Profiling¶
- Profiling
Introduction¶
Profiling is the process and tools used for performance analysis of an application or piece of software. This involves executing the application while instrumented with performance probes (timing and counters) so that one can determine where the time is spent and focus on bottlenecks ("hotspots"). There are typically 2 modes: sampling mode and tracing mode. Sampling is less intrusive because it tries to limit its capture to just some representative results. Tracing mode is very intrusive, because it gives exact counts and timing. Sampling mode can give you an idea of what is going on but often the details are fuzzy/inexact. Tracing mode gives you the full picture but the application runs very slowly. The results are relatively correct but the time amounts are much longer than when there is no tracing.
Although VisualVM is included in the JDKs up to Java 8, it is not very useful for tracing mode profiling. We have found that in real applications, sometimes VisualVM will just freeze itself and the application. CPU sampling mode works OK and is useful for finding high-level hot spots, though it can be misleading at times. Information on VisualVM included in the JDK can be found at https://docs.oracle.com/javase/8/docs/technotes/guides/visualvm/.
In our experience, the commercial product Yourkit is significantly better for profiling. It requires running the target JVM with an agent. The absolute times are greatly inflated because of the profiling overhead, but the call counts and relative times seem quite accurate.
VisualVM can be useful for enabling and capturing the output of specific JMX MBean instrumentation that has been placed in the FWD code. These locations can be very useful for targeted measurement of performance and timing. See the
How to Enable Tracing¶
TBD
YourKit Java Profiler¶
The YourKit Java Profiler is able to do multiple kind of profiling tasks that will be explained in the following sections. The most common use-case is for the FWD server, identificable as ServerDriver in the list of monitoring applications.
- agent attaching, when YourKit will weakly connect to the Java application to profile and retrieve some vitals. This is not a costly operation.
- intrumentalization, when YourKit will actually weave tracing code into the loaded classes. This is a very costly operation
These two can be activated or deactivated at different moments through different interfaces.
Ways to profile¶
Attach at run-time¶
This is a dynamic mean of attaching the agent to an already running Java application from within the YourKit application. This is the trivial way to use YourKit from within a local development environment on which both YourKit and the FWD server runs. To do so, one should simply open the YourKit application and select the FWD server from the list of applications to monitor. Because the attaching happens at run-time, there will be a consistent delay in the attaching process as the agent is attached right at that time.
The attach will only attach the YourKit specifics into the FWD server. However, in order to start sampling, tracing, etc., one should enable it from the already opened GUI application.
Remote attach to Java process¶
TODO
Use YourKit at CLI¶
It is possible to configure YourKit at command line to directly add the agent to the FWD server, so it is loaded with the JVM.
TODO:- How to enable or disable tracing / sampling at a certain moment of time?
- How to do a snapshot?
Integration with IDE¶
Eclipse¶
Eclipse IDE allows integration with YourKit through a dedicated plug-in that should be installed from the Eclipse Marketplace. After installing, there will be a new option in the run menu (or toolbar) to start a Java process with YourKit agent. Editing the configuration allows enabling the profiler or choosing the profiler type: sampling, async. sampling, tracing, call counting, etc. Also, the YourKit will open at the same time as the FWD server that was opened from the IDE.
IntelliJ IDEA¶
TODO
Snapshots¶
YourKit snapshots are useful to persist the profling data. YourKit can be used to open such snapshots and analysze the profiling data after the FWD server has closed.
YourKit functionalities¶
CPU and Threads¶
The most basic views are over the CPU and Thread activity. The CPU view is the main screen that opens after attaching with YourKit agent in the GUI application. The Threads view can be toggled from the menu on the top of the screen. These views are not proving way more valuable that what VisualVM is able to do.
After attaching, the stack trace telemetry is enabled by default, lively tracking the states of the threads. This may slow down the profiler, so consider disabling if not needed.
Memory¶
The memory view is relevant to detect any potential memory leak or high work from the GC:- the "Memory Snapshot" functionality is similar to what Eclipse MAT does as it allows doing heap dumps and analyzing them.
- use this to spot potential memory leaks or structures with a high number of objects that should be optimized
- [requires intrumentalization] the "Object allocation recording" functionlity is quite unique as it allows tracking what object were created from the moment the feature was activated.
- use this to understand if the GC is stressed with a high number of allocations (that should be deallocated after)
Exceptions¶
The exceptions view is used to detect which exceptions were throws often after the agent was attached. This feature is enabled by default and may slow down the profiler. Considering disabling after attaching if not needed.- Use this insight to understand what FWD flows rely on exceptions and consider refactoring as stack-based behaviors (using
return) are more performant than exception unwinding (usingthrow)
CPU¶
This is the spot where YourKit excels: the CPU profiling. The profiling can be done using sampling, async. sampling, tracing and call counting (more information on these in the YourKit GUI). Out of these, sampling should be used for a fast approximate udnerstanding on where the CPU is spending time. This doesn't require instrumentalization, so it is able to provide quick insights. On the opposite, tracing should be used for an exact understanding on where the CPU is spending time. This requires instrumentalization and is a slower process by definition.
The screen that is most relevant for CPU profiling is "Method list". This will show only live data, but doesn't permit much in depth analysis.- It shows a list of all methods called in the FWD server and their Total time (spent in the method and called methods), Own time (spent only inside the method code) and Count (the number of times it was called). The times are aggregated, so each method will be shown only once.
- The information on the Total time, Own time, Count and Avg. time.
- For each method, we can retrieve more information about the control flow:
- "Back traces": from which method(s) was the analyzed method invoked, together with Time and Count information
- "Callee List": a list of methods that were hit after calling the analyzed method, together with Time, Own Time and Count
- "Merged Callees": a list of merged methods that follow right after the invocation of the analyzed method, togheter with Time, Own Time and Count
Hints: mind the recurssion scenarios; sometimes the aggregate times may not add up to the total time exactly due to recurssions.
As of version 2024.3, the settings to get a complete trace profiling are (at Settings -> CPU tracings... menu option):
time=cpu adaptive=false adaptive_min_method_invocation_count=20000 adaptive_max_average_method_time_ns=1000 adaptive_min_method_time_percent=0.1
This captures real CPU time and disables adaptive tracing.
Database¶
This is part of a profiling snapshot that should be done according to theCPU section. Such view is generating a comprehensive report on what SQL statements were called, how time consuming they were, how many times were executed, etc. Also, there is an important feedback on the place from which the SQL was called.
- This should be used to indentify slow running queries that have the potential to be optimized
- This can also provide an insight on statements that were run multiple times and have potential to be optimized to avoid database chattiness
Events¶
This is part of a profiling snapshot that should be done according to theCPU section. Such view shows the IO time invested by the CPU. This should be carefully analyzed in regard to DB work, socket work or file work.
- The SQLs are analyzed and grouped by connections. Ideally, all SQL statements should have been prepared and there should be close to no duplicated prepared statements (i.e. with same SQL statement).
- Sockets and Files can be analyzed to understand how FWD is doing its IO work.
- Events is also shows the class loading process.
Analysis Tips¶
Merged Callees¶
This section is specific to Yourkit.
A very useful view is the Merged Callees tree, where you can manually expand the nodes that are time consuming. This is taken from a CPU profiling snapshot, captured in tracing mode (not async sampling mode). This is the slowest mode, but it's not too bad when you are tracing a well-defined, relatively short operation, like opening a single screen.
After capturing and opening the snapshot, open either the Hot spots or the Method list views, select a method in the top part of the screen, then select the Merged Callees view in the bottom part of the screen. From there, you can open/close individual nodes in the tree.
How to Find a Problematic Method¶
Sometimes a problematic method may be difficult to find. For example, it may not appear in a list of hotspots but it could still be a significant bottleneck (in Yourkit, items in Method list which are not mentioned in the Hot spots window).
One can look for methods which consume higher than some threshold of the overall, aggregate time. Initial analysis will use a threshold somewhere between 5-10%, which generally will appear as a hotspot (in Yourkit they will appear in the Hot spots view). As fixes are incorporated, the most obvious items will be removed. This makes the bottlenecks less obvious to find. Thar means the threshold will be reduced and at that point one might look for methods that are at least 1-3% of the overall aggregate time.
Bottlenecks in FWD¶
When profiling FWD itself, one will usually ignore the runtime methods whose main purpose it is to invoke converted business logic, like the ControlFlowOps.invoke*() methods or the BlockManager workers. Those methods are hard to navigate, because the call tree from those points downward is very deep.
Focus on methods which actually result in work which takes a long time in the FWD runtime itself, or in third party code called from FWD (e.g. H2).
In Yourkit, there is also SQL information ("Events -> Events by Table"), to find slow queries, to see if there is something wrong with the way the query is formed. YourKit records the SQL that was executed, but unfortunately not the substitution parameters that were passed.
Bottlenecks in Converted Code¶
The same techniques described above can be used with the converted code (which is just Java after all). The key difference is that one may want to exclude the FWD runtime classes from the analysis so that it does not obscure the application code bottlenecks. The FWD runtime will be involved with everything being processed in the converted code. If it is not excluded then the hotspots may appear to be in FWD instead of the application.
TBD: add more details here.
JDK Mission Control (JMC)¶
Installation¶
JDK Mission Control version 9 can be installed from https://www.oracle.com/java/technologies/javase/products-jmc9-downloads.html, Linux x64 Compressed Archive - 92.45 MB - jmc-9.0.0_linux-x64.tar.gz should be installed.
- Unzip the archive:
tar -xvzf jmc-9.0.0_linux-x64.tar.gz
- Create a run script (running JMC requires Java 17)
cd jmc-9.0.0_linux-x64/JDK\ Mission\ Control touch jmc.sh chmod 700 jmc.sh
Open the file with any editor and add:./jmc -vm /usr/lib/jvm/java-17-openjdk-amd64/bin/java
Additional configuration.¶
In the previously created script, we can add additional VM arguments using-vmargs:
-XX:+UnlockDiagnosticVMOptions -XX:+DebugNonSafepoints- unlocks additional options for diagnosing faults or performance problems with the JVM andDebugNonSafePointsimproves the method profiling data accuracy (those options also introduce overhead)-XX:+FlightRecorder -XX:FlightRecorderOptions=stackdepth=256- JMC truncates all stack traces in the recording to the default depth of 64, this option increases the stack depth that is saved (most truncated logs can occur for important events such as Allocation in new TLAB, Java Error, Java Exception, Method Profiling Sample, Old Object Sample).
In the end, the script should be:
./jmc -vm /usr/lib/jvm/java-17-openjdk-amd64/bin/java -vmargs -XX:+UnlockDiagnosticVMOptions -XX:+DebugNonSafepoints -XX:+FlightRecorder -XX:FlightRecorderOptions=stackdepth=256
Important: The options do not seem to work after being tested.
Usage¶
1. Quick Steps: JVM Browser -> Choose JVM -> Right click Flight Recorder -> Start Flight Recording -> Finish -> Right click the new recording -> Stop -> Right click the recording again -> Dump whole recording
- Choose if the recording is a Time fixed recording or a Continuous recording (for profiling purposes, is is better to use a Continuous recording because it allows the user to stop the recording at any point)
- Create a new Template by going into the Template Manager, the new template can then be edited by clicking Edit (for a more detailed configuration, press Advanced in the Edit window)
- Garbage Collection: Normal (Garbage collection performed by the JVM - cause, longest pause and sum of pauses)
- Memory Profiling: All, including Heap Statistics (May cause long full GCs)
- Compiler: Off
- Method Sampling: Normal, but depending on the scenario Ludicrous (High Overhead) can be used
- Thread Dump: Every 60s / Every 10s, but depending on the scenario Every 1s (High Overhead) can be used (Periodic thread dumps - normal textual thread dumps)
- Exceptions: Off
- Memory Leak Detection: Object Types + Allocation Stack Traces + Path to GC Root
- Synchronization Threshold: 10ms (Events above 10ms are collected, so if a thread waits for a lock more than 10ms, an event is saved)
- File I/O Threshold: 10ms
- Socket I/O Threshold: 10ms
- Class Loading: Unchecked
- Flight Recorder (for profiling purposes, those event types should be disabled entirely)
- Java Application
- Statistics - each option should be enabled except Direct Buffer Statistics
- Allocation in new TLAB (Thread Local Allocation Buffer) - enabled + stack traces. Each thread in a java application has its own TLAB and it represents a thread-specific portion of the Eden space in the heap (when an object is created, the memory will allocated from the Eden space). TLABs are used to reduce overhead when creating multiple threads are allocating objects concurrently.
- Allocation outside TLAB (Thread Local Allocation Buffer) - enabled + stack traces. When a thread's TLAB is full or the object allocated is too large to fit in the TLAB, the allocation is done directly in the Eden space outside of any TLAB. (it is a more expensive operation)
- File Force - disabled
- File Read - disabled
- File Write - disabled
- Java Error - enabled + stack traces.
- Java Exception - enabled + stack traces.
- Java Monitor Blocked - enabled + stack traces. Events related to blocked monitors.
- Java Monitor Inflated - enabled + stack traces. Events related to inflated monitors (multiple threads are trying to acquire the same lock)
- Java Monitor Wait - enabled + stack trace. Events related to waiting on a monitor.
- Java Thread End - enabled
- Java Thread Park - enabled + stack traces
- Java Thread Sleep - enabled + stack traces
- Java Thread Start - enabled + stack traces
- Object Allocation Sample - enabled + stack traces
- Socket Read - disabled
- Socket Write - disabled
- Java Development Kit (for profiling purposes, those event types should be disabled entirely)
- Java Virtual Machine
- Class Loading - each option should be disabled
- Code Cache - each option should be disabled. It is related to Just-In-Time compilation, this is where the JIT compiled code is stored.
- Code Sweeper - each option should be disabled.
- Compiler - each option should be disabled.
- Diagnostics - each option should be disabled.
- Flag - each option should be disabled.
- GC - each option should be enabled, but do take a look at the Detailed Events where some events are not necessary.
- Profiling - each option should be enabled.
- Runtime - The only options that should be enabled are Safepoint (entirely), JVM Shutdown, Native Library, Reserved Stack Activation (reserved space on thread stacks that helps them complete when a stack overflows occurs), Thread Dump and VM Operation.
- Initial System Property
- JVM Information
- Operating System
- File System - disabled
- Memory - Only enable Physical Memory
- Network - enable Network Utilization
- Processor - enable all options
- Container Configuration - disabled
- Initial Environment Variable - enabled
- OS Information - enabled
- Process Start - disabled
- System Process - enabled
- Virtualization Information - disabled
- jdk (for profiling purposes, those event types should be disabled entirely)
Important notes, tips and discoveries.¶
- There is a limit to
Continuous recordings, it will always save the latest data and will write it to a global buffer which will discard the oldest data when it fills up, the size of this global buffer is unknown.
JMX MBean Instrumentation¶
Introduction¶
For an introduction to MBeans see https://www.baeldung.com/java-management-extensions
The JMX MBean infrastructure and some instrumentation was added to FWD v4 starting in task branch 3821c revision 11645 (see #4785-746 and the following notes). It will be further enhanced in #1849.
Design¶
There are several types of counters defined in thecom.goldencode.p2j.jmx package.
SimpleLongCounter- contains twolongfields. Theupdateoperation accepts alongargument. The value of the argument is added to thetotalfield. Thecountfield is incremented by 1.SimpleMapCounter- holds a map of namedSimpleLongCountercounters. Anupdateoperation provides a name of the counter and alongupdate for it.NanoCounter- a counter for measuring execution times. Contains the same fields asSimpleLongCounterbut contains atimermethod which accepts anOperation(a Functional interface that is a 'Runnable that can throw Exception'). The operation is called and the elapsed time is used to update the values oftotalandcount. See theServerStateclass for an example.
NANO_TIMER.timer(() -> setWidgetAttrs((Object[])PayloadSerializer.readPayload(in)));
Every instance of the counter contains its own enabled flag to minimize the overhead for checking if it is enabled. The MBean propagates the changes of this flag to all its instances on update. See Facultative class implementation for the details. So when all MBeans are disabled the runtime overhead is negligible.
Usage¶
By default all counters are disabled. To enable you can use VisualVM with the VisualVM-MBeans plugin. It is also possible to use JConsole but it is more effort. These instructions will demonstrate usage with VisualVM.
You have to install the VisualVM-MBeans plugin. Open Tools->Plusins menu and add VisialVM-MBeans plugin if it is not yet installed:
Steps:
1. Connect to a process.
Start VisualVM, select the process, and double click on it. See the screenshot below
2. Switch to the MBeans tab.
FWD MBeans are under com.goldencode.p2j.. For a specific counter, you can see values in the Attributes tab. 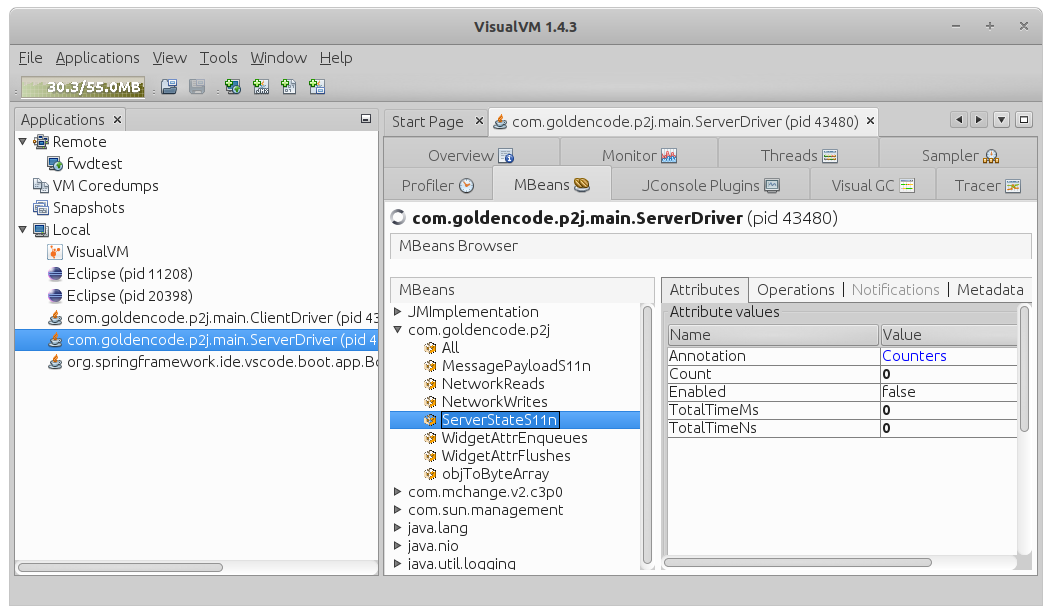
3. Enable/Disable/Reset/Print Counters
In the Operations tab, you can enable/disable/reset the counter. In this tab, you can also print value(s) to a specified file. If the file already exists, the new data will be appended. The value of the Annotation attribute will be included in the output.
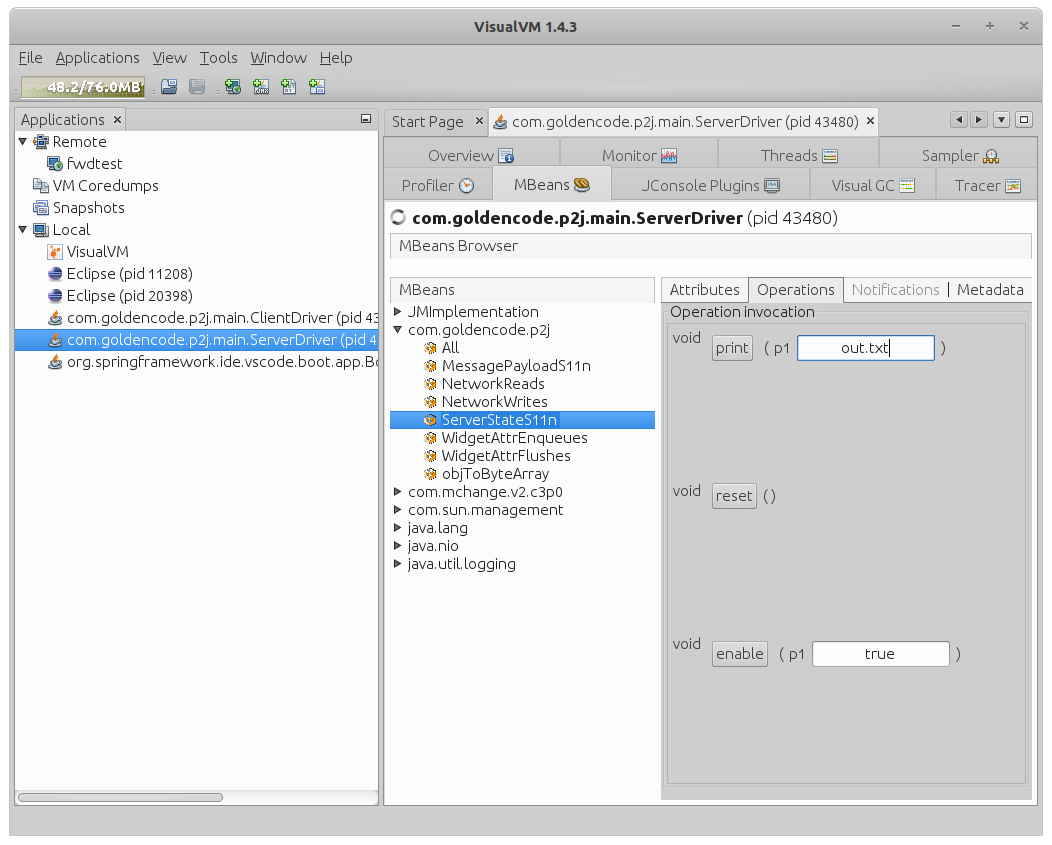
The All section allows one to change annotation and enable/disable/reset/print all defined counters in one operation.
Adding Tracepoints¶
To add a new instrumentation location, just add a new member to the corresponding enum in the FwdJMX class and modify the application code to use it.
For example, imagine that we want to measure how much CPU time takes the decryption of the SSL traffic. More specifically - the total CPU time consumed by the SSL.unwrap() method which is called in the SSL.doUnwrap() method:
unwrapResult = engine.unwrap(outUnwrap, inpUnwrap);
We have to do the following:
- Add sslUnwrap member to the
FwdJMX.TimeStatenum./** ServerStat.widgetAttrs (de)serialization */ ServerStateS11n, /** Message.payload (de)serialization */ MessagePayloadS11n, /** Protocol.objToByteArray */ objToByteArray, /** SSL.doUnwrap */ sslUnwrap; - Define a static member
private static final NanoTimer UNWRAP_TIMER = NanoTimer.getInstance(FwdJMX.TimeStat.sslUnwrap);in theSSLclass. - Replace
unwrapResult = engine.unwrap(outUnwrap, inpUnwrap);
withAtomicReference<SSLEngineResult> holder = new AtomicReference<>(); UNWRAP_TIMER.timer(() -> holder.set(engine.unwrap(outUnwrap, inpUnwrap))); unwrapResult = holder.get();
What was described above in this section works for 'general purpose' counters which are supposed to be used in different situaions.However there can be more specific requirements. In this case one can define a special MBean and its implementation and register it using FwdJMX.register call.
See e.g. the instrumentation of the LockTableUpdater using LockTableUpdaterStatMBean and LockTableUpdaterStat.
JMX Instrumentation Types¶
FWD provides JMX instrumentation to measure various parts of the FWD runtime, grouped under the com.goldencode.p2j name. There is a MBean named All, which provides operations to:
dumpAll(String), write all the JMX instrumentation to a file.resetAll(), to reset all metrics which are not live representation (timers, counters, etc).enableAll(boolean), to enable or disable all metrics which are not a live representation (timers, counters, etc).
The basic JMX metrics defined by p2j.jmx.FwdJMX class are:
TimeStat¶
This is referenced as TIMER in this documentation, with these attributes and operations:
| Attribute | Type | Description |
|---|---|---|
Enabled |
boolean | The metric's state - enabled or disabled. |
Count |
long | The number of executions of this metric. |
TotalTimeMs |
long | Total execution time, in milliseconds. |
TotalTimeNs |
long | Total execution time, in nanoseconds. |
| Operation | Description |
|---|---|
void print(String) |
Dump this metric to the specified file. |
void reset() |
Reset this metric. |
void enable(boolean) |
Enable or disable this metric. |
Counter¶
This is referenced as COUNTER in this documentation, with these cases attributes and operations:
| Attribute | Type | Description |
|---|---|---|
Enabled |
boolean | The metric's state - enabled or disabled. |
Count |
long | The number of executions of this metric. |
Total |
long | Total aggregated value of this metric. |
| Operation | Description |
|---|---|
void print(String) |
Dump this metric to the specified file. |
void reset() |
Reset this metric. |
void enable(boolean) |
Enable or disable this metric. |
MapCounter¶
This is referenced as MAP in this documentation, with these cases attributes and operations:
| Attribute | Type | Description |
|---|---|---|
Enabled |
boolean | The metric's state - enabled or disabled. |
Count |
long | The number of executions of this metric. |
Total |
long | Total aggregated value of this metric. |
Values |
Map<String, Long> | Aggregated value of this metric, by a specific key. |
| Operation | Description |
|---|---|
void print(String) |
Dump this metric to the specified file. |
void reset() |
Reset this metric. |
void enable(boolean) |
Enable or disable this metric. |
QueryProfiler¶
This is referenced as QUERY in this documentation, a custom metric with these attributes and operations:
| Attribute | Type | Description |
|---|---|---|
Enabled |
boolean | The metric's state - enabled or disabled. |
QueryCount |
long | The number of executed queries. |
Values |
Map<String, Map<String, Long>> | For each query, its aggregated value for: * ROWS_COUNT, number of returned rows * CACHE_HITS, number of records read from cache. * CACHE_MISSES, number of records read from the table. * HYDRATE_TOTAL_TIME, total time in nanos spent in hydrating a record. |
| Operation | Description |
|---|---|
void print(String) |
Dump this metric to the specified file. |
void reset() |
Reset this metric. |
void enable(boolean) |
Enable or disable this metric. |
LockTableUpdaterStat¶
This is referenced as LOCK in this documentation, a custom metric to track, for each connected database, the access to the meta _lock table.
| Attribute | Type | Description |
|---|---|---|
ActiveLocks |
long | Get number of active locks |
DeletesFromVST |
long | Get number of VST records deleted not in batch. |
LockEvents |
long | Get number of processed lock events. |
PersistCalls |
long | Get the number of calls to persist locks to the meta database |
PersistedLocks |
long | Get number of locks in VST. |
| Operation | Description |
|---|---|
void flush() |
Persist locks to the meta database. |
Available Instrumentation Points¶
See Monitoring.
Persistence Subsystem Method Tracing¶
The purpose of this feature set is to enable method-level tracing, to determine where in the persistence runtime implementation time is being spent, without the full overhead and resource requirements of CPU tracing. Time spent is measured upon entry and exit of a method, and is aggregated at the package level, for a set of specified packages. This coarse-grained approach is not meant to be a substitute for CPU tracing with a commercial profiler; rather, it is intended to help the user understand in which packages/subsystems in the persistence layer of FWD relative time is being spent, to direct further analysis of expensive areas.
The implementation uses AspectJ to instrument certain sets of methods, collecting elapsed time information for the methods which serve as entry points into a package/subsystem, and the method hierarchy called by those methods. A post-processing step aggregates the data by package, in order to determine relative elapsed time spent in those call paths.
While this approach has considerably lower overhead than CPU tracing, the overhead is still significant, so this tracing should not be enabled in production! Time measurements in absolute terms will reflect this overhead and should not be interpreted as the "real" time that would be spent if tracing were disabled. However, time measurements relative to each other should provide a reasonably accurate depiction of where time is being spent.
Setup¶
When setting up Method Tracing, changes to thedeploy/server/server.sh need to be made:
- Create a variable called
agentand assign an empty string.agent=""
- In the while loop that processes the options, make available the following options
-a,-m1and-m0by modifying":dyptksw1z:h:l:c:i:b:"
to":dyptksw1az:h:l:c:i:b:m:"
Theaoption will enable the agent for method profiling and themwill toggle between starting/stopping the collection of data from method profiling.
Add the two options in the while loop:m ) mode="-m$OPTARG"; trace=1; statcode="y" ;; a ) agent="-javaagent:../lib/aspectjweaver-1.8.10.jar" ;;
Themwill assign the existentmodevariable andawill assign theagentvariable declared previously. - Where the P2J server is executed, add the agent value as JVM parameter. Make sure
modeis used as Java parameter.$prog $hprof $maxheap $srvr $dtxt $agent $spi $cpath -Djava.system.class.loader=com.goldencode.p2j.classloader.MultiClassLoader com.goldencode.p2j.main.ServerDriver $mode $batch $cfg $port "$@"
Enabling/Disabling at Runtime¶
Method tracing is disabled by default, so running./server.sh normally will not be affected.In order to enable method tracing in a project, the following commands should be executed:
- Start a server using
./server.sh -a. The-aoption will make method tracing available. AspectJ load-time weaving is used when-ais provided; otherwise the tracing aspect will not be loaded at all.
The following options must be run from a separate command line and will remotely attach to the server running under the same instance number.
- After the server has started completely, you can run
./server.sh -m1. The-m1option will turn on active tracing on the target server. This is not meant to stay opened; it only enabled the method tracing on the target server. - In order to turn off active tracing, use
./server.sh -m0. This command can be ran at any time while the server is open and it will generate atrace.csvindeploy/serverfolder.
Use LibreOffice or any tool to view the contents of the trace.csv file.
For more information related to Method Tracing usage, refer to #4056, respectively #4056-12.
Interpreting the CSV Results¶
Results are split in a fairly complex (yet insightful) manner based on scenarios and buckets. These two concepts are orthogonal, so we can compute statistics on one depending on the another.- The results contain an aggregate of all calls into the traced packages.
- The results are split in multiple scenarios separated by an empty line.
- A single scenario is an unit of high-cohesion calls inside the traced packages. Basically, the traced methods in a scenario are the ones used in the back-stage by an interaction with the FWD API.
- The methods from a scenario are split into buckets (usually packages). This is done to logically separate the interaction between the persistence layer, the ORM, c3p0, H2 and persistent database.
- Each bucket is computing statistics.
- There are final statistics across all scenarios.
- Count: The number of times it was called.
- Agg Time (nano): The aggregate time in nanoseconds spent in this method (including sub-calls) - default sorting (descending)
- % of Total: The ratio between the aggregate time spent in this method (including sub-calls) and the total time spent in the scenario. The root method always has this value set on 1.
- Own Time (nano): The aggregate time in nanoseconds spent in this method (excluding sub-calls)
- % of Total: The ratio between the aggregate time spent in this method (excluding sub-calls) and the total time spent in the scenario.
- % of Grand Total: The ratio between the aggregate time spent in this method (excluding sub-calls) and the total time spent across all scenarios.
- Own Time (nano): The time spent exclusively in this bucket
- % of Total: The ratio between the time spent in this bucket and the total time spent in all buckets of the scenario.
- % of Grand Total: The ratio between the time spent in this bucket and the total time spent across all scenarios.
- Agg Own Time (nano): The aggregate time spent in the bucket across all scenarios
- % of Grand Total: The ratio between the aggregate time spent in the bucket and the total time of the tracing
Using a Spreadsheet to Aggregate and Analyze the CSV Output
Using the HTML UI to Interpret Results¶
After executing./server.sh -m0, beside the trace.csv file, a HTML UI is generated. Inside deploy/server/trace there are generated files which can be used to visualize the method tracing data:
index.htmlis the root file to be opened to visualize data. The Web page should be simple to use- The left menu presents the root of the traced scenarios. Each such link opens a different scenario.
- The top menu presents the bucket traced.
- The table in the middle is the data from the selected scenario for the selected bucket.
datacontains the server-side exported data regarding method tracing. Each folder inside is the root of a scenario. Each such folder has a JS per bucket which is included in theindex.htmlfile.data/meta.jshas information about overall statistics like: the name of the buckets, the name of the roots and the total elapsed timejs/loader.jsis responsible for initializing the trace data for each scenario. This is the first JS which should be included in theindex.htmlfile.js/trace.jsis copied here as a resource and provides the basic functionality for the interface.css/bootstrap.min.cssis a bootstrap CSS used for interface styling.
Example of Using Method Tracing on Hotel GUI¶
Right now (Hotel_GUI rev. 252), the project is configured to allow-a and -m options. In order to retrieve some information on method tracing for the Hotel GUI project, one should run:
./deploy/server/server.sh -ato start the server with LTW- open a client using
./deploy/client/client.shand go to place in application, which should be traced. ./deploy/server/server.sh -m1to start tracing- do the scenario for which the tracing is intended
./deploy/server/server.sh -m0to stop tracing- consult
trace.csv
The trace_hotel_gui.csv results file is attached as an example. It was generated by tracing the login and some basic operations inside Hotel GUI.
Comparing Results¶
The most simple way of comparing results is by retrieving the CSV or HTML UI from two executions of the same scenario inside the target application.
These should be compared side-by-side as they usually generate the same scenarios/method tracing.
*TODO: think of a better way to display the performance delta between two H2 version. Maybe the HTML UI can be extended to load 2 data folders and compute delta.
Result-set Invalidation Tracing¶
AdaptiveQuery tracing is enabled/disabled together with Method Tracing.
adaptive.csv and are split into two categories:
- per query information
Each query displays data about it's state and methods called:- The procedure where the
AdaptiveQuerywas defined (from the converted application). - Number of tables joined.
- Scrolling status.
- Number of calls to a few important methods (
invalidation,revalidation, etc.) - Ratio between the
invalidateandstateChangedmethods. - Ratio between the return type of the
doubleCheckInvalidationmethod (true/false). - A table containing predefined methods in which information about the total number of calls, calls before the first invalidation, calls between the first invalidation until the next revalidation, number of calls in preselect/dynamic mode, time executed in these two modes, percentage from the total number of calls of the methods called in these modes and total time executed by each method traced.
- The procedure where the
- overview information
- Total number of queries.
- Total number of invalidated queries.
- Number of calls to a few important methods (
invalidation,revalidation) and an average per query value for each one. - Number of method calls made by all the queries.
- Number of scrolling/non-scrolling queries.
- A total table that sums the table defined for each query, but displays the average value obtained from all the queries for most of the values obtained from each query.
- A parent calls table with the purpose of displaying the number of AdaptiveQueries generated by a procedure.
adaptive.csv file can be influenced by two final values declared in the AdaptiveQuery tracing class:
OUTPUT_ALL_QUERIES: Controls the displayed queries. When set to false, only queries that were invalidated are displayed. This flag provides easier access to important queries when tracing in a large application and is set to false by default.PARENT_CALL_AMOUNT_LIMIT: Threshold representing the minimum amount of queries that a procedure call needs to generate in order to be displayed in the parent calls table. By default this value is set to 3.
Analyzing Large Heap Dumps¶
For large heap dumps, it may not be possible to load them with jhat or similar tools, for live OQL analysis, as the memory requirements may exceed the available RAM on the machine (for example, a binary file of 27GB was created when dumping 17GB of heap used by the FWD server, and this couldn't be loaded with jhat even if it was allowed to use 55GB of RAM).
It is possible to analyze these large heap dumps using Eclipse MAT, available here: https://www.eclipse.org/mat/downloads.php
Download and extract the Linux (x86_64/GTK+) version int ~/apps/mat. Edit the ~/apps/mat/MemoryAnalyzer.ini and add these parameters (adjust the Xmx and Xms accordingly to your system):
-vmargs -Xms26144m -Xmx48192m -XX:+UseConcMarkSweepGC -XX:+CMSParallelRemarkEnabled -XX:+CMSClassUnloadingEnabled -XX:+UseCMSInitiatingOccupancyOnly
Note that Eclipse MAT requires Java 11 or above to run. You will need to install a (non-default) JDK 11 and edit ~/apps/mat/ParseHeapDump.sh to add these lines, so MAT will use Java 11:
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64/ export PATH=$JAVA_HOME/bin:$PATH java --versionOnce Eclipse MAT is installed and configured, follow these steps:
- run the application scenario which is suspected of a memory leak, or other 'stress test' scenario. Wait for it to finish completely. Leave the FWD server running, if possible.
- dump the FWD server heap:
jmap -dump:format=b,file=$PWD/heap_dump_PID.hprof PID
wherePIDis the process ID for the FWD server. - analyze this heap dump file with MAT:
cd ~/apps/mat ./ParseHeapDump.sh /path/to/heap_dump_PID.hprof org.eclipse.mat.api:suspects
whereheap_file.hprofis the heap you want to analyze.
- look where these instances are kept in FWD
- attach a debugger to the FWD server
- add breakpoints where these instances are created or added to collections
- run the original scenario, wait for the breakpoint to hit and check if the collection where the instance is added contains a runaway number of instances
- repeat as necessary
ParseHeapDump.sh are (from https://wiki.eclipse.org/MemoryAnalyzer/FAQ):
org.eclipse.mat.api:suspectsargument creates a ZIP file containing the leak suspect report. This argument is optional.org.eclipse.mat.api:overviewargument creates a ZIP file containing the overview report. This argument is optional.org.eclipse.mat.api:top_componentsargument creates a ZIP file containing the top components report. This argument is optional.
Once these reports are generated, you can open the heap dump in Eclipse MAT - create a script with a content like this, so Java 11 is used:
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64/ export PATH=$JAVA_HOME/bin:$PATH java --version "$(dirname -- "$0")"/MemoryAnalyzer
And open the heap file.
----
Profiling through Persistence Loggers¶
One may use configurations specific to SQLStatementLogger or P2JQueryLogger in order to profile various SQLs or P2JQueries. These will be placed in the directory, under the persistence tag for global profiling, or under the database/<database-name> tag for database-specific profiling.
More information on what else can be logged can be found in PersistenceLogger.
SQLStatementLogger¶
An example of configuration for SQL profiling:
<node class="container" name="sql-logging">
<node class="boolean" name="enabled">
<node-attribute name="value" value="TRUE"/>
</node>
<node class="boolean" name="profiling">
<node-attribute name="value" value="TRUE"/>
</node>
<node class="double" name="min-time-threshold">
<node-attribute name="value" value="0.5"/>
</node>
<node class="string" name="output-to-file">
<node-attribute name="value" value="sql_%db.log"/>
</node>
<node class="container" name="output-to-db">
<node class="boolean" name="enabled">
<node-attribute name="value" value="TRUE"/>
</node>
<node class="string" name="db-name">
<node-attribute name="value" value="sql_%db_%as"/>
</node>
<node class="string" name="db-user">
<node-attribute name="value" value="user"/>
</node>
<node class="string" name="db-pass">
<node-attribute name="value" value="pass"/>
</node>
</node>
</node>
In the above example, SQLs that are slower than 0.5 milliseconds will be logged in database-specific files (.log), as well as in a h2 database.
P2JQueryLogger¶
An example of configuration for P2JQuery profiling:
<node class="container" name="p2j-query-logging">
<node class="boolean" name="enabled">
<node-attribute name="value" value="TRUE"/>
</node>
<node class="integer" name="processed-components">
<node-attribute name="value" value="1"/>
</node>
<node class="boolean" name="profiling">
<node-attribute name="value" value="TRUE"/>
</node>
<node class="double" name="min-time-threshold">
<node-attribute name="value" value="0.01"/>
</node>
<node class="string" name="output-to-file">
<node-attribute name="value" value="p2j-query_%db.log"/>
</node>
<node class="container" name="output-to-db">
<node class="boolean" name="enabled">
<node-attribute name="value" value="TRUE"/>
</node>
<node class="string" name="db-name">
<node-attribute name="value" value="p2j_%db_%as"/>
</node>
<node class="string" name="db-user">
<node-attribute name="value" value="user"/>
</node>
<node class="string" name="db-pass">
<node-attribute name="value" value="pass"/>
</node>
</node>
</node>
In the above example, P2J Queries that are slower than 0.01 milliseconds will be logged in database-specific files (.log), as well as in a h2 database.
Using EXPLAIN to Analyze SQL Performance¶
The SQL EXPLAIN directive can be used to determine details about how the database engine will handle a specific SQL query. It requires using the PostgreSQL console (psql).
It is important to follow this process so that the results most closely match how FWD uses SQL. Without the prepared statement, the results may differ from what will happen at runtime.
The process:
PREPAREto prepare the statement/plan.EXPLAIN [ANALYZE] EXECUTEto get the explain output for the execution of the prepared statement.DEALLOCATEto free the prepared statement/plan's resources.
Here's an example of a query on the p2j_test.person table, where the 1st substitution parameter is an int, the 2nd is a string, and the 3rd is an int:
p2j_test=> prepare q1 (int, text, int) as select id from person p where p.emp_num = $1 and upper(rtrim(p.last_name)) = $2 order by p.ssn asc limit $3;
PREPARE
p2j_test=> explain analyze execute q1 (200, 'BARNS', 1);
QUERY PLAN
---------------------------------------------------------------------------------------------------------------
Limit (cost=1.17..1.17 rows=1 width=40) (actual time=0.086..0.086 rows=1 loops=1)
-> Sort (cost=1.17..1.17 rows=1 width=40) (actual time=0.084..0.084 rows=1 loops=1)
Sort Key: ssn
Sort Method: quicksort Memory: 25kB
-> Seq Scan on person p (cost=0.00..1.16 rows=1 width=40) (actual time=0.022..0.026 rows=1 loops=1)
Filter: ((emp_num = 200) AND (upper(rtrim(last_name)) = 'BARNS'::text))
Rows Removed by Filter: 7
Execution time: 0.168 ms
(8 rows)
Then, when you're done with the prepared query q1:
deallocate q1;
or just disconnect psql.
Usage statistics in PostgreSQL¶
The PostgreSQL statistics collector is a built-in subsystem that gathers and tracks real-time performance data about database activity. It collects stats like:
- Table and index usage (e.g. scans, reads, writes)
- Function calls
- I/O activity
- Row operations (inserts, updates, deletes)
These statistics help database administrators and developers monitor performance, tune queries, and optimize indexes. Here are some examples:
SELECT relname AS table_name, seq_scan, seq_tup_read, idx_scan, idx_tup_fetch, n_tup_ins AS inserts, n_tup_upd AS updates, n_tup_del AS deletes FROM pg_stat_user_tables ORDER BY seq_tup_read + idx_tup_fetch DESC limit 10;Retrieves the top 10 most-read tables (by row reads) in PostgreSQL using statistics from pg_stat_user_tables.
It lists for each table:
- seq_scan: Number of sequential scans.
- seq_tup_read: Rows read via sequential scans.
- idx_scan: Number of index scans.
- idx_tup_fetch: Rows fetched via index scans.
- inserts / updates / deletes: Number of write operations.
SELECT relname AS table_name, seq_scan, seq_tup_read, idx_scan, idx_tup_fetch, n_tup_ins AS inserts, n_tup_upd AS updates, n_tup_del AS deletes FROM pg_stat_user_tables where relname = 'sometable' or relname = 'othertable' ORDER BY seq_tup_read + idx_tup_fetch DESC;Retrieves usage statistics for specified tables from the PostgreSQL system view pg_stat_user_tables.
For each of these tables, it shows:
- seq_scan: Number of times a full-table scan (sequential scan) occurred.
- seq_tup_read: Total rows read by sequential scans.
- idx_scan: Number of times an index scan occurred.
- idx_tup_fetch: Total rows fetched using indexes.
- inserts / updates / deletes: Number of row-level write operations.
Then it orders the results by total rows read (from either sequential or index scan), descending, so the busiest table appears first.
SELECT pg_stat_reset();
Reset all collected statistics for the entire database cluster.
© 2020-2025 Golden Code Development Corporation. ALL RIGHTS RESERVED.
VisualVMplugins.png (61.8 KB)
FWDMBeans.png (128 KB)
MBeansOps.png (127 KB)
hotel_trace.csv  (268 KB)
(268 KB)
subtotals_example.png (43 KB)
libreoffice_regex_in_formula.png (95.8 KB)