Data Migration¶
All but the most trivial Progress 4GL applications require database access. In the FWD runtime environment, data persistence services are backed by a Relational Database Management System (RDBMS). To prepare your converted application to run, it will be necessary to move your data out of a Progress database and into an RDBMS. Currently supported databases are PostgreSQL, SQL Server, and H2. As a prerequisite to the data import, you should have installed the necessary database software and prepared a new, target, database instance, as described in one of the following chapters:- Database Server Setup for PostgreSQL on Linux
- Database Server Setup for PostgreSQL on Windows
- Database Server Setup for SQLServer on Windows
- Database Server Setup for H2
- exporting your existing data from a Progress database;
- the process of migrating your data to its new home.
In order to migrate your data, you should have completed as a prerequisite at least the front end and middle portions of the conversion process with your application, and the results of that effort should successfully build (see the Building Converted Code chapter). Data migration relies upon classes and configuration files generated by those phases of conversion.
Data Export¶
The first step in migrating your data is to export it from its source, Progress database into an intermediate form which the import process can use. FWD data import uses the standard format written by the Progress EXPORT statement. It expects each table's data to be stored in a separate text file with a .d extension. It is critically important that the root file name of the export file matches the name specified for the corresponding table by the DUMP-NAME property in the .df schema file for the database. Otherwise, the import process will not be able to associate the exported data with the target table in the new database, and that table's data will not be imported.
Sequences represent a special case. Their definitions usually are exported together with the rest of the tables of the database, but optionally they can be exported to a special file named _seqdefs.df. Additionally, their current values must be exported manually. For the import of these values to be successful, the name of the file must be the default _seqvals.d offered by the Data Dictionary tool. Otherwise, the file will not be found and the sequences will not be correctly initialized in FWD.
The most convenient - though not necessarily the fastest - way to export data from its original Progress database is to use the Progress Data Dictionary utility. From the Data Dictionary, go to the Tools -> Data Administration menu. From there, use the menu Admin -> Dump Data and Definitions -> Sequences Current Values.
Refer to the Internationalization chapter for how to deal with encoding requirements during the export.
Move the exported files to a location accessible to the target database system. For a large data set, we recommend placing them on as fast a partition/drive as is available, to maximize I/O throughput during data import. In preparation for import, the files should be uncompressed and in a single directory.
Export Data from SQL Database into .d Dump Files¶
FWD supports exporting relational database data into .d file format using the ExportWorker utility. The export is a multi-threaded process, in which each thread handles the export of a single table at a time. Multiple tables are processed in parallel based on the specified thread count and the tables are exported in the order they are discovered.
NOTE: this form of export is not part of the normal flow of migrating data from a Progress database to a relational database. It is provided as a means of providing "round trip" support, for whatever reasons a user may have (e.g., test, backup, comparison, etc.). Database vendors generally provide tools for regular backup/restore/upgrade purposes, which should be explored and leveraged as post-conversion/migration options.
The FWD data export process handles both single tenant and multi-tenant configurations.
The data export can be performed using the export.sh script, which is included in the p2j repository under the /tools/scripts directory.
export.sh
-d {export_dir}
-l {lobs_dir}
-h {host}
-p {port}
-f {fwd_jar_dir}
-a {app_jar}
-m {dmo_package}
-e {encoding}
-x {max_heap}
-t {max_threads}
--db_type={db_type}
--db_variant={db_variant}
--db_home={db_home}
--db_adminid={db_adminid}
--db_adminpw={db_adminpw}
--db_physical_names={db_physical_names}
--db_logical_names={db_logical_names}
where:
{export_dir}is the path to the directory where the .d files will be stored;- if the specified directory doesn't exist, it will be created by the script.
{lobs_dir}is the directory path where LOB files will be stored;- if the specified directory doesn't exist, it will be created by the script;
{host}is the database host name or IP address.{port}is the port number the database listens on.{fwd_jar_dir}is the directory containing the FWD jars;{app_jar}is the application jar file;{dmo_package}is the base dmo package name (such ascom.goldencode.hotel.dmo);{encoding}is the character encoding to use for exported data- if not specified on the command line, the encoding will be read from the
p2j.cfg.xmlconfiguration file; - if absent there, it defaults to
UTF8;
- if not specified on the command line, the encoding will be read from the
{max_heap}is the maximum heap available to the JVM, specified as a number followed by anmfor megabytes or agfor gigabytes;{max_threads}is the maximum number of threads to use for export;{db_type}is the target database type (postgresql, sqlserver, mariadb, h2, etc.);{db_variant}is the database dialect variant (for mariadb db_type, lenient variant can be used);{db_home}is the location for h2 database, ignored if dbtype not h2;{db_adminid}is the database administrator username;{db_adminpw}is the administrator’s password;{db_physical_names}is a comma-separated list of physical database names to export.{db_logical_names}is a comma-separated list of logical database names corresponding to physical databases;- specify logical names only when exporting multi-tenant databases or when the logical names differ from the physical names.
- the order of physical names must exactly match the order of each logical name and the physical database name must have a corresponding logical name.
IMPORTANT NOTE: The fwdspi.jar name should NOT be changed because it is hardcoded in the script and also for java 17 it needs to be in the root of {fwd_jar_dir}
For example, for a PostgreSQL database named hotel_db we might use:
./export.sh -d ~/hotel/export -f ~/hotel/deploy/lib -a ~/hotel/deploy/lib/hotel.jar -m com.goldencode.hotel.dmo -p 5432 -h localhost --db_type=postgres --db_adminid=fwd_admin --db_adminpw=admin --db_physical_names=hotel_db
Assuming the Hotel is a multi-tenant application and you want the export the data for the tenant_1 and tenant_2 use:
./export.sh -d ~/hotel/export -f ~/hotel/deploy/lib -a ~/hotel/deploy/lib/hotel.jar -m com.goldencode.hotel.dmo -p 5432 -h localhost --db_type=postgres --db_adminid=fwd_admin --db_adminpw=admin --db_logical_names=hotel_db,hotel_db
--db_physical_names=tenant_1,tenant_2
Data Import¶
In this phase you will populate a new, target, database with the data exported from the corresponding Progress database. The process is the same, regardless of which type database you are using, since it uses the FWD runtime to process the import.
Prepare a Path to the Exported Data.¶
The data import process expects to find the data export (.d) files in a subdirectory of $P2J_HOME/data/. The approach we recommend is to create a symbolic link within $P2J_HOME/data/, which points to the directory containing those files. For example:
cd $P2J_HOME/data
ln -s {export_file_path} dump
where
{export_file_path} is the absolute path to the export file directory.
If your system does not support symbolic links, store the exported data directly in a dump subdirectory of $P2J_HOME/data/.
Set Logging Properties¶
The import program writes status and error messages using the J2SE logging API. This mechanism requires the logging subsystem be configured. To do this, FWD relies upon a logging.properties file in the $P2J_HOME/cfg/ subdirectory. A minimalist example of this file follows:
############################################################ # Default Logging Configuration File # # You can use a different file by specifying a filename # with the java.util.logging.config.file system property. # For example java -Djava.util.logging.config.file=myfile ############################################################ ############################################################ # Global properties ############################################################ # "handlers" specifies a comma separated list of log Handler # classes. These handlers will be installed during VM startup. # Note that these classes must be on the system classpath. # By default we only configure a ConsoleHandler, which will only # show messages at the INFO and above levels. handlers= java.util.logging.ConsoleHandler # Default global logging level. # This specifies which kinds of events are logged across # all loggers. For any given facility this global level # can be overriden by a facility specific level # Note that the ConsoleHandler also has a separate level # setting to limit messages printed to the console. .level = WARNING ############################################################ # Handler specific properties. # Describes specific configuration info for Handlers. ############################################################ # Limit the message that are printed on the console to INFO and above. java.util.logging.ConsoleHandler.level = FINEST java.util.logging.ConsoleHandler.formatter = java.util.logging.SimpleFormatter ############################################################ # Facility specific properties. # Provides extra control for each logger. ############################################################ com.goldencode.p2j.schema.ImportWorker.level = WARNING
The above settings will log warning and error messages generated by the import process to the console from which the program is launched. This level of logging is appropriate in most cases. For more verbose logging, change the last line (for the
com.goldencode.p2j.schema.ImportWorker logger) to a more verbose setting than WARNING, such as INFO, FINE, FINER, or FINEST.
Hibernate ORM is used under the covers for the import. It uses a number of its own loggers to provide additional details. For example, you can add entries for the org.hibernate.SQL and org.hibernate.type loggers, which will log detail about the SQL statements used by the import. Be forewarned that this can produce a lot of output.
Run the Import¶
The FWD import is a multi-threaded process, in which each thread of execution is dedicated to the import of a single table's data from start to finish, until that table's migration is complete. The import program will attempt to process tables in the order which allows the overall process to complete most quickly. Thus, those tables which are deemed to require the most time are attacked first in parallel threads, then those which are expected to take less time, and so on.
The command to run the import is as follows. It is formatted on multiple lines for readability, but it must be executed as a single command.
java
-server
[-Xmx{max heap} [-XX:+HeapDumpOnOutOfMemoryError]]
-classpath p2j/build/lib/p2j.jar:deploy/lib/{application}.jar:cfg:
-Djava.util.logging.config.file=cfg/logging.properties
-DP2J_HOME=.
com.goldencode.p2j.pattern.PatternEngine
-d 2
"dbName=\"[{export path}]\""
"targetDb=\"{postgresql | sqlserver | h2}\""
"url=\"{jdbc url}\""
"uid=\"{user role}\""
"pw=\"{password}\""
["tenantMode=\"{tenantMode}\""]
["dataPath=\"{dataPath}\""]
["lobPath=\"{lobPath}\""]
["maxThreads={threads}"]
schema/import
data/namespace {schema}.p2o 2>&1 | tee data_import_$(date '+%Y%m%d_%H%M%S').log
where:
{max heap}is the maximum heap available to the JVM, specified as a number followed by anmfor megabytes or agfor gigabytes;{export path}is an optional path which specifies the location of the export files, relative to$P2J_HOME/data/; if empty, the export files should reside directly in$P2J_HOME/data/;{application}must be replaced with the name of the application (as used for an application jar file);{jdbc url}must be replaced with a JDBC URL appropriate to the target database, as follows:- for PostgreSQL:
jdbc:postgresql://[{host}[:{port}]/]{database} - for SQL Server:
jdbc:sqlserver://{host};instanceName={sqlInstance};databaseName={database}; - for MariaDb (strict):
jdbc:mariadb://{host}[:{port}]/{database} - for MariaDb (lenient):
jdbc:mariadblenient://{host}[:{3306}]/{database} - for H2:
jdbc:h2:{location}/{database_name};MV_STORE=FALSE;LOG=0;CACHE_SIZE=65536;LOCK_MODE=0;UNDO_LOG=0
- for PostgreSQL:
{user role}should be replaced with a database role which has right to insert records into the database;{password}should be replaced with the password for the specified{user role};{tenantMode}is one of the following values:"none","default","strict", or"tenant". In case of multi-tenant import, this will filter the imported tables so that the share data won't leak into private and vice-versa;{dataPath}is the name of the folder containing.dfiles. If not specified it isdata/dump/{dbName}{lobPath}is the name of the folder containing LOB data. If not specified it is{dataPath}/lobs{threads}is a positive number indicating how many threads the import should use;{schema}is the name of the database schema namespace, as specified in$P2J_HOME/cfg/p2j.cfg.xml.
For example, for a PostgreSQL target database named hotel_test_db whose schema is named hotel, we might use:
java
-server
-Xmx2g -XX:+HeapDumpOnOutOfMemoryError
-classpath p2j/build/lib/p2j.jar:deploy/lib/hotel.jar:cfg:
-Djava.util.logging.config.file=cfg/logging.properties
-DP2J_HOME=.
com.goldencode.p2j.pattern.PatternEngine
-d 2
"dbName=\"hotel\""
"targetDb=\"postgresql\""
"url=\"jdbc:postgresql://localhost:5433/hotel_test_db\""
"uid=\"fwd_user\""
"pw=\"password\""
"maxThreads=2"
schema/import
data/namespace hotel.p2o 2>&1 | tee data_import_$(date '+%Y%m%d_%H%M%S').log
Assuming the Hotel is a multi-tenant application and you want the import the private part of a database from a merged dump (where a tenant and the default databases were dumped together) use:
java
-server
-Xmx2g -XX:+HeapDumpOnOutOfMemoryError
-classpath p2j/build/lib/p2j.jar:deploy/lib/hotel.jar:cfg:
-Djava.util.logging.config.file=cfg/logging.properties
-DP2J_HOME=.
com.goldencode.p2j.pattern.PatternEngine
-d 2
"dbName=\"hotel\""
"targetDb=\"postgresql\""
"url=\"jdbc:postgresql://localhost:5433/hotel_test_db\""
"uid=\"fwd_user\""
"pw=\"password\""
"maxThreads=2"
"tenantMode=\"tenant\""
schema/import
data/namespace hotel.p2o 2>&1 | tee data_import_$(date '+%Y%m%d_%H%M%S').log
This will exclude any shared tables (even if their .d files are present) and will import only the multi-tenant tables.
The maximum heap setting is optional, as is the setting to create a heap dump in the event of an out of memory error. Note that these are specific to the Oracle JVM implementation, or those based upon it (e.g., OpenJDK JVMs). If using a different JVM, options specific to that JVM implementation may be used here instead.
Setting the number of threads to use is optional as well. The default is 4. A higher number here is not necessarily better, depending on the distribution of data across exported tables. If there is a small number of very large tables and a large number of smaller tables, using a higher number of threads may actually increase the overall import time. The reason is that each thread operates on a single table. A small number of very large tables (sometimes only one) will define the critical path of the import. Taking away I/O resources from the threads processing those very large tables by assigning additional threads to process smaller tables can slow the progress of those critical tables, and may therefore lengthen the critical path.
If exported data has a more even distribution among tables, a higher number of threads generally will be better. However, it is recommended to not exceed the number of available CPU cores.
A note on multi-tenant tables¶
Based on the attributes set at the moment of creation, there are three kind of multi-tenant tables:Based on the 4GL table type and the FWD import
tenantMode parameter, we have the following matrix:
| Screen-shot at table creation | Table Type | Observations | FWD Import (with 9093a) |
|---|---|---|---|
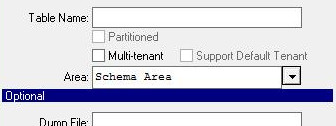 |
Single Tenant | tenantMode="none"✅ Will import all tables from available.d files, ignoring the MT annotations in .p2o file tenantMode="tenant"❌ Will NOT import these tables tenantMode="default"✅ Will import these tables tenantMode="strict"✅ Will import these tables |
|
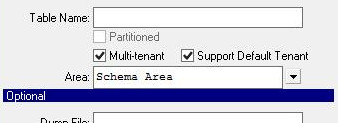 |
Multi-tenant with Default Tenant |
Notice the presence of Area entry.The Default tenant has it own image(set of records) of these tables. Your application does not access it, but it is there. |
tenantMode="none"✅ Will import all tables from available.d files, ignoring the MT annotations in .p2o filetenantMode="tenant"✅ FWD will import these files if .d is available.tenantMode="default"✅ FWD assumes the .d file from source directory belongs to Default tenant and will attempt to importtenantMode="strict"❌ Will NOT import these tables |
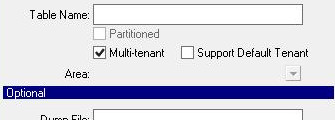 |
Multi-tenant without Default Tenant support |
The Area entry is absent since theDefault tenantwill not have access to this table. In this case, the table is marked as NO-DEFAULT-AREA in the .df file. |
tenantMode="none"✅ Will import all tables from available.d files, ignoring the MT annotations in .p2o filetenantMode="tenant"✅ FWD will import such table if the .d file is available.tenantMode="default"❌ FWD import WILL IGNORE the .d and skip importing these tables.tenantMode="strict"❌ Will NOT import these tables |
tenantMode:
| Mode | Value for tenantMode parameter (and aliases) |
Expected Result |
|---|---|---|
| Single Tenant | null / not specified / default valuealiases: "none", "no", "false" |
All tables and sequences are imported each time, regardless of the MT attributes. |
| Default Tenant | "default" |
Import all tables and sequences exported from a default tenant. This includes all elements accessible in this context: * tables and sequences which do not have multi-tenant annotation and* MT tables having a storage area specified (therefore they were accessible to default tenant). |
| Default Tenant (strict mode) |
"strict"alias: "strict-default" |
This restricts the previous mode by not allowing multi-tenant with support for default tenant tables, even if they were declared as such. |
| Tenant | "tenant"aliases: "yes", "true" |
Import only multi-tenant tables and sequences. All of these them, with or without a storage area set. |
Solving Character Encoding Problems¶
OpenEdge databases do not enforce character encoding. This means it is possible to insert invalid characters into a database that is nominally encoded with an incompatible codepage. We have seen this before when trying to import database dumps which declare to use a specific encoding, but have incompatible bytes (i.e. bytes without a character associated in that code page, in case of single byte charsets or invalid combinations of bytes in case of multi-byte charsets).
A second possible problem is that, even if the source is correctly encoded, the encoding of the target database will not be able to support all characters. For example, if the source is UTF-8, it is very likely that there will be characters which will not be supported by a single-byte CP, like ISO 8859-1.
- invalid CP: the import apparently finished with success, but some characters are incorrect. For example:
"hâ¢tâ¢eÅ HkJk"; - invalid CP: the import apparently finished with success. One extra record was inserted having
nullvalues for all columns but for first two (of typecharacter) which had"?"values; - invalid CP: the import stopped at first bytes, a single record was inserted with all columns set to
null. The tool did not report errors, just that an warning for failing to read the PSC footer and also the heuristics also no providing a valid file structure; - truncated file: import for the specific table stopped with
Error creating record #NNNNError processing import data; 1 record(s) uncommitted due to this error; 2 record(s) dropped. Cause: ** Attempt to read from closed stream . (1386). The records up-to the end of file were successfully imported. The other tables imported normally; - corrupted file: tool reports:
Error creating record #NNNN (0 previously dropped) [file offset: 0x00000000]. Cause: ** Invalid character in numeric input h. (76). The other tables were correctly imported. - bad layout (wrong table): same as above, no records imported.
For these reasons we developed the DatabaseDumpChecker utility application which can scan a database dump and report the 'bad bytes'. The result (file and offset) then can be inspected and the customer should choose a 'replacement' character for each of the invalid bytes. This process can be iterative. Finally, these mappings shall be added to p2j.cfg.xml in the byte-mapping parameter so that the import will use them to replace the bad bytes with their mapping on-the-fly, during the import.
The normal process flow would be:
- Run
DatabaseDumpCheckerwithout any byte mapping configuration. You can launch it from any directory because the fist parameter is location of.dfiles. The next two parameters are theCPfor read (decode from.d) and for write (simulates the SQL). The verbosity is the last mandatory parameter (a good default is 2). The application will output all bad bytes to the console and the first offset into the file to allow further investigation. Use value 3 for verbosity to get all offsets listed. Ignore the non-recoverable messages in this step (because no mapping was specified all errors are not recoverable). - Analyse the output and find the proper replacements for bad bytes. For example, one can use
0x3F, the normal question mark (?) as replacement for all bad bytes. Use them to update the command line for launchingDatabaseDumpChecker: pairs of hexadecimal values<bad> <new>. Ex:0x90 0x3F. You can use optional delimiter if you want to make the pair more visible (,,;). Run again and check if there are any messages about non-recoverable messages this time. If this is the case different replacement bytes might be needed. Repeat this step as necessary. - When
DatabaseDumpCheckerreports that all errors are recoverable by using the replacement bytes, use them to add/update the byte-mapping parameter in for the namespace the dump directory belongs to. - Run the import. Now there should be no encoding-related import errors.
Notes: this application is quite fast, it is limited only by the speed of your drive so the process, even if needs to be iterated, should not take too long.
Syntax for DatabaseDumpChecker is:
java DatabaseDumpChecker <dumpDir> <source-charset> <target-charset> <verbosity> <replacement-pairs>*
Where:
dumpDiris the directory where the dump files can be found. The utility will process all an only*.dfiles, ignoring all others;source-charsetthe name of Java Charset (it will be loaded withCharset.forName) to be used when reading the files (NOT the 4GL name). This is used to check the input file;target-charsetof the database. Also Java Charset. This is used to check whether the destination database is able to store the read data;verbosityas explained above. There are 4 possible values0=only summary,1=more details,2=recommended,3=list each error.replacement-pairs: optional pairs of mapped bytes. Multiple pairs of bytes (hexadecimal, no prefix). The pairs are separated by spaces. Ex:81:3F. These will be used in subsequent runs and will not be reported as errors.
How the p2j.cfg.xml should look:
<namespace name="hotel"...> ... <parameter name="byte-mapping" value="81:3F 90:3f 9D:3f" /> </namespace>
This will replace bad bytes in a CP like 1252 with ?. To drop these characters, use the following value instead: value="81: 90: 9D:". Each database/namespace can have customised byte maps.
Now when the import encounters a bad byte, it will report:
guest.d: Invalid byte 0x8d at offset 0x8106dbdf replaced with 0x3f guest.d: Invalid byte 0x90 at offset 0x92fdb241 was dropped.
Summary¶
At this point, you have migrated your application's data set into a new, working, database instance. Before proceeding further, it would be wise to make live and archival backups of this pristine database. Please refer to the vendor-specific database setup chapter for instructions on doing this for the particular database implementation you are using.
If you have successfully converted and built your entire application by this point, you are ready to configure your application to run in the FWD environment. If not, you can at least use your favorite SQL tool to connect to your database and browse through your data in its new home.
© 2004-2017 Golden Code Development Corporation. ALL RIGHTS RESERVED.