Conversion Technology Architecture¶
Summary¶
This chapter provides an overview of the automated FWD conversion process used to transform the 4GL application, its database schema files and its data into a drop-in replacement in which the source code is written in Java. This is to be distinguished from the project methodology used which was the subject of the previous chapter. The FWD tools and technology that provide the automated conversion process is only used in certain steps in the project. This chapter describes those FWD conversion tools.
The problem of converting an application from one language to another is extremely complex. Some of the main sources of this complexity include:
- The source language (Progress 4GL) and target language (Java) have significant differences. This is a natural consequence of:
- independent design processes with differing goals;
- development of each language was done by different companies;
- over a decade of technological advances in between the start of each language's respective design;
- The functionality supported by the Progress 4GL language and runtime is extensive. Even small applications are likely to be dependent upon an extensive range of features, all of which must be supported.
- In an effort to make applications easier to write, the designers of the Progress 4GL intentionally based many critical behaviors of the compiler and the runtime upon implicit decisions of the programmer rather than requiring the programmer to provide explicit guidance. For this reason, all 4GL applications have an unusually large amount of hidden and quirky behavior which cannot be easily determined.
- The Progress 4GL documentation is incomplete in many important areas. Even where there is documentation, that documentation is often misleading or inaccurate. This makes learning the language more difficult and duplicating the functionality even harder still.
- The Progress 4GL was designed to be similar to the use of human languages. This massively increased the number of keywords and the complexity of the syntax. Over the years the syntax was extended in many different and inconsistent ways.
This massive complexity is a huge impact for the FWD technology since it is designed to convert to a functionally identical result using a 100% fully automated conversion process. This means that the code will convert without any manual modifications of the generated source code! This fidelity requirement causes an order of magnitude increase in the complexity level of the conversion process. An unusual level of automation is needed to deal with this extreme complexity.
This extreme automation has an additional benefit. The conversion process can be executed at any time, over and over. This means that development can occur in the 4GL and the conversion can be run on the latest 4GL code with each commit, yielding a deployable Java version of the code which can be executed in the FWD runtime engine. This makes it possible to select any mixture of 4GL and Java development for an application. Development can occur in all 4GL, all Java or any mixture of the two. Over time this mixture of development can be shifted as may meet the organization's requirements.
The overall flow of the process can be seen in the following figure. This is a greatly simplified representation of the process. Each phase of the process has multiple sub-phases and each sub-phase may have hundreds or thousands of individual steps.
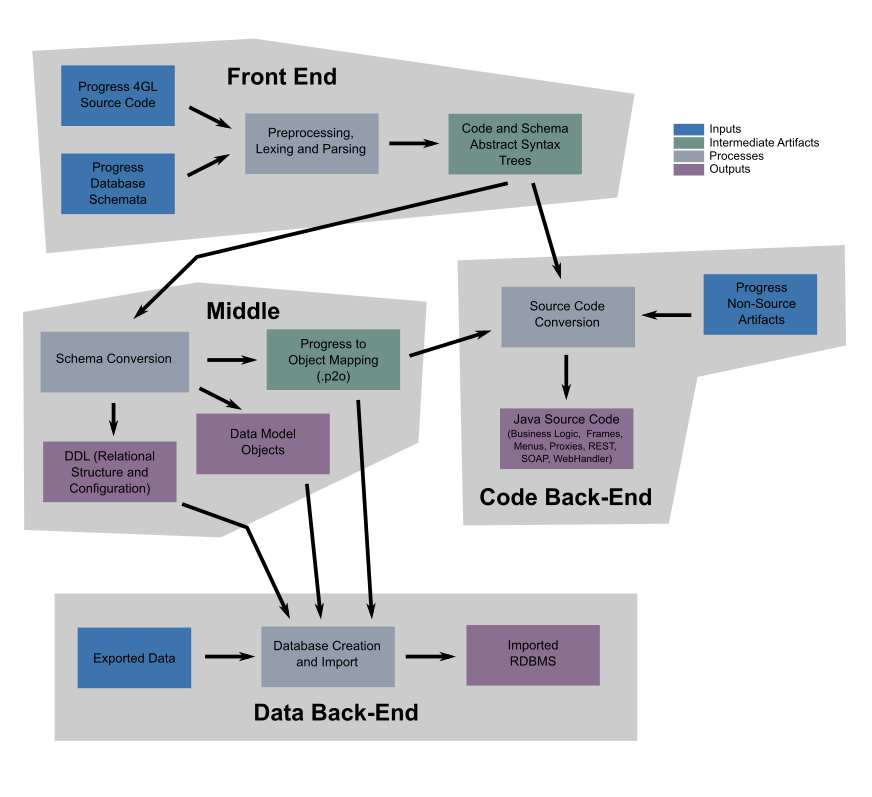
Before the automated conversion can be run, there is preparation work to be done. This preparation work is highlighted in the previous chapter on methodology and the details are addressed in later chapters of this book. It should be noted that this preparation work may be as short as a few days of work or as long as several months, depending of the composition and complexity of the application being converted. All of this preparation work may result in configuration data (called hints), 4GL source code changes, 4GL database schema changes or custom conversion rules which are utilized by the automated conversion process to properly complete its work.
When it is time to run the tools themselves, the entire process is automated and can be run as a single command line (except for the "Data Back-End" which is a separate step). A very small application (with a small schema and few rows in the database) might complete the entire process in under 5 minutes. For a medium or large application, the process may take hours.
The automated conversion process is written in a combination of Java and a language called Tree Processing Language (TRPL). Most of the Java portions are hand coded with the exception of certain parsing-related tasks where ANTLR (see www.antlr.org) was used to generate Java code from a grammar file). The TRPL language was invented by Golden Code Development and is the basis for the majority of the conversion process. All of this conversion technology (including the grammars for preprocessing, lexing and parsing 4GL source code and schemas) was created from scratch by Golden Code Development.
Details¶
Required Inputs¶
The application to be converted is comprised of the following inputs:
- for each database that is accessed by the application:
- the corresponding schema must be provided as a single exported
.dffile (this is needed at conversion time) - all data must be exported into
.dfiles for each database instance to be migrated
- the corresponding schema must be provided as a single exported
- all accessible application source code must be made available, preferably in un-preprocessed form:
- external procedure and trigger procedure files (usually
.por.w) - classes (
.cls) - embedded SpeedScript programs (
.htmor.html) - include files (usually
.i)
- external procedure and trigger procedure files (usually
- non-source code artifacts
- Proxygen
.xpxgfiles - REST
.paarfiles - SOAP
.wsmfiles - WebHandler
.propertiesconfiguration
- Proxygen
There are additional inputs that may be required (e.g. protermcap or .wrx files) for the resulting application to be complete or to correctly operate, but these inputs are not essential to this summarized discussion. For more details, please see Gathering Inputs.
Front End Conversion Process¶
The front end of the conversion process is responsible for converting all application inputs into an intermediate form which is more easily processed programmatically. This intermediate form is called an Abstract Syntax Tree (AST). This is a form that can be easily traversed, analyzed and transformed using the TRPL language which forms the base technology for all subsequent conversion processing. The most important aspect of the front end conversion is that it reads source files and and turns them into ASTs. Here is the concept:

The following is the medium detail process for the front end:
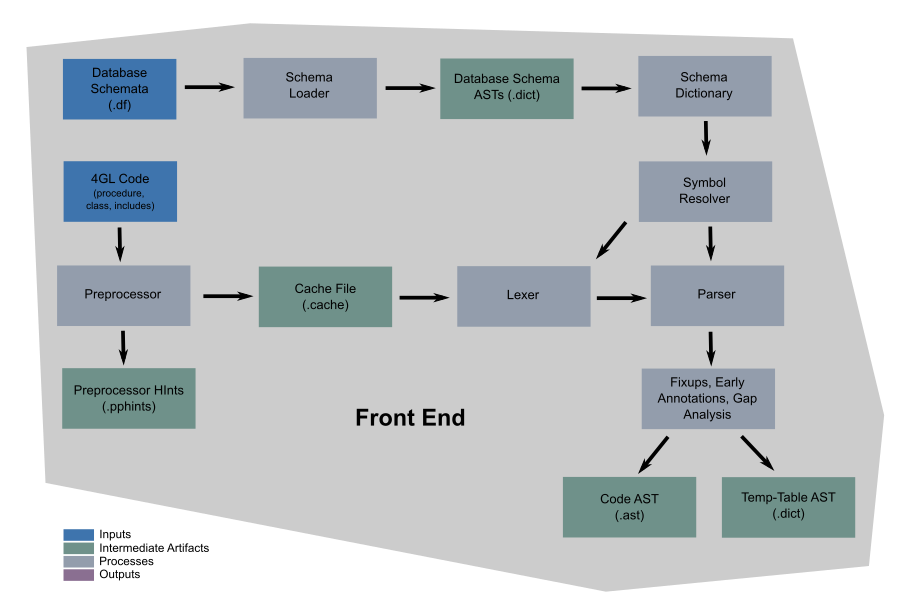
Since any database logic in the application source code can only be understood properly within the context of the database schemas that are in active use, the first step in the front-end process is to parse the database schemas. This parsing process takes all of the fields, tables, index and other data from the data dictionary and converts it into a set of ASTs. Java classes expose services based on this information read from the ASTs. These services are consumed by downstream conversion processing, including the 4GL language parsing. One example of these services is schema name resolution in the database.table.field format.
Each procedure file is then preprocessed. This handles include file processing, reference expansions and other preprocessor features.
The resulting source code is converted into a stream of tokens by the lexer and these tokens are structured into an AST by the parser. From this point of the process onward, all other conversion work is written in the TRPL language. TRPL is hosted in a Java environment and the implementation is pure Java. Even the resulting TRPL programs are compiled into Java classes for execution. Notwithstanding this, TRPL is a separate language that is designed to efficiently define the rules by which an AST is traversed, analyzed, modified or otherwise transformed.
Once the ASTs for all source files are available, they are analyzed to determine the call-graph of the application. An application's call-graph defines all programmatic linkages between discretely scoped portions of source code. For example, when one external procedure invokes another external procedure using the RUN language statement, there is a linkage defined between the respective nodes in the call-graph. The call-graph is useful for a wide range of analysis such as unreachable code processing.
The results of the front-end are various intermediate forms including source code ASTs, the schema dictionary ASTs.
In order to improve downstream code quality, a detailed record of all preprocessor transformations is stored as preprocessor hints. This allows downstream code to determine which AST nodes came from include files (and which include file), no matter how deeply nested the include file expansion occurred. Likewise, all preprocessor expansions of named or positional references can be determined from these hints.
Middle Conversion Process¶
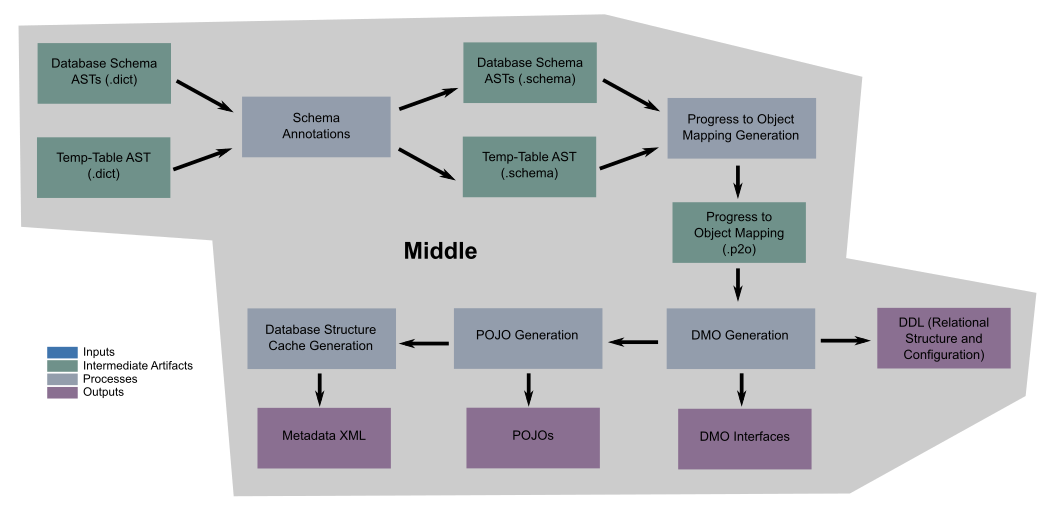
The middle of the conversion process analyzes the database schema and the application source ASTs to design and generate a complete set of Data Model Object (DMO) interfaces. Each DMO interface provides object-oriented access to a record of a given table in the converted relational schema. The DMO interfaces are used by the generated business logic.
There are other critical outputs of this phase. The DMO interfaces are the basis of Object-Relational Mapping (ORM) in FWD. ORM implements the idea that in an object oriented language, one would rather work with an object than a raw data record. While the generated DMO interfaces represent one of the final outputs of the conversion process, the conversion process itself must be aware of the mapping between Progress schema elements and their replacement objects (the DMOs). This information is retained in a persistent AST known as the Progress to Object (P2O) mapping. This mapping is used in several ways: downstream during the code back-end phase of conversion to reference database resources in converted business logic; to generate table, index, and sequence DDL for the specified database dialects; to drive the process of importing data into a new database; and at runtime, to facilitate on-the-fly conversion for temp-tables dynamically defined by business logic.
Code Back-End¶
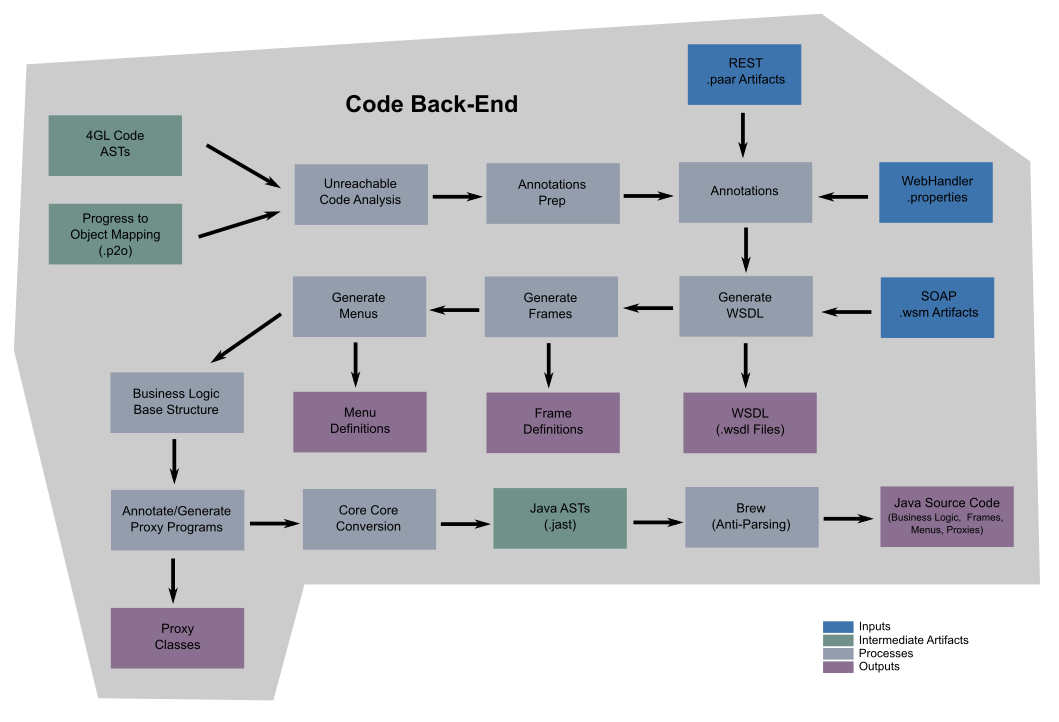
The code back-end analyzes source ASTs, transforms them into Java AST equivalents and then generates Java source code for each corresponding output file.
The code back-end traverses all source AST nodes that are reachable. Any code that is not reachable is removed (if it is in a live procedure file) or if the entire file is unreachable, the filename is placed in the dead files list. It is common for there to be a large amount of unreachable code in large applications that have been written over the course of decades. The percentage of unreachable code has been seen to be as large as 25%!
At this point, the source ASTs are ready for intensive analysis. This logic analysis sub-phase is actually a set of more than 60 sub-sub-phases, each with potentially hundreds of rules defined for the inspection, categorization, analysis and preparation of the source trees. As an example, 3 related sub-sub-phases exist for the proper calculation of buffer scopes for every database reference in every AST. Such analysis must by its nature be driven by the structure of the AST since the AST structure is highly related to scope processing. Frame scoping, block properties such as transaction levels and thousands of other critical facts are determined/calculated in this phase. The results of this analysis is written back into each AST as a set of annotations. Each AST node will have an arbitrary number of these annotations saved after this analysis is complete. These annotations are consulted in later steps to make decisions on the disposition or transformation of the associated AST nodes.
The next sub-phase (frame generator) is to extract the user interface (UI) from the business logic. It re-factors (separates) all static portions of the user interface into frame definition classes and removes these elements from the business logic, resulting in a cleaner and more modern application.
The core-conversion sub-phase is the moment in which a parallel set of Java ASTs is created based on the structure and content of the each original live Progress AST. As with the logic analysis, this sub-phase contains over 30 sub-sub-phases, each one with a potentially large number of rules. Generally, there is a single target AST (Java) created for each source AST (Progress 4GL). The structure of the source AST drives much of the structure of the target AST, though the target AST will be re-factored to improve code quality. After this sub-phase, the resulting Java ASTs are walked and each node is output into Java source code form (a kind of anti-parser).
Data Migration Process¶
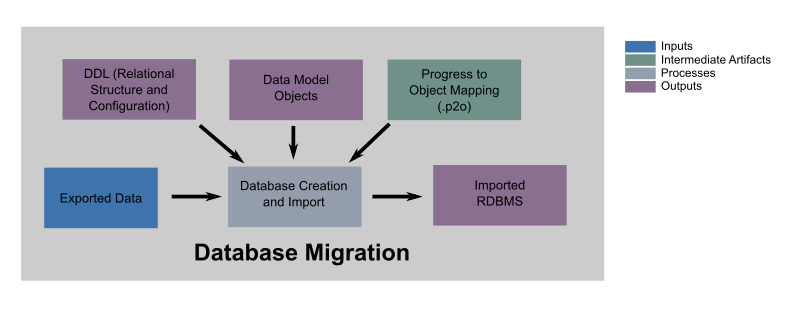
The database import process creates database instances and supports loading (importing) all exported data. Artifacts from the conversion are used to enable the migration. The end result of this phase is a fully operational relational database with all data migrated/loaded and ready for application access.
Converted Application Build¶
The conversion generates code that will compile (using javac) without any editing or modifications required. If the sample project was used to create the configuration, the Apache Ant build.xml can be used to compile, jar and run javadoc for the converted application.
This final phase of the code conversion process builds one or more JAR files for the application which are then loaded into the server runtime environment. The runtime environment provides a general purpose, secure, distributed application platform. More importantly it provides a layer of Java infrastructure that provides the identical behavior and function as the equivalent Progress 4GL language constructs. This compatible runtime is necessary to enable the resulting JAR file to run identically to the original application.
© 2004-2022 Golden Code Development Corporation. ALL RIGHTS RESERVED.