIND FIRST tt. END. doesn't work in 4GL.
Agreed. Since the analytics approach won't be able to detect the wider range of cases, I think the report is not needed. I think it is best to focus on the runtime approach.
You are right. However, the static analysis can provide all find queries inside for each (excluding the ones called inside procedures or dynamic queries). Runtime analysis can cover more cases, but only for the executed scenario. The report can deliver a lower bound which may be higher than the runtime result.
I want to finish the current report ASAP and start working on implementing the runtime tracker.
#12 Updated by Greg Shah over 3 years ago
This is my intent, but I wanted to share my work until now.
Understood. No worries.
Also, I guess you mean referencing the same buffer in the where clause.
Yes, exactly. This is a kind of implicit join which could be refactored into something more performant.
I want to finish the current report ASAP and start working on implementing the runtime tracker.
OK
#13 Updated by Dănuț Filimon over 3 years ago
- File 6709-rpt-20221125.diff added
I made the changes for the report. Now, it can track FIND statements that reference the same buffer as the FOR EACH in the WHERE clause. I am now going to start implementing the runtime solution.
#14 Updated by Greg Shah over 3 years ago
OK, this is close to correct.
1. Please switch out the use of a Stack for the ScopedSymbolDictionary. The idea is similar but the ScopedSymbolDictionary will search up the scopes to find a match. This is important because the match might not be with the nearest enclosing FOR EACH.
2. The following code is matching at the wrong node:
<rule>type == prog.KW_FOR and
this.descendant(1, prog.KW_EACH) and
this.nextSibling.type == prog.BLOCK
<action>recordAst = this.getImmediateChild(prog.RECORD_PHRASE, null)</action>
...
The problem here is that it will only match one RECORD_PHRASE while there may actually be many. Also, the check on BLOCK is not needed. The better way to do this is to match on a condition like this:
<rule>relativePath("STATEMENT/KW_FOR/KW_EACH/RECORD_PHRASE")
...
Inside that rule (i.e. when that match is true), this and copy will have token type RECORD_PHRASE.
#15 Updated by Dănuț Filimon over 3 years ago
- File 6709-rpt-20221205.diff added
Greg Shah wrote:
1. Please switch out the use of a
Stackfor theScopedSymbolDictionary.
I made the FOR EACH AST the scope and the schemaname of each TEMP-TABLE or BUFFER as symbol.
2. The problem here is that it will only match one RECORD_PHRASE while there may actually be many. Also, the check on BLOCK is not needed.
I did the changes to match KW_FOR/RECORD_PHRASE, KW_EACH and RECORD_PHRASE are siblings.
- Included
RECORD_PHRASE/BUFFERwhen adding a symbol to the current scope. - Swapped the usage of the
bufnameannotation withschemanamebecause I could extract the temp-table name from in the case ofBUFFER.
Please review the attached diff.
#16 Updated by Greg Shah over 3 years ago
Code Review 6709-rpt-20221205.diff
Good, it is getting closer.
1. I don't think we should limit the for each processing to only match temp-tables and buffers. All record phrase targets (tables, temp-tables, buffers, work-tables) are valid.
2. We can't use schemaname because different buffers can share the same schemaname but cannot share the same bufname. If the reference is not to the same buffer then it isn't an implicit join so it isn't a nested case.
3. The the FIND statement WHERE clause processing, you can easily limit the processing to field references using evalLib("fields") or (more explicitly) evalLib("fieldtype", this.type). This is a cleaner approach than searching for a node that has a schemaname that includes a ..
#17 Updated by Dănuț Filimon over 3 years ago
- File 6709-rpt-20221208.diff added
Greg Shah wrote:
1. I don't think we should limit the for each processing to only match temp-tables and buffers. All record phrase targets (tables, temp-tables, buffers, work-tables) are valid.
I made the changes to include tables and work-tables.
2. We can't use
schemanamebecause different buffers can share the sameschemanamebut cannot share the samebufname. If the reference is not to the same buffer then it isn't an implicit join so it isn't a nested case.
3. The theFINDstatementWHEREclause processing, you can easily limit the processing to field references usingevalLib("fields")or (more explicitly)evalLib("fieldtype", this.type). This is a cleaner approach than searching for a node that has aschemanamethat includes a..
Since schemaname should not be used, I returned to bufname and instead of checking if the annotation is present, I used evalLib("fields") to make sure that a field is evaluated.
I attached the diff with the mentioned changes.
#18 Updated by Dănuț Filimon over 3 years ago
AdaptiveQuery query4 = new AdaptiveQuery();
forEach("loopLabel13", new Block((Init) () ->
{
query4.initialize(wtcustomer, ((String) null), null, "wtcustomer.recid asc");
},
(Body) () ->
{
query4.next();
new FindQuery(tt1, "tt1.fieldTt11 < ?", null, "tt1.fieldTt11 asc", new Object[]
{
(P2JQuery.Parameter) () -> wtcustomer.getCustnum() // can't retrieve buffer from lambda
}).next();
}));
This is how a FindQuery is generated as a nested find. The problem is that I can't retrieve the buffer from the where clause. A solution for this would be to change the lambda to FieldReference.
#19 Updated by Greg Shah over 3 years ago
I think FieldReference is less clean looking and it will be slower. In #4928, we do have some ideas to improve it using lambdas but it won't ever be as clean as the current approach. We could implement this as an optional conversion which could then be used by the runtime for detection of nesting. If that was only done for this kind of testing, then it might be OK.
Eric: What other ramifications are there which we need to consider?
#20 Updated by Greg Shah over 3 years ago
1. I don't think we should limit the for each processing to only match temp-tables and buffers. All record phrase targets (tables, temp-tables, buffers, work-tables) are valid.
I made the changes to include tables and work-tables.
Instead of this:
<action>recordAst = null</action>
<rule>this.getImmediateChild(prog.TEMP_TABLE, null) != null
<action>recordAst = this.getImmediateChild(prog.TEMP_TABLE, null)</action>
</rule>
<rule>this.getImmediateChild(prog.BUFFER, null) != null
<action>recordAst = this.getImmediateChild(prog.BUFFER, null)</action>
</rule>
<rule>this.getImmediateChild(prog.TABLE, null) != null
<action>recordAst = this.getImmediateChild(prog.TABLE, null)</action>
</rule>
<rule>this.getImmediateChild(prog.WORK_TABLE, null) != null
<action>recordAst = this.getImmediateChild(prog.WORK_TABLE, null)</action>
</rule>
You can just do this:
<action>recordAst = this.getChildAt(0)</action>
There are only those 4 possible cases and they are always the first child of the RECORD_PHRASE.
Otherwise the proposed changes look good. If they pass testing, then you can commit them in 3821c.
#21 Updated by Dănuț Filimon over 3 years ago
Greg Shah wrote:
You can just do this:
<action>recordAst = this.getChildAt(0)</action>
Did so.
If they pass testing, then you can commit them in 3821c.
I created a report before the modification above was introduced. The report was generated successfully, but no nested finds were found in the project. I plan to introduce a few non-related nested finds in the project and generate another report soon.
Committed 3821c/rev.14436. Added FOR EACH nested FIND report.
#22 Updated by Greg Shah over 3 years ago
I've uncommitted 3821c rev 14436. It causes the following regression in conversion for a large customer application. See #6851-153.
Danut, please address the bug and make sure to test conversion with that application.
#23 Updated by Dănuț Filimon over 3 years ago
Looks like the problem was caused by a FOR FIRST table statement. Fixed by checking if the previous sibling of the RECORD_PHRASE is KW_EACH when getting the recordAst and saving a symbol. I took the individual statement from the file mentioned in #6851-153 and converted a similar example separately with no problems. I am currently testing conversion of the specified application and will make an update when it's done.
#24 Updated by Dănuț Filimon over 3 years ago
Greg Shah wrote:
Danut, please address the bug and make sure to test conversion with that application.
The bug is fixed and the conversion was successful. Should I commit the changes?
I am currently trying to convert
(P2JQuery.Parameter) () -> wtcustomer.getCustnum()into
new FieldReference(wtcustomer, "custnum")
I managed to find where the cast to P2JQ.Parameter is made, but it wasn't the solution that I needed. I was left with
wtcustomer.getCustnum(). My question is where in the rules is the CustNum getter added? I want to keep wtcustomer and custnum separatelly so i can create a FieldReference.#25 Updated by Greg Shah over 3 years ago
The bug is fixed and the conversion was successful. Should I commit the changes?
Please post an updated patch for review.
My question is where in the rules is the CustNum getter added? I want to keep wtcustomer and custnum separatelly so i can create a FieldReference.
We emit the getter or the FieldReference in convert/database_references.rules. I think the most likely scenario here is to use the accessor flag to force FieldReference to be used. Make sure to do this based on a flag that by default is off. In other words, we only want to turn this on when an explicit flag is set.
#26 Updated by Dănuț Filimon over 3 years ago
- File 6709-20221216.patch added
Greg Shah wrote:
Please post an updated patch for review.
We emit the getter or the
FieldReferenceinconvert/database_references.rules. I think the most likely scenario here is to use theaccessorflag to forceFieldReferenceto be used. Make sure to do this based on a flag that by default is off. In other words, we only want to turn this on when an explicit flag is set.
This is what I was looking for. Thank you.
#27 Updated by Greg Shah over 3 years ago
I'm OK with the 6709-20221216.patch.
You've tested conversion for both the large customer application and also Hotel GUI?
#28 Updated by Dănuț Filimon over 3 years ago
Greg Shah wrote:
You've tested conversion for both the large customer application and also Hotel GUI?
Yes, both applications converted successfully.
Can I commit the changes to 3821c?
#29 Updated by Greg Shah over 3 years ago
Yes.
#30 Updated by Dănuț Filimon over 3 years ago
Committed 3821c/rev.14460. Added nested find annotation and report. Any annotated FIND that is nested in a FOR EACH will be displayed under FOR EACH Nested FIND when generating a report and classified based on the keyword used.
#31 Updated by Dănuț Filimon over 3 years ago
- File 6709-20221222.diff added
I managed to convert Hotel GUI and a few smaller tests and use FieldReference. I actually didn't make use of convert/database_references.rules because the accessor annotation would make the query components also use FieldReference and additional changes proved really difficult.
I found out that the related_buffer annotation seems to influence the usage of FieldReference. As suggested in #6709-25, I added a flag called enable_find_field_reference in the directory.hints file and made changes in annotations/index_selection.rules to use the hint to set the related_buffer annotation to true in all FindQueries.
I've tested conversion on a customer application overnight at least 2 times and fixed small mistakes. I also managed to test runtime tracking of nested finds. My approach was to use the offEndQueries value from the TransactionManager, but the set is actually cleared after the block.init() is executed, while I need it in the body which contains the FindQuery. I created a list in BlockDefinition to store the values of offEndQueries in the top block of the WorkArea and make use of them when checking if the record buffer of the FindQuery matches any of the record buffers of the components. The list is then cleared when the scope is closed.
When I wrote the implementation for the runtime tracking of nested finds, I looked over 3194a/rev.11127 and borrowed a similar idea, but it's a bit more general since the idea was to only track nested finds. I attached a diff with the latest changes, please take a look at it and tell me if any improvements can be made.
#32 Updated by Alexandru Lungu over 3 years ago
I will try to patch a customer application I have on my development environment to test the changes. If everything is right, I will do some preliminary tracking on that application.
#33 Updated by Greg Shah over 3 years ago
Code Review 6709-20221222.diff
The conversion changes seem reasonable.
Do we really need to implement this as part of the query-off-end processing? All of this behavior is deeply specific to the persistence layer. It seems like the BufferManager or something else in persistence should easily be able to provide a list of the active FOR EACH queries. Extending the TransactionManager with even more query-specific logic is not good. At a minimum, we would only want this runtime processing when a flag is set in the directory. If it is not active, then there should be no processing and no impact of the tracking.
Although we do have some off-end processing inside the generic transaction/block processing, I really want to remove it. If this "get the list of all for each queries" processing really needs to be tracked during the block processing, I would hope we already expose the block/transaction notifications that are needed.
The matching logic in the FindQuery seems expensive. It seems like the inverse of what we need. We already have access to the buffer being referenced. Can't we just ask the buffer if it is associated with a FOR EACH query? Looping through all FOR EACH queries to see if this buffer is in the list is a lot of unnecessary work that some simple state in the buffer could answer. If we need more state in the buffer to store this, that seems a better way.
#34 Updated by Greg Shah over 3 years ago
- Related to Support #7004: eliminate the off-end processing in the TransactionManager and minimize the processing of off-end added
#35 Updated by Greg Shah over 3 years ago
Eric: Please review and advise.
#36 Updated by Dănuț Filimon over 3 years ago
- File 6709-20230106.patch added
I've changed the way tracking is done based on #6709-33. The only change I've done to TransactionManager is to retrieve offEndQueries and save the value in a Map from BufferManager until the for each body closes. I also included a flag in directory.xml, called enable_find_field_reference, which by default is false and is used to toggle the runtime tracking of nested finds. I also created a MBean that can be used to track the counter of FindQueries that were initialized. I tested Hotel GUI and a customer application (~30 minutes) and the MBean didn't increase, I made sure it worked using a small test.
Please review the attached patch.
#37 Updated by Constantin Asofiei about 1 year ago
This needs to be brought back into focus. What we need is a mode (when activated) which will track FIND queries, at runtime. This mode can be activated when running automated tests for an application, and produce the report.
For the case of FIND nested in loop blocks (not necessarilyFOR EACH, and on any level on the stack), we need a report which will generate info about:
- outer loop block(s) (how many levels do we track?). Here we need the external program/.cls, plus the internal entry (procedure, method, etc), with the line number in the .java. Do we need info about the type of the loop?
- the info about the FIND being executed: database, buffer name, table name, external program/.cls, internal entry
- the tracking will be done on the location of the FIND statement in the .java, and not the external program/.cls instance executing it
Do we set a threshold over which we report the number of FIND executions? I don't think this is needed, if the report (.csv?) is well structured, then excel will allow you to analyze it in any way.
We need also to consider if this needs to be expanded to any type of nested queries.
#38 Updated by Alexandru Lungu about 1 year ago
There are some bugs in the report so that more nested FINDs are logged than needed. I think the flag is set incorrectly to some of them.
Some pseudo-code:
function fnc_name returns character
(input some_param as integer) :
define buffer pt for pt.
find first pt
where pt.f1 = some_param
and pt.f2 = 'd':U
no-lock no-error.
if available pt then
return pt.f3.
return ?.
end function.
function fnc_name returns character
(input p1 as character,
input p2 as character,
input p3 as character):
define variable var1 as character no-undo.
define buffer pt for pt.
find first pt
where pt.f1 = p1
and pt.f2 = p2
and pt.f3 = p3
no-lock
no-error.
if available pt then
run ext_proc in target-procedure( input rowid(pt), output var1).
return var1.
end function.
function fnc_name returns character
(input p1 as character,
input p2 as character,
input p3 as character):
define variable var1 as character no-undo.
define buffer pt1 for pt1.
define buffer pt2 for pt2.
define buffer pt3 for pt3.
namespace.Obj:proc1(input p1, input 'test':U, output var1).
namespace.Obj:proc2(input p2, input 'test2':U, output var1).
find first pt1
where pt1.f1 = p1
and pt1.f2 = p2
no-lock no-error.
for each pt2
where pt2.f1 = p1
and pt2.f2 = pt1.f1
no-lock:
find first pt3
where pt3.f1 = p1
and pt3.f2 = '':U
and pt3.f3 = '':U
and pt3.f4 = '':U
and pt3.f5 = pt1.f1
and pt3.f6 = pt2.f2
no-lock no-error.
if available pt3 then
return pt3.f6.
end.
return '':U.
end function.
For the last example, both the nested FIND and the FIND out-side are marked as being nested.
#39 Updated by Dănuț Filimon about 1 year ago
- Tracking nested finds in different looping blocks (for each, repeat, do ... to, do while);
- Tracking nested finds that use persistent and temporary tables separately;
- Tracking joins between persistent and temporary tables (persistent-persistent, persistent-temporary, temporary-temporary);
- Investigate #6709-38.
#40 Updated by Dănuț Filimon about 1 year ago
Alex, I took a look at the last example from #6709-38 and only the FOR EACH find has the nested_find annotation. Are you sure this is the right example? I did have to remove
namespace.Obj:proc1(input p1, input 'test':U, output var1). namespace.Obj:proc2(input p2, input 'test2':U, output var1).and maybe this was the cause?
#41 Updated by Dănuț Filimon about 1 year ago
<ast col="24" id="30064771109" line="3" text="where" type="KW_WHERE">
<annotation datatype="java.lang.Boolean" key="nested_ref" value="false"/>
<ast col="0" hidden="true" id="30064771111" line="0" text="expression" type="EXPRESSION">
<annotation datatype="java.lang.Long" key="support_level" value="16400"/>
<annotation datatype="java.lang.Boolean" key="hql" value="true"/>
<ast col="37" id="30064771112" line="3" text="=" type="EQUALS">
<annotation datatype="java.lang.Long" key="matchtype" value="101"/>
<annotation datatype="java.lang.Long" key="support_level" value="16400"/>
<annotation datatype="java.lang.Boolean" key="nullable" value="true"/>
<annotation datatype="java.lang.Boolean" key="hql" value="true"/>
<ast col="30" id="30064771115" line="3" text="tt1.f1" type="FIELD_INT">
<annotation datatype="java.lang.String" key="fieldname" value="tt1.f1"/>
<annotation datatype="java.lang.Boolean" key="hql" value="true"/>
<annotation datatype="java.lang.Boolean" key="current_buffer" value="true"/>
<annotation datatype="java.lang.Long" key="type" value="422"/>
<annotation datatype="java.lang.Long" key="support_level" value="16400"/>
<annotation datatype="java.lang.Long" key="oldtype" value="6"/>
<annotation datatype="java.lang.String" key="methodtxt" value="getF1"/>
<annotation datatype="java.lang.String" key="uniquename" value="tt1_tt1_false"/>
<annotation datatype="java.lang.Long" key="frefid" value="30064771083"/>
<annotation datatype="java.lang.String" key="bufrefkey" value="tt1,tt1,30064771075"/>
<annotation datatype="java.lang.Boolean" key="nullable" value="true"/>
<annotation datatype="java.lang.Long" key="recordtype" value="14"/>
<annotation datatype="java.lang.String" key="schemaname" value="tt1.f1"/>
<annotation datatype="java.lang.Boolean" key="is_meta" value="false"/>
<annotation datatype="java.lang.String" key="dbname" value=""/>
<annotation datatype="java.lang.Long" key="bufreftype" value="21"/>
<annotation datatype="java.lang.String" key="name" value="tt1.f1"/>
<annotation datatype="java.lang.Long" key="refid" value="30064771123"/>
<annotation datatype="java.lang.String" key="bufname" value="tt1"/>
</ast>
<ast col="39" id="30064771116" line="3" text="room.room-num" type="FIELD_INT">
<annotation datatype="java.lang.Boolean" key="related_buffer" value="false"/>
<annotation datatype="java.lang.Long" key="support_level" value="16400"/>
<annotation datatype="java.lang.Boolean" key="nullable" value="true"/>
<annotation datatype="java.lang.String" key="uniquename" value="hotel.room_hotel.room_false"/>
<annotation datatype="java.lang.Boolean" key="possible_needs_buffer" value="true"/>
<annotation datatype="java.lang.Boolean" key="sub_expression" value="true"/>
<annotation datatype="java.lang.Long" key="recordtype" value="12"/>
<annotation datatype="java.lang.String" key="schemaname" value="hotel.room.room-num"/>
<annotation datatype="java.lang.String" key="format" value="">>>>9""/>
<annotation datatype="java.lang.String" key="name" value="room.room-num"/>
<annotation datatype="java.lang.String" key="fieldname" value="roomNum"/>
<annotation datatype="java.lang.Boolean" key="hql" value="false"/>
<annotation datatype="java.lang.Boolean" key="current_buffer" value="false"/>
<annotation datatype="java.lang.Long" key="type" value="422"/>
<annotation datatype="java.lang.Long" key="oldtype" value="6"/>
<annotation datatype="java.lang.String" key="methodtxt" value="getRoomNum"/>
<annotation datatype="java.lang.String" key="bufrefkey" value="hotel.room,hotel.room,-1"/>
<annotation datatype="java.lang.Boolean" key="is_meta" value="false"/>
<annotation datatype="java.lang.String" key="columnlabel" value=""Room Number""/>
<annotation datatype="java.util.ArrayList" key="label">
<listitem datatype="java.lang.String" value=""Room Number""/>
</annotation>
<annotation datatype="java.lang.String" key="dbname" value="hotel"/>
<annotation datatype="java.lang.Long" key="bufreftype" value="21"/>
<annotation datatype="java.lang.Long" key="refid" value="30064771124"/>
<annotation datatype="java.lang.String" key="bufname" value="hotel.room"/>
</ast>
</ast>
</ast>
</ast>
I can extract the type of tables we use in a FIND where clause by looking at the
recordtype annotation (TABLE or TEMP-TABLE), I can also check what is the database used by using dbname ("" is for the temp-tables). I can make reports for each one, but I think the one where we use the recordtype is enough. The classify function will return PERSISTENT, TEMPORARY, PERSISTENT AND TEMPORARY depending on the scenario.#42 Updated by Alexandru Lungu about 1 year ago
Alex, I took a look at the last example from #6709-38 and only the FOR EACH find has the nested_find annotation. Are you sure this is the right example? I did have to remove
May be related to the OO stuff, can't tell. I copy-pasted the code and simply replaced the names.
#43 Updated by Dănuț Filimon about 1 year ago
- FOR EACH Nested FIND -> Nested FIND
- Nested FIND Parent Blocks (block_type of the inner_block)
- Nested FIND Table Joins (persistent/temporary or both type of tables)
Alexandru, I think you can pick this up for the moment and check if there is anything else that might be needed.
#44 Updated by Dănuț Filimon about 1 year ago
- Nested FIND: 13 first, 6 next, 5 last, 5 current, 3 where (this is confusing a bit because I can have FIRST ... WHERE) - I'll make sure to clear that up
- Nested FIND parent blocks: 6 do_to, 6 repeat, 6 for_loop, 2 repeat_to, 2 repeat_while
- Nested FIND Table Joins: 3 Persistent join, 1 persistent and temporary join
#45 Updated by Dănuț Filimon about 1 year ago
Dănuț Filimon wrote:
- Nested FIND: 13 first, 6 next, 5 last, 5 current, 3 where (this is confusing a bit because I can have FIRST ... WHERE) - I'll make sure to clear that up
Committed 6709a/16033 for the above.
#46 Updated by Dănuț Filimon about 1 year ago
Committed 6709a/16034. Included UNIQUE finds in the report, I missed those previously.
#47 Updated by Dănuț Filimon about 1 year ago
- add a report where nested find queries are displayed based on the type of block, but only if the block references the same buffer
- add report for database nested find joins (it's based on the database name).
#48 Updated by Alexandru Lungu about 1 year ago
Is this ready for review? Or are you actively working on #6709-47?
#49 Updated by Dănuț Filimon about 1 year ago
#50 Updated by Dănuț Filimon about 1 year ago
- there must be a nested find (
ensted_findannotation), there must be a specific ancestor looping inner block (FOR_LOOP) and there must be a for each nested find reference (a buffer used by the for each must also be used in the find query, which can be the record phrase or a field in the where clause). The FOR EACH must use EACH for this, but a statement such asFOR EACH tt1, FIRST tt2.will qualifytt1andtt2buffers for referencing, and the FIND query will be part of the report the moment a valid reference is found. - FINDs will be classified by the same expression used in the Nested FINDs report.
I am working on the next block report, but my plan is to find any common code I need and create functions and avoid repetition.
#51 Updated by Dănuț Filimon about 1 year ago
I rebased 6709a to latest trunk/16046 and committed 16050. Added nested find block type reports.
#52 Updated by Dănuț Filimon about 1 year ago
- Status changed from WIP to Review
- FOR EACH blocks are the most simple because those include a query.
- do while generates
while (tt1._available()),while ((tt1.isF2()).booleanValue()),while (_isEqual(tt1.getF1(), 1)) - repeat while generates LogicalOps expressions that are used as clauses
- do ... to generates
for (i.assign(1); _isLessThanOrEqual(i, tt1.getF1()); i.increment()) - repeat for generates
repeat("loopLabel9", new Block((Init) () -> { RecordBuffer.openScope(tt5); },which could work - repeat to generates a ToClause.
#53 Updated by Dănuț Filimon about 1 year ago
- reviewer Alexandru Lungu, Ovidiu Maxiniuc added
Ovidiu/Alexandru, please review 6709a for the report changes.
#54 Updated by Dănuț Filimon about 1 year ago
Dănuț Filimon wrote:
I'm looking into the runtime changes and how the blocks are converted at the moment, just to understand what I can use to my advantage. Currently:
- FOR EACH blocks are the most simple because those include a query.
This is the easiest out of all of them, I can get the record buffers associated directly from the query. I did something similar in this issue, but there are a few improvements that can be done.
- do while generates
while (tt1._available()),while ((tt1.isF2()).booleanValue()),while (_isEqual(tt1.getF1(), 1))- repeat while generates LogicalOps expressions that are used as clauses
- do ... to generates
for (i.assign(1); _isLessThanOrEqual(i, tt1.getF1()); i.increment())- repeat for generates [...] which could work
- repeat to generates a ToClause.
The rest are complicated, mostly because there is no query involved and there is no such thing as offEndQueries that can be used. For simple blocks like while (tt1._available()), I have no way of knowing when I enter and exit the loop. My suggestion right now is to only write the part for the FOR EACH queries.
We have the reports for the nested finds in specific blocks, but I don't think this will be enough.
#55 Updated by Greg Shah about 1 year ago
If we are implementing a runtime mode for this detection, we would expect to use the TransactionManager to get details about the enclosing scopes. The would allow us to track any looping block except for the ones that have no BlockManager support.
I would expect that we would "overlay" the existing queries on that "view" to know what queries are being executed in loops.
#56 Updated by Greg Shah about 1 year ago
We don't want this to be driven by conversion, but rather we would want to detect things purely based on runtime processing. This will detect a wider range of cases, including dynamic queries.
#57 Updated by Dănuț Filimon about 1 year ago
Greg Shah wrote:
If we are implementing a runtime mode for this detection, we would expect to use the
TransactionManagerto get details about the enclosing scopes. The would allow us to track any looping block except for the ones that have noBlockManagersupport.I would expect that we would "overlay" the existing queries on that "view" to know what queries are being executed in loops.
The TransactionManager holds information about the blocks and offEndQueries which is what I need, the issue comes when I am trying to see what buffers are being used by the FindQuery. If I have something like:
new FindQuery(tt1, "tt1.f1 = 1 and ?", null, "tt1.recid asc", new Object[]
{
(P2JQuery.Parameter) () -> isEqual(tt2.getF1(), 1)
}).first();
I am sure that the where clause will only include only the buffer tt1, but to find the buffers used in the parameters is something else. I am trying to find a solution that will not introduce too much of an overhead.#58 Updated by Dănuț Filimon about 1 year ago
One solution would be to consider all FindQuery nested when its buffers can be found in the openBuffers and we are in a FOR_LOOP block, but this scenario will consider the FindQuery as nested:
for each tt1. find first tt2. end.
#59 Updated by Dănuț Filimon about 1 year ago
- File chui-nestedfind-report.png added
Added a fix to 6709a/16051, only reports are affected. I also got the report results for the ChUI application.
Nested FINDUNIQUE ... WHERE: 13572 matches (65.57%) in 1254 files (87.20%)FIRST ... WHERE: 2518 matches (12.16%) in 700 files (48.68%)LAST ... WHERE: 1549 matches (7.48%) in 462 files (32.13%)NEXT ... WHERE:777 matches in 182 filesUNIQUE: 774 matches in 256 filesLAST: 613 matches in 263 filesPREV ... WHERE: 483 matches in 130 filesFIRST: 376 matches in 205 filesCURRENT: 19 matches in 19 filesNEXT: 12 matches in 9 filesPREV: 7 matches in 4 files
Nested FIND Parent BlocksREPEAT: 11658 matches (56.32%) in 827 files (57.51%)FOR_LOOP: 5964 matches (28.76%) in 890 files (61.89%)DO_WHILE: 1646 matches (7.95%) in 204 files (14.19%)DO_TO: 746 matches in 228 filesDO_TO_WHILE: 309 matches in 33 files - NOTE: No individual report for this one, it will be a TODOREPEAT_WHILE: 281 matches in 71 filesFOR_LOOP_WHILE: 75 matches in 15 files - NOTE: No individual report for this one, it will be a TODOREPEAT_TO: 31 matches in 13 files
Nested FIND Table JoinsPERSISTENT JOIN: 7524 matches (90.24%) in 1012 files (95.38%)PERSISTENT AND TEMPORARY JOIN: 777 matches (9.32%) in 235 files (22.15%)TEMPORARY JOIN: 37 matches (0.44%) in 23 files (2.17%)
Nested FIND Database Joins- NOTE: I found an issue here, only joins that involve more than 1 database should be reported, but I have reports for a single database. A total of 29 "joins" reported, but only 18 are right. From that 18, only 1 involves 3 databases (including temp)._temp <db1>: 742 matches (8.9%) in files (21.87%)_temp <db2>: 20 matches (0.24%) in 1 file (0.09%)<db1> <db3>: 6 matches (0.07%) in 2 files (0.19%)
Nested FIND in FOR EACH(total nested finds in FOR_LOOP were 5954, while only 3416 were reported here)UNIQUE ... WHERE: 2588 matches (75.76%) in 757 files (91.65%)FIRST ... WHERE: 563 matches (16.48%) in 258 files (31.23%)LAST ... WHERE: 232 matches (6.79%) in 109 files (13.20%)NEXT ... WHERE: 27 matches in 17 filesPREV ... WHERE: 6 matches in 2 files
Nested FIND in REPEAT(total nested finds in REPEAT were 11658, while only 35 were reported here)UNIQUE ... WHERE: 18 matches (51.43%) in 3 files (75%)FIRST ... WHERE: 16 matches (45.71%) in 3 files (75%)NEXT: 1 match (2.86%) in 1 (25%)
Nested FIND in REPEAT ... TO: 0 foundNested FIND in REPEAT WHILE(total nested finds in REPEAT_WHILE were 281, while only 61 were reported here)NEXT ... WHERE: 39 matches (63.93%) in 16 files (53.33%)UNIQUE ... WHERE: 19 matches (31.15%) in 15 files (50%)LAST ... WHERE: 2 matches (3.28%) in 1 file (3.33%)FIRST ... WHERE: 1 match in 1 file.
Nested FIND in DO ... TO- 0 foundNested FIND in DO WHILE(total nested finds in DO_WHILE were 1646, while only 33 were reported here)NEXT ... WHERE: 16 matches (48.48%) in 12 files (70.59%)LAST ... WHERE: 7 matches (21.21%) in 3 files (17.65%)UNIQUE ... WHERE: 6 matches (18.18%) in 5 file (29.41%)PREV ... WHERE: 4 match in 4 file.
#60 Updated by Dănuț Filimon about 1 year ago
I committed 6709a/16052. Added FOR_LOOP_WHILE and DO_TO_WHILE reports, fixed database joins report. (refs: #6709)
In addition to #6709-59, I've got:Nested FIND in FOR_LOOP_WHILE(A total of 75 nested finds, while only 31 had references)UNIQUE ... WHERE: 30 matches in 13 filesFIRST ... WHERE: 1 match in 1 file.
Nested FIND in DO_TO_WHILE(A total of 309 nested finds, while only 152 had references)NEXT ... WHERE: 76 matches in 15 files.PREV ... WHERE: 76 matches in 15 files.
#61 Updated by Dănuț Filimon about 1 year ago
new FindQuery(tt1, "tt1.f1 = 1 and ?", null, "tt1.recid asc", new Object[]
{
(P2JQuery.Parameter) () -> isEqual(tt2.getF1(), 1)
}).first();
I can't come up with any idea on how to let the FindQuery that tt2 is a reference that needs to be checked. In AbstractQuery.processSubstitutionArguments() I end up checking each object and the only information I can get from Start@lambda is the Start class and it's parameters (tt1, tt2 and other properties defined).
#62 Updated by Greg Shah about 1 year ago
Dănuț Filimon wrote:
[...]
I can't come up with any idea on how to let the FindQuery that
tt2is a reference that needs to be checked. InAbstractQuery.processSubstitutionArguments()I end up checking each object and the only information I can get from Start@lambda is theStartclass and it's parameters (tt1, tt2 and other properties defined).
We could make a conversion change to pass in an array of buffers that are referenced in the substitution parameters. Then the runtime could track from there.
#63 Updated by Dănuț Filimon about 1 year ago
Greg Shah wrote:
Dănuț Filimon wrote:
[...]
I can't come up with any idea on how to let the FindQuery that
tt2is a reference that needs to be checked. InAbstractQuery.processSubstitutionArguments()I end up checking each object and the only information I can get from Start@lambda is theStartclass and it's parameters (tt1, tt2 and other properties defined).We could make a conversion change to pass in an array of buffers that are referenced in the substitution parameters. Then the runtime could track from there.
If conversion changes are acceptable, this is what I'd like to do. I've already experimented with arrays and FindQueries in #9078, so this should be a piece of cake!
#64 Updated by Greg Shah about 1 year ago
If conversion changes are acceptable, this is what I'd like to do.
Yes, go ahead.
#65 Updated by Dănuț Filimon about 1 year ago
I implemented the conversion changes necessary, this works by emitting a DataModelObject array before the Object array in database_access.rules. I still have to iterate over the tree to check for any fields and process the bufname annotation depending on whenever the database is _temp or persistent. Right now I am running a ChUI conversion to validate my conversion changes, then I'll continue working on the runtime.
#66 Updated by Dănuț Filimon about 1 year ago
I'll have to work on the conversion changes a bit more, the bufname is not the right one to use in this case. I've found a scenario on ChUI where I am not using the right buffer.
#67 Updated by Dănuț Filimon about 1 year ago
I see the ChUI project used datanames.xml which also changes how the converted project sees the bufname and filename.
<phrase-root>
<custom>
<phrase-match="et" replace="example test"/>
</custom>
</phrase-root>
But the most problematic issue is that the fieldname isn't always mentioning the matched table, while the other annotations always use the original table name.
#68 Updated by Dănuț Filimon 12 months ago
Dănuț Filimon wrote:
I see the ChUI project used
datanames.xmlwhich also changes how the converted project sees the bufname and filename.<phrase-root>
<custom>
<phrase-match="et" replace="example test"/>
</custom>
</phrase-root>But the most problematic issue is that the fieldname isn't always mentioning the matched table, while the other annotations always use the original table name.
I found a way to get the actual buffer name used (after the match is done).
<action>refidval = #(long) bufRef.getAnnotation("refid")</action>
<action>refAst = getAst(refidval)</action>
<action>printfln("--- %s", #(String) refAst.getAnnotation("javaname"))</action>
this is from get_javaname, so I am sure I can just use this function to get the name of the buffer.
I'll wrap up the changes and start a ChUI conversion to confirm that the issue is fixed.
#69 Updated by Dănuț Filimon 12 months ago
- Status changed from Review to WIP
- % Done changed from 0 to 50
I am putting this into WIP as I am close to getting the runtime changes done, so I'd rather get a review for all of the changes when I am finished. I asked Andrei to run a test with a customer application and there was a regression, so I'll be investigating this issue.
#70 Updated by Dănuț Filimon 12 months ago
- % Done changed from 50 to 80
- Status changed from WIP to Review
I committed 6709a/16053. There was an issue with RuntimeJastInterpreter.java where the DataModelObject array was not handled.
Alexandru, please review. I'll leave the Done at 80 since I might need to add more details or process the query information in a way that is easy to read.
The customer application I tested showed a single nested FindQuery executed 104 times (database: _temp, 1 buffer).
#71 Updated by Dănuț Filimon 12 months ago
Dănuț Filimon wrote:
I committed 6709a/16053. There was an issue with RuntimeJastInterpreter.java where the DataModelObject array was not handled.
I should have given a bit more context on all of the changes and not the regression.
Changes include:- Additional classes for nested FindQuery JMX.
- Rule changes to add a DataModelObject array, this is done right before the Object array is created because the arguments of this array are generated when found. For the DMO array, I can get all buffers much sooner and I can avoid putting the code in a place and getting conflicts between the elements of both arrays.
- FindQuery constructors to support the new array, the nested check is only done once when the query is initialized.
- Changes to BlockManager and TransactionManager to hold off clearing the offEndQueries after stopping the registration as I need those to check for the nested status, TransactionManager has
isNestedBufferReference()which takes a buffer and checks if it's nested.
#72 Updated by Dănuț Filimon 11 months ago
Rebased 6709a to latest trunk/16122, the branch is now at revision 16129.
#73 Updated by Dănuț Filimon 11 months ago
Rebased 6709a to latest trunk/16145, the branch is now at revision 16152.