Bug #7336
optimize DmoMeta.byLegacyName
100%
History
#1 Updated by Alexandru Lungu about 3 years ago
- File performance-tests.png added
- Status changed from New to WIP
- Start date deleted (
05/09/2023) - % Done changed from 0 to 30
The effort for this task is related to the DmoMeta.byLegacyName hotspot, caused by lots of calls to TextOps.rightTrimLower. This is required to identify a certain property in a map based on a rtrimmed case-insensitive comparison.
Exploring¶
General use-case¶
In a run of a large customer application, I get ~588k hits of DmoMeta.byLegacyName.
A single TextOps.rightTrimLower takes on average 0.00057ms, while an IdentityHashMap look-up is done in 0.00007ms close to 0.00009ms.
Our use-case requests to support a lot of look-ups (~588k) and no real-time updates. Also, the build-up time is negligible, especially in warm runs.
In conclusion, the map we use stores the intern representation of strings, so the map look-up is very fast. However, we are forced to rtrim and lower the strings we use before comparison (+ interning) at look-up time. The solution is to move the complexity from look-up time to build-up time.
Specific use-case¶
In the customer application I tested, a temp-table has ~35 fields, while a persistent-table has ~65 fields. These are only static tables, the real use-case may be skewed due to dynamic definitions.
Patricia Trie Performance¶
I had an attempt to implement a classical character based trie, but end up with very bad performance results. I don't have a clear mean of storing the edges, without obvious problems comparing to a simpleIdentityHashMap.
- A hash map in each trie node explodes the put time (x50). The get time is only x2 slower.
- An array of 100 positions (just on the presumptions that characters are usually ASCII) causes OOM.
- I encountered other implementations in Java of such trie, but most of them relate to suffix compression or edge compression. These are heuristics and don't guarantee a good fit on our use-case.
- The time is considerably better, considering we don't have to generate huge structures in each node, but only keep a reference to left/right nodes.
- Each character is converted to its binary representation to use the left/right model from bitwise trie model. In Java, characters have 16 bits, so a 20 character long string determines a 320 depth tree. An easy optimization here is to extend the PATRICIA trie implementation to allow only 8-bit binary representation. I expect most of the table field names to use only ASCII characters anyway.
- apache.commons4 allows the override of
AbstractBitwiseTrie, but not thePatriciaTrie. Therefore, we don't have a mean of easily extending the PATRICIA tree there, beside re-extending it fromAbstractBitwiseTrie(or do a pull request).
I've done some tests in that sense: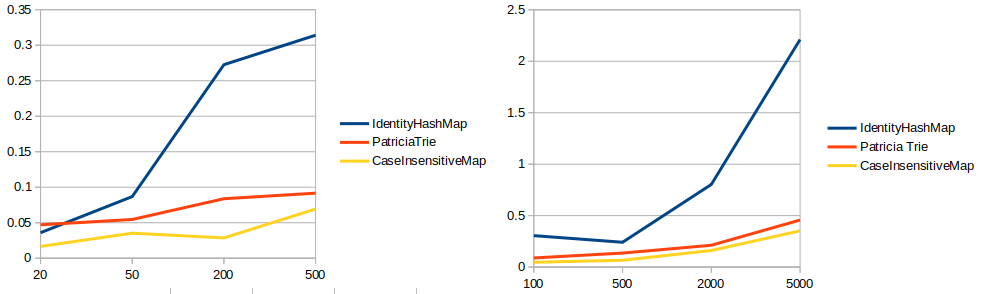
The y-axis is the time and the x-axis is the number of .get calls. In the left diagram we have a target map with 20 entries. In the right diagram we have a target map with 100 entries. The put time is similar between these. All times are warm.
For IdentityHashMap, I use the intern of strings. Each look-up and update is done with toLowerCase.
For PatriciaTrie, I use the original strings. Each look-up and update is done with the string as it is. This approach presumes that we will extend the PatriciaTrie implementation to solve the case-insensitive issue implicitly. Therefore, we can consider that these times will increase a bit after integration.
For CaseInsensitiveHashMap, I use the original strings. Each look-up and update is done with the string as it is. The implementation already takes case of case-sensitivity.
The results are not promising for the PatriciaTrie, especially in comparison with CaseInsensitiveMap. Also note that the PatriciaTrie should be extended to achieve something like this. Also, it may prove faster with lowering the bits used per character (8 instead of 16).
IdentityHashMap optimization¶
This is important!
I experimentally added a map look-up before TextOps.rightTrimLower(lf).intern(). If the parameter is already in the map, return it. I used the fact that the map entries are interned, so usually the string we will get may be already in the map as they are.
Out of 588k calls, 440k resolve with this short-circuit. The total time for this is 32ms. The other 148k are not found in the map in the first try (or the map is not created yet). All these 148k are resolved in 86ms.With a rough calculation on my side, the old implementation shown 376ms spent in DmoMeta.byLegacyName. With this short-circuit, only 124ms are spent here, meaning a -66% improvement. This doesn't eliminate the lowerCase and trim, but rapidly handles the cases which don't require them.
With a real profiling scenario, the old implementation shown 250ms spent on the look-up. With this short-circuit, only 139ms are spent here, meaning a -45% improvement. This doesn't eliminate the lowerCase and trim, but rapidly handles the cases which don't require them.
The downside here is that we increase the dependence upon an IdentityHashMap and rule out the possibility to switch to a CaseInsensitiveHashMap.
I will update this task with a comparison between IdentityHashMap with short-circuit and CaseInsensitiveHashMap.
Right trimming¶
TODO
#2 Updated by Alexandru Lungu about 3 years ago
Done multiple runs of a customer POC. I got:
Original: 50ms spent on map look-up, 200ms spent on lowering, right-trimming and interning.
Original optimized: 63ms spent on map look-up and short-circuit, 76ms spent on lowering, right-trimming and interning.
CaseInsensitiveMap: 90ms spent on map look-up, 21 ms spent on right trimming.
Note that I also tried CaseInsensitiveMap with interning, but it was disastrous (94 ms look-up, 173 rtrim and intern).
The best solution for now is using CaseInsensitiveMap to a total of 111ms comparing to the original 250ms (-55% improvement). Fortunately, I think that we can make CaseInsensitiveMap aware of rtrim: compute the hash without the last spaces and do regionMatch properly. Hopefully, this can go under 100ms and have our optimization close to -60%.
On the other side, I would like to go ahead with a apache.commons4 PATRICIA test. Eventually, I will do some magic to have a case-sensitive, 8bit implementation there and see some proper results. If PATRICIA will have a look-up < 90ms (comparing to CaseInsensitiveMap), we can switch to PATRICIA and do the rtrimming inside.
#3 Updated by Alexandru Lungu about 3 years ago
- Status changed from WIP to Review
- % Done changed from 30 to 100
Right trimming¶
I found it accessible to add rtrim in some structures:- For
CaseInsensitiveMapI stop computing the hash before the trailing spaces (detected after doing a reverse look-up). The stringregionMatcheswill be done until the trailing spaces - For
PatriciaTrie, stringregionMatchesis done until the trailing spaces. Fortunately, the suffix compression technique used there allowed me to approach such simple solution. - For
IdentityHashMapandHashMap, such extension wasn't possible, so rtrimming should be done before look-up.
Patricia Trie optimizations¶
I've done a lot of PatriciaTrie optimizations. I cut down the whole implementation to the following traversing function.
public boolean isBitSet(final String key, final int bitIndex, final int lengthInBits)
{
// [sanity check]
return BITS[key.charAt(bitIndex >> 3)][bitIndex & 7]; // BITS[i][j] -> if the j-th bit of the upper-case version of i is set
}This is called between 1-8 times per character in a look-up to reach the longest matching prefix in the trie (return
false means left, true means right). The upper-bound is Nodes times, but the average is log(Nodes) times.
After the closest node is found, it should be checked. This is done with regionMatches between the first mismatching character till the trailing spaces.
Unless BITS (which is a boolean[][]) can be optimized, I am afraid this is the best we can achieve here to support both case-insensitivity and rtrimming in a Patricia Trie.
Results¶
HashMap¶
Of course, I had to giveHashMap a shot. Impressively, it set a really low standard of 118 ms.
- Lower + r-trim: 51ms
- Look-up: 67ms
This made me think that out problem here was the .intern. In fact, removing it and using HashMap cut down the time from 250ms to 118ms. Our issue was interning, causing a ~133ms overhead.. The results now on are only fine-tuning of these 118ms, but certainly not that big as we got after removing .intern. Doing a look-up into the string pool 558K times wasn't that fast. Also, we risked interning string patterns which were not in the map, so this was leaking random strings into the string pool.
Patricia Trie¶
This is a test with Patricia Trie without any changes. This uses the right implementation from apache.commons4.- Lower + r-trim: 52ms
- Look-up: 88 ms
Of course, this approach fails as long as it doesn't succeed to surpass the simple HashMap. The whole idea of using a Patricia Trie is to have access to its internals and do the character comparison in ignore-case. Also, this allows rtrimming. It is good to see however what are the implications of using the Patricia Trie straight-away and what is the optimization degree afterwards.
Optimized Patricia Trie¶
Reducing 8bit to 16bit wasn't that relevant considering the path compression technique. I replaceds1.compareTo(s2) == 0 with s1.equals(s2) (or for that matter, equalsIgnoreCase). I replaced any division and mod operations with bit-wise operands and implemented support for rtrim. Of course, I've done the checks case-insensitivity. The results:
- Look-up: 101ms
This is better than the HashMap and way better than the initial IdentityHashMap. However, it has a really big limitation. I had to copy-paste the apache.commons4 source code to be able to extend it. As said, AbstractPatriciaTrie is not public and some methods from AbstractBitwiseTrie were protected, so I couldn't just extend. In a ideal case, I should have been able to extend AbstractPatriciaTrie, assigning it another StringKeyAnalyzer which does the whole case-sensitive/rtrim job.
CaseInsensitiveMap¶
We already have an implementation of such map. I extended to conditionally support rtrim.- Look-up: 98ms
This is the fastest solution profiled by now. It is close to the Optimized Patricia Trie, but it is cleaner. For that matter, I would go with such replacement in DmoMeta.byLegacyName for a total of -60% improvement (-16% comparing to the HashMap).
Conclusion¶
Even though I had high hopes with the Patricia Trie, I have to admit that using CaseInsensitiveMap is the best way to go here. I had several performance tests in which I've got better results with Patricia Trie comparing to CaseInsensitiveMap, but all were of a really slight difference (< 5%). In the tested POC I have better results with CaseInsensitiveMap (~3%). Also, the integration of Patricia Trie is not that clean due to the need of a better interface with apache.common4 (allowing us to extend it easily and not integrate code as it is).
The goal of this task was to optimize DmoMeta.byLegacyName, but the bottleneck was related to .intern rather than the data structure used. Even so, we can agree that 16% optimization is for us to take with CaseInsensitiveMap, beside the whole .intern removal.
If there are no other suggestions here, I will go ahead committing CaseInsensitiveMap inside DmoMeta.byLegacyName to 7026d.
#4 Updated by Alexandru Lungu about 3 years ago
Committed the switch to CaseInsensitiveHashMap in DmoMeta.byLegacyName with 7026d/rev. 14565.
#5 Updated by Alexandru Lungu about 3 years ago
- Status changed from Review to Test
7026d was merged to trunk as rev. 14587. This can be closed.
#6 Updated by Greg Shah about 3 years ago
- Status changed from Test to Closed
- Assignee set to Alexandru Lungu
#7 Updated by Eric Faulhaber about 3 years ago
- Subject changed from Trie implementation to support case insensitive and rtimmed string structures to optimize DmoMeta.byLegacyName