Runtime Architecture¶
Overview¶
This chapter explores the high level design of the FWD runtime technology. This runtime is necessary to execute the converted Java application as a drop-in replacement for the original Progress environment.
The FWD conversion process transforms a Progress ABL application into a pure Java equivalent. Among other artifacts, the results of the automated conversion process include:
- one or more
jarfiles with the compiled, pure Java equivalent of the application; - a Relational Database Management System (RDBMS) instance loaded with the database schema and the imported application data.
This resulting Java application is dependent upon and executed using the FWD runtime.
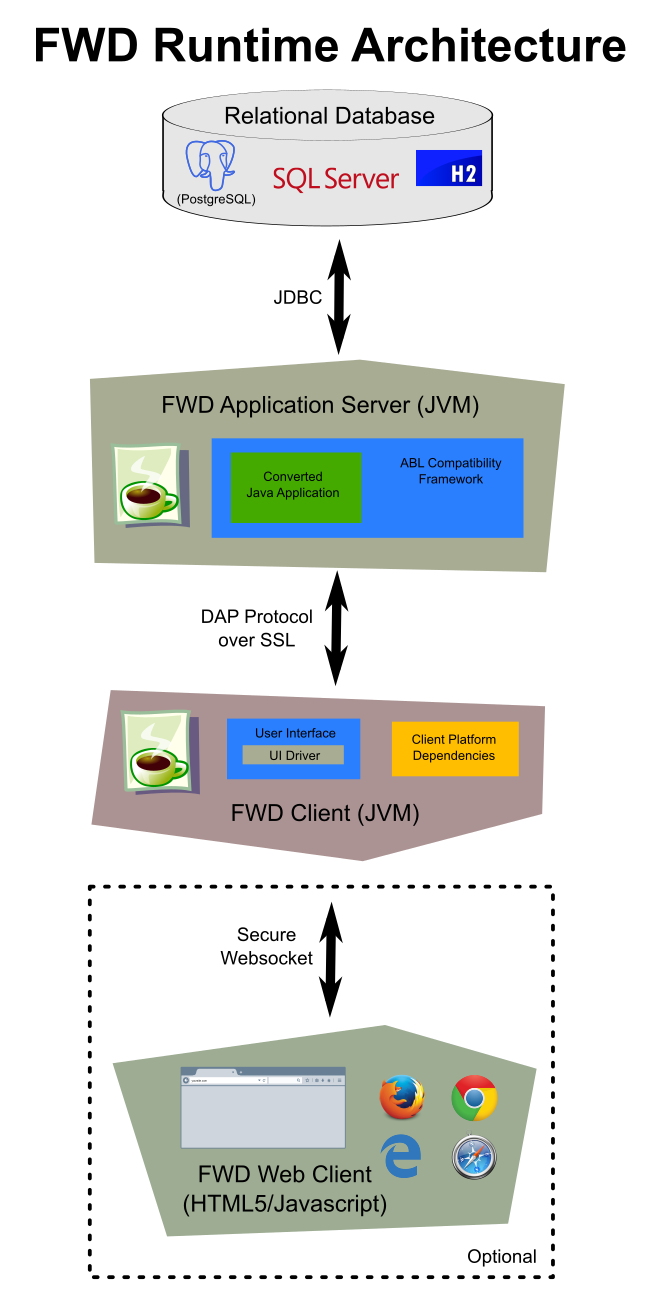
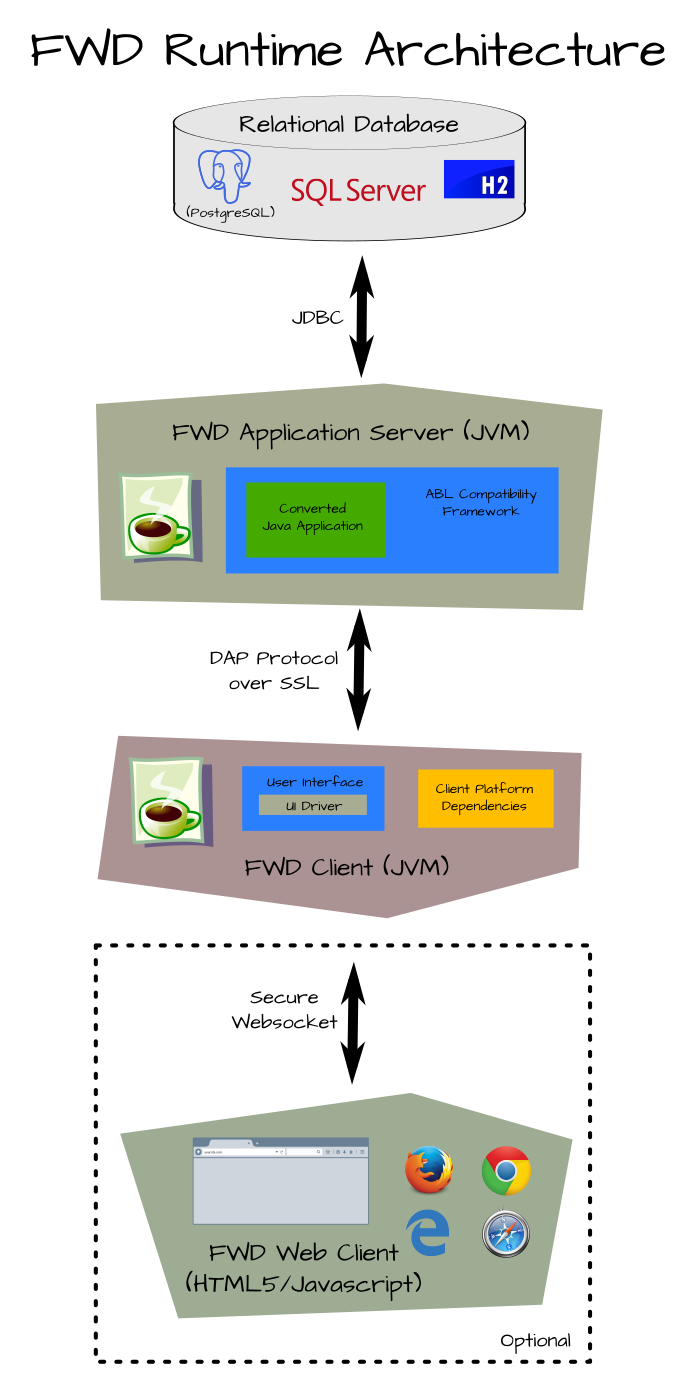
The architecture is designed as a 3 (sometimes 4) tier solution.
On the back end, there is a one-for-one replacement of the Progress database by an RDBMS database instance. This database server is not part of the FWD runtime per se. Rather, FWD relies upon one of a supported list of proprietary databases and open source projects. Access to this database only occurs from the FWD application server and this access occurs using JDBC (usually over TCP/IP).
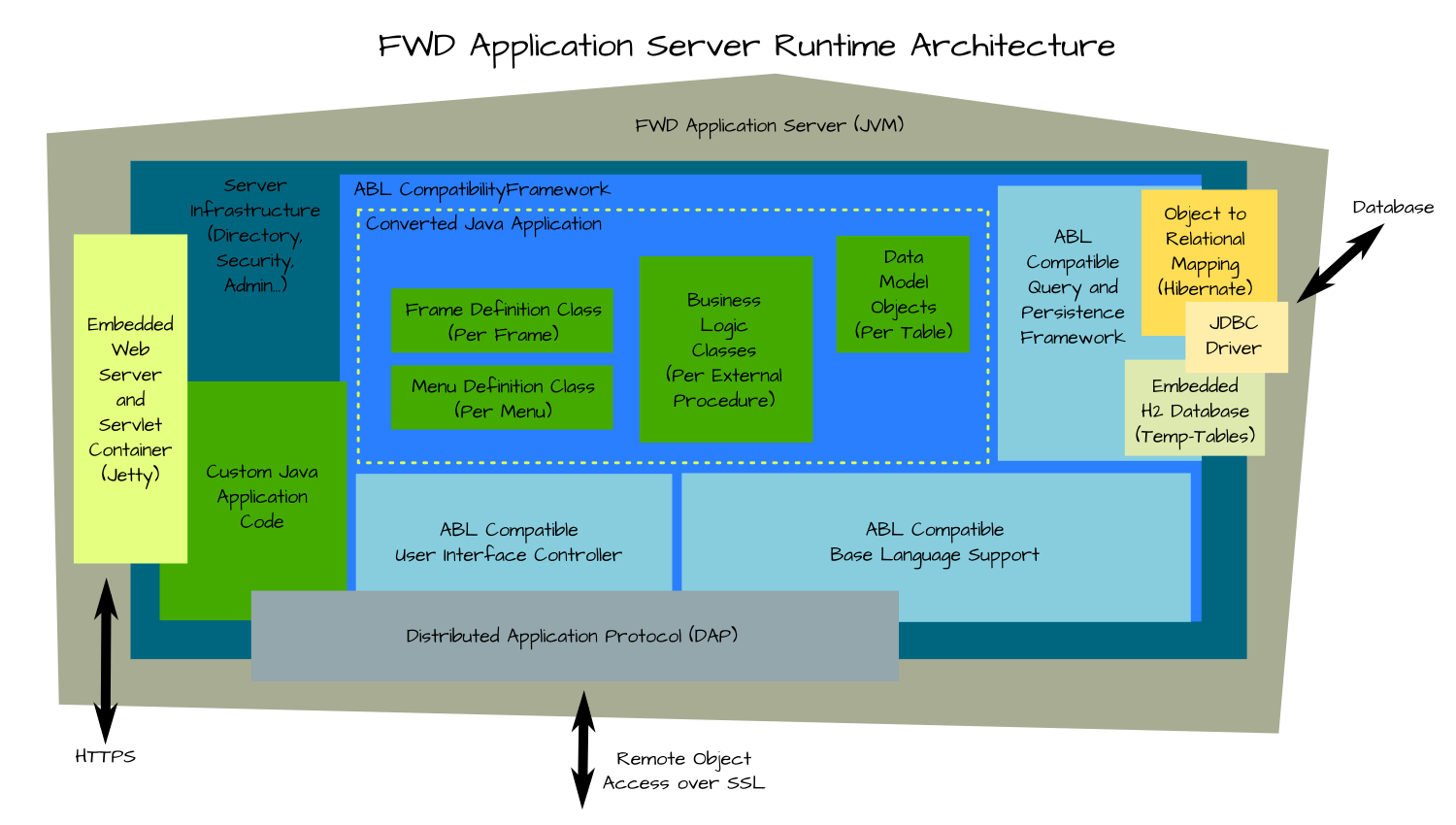
The converted Java code runs in the FWD application server (and never in the FWD client, even for applications with a user interface). The FWD application server uses a custom written, secure, distributed application platform as a foundation. Built upon this foundation is an ABL compatibility framework that provides the identical behavior and function as the equivalent Progress ABL language constructs. In total, this runtime is necessary to enable the resulting jar file(s) to run identically to the original application. The runtime environment executes in a Java virtual machine (JVM), performing an equivalent service for each API call made by the converted application. For example, if the application opens a database transaction, populates buffers, changes records, partially undoes that unit of work, then commits, the FWD runtime does the same. However, it uses Java, the custom FWD application server and a different database back end, such as PostgreSQL.
The original Progress OpenEdge environment is inherently a client-oriented design. In the FWD implementation, the converted code exclusively executes in the application server, but the client-specific dependencies of the original application require that some of the compatibility framework must be implemented in a per-user process that runs in the context of a specific operating system account. This is the FWD client, which manages only interactions with the user and those low-level operations which must occur in the context of the client system. These include file system access, process launching, and other operating system level operations.
In the user interface layer of the FWD client, the design allows a high degree of shared infrastructure among the various, low-level client drivers. This approach is enabled by an abstraction layer that allows different UI technologies to be used for the same application UI. Thus, if the application operates on a GUI screen, the runtime renders that screen identically in a web browser and executes the same logic, but with Java and JavaScript. two of the possible six UI drivers are web clients, written in HTML5/CSS/Javascript. The web client is the optional 4th tier and it is just a very thin presentation engine that connects to the FWD client for all the real work.
Progress ABL Compatibility Framework¶
Using the general purpose runtime infrastructure as a base, an application server has been created which hosts applications that have been converted with the FWD automated conversion process. Built on top of these generic components is a Progress ABL compatibility framework. This layer provides a set of common services for handling a very large percentage of the functionality available in the Progress 4GL language. The converted code runs inside the FWD application server ("FWD Server"), which is where most of the compatibility framework is implemented.
A client environment ("FWD Client") likewise has been created which uses the general purpose runtime as a base. Using this client, a session can be established with the FWD Application Server and users can logon and interact with the converted application in the same manner as the original Progress ABL version. This client implements the majority of the user interface processing for the Progress ABL compatibility environment and in this role it is referred to as the thin client. Since the client is designed for both interactive and batch usage, batch or utility programs that are non-interactive can be run using the same FWD Client software.
Once a session is started (the client process has been launched and the user or process has been authenticated), then there will be a thread on the server that has its security context defined by the associated user account's identity. This thread will execute the business logic in the server process, with no access to any resources, rights or data of any other user account. The FWD Server process runs all connected users in the same Java Virtual Machine (JVM) but isolates each thread's access using the security manager.
Both the client and the server are simply Java processes and it is possible to write a custom application to connect and utilize the server's resources. It is likewise possible to add other hand-written programs to the server to export additional functionality.
The original application's custom security implementation can be optionally converted into a common and standardized security model. This approach leverages the security manager implementation. Likewise, all of the application's configuration including security relevant data is migrated into the centralized secure directory. Usage of this data is mapped to the directory as needed.
For the most current description of the Progress ABL features which are supported (as well as those yet to be supported), please see Supported ABL Features.
The following is a summary of some of the runtime features:
- Provides converted Java code with OpenEdge compatibility.
- Moves complexity into common code and leaves application code clean.
- Hides differences between back-end databases, UI client types and operating systems.
- Enables use of open source stack components down to “the metal”.
- Leverages Java and SQL features wherever doing so will not break compatibility. For example, in queries the WHERE clause is almost always processed on the database server instead of running in interpreted 4GL where the business logic executes.
- Open source license combined with documentation provides a significant improvement in development team control as compared to the black-box approach of Progress.
- Provides a secure, centrally managed, distributed application environment.
- All code is pure Java except for a very small layer in native C used to support some ABL features which cannot be implemented in Java.
- Business logic runs in an application server with each user/process having separate threads and security context.
- Interactive users have a thin presentation engine that accesses the application server. No application code is run in the thin client, it is driven on an MVC-like basis from the server using frame definitions, screen buffers and the invocation of UI primitives.
- Can expose the entire application UI in a Web Browser (Javascript-only, no plugins).
Relational Database¶
At this time, there are 4 supported databases:
- PostgreSQL (recommended)
- MariaDB
- Microsoft SQLServer
- H2 (a non-production Java database), can be used in either embedded mode (an in-memory implementation inside the FWD application server) or as a standalone Java server process
The converted code runs inside the FWD application server. That converted code includes data model objects (DMOs) that represent tables in the database and temp-tables. These DMOs are managed by a combination of the FWD persistence layer and the Hibernate open source object to relational mapping (ORM) technology. The converted business logic uses the DMOs and executes converted queries using the FWD persistence layer to manage buffers, transactions, queries and all the database state.
The converted queries are database independent. WHERE clauses emit as Hibernate Query Language (HQL) and the combination of the FWD persistence layer and Hibernate's Dialects (database-specific modules that provide a common interface) allow the HQL to be implemented generically for all database implementations. Since the application code is generic and the FWD runtime hides the different database implementations, the specific database to be used for an installation can be chosen at the time that installation is deployed.
The FWD application server connects to the database using JDBC, most often over TCP/IP (including TLS support). Deployment can be on the same machine or a different machine. In production environments, it is most common to use a separate machine. This improves security, improves scalability and allows database-specific performance tuning.
Here is the high level diagram for PostgreSQL:
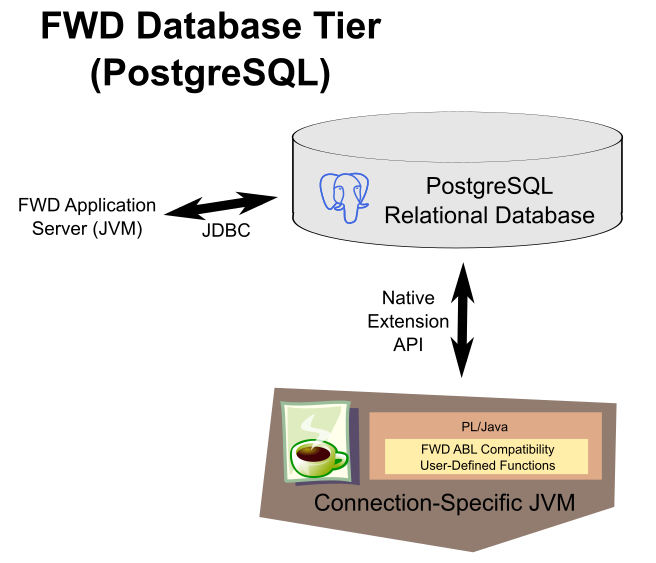
Set operations and database engine filtering are leveraged as much as possible. This is important to reduce the round trips to the database. One important approach to enabling this is to maximize the components of the WHERE clause that can be executed on the database server. To accomplish this, the database must support user-defined functions (e.g. PL/Java for PostgreSQL). In the above diagram, each connection has a dedicated JVM process that runs the FWD code that implements user-defined functions needed to match the ABL WHERE clause behavior. These are the same Java methods used in the FWD application server for ABL compatibility. Since the ABL executes its query WHERE clauses in the ABL process itself (a kind of fat client approach) instead of in the database, the WHERE clauses routinely use ABL features directly. FWD provides ABL compatible versions of these features but they need to be callable from the database server using the database's native extension mechanism. In the case of PostgreSQL, this mechanism is called PL/Java. It allows Java methods to be called directly from a SQL WHERE clause.
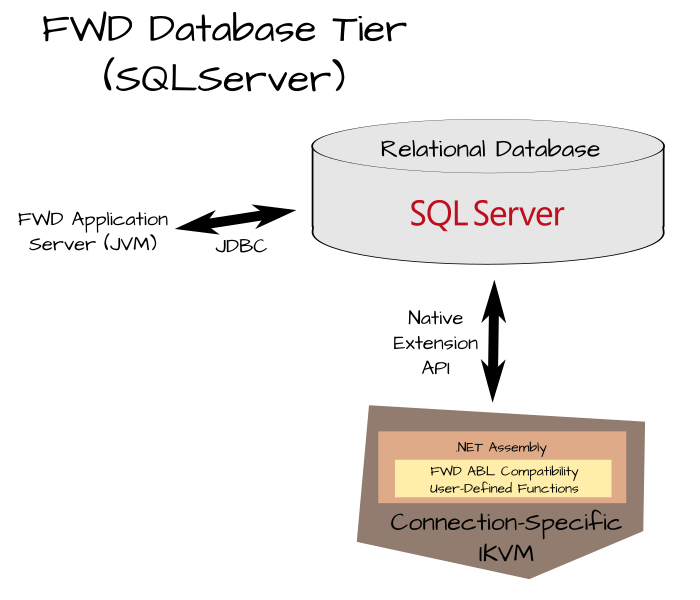
On SQLServer, the design is similar but it must take the .NET environment into account:
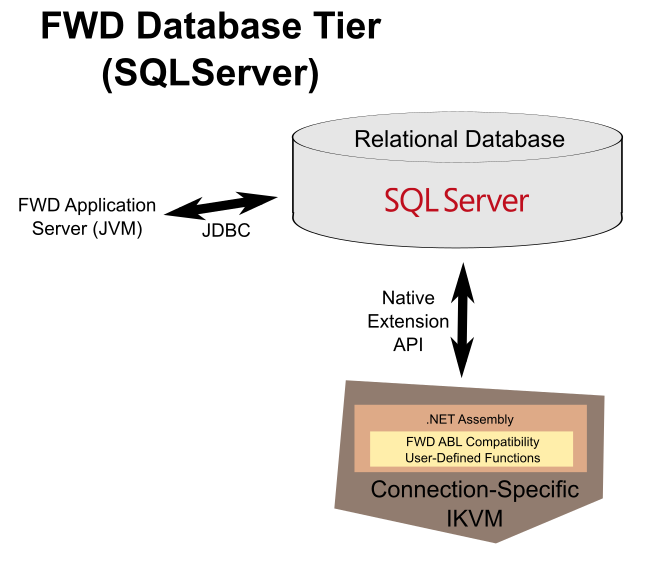
SQLServer does not directly support Java user-defined functions, but it natively supports .NET functions packaged as assemblies. In order to leverage the compatible Java implementation, we use the IKVM project (see http://www.ikvm.net/) which provides a JVM implementation in .NET and tools for converting Java classes to .NET CLR.
Adding support for a new database can be done in 3-4 months. Golden Code can help if needed.
FWD Application Server¶
The converted application runs entirely on the FWD Server, no converted ABL code ever runs on the FWD Client. The converted code can be categorized into groupings:
- business logic
- data model objects (DMOs)
- frame definitions
- menu definitions
These groupings together form the converted application code which is hosted inside a compatibility environment that provides fidelity with the behavior and semantics of the Progress ABL environment.
All converted code is dependent upon the base language support. This ranges from the most elemental support for Progress data types (e.g. logical or character) to the most complex block properties. Expression support, built-in functions, control flow and many other basic services are all provided by the base language support.
The converted business logic is where the majority of the original Progress ABL programs reside. This is where variables and other resources like streams are defined, where the block structure of the program exists and where all control flow is managed. All top-level application entry points (a Progress ABL procedure which is run as the "startup procedure") are exposed as exported entry points via the distributed application protocol.
The application server gets most of its configuration from a "directory" service that usually is backed by an XML file.

After a FWD Client successfully establishes a session (this includes proper authentication), it calls the converted startup procedure (via the exported entry point) to start application execution. That call does not return until the application exits.
The converted data model objects define the structure, validation and other features of the database access. The business logic uses buffers and obtains DMOs for these buffers via queries or by creating a new record. Once a DMO is available its properties can be read or written via getter/setter methods. The business logic will use and modify the DMOs in the same manner as the original Progress ABL logic did.
The DMO implementation is dependent upon a layer of persistence services that implements the Progress ABL compatibility features for database support. This layer is tightly integrated with Hibernate, an open-source Object-Relational Mapping (ORM) technology. Hibernate is the backing infrastructure that translates DMOs into records of a table and vice versa. Hibernate uses Java Database Connectivity (JDBC) for its relational database access. In areas where different databases support variations in SQL syntax, Hibernate adds its own "dialect" support, which largely hides the differences between different relational database implementations. The use of JDBC and Hibernate does provide a high degree of database independence, with syntax support for 30+ databases. At the time of this writing, however, only PostgreSQL, SQLServer and H2 are fully supported by FWD. In addition to supporting the varying syntax dialects of individual database implementations, FWD requires that a database has the ability to execute user-defined functions implemented in Java at the database server, and a handful of other features.
As part of the conversion process, all static elements of the user interface (UI) are separated from the business logic. Instead, a single explicit frame definition is written for each unique frame. These frame definitions specify the widgets (name and type), layout, frame position, formatting, frame options (e.g. title, down iterations) and widget options (e.g. label, data type). These frame definitions are encoded as Java classes.
Since Progress ABL is a single threaded "fat client" environment, 4GL business logic generally has synchronous UI dependencies written deeply into the control flow of the program. In fact, in many cases the transaction processing and error handling are very sensitive to the placement of these UI language statements. In the converted Java application, while the static frame definitions have been completely removed from the business logic, the business logic's dependencies upon synchronous UI interaction remain as part of the control flow of a program. In this sense, the business logic can be thought of (loosely) as the controller in a Model-View-Controller (MVC) architecture. The frame definitions are the views and the DMOs are the model. For example, the business logic may need to display a report on the screen so it may have a query in a loop which obtains a DMO and then fields from that DMO are written into the widgets of the frame and the frame is told to display.
The frame definition is a Java class on the server which is used by the business logic to interact with the logical concept of a frame. As an example, the business logic might call a setter method to update the data in a given widget. Likewise the frame object implements an extensive list of methods to provide access to behavior expected in the Progress ABL. While the frame objects provide a server-side interface, the actual UI processing such as layout, rendering and event handling is all handled on the FWD Client (sometimes called the "thin-client" because it is just a presentation engine). To achieve this separation, the frame's definition is converted (at runtime) into a configuration and this is sent down to the client to be instantiated however the particular client (e.g. TTY, GUI, web...) must handle it. Likewise, the data associated with a frame's widgets (a screen buffer) is transferred to and from the thin client as needed to keep the state synchronized. This is possible since the Progress ABL is inherently single threaded. This means that any time the business logic executes a UI language statement, that server-side logic blocks until the client is done.
A Progress ABL compatible UI layer provides the server-side UI functionality and handles calling the UI primitive operations (that are exported from the thin client via the DAP) as required to maintain compatible behavior. This same component provides a number of exported interfaces which are called recursively by the thin client in order to handle certain features such as field level validation and triggers. Both of these call-backs must run on the server BUT they also must run nested inside already active UI processing. For example, a Progress ABL WAIT-FOR language statement does not return when a trigger executes. Rather, the trigger is a call-back executed nested within the WAIT-FOR processing. All of the complexity of the Progress ABL event processing model is supported including nested WAIT-FOR processing that can be arbitrarily deep.
FWD Client¶
The user (or possibly a batch process) connects to the converted application by running a FWD Client (as a JVM process). The core function of this process is often referred to as the "thin client". The client process is “thin” from the perspective that it does nothing except connect to the server, authenticate and then invoke an entry point (to business logic) on the server side. The business logic may invoke user interface code (if that is required in the original application) and in such cases, frame definitions are loaded and sent down to the client node. The client does not require access to the converted application code nor does it require direct access to the database or directory. The server drives all client activities using a set of user interface “primitives“. This allows the client code to be completely generic (not application-specific) as well as reasonably thin. All real processing occurs on the server, though any interactive client does cooperate with the server in processing things such as triggers or field level validation expressions.
As part of the session setup process (especially for interactive clients), a customizable authentication process is integrated into the thin client. If the client authentication plug-in is enabled, an application-specific class (as configured in the directory) is downloaded dynamically to the client over the secure session. The client executing this plug-in can provide a logon dialog and/or use any other programmatic facility such as biometric readers to obtain authentication data. This data is sent to the server and if authentication succeeds, the session is established.
The thin client has been designed with the intention that it only provides a presentation layer for the application. Unlike the Progress client, no business logic or data access of ANY kind is executed on the thin client.

When the server sends a frame definition down to the thin client, this is not a Java class but the data that specifies the frame's configuration. That definition is used to instantiate all the backing frame and widget resources needed to support the specified features. Subsequent UI primitive operations on a frame will include screen buffers or other state needed to execute. In response to these primitive UI operation requests by the server, the thin client will implement the backing function using common code where possible. This common code then uses driver-specific low-level operations to handle drawing, layout and certain other functions such as keyboard reading.
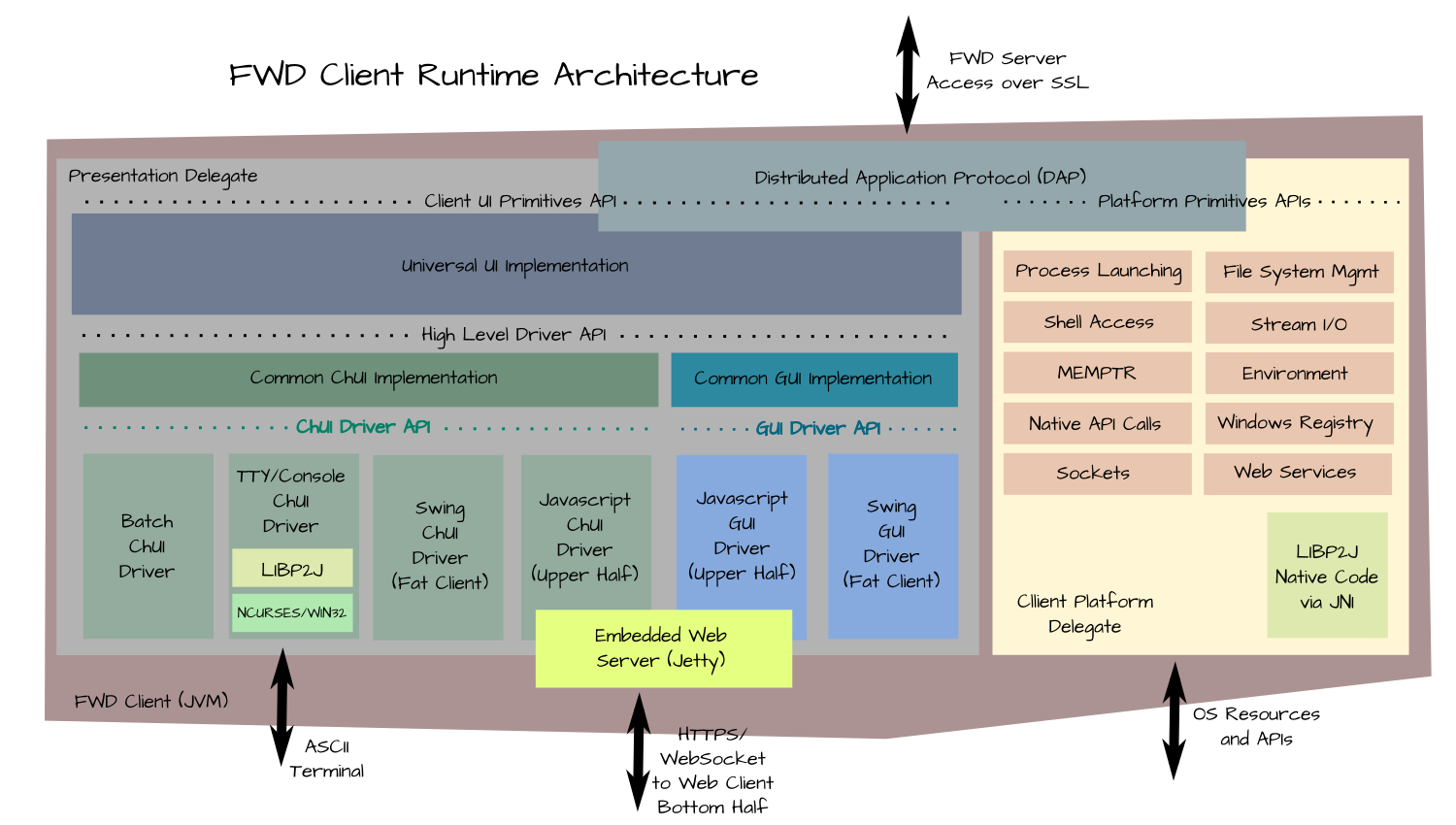
Multiple different client types are enabled via this approach, while the server's user interface logic is identical for (and agnostic to) each client type. This is enabled by implementing an abstract interface of UI primitive operations and a data driven approach to defining resources such as frames. This approach works for both TTY (character user interface or ChUI) and GUI client types. For both of these types, there is a very large amount of common behavior/features which lend themselves well to abstraction. The client-side code that implements this is the presentation delegate.
The core design of the FWD Client presentation delegate is to expose a generic API of UI primitives which enable control by the converted application on the server. This is implemented in common code (code that does not depend on the type of UI (ChUI or GUI). Most of the presentation delegate is implemented in this common code. The following are examples:
- core widget implementation
- window and frame management
- high level primitives (e.g. DISPLAY, VIEW, ENABLE, DISABLE, WAIT-FOR, CHOOSE, SET, UPDATE, PROMPT-FOR...)
- data formatting
- state synchronization with the server-side frames, widgets, menus and other UI constructs
- screen buffer management
- frame scoping and widget/frame registry
- event processing and the input event loop
- triggers
- validation processing
- frame layout processing
- focus management
- clipping and the main drawing manager
Below this common code, is the high level API that allows different drivers to be used without changing the common code. The idea is that the common code can be implemented using a standardized set of worker routines. Below there, we implement a layer of common driver code that is specific to the UI type (ChUI or GUI). By doing this, we reduce the amount of code needed in the specific drivers that are plugged in. The objective is to maximize the common code. This set of driver abstraction layers enables 6 drivers (currently) to be implemented:
- ChUI
- Native TTY (implemented via a JNI library that calls NCURSES or the WIN32 Console APIs), which can be used with real hardware terminals or with terminal emulators
- Batch (also used for Appserver and would be used for WebSpeed)
- Swing (a fat client implementation that looks like a terminal emulator but it is provided directly by the FWD Client)
- Web (this is a 4-tier architecture where the bottom half of the driver is a browser which uses HTML5/CSS/Javascript to access the FWD Client via a WebSocket)
- GUI
- Swing (a fat client implementation that looks just like the original ABL Windows application)
- Web (this is a 4-tier architecture where the bottom half of the driver is a browser which uses HTML5/CSS/Javascript to access the FWD Client via a WebSocket)
The driver in use is selected at runtime (when you start the JVM for the FWD Client). All of these drivers can be used simultaneously against the same server (each driver can be used independently of the others).
While the user interface (presentation delegate) does constitute most of the code of the FWD Client, the Progress ABL does implement several other sets of functionality that MUST be implemented on the client. In the FWD Client, this is called the client platform delegate. Please see Client Platform Delegate for details.
General Purpose Runtime Modules¶
Some of the core FWD runtime modules are not specific to the Progress ABL. Instead, they provide a general purpose platform for secure distributed computing. The most important of these modules are the Distributed Application Protocol, the Directory Service, and the Security Manager.
Distributed Application Protocol (DAP)¶
The DAP is designed as a message passing system where messages are exchanged by nodes arranged into a logical network.
The network is comprised of leaf nodes and routing nodes. Leaf nodes are end-points in the network. They may only have a direct connection to a routing node. Routing nodes may connect to any type of node and are a superset of leaf node function with the additional ability to forward or route messages between two nodes which have no direct connection. The logical network can be arbitrarily complex by connecting routing nodes together into mesh, star, tree or other topologies. Nothing in the protocol has any knowledge or dependency upon the topology of the logical network. That is left as a runtime choice.
For the network to exist, a session must be established between two nodes (leaf ↔ router or router ↔ router). As more nodes establish sessions, the network grows. Messages may be passed between any two nodes that have an active session with the same logical network. A message may be directly sent (if the two nodes are directly connected) or indirectly sent (if no direct connection exists between the nodes).
Messages can contain a graph of arbitrarily complex objects as a payload. The java.io.Serializable interface is used to enable the transmission and reception of messages over a network connection.
Each end of a session has a message queue that is used to send and receive messages. Once a message is enqueued, if the caller does not require synchronous processing, the caller continues immediately without waiting for transmission. If the caller requires the semantics of a synchronous call, then that calling thread will block while the message is sent to the other side, processed there and the result is returned. Even though the protocol is based on messages and queues (an inherently asynchronous concept), at the high level interface to the caller, the mechanism naturally provides for both synchronous and asynchronous forms of processing.
The communications transport for a session is provided by Transaction Layer Security (TLS), which is based on the de-facto SSL 3.0 standard. This is a reliable connection-oriented (TCP-based) protocol which uses encryptions and digital certificates to ensure the privacy and integrity of all network operations.
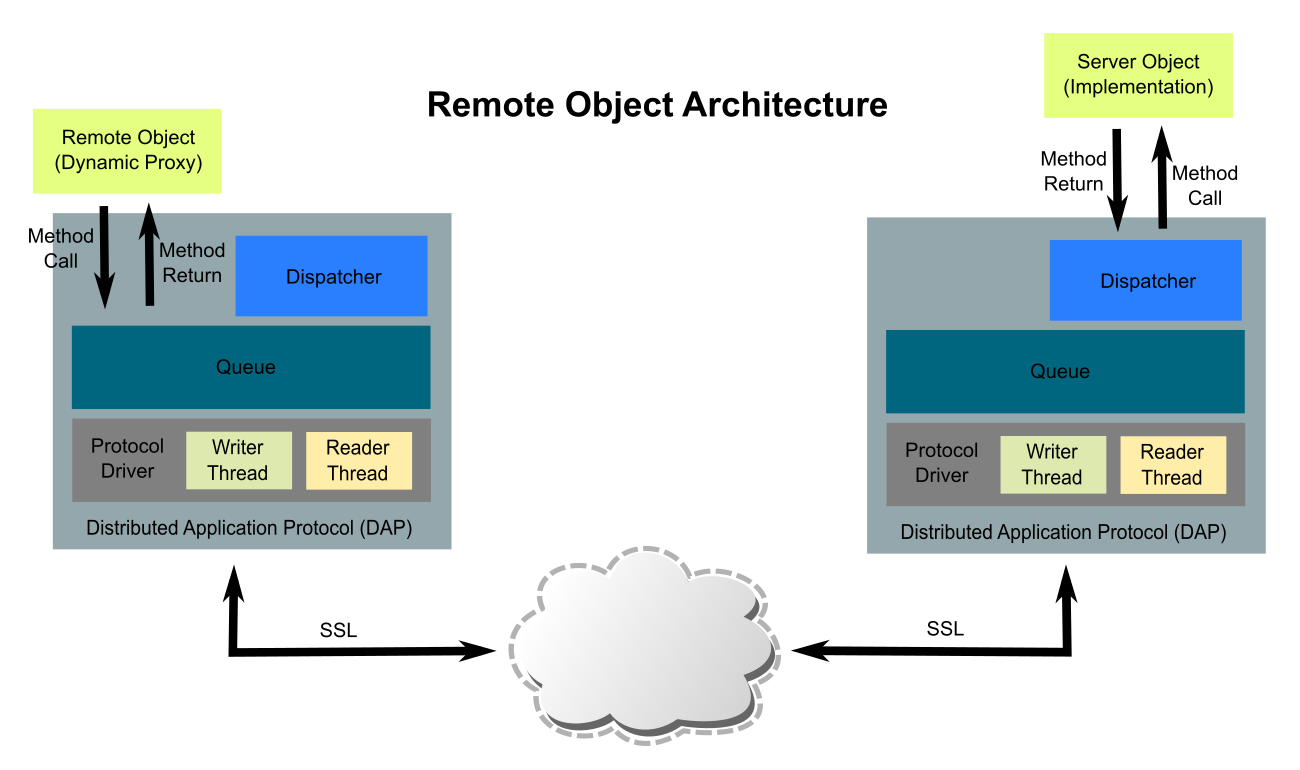
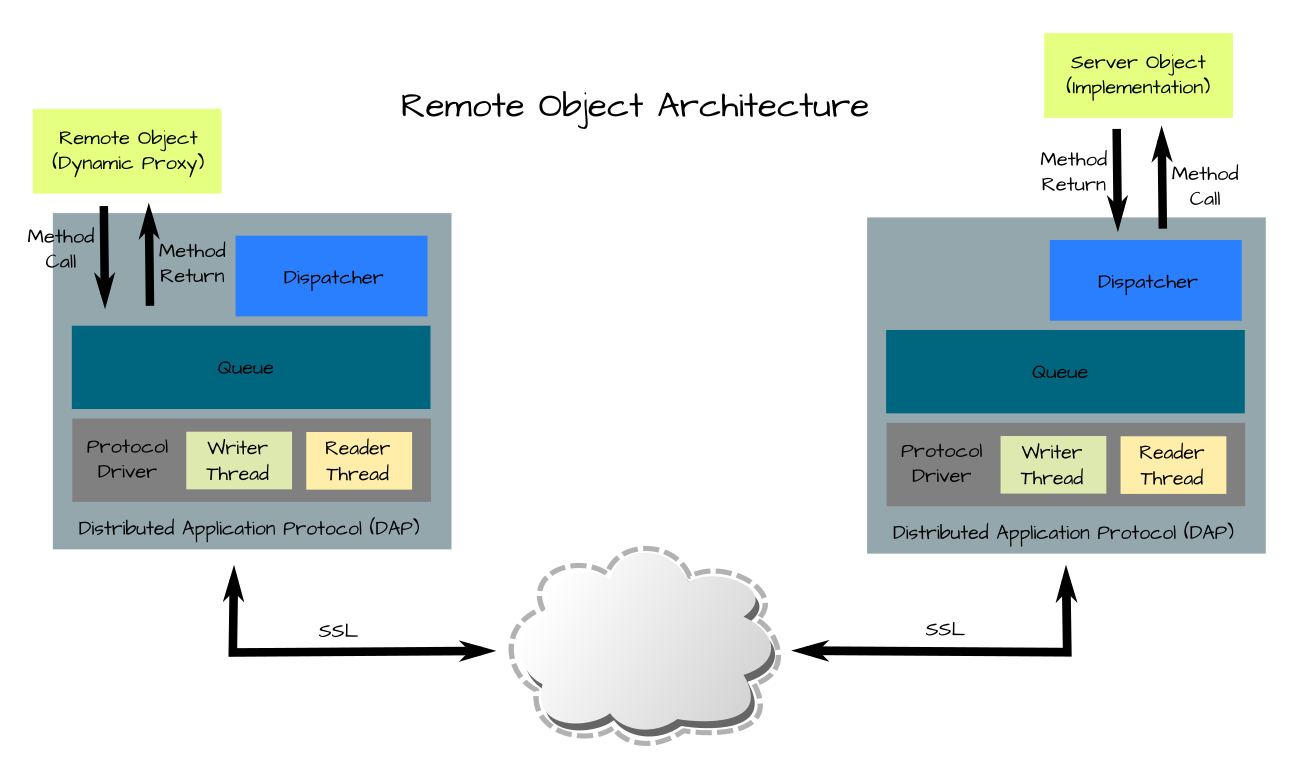
Over this lower level network infrastructure is built a secure remote object protocol that allows two Java applications to make method calls synchronously (e.g. remote procedure call) with minimal effort. This can be thought of as a simpler, faster and more secure form of Remote Method Invocation (RMI) as it is similar in function.
The remote object technology provides a local proxy object that implements one or more interfaces. A reference to this object can be obtained easily and calls to its methods are remoted to the object server. The proxy translates method calls into messages which are sent over the DAP to the peer node on the other side of the session. The calling thread will block until a matching reply message is received.
On the peer node, a server object must have been registered. Messages from the remote proxy object are read from the inbound queue by the dispatcher. This dispatcher matches the message with its destination object and method. The method is invoked and when complete the result (or any thrown exception) is packaged as a message and sent back to the requesting node. At that point the waiting thread is unblocked and dequeues the reply message, returning it to the remote proxy. The remote proxy unpackages the returned data (or thrown exception) and returns it (or throws it) to the caller.
All access to exported entry points (and registered server objects) is controlled by a DAP-specific resource plug-in in the security manager.
Systems of arbitrary complexity can be built easily using this remote object implementation. Clients, servers, peer-to-peer systems, batch processes, web agents and more are all possible.
For more information, see DAP Specification.
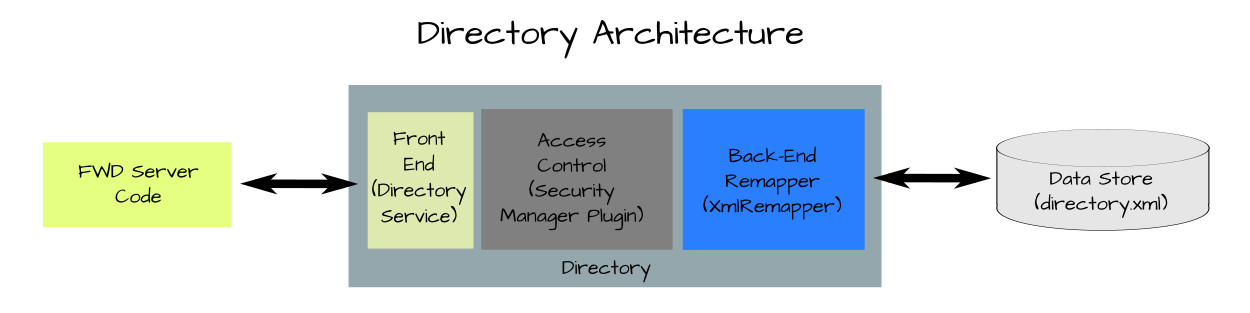
Directory Service¶
Complex networked systems require configuration data. Such data sets are often large and require a complex structure for efficient organization. One flexible approach is to structure configuration data in a tree. In addition, this configuration data needs to be shared throughout the logical network. To accommodate these requirements, a centralized directory service has been created.
A directory is a hierarchy of typed objects. All the directory objects are structured to form a tree. These directory objects have a type (called a class) which determines what information can be stored in an instance of the type. Named data values stored in a directory object are called attributes. Attributes can be any of the following primitive data types:
- integer
- double
- boolean
- string
- byte array
- bit field (contains arbitrary bit patterns with a specified maximum number of bits in total)
- bit selector (a mutually exclusive bit field which can only have a single bit set at any given moment)
- date
- time
Using these types, directory objects of arbitrary complexity can be designed. These objects can have any number of attributes (data of one of the primitive types) and any number of child objects which can themselves be arbitrarily complex.
Every directory object is a node in the directory tree and as such, has an ID. Every node can be identified by this ID string which describes how to find the object in the tree from its root. For example:
/security/accounts/user_x /security/acl/resource3/rights /server/headquarters/threads
The path is made of links separated by the forward slash ('/') character like in file system directories. Every link names a node in the subtree of its parent. Sibling objects all have unique names, although the same names can be reused at different levels of the tree.

The directory service provides a general purpose interface which supplies functions such as reading, writing, enumerating and searching for directory objects. Applications are written to this interface.
For every call to the directory service, the access rights of the caller are checked to ensure that the caller is allowed to execute the requested operation. This access control function is implemented with a security manager resource plug-in. If the operation is allowed, then the request is passed on to the instance of the remapper.
The remapper is a plug-in which implements a standardized low-level interface (for the directory service) and remaps these primitive operations to the proper semantics of some specific back-end data source. At this time, remappers exist for Lightweight Directory Access Protocol (LDAP) Servers (via JNDI) and for an XML-based directory. Other directory back-ends can be added over time due to the pluggable design of the directory service.
In this manner, a general purpose and standardized interface is provided to applications while the back-end directory technology can be varied. The plug-in architecture allows the choice of directory back-end to be made at installation time rather than at development time. This means that one does not need to hard code the application to a specific directory back-end, in any way.
The integration with the security manager enables a highly flexible security policy. This allows granular control over the users/groups (security subjects) and the operations that those subjects are allowed to do on specific portions of the directory tree. For example, a specific group may have rights to read from certain parts of the directory and may be allowed to write to a specific directory object, while another group (or user) may have completely different rights to those same locations. Rights can be assigned down to the specific directory object or can be set at any parent object (which allows a policy to be set for the sub-tree of objects contained under that parent object). The following operations can be secured:
- enumerate
- create
- delete
- add (determines if a child node can be added)
- read
- write
- no access (special negative right that disables all access no matter what other operations are enabled)
This secure directory service is accessible over the DAP such that its interface is exported as remote objects. This allows easy, remote access to centralized directory data.
It is important to note that any kind of structured data can be stored in the directory, but generally the directory is used for often-read but seldom-changed data such as configuration data. The directory back-end can be a general purpose database (if one writes a back-end plug-in that provides such a feature) but generally the external data source for the directory is an environment that is optimized for read access (e.g. LDAP servers are usually optimized in this manner). As such, this is not meant to be a general purpose database but rather a special purpose data store.
Of the configuration data stored in the directory, the majority of that data is usually dedicated to security purposes. For example, the directory contains all account data, access control lists (ACLs) and other security configuration.
Security Manager¶
The security manager is a subsystem which enables strong application-level security. Application-level security is a means of protecting application data and logic from unauthorized access or modification in a multi-user environment. Note that as a Java subsystem, this code cannot provide operating system (OS) level security. Strong OS-level security must still be provided outside of the security manager.
Servers provide shared resources that can be accessed by multiple users. Using the DAP, multi-threading is used to provide a scalable server environment. This means that the server will listen on predefined ports for incoming TLS connections from remote processes. Each incoming session must be authenticated by the security manager before it can be allowed to operate. Authentication is the process of verifying that an entity is whom they claim to be. In this manner, the security manager is made aware of every new subject in the system and that security context (the subject's identity as known in the security configuration and which is established by an authentication process) is associated with the new session (if authentication succeeds).
Security subjects are entities in the system which access resources. Resources represent data or points in application logic that have to provide controllable access. The following subjects are possible:
- user (an interactive end-user)
- process (an agent program or non-interactive/batch process)
- group (a list of other subjects)
Clients are programs that connect to the server and which represent a specific subject in the system. When a client attempts to establish a session, it must provide authentication data that establishes the represented subject's identity. For most interactive clients, this would be some kind of logon dialog that allows the user to specify a userid and password. A pluggable architecture for this authentication process is provided by the security manager. This allows the client and server sides of the authentication process to be augmented by custom logic, without any changes to the security manager code. This enables a wide range of possible authentication solutions including the use of biometrics (e.g. fingerprint readers) as well as multi-factor authentication (e.g. something you are + something you have + something you know). Client programs that are non-interactive or batch processes will usually take advantage of the certificate-based authentication modes that are provided by the security manager. This allows a subject's identity to be associated with a known certificate issued by a known certificate authority. The client that supplies this certificate during authentication can be authenticated without any interactive processing (if this is enabled by the security manager's configuration for that subject's account). There is even a provision for anonymous connections to the server. Anonymous subjects are also associated with a security context and may have rights assigned. This richness in authentication capabilities allows for highly distributed systems of arbitrary complexity.
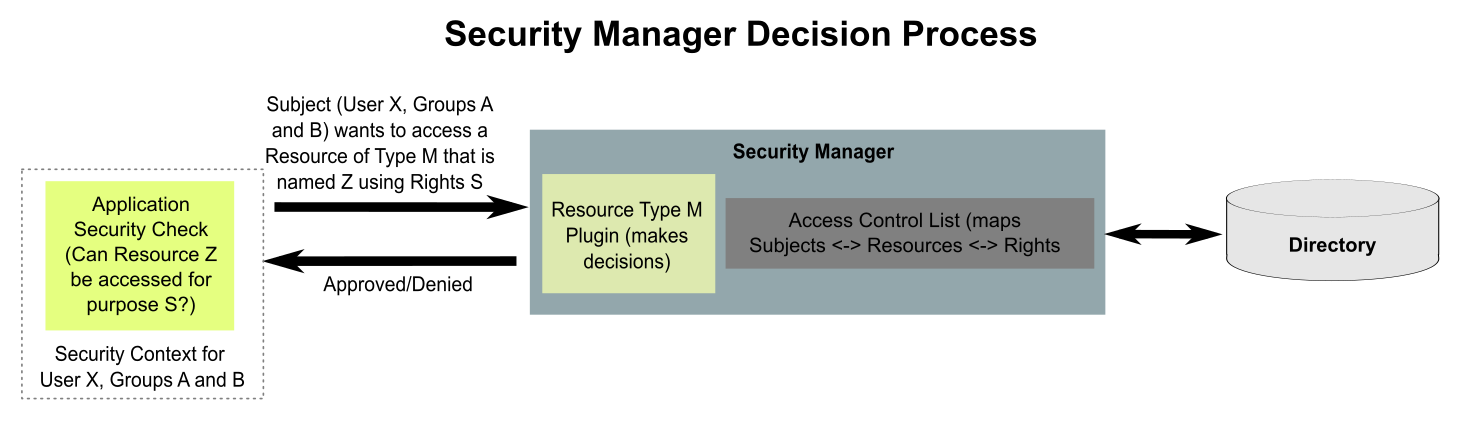
Once authenticated, any request a client submits to the server will run on a thread which is assigned the security context that identifies the associated subject. This context is intrinsic to each thread and can only be accessed within the security manager. Thus it cannot be changed or even inspected by any other code on the server. This allows security decisions to be made based on the subject associated with each request.
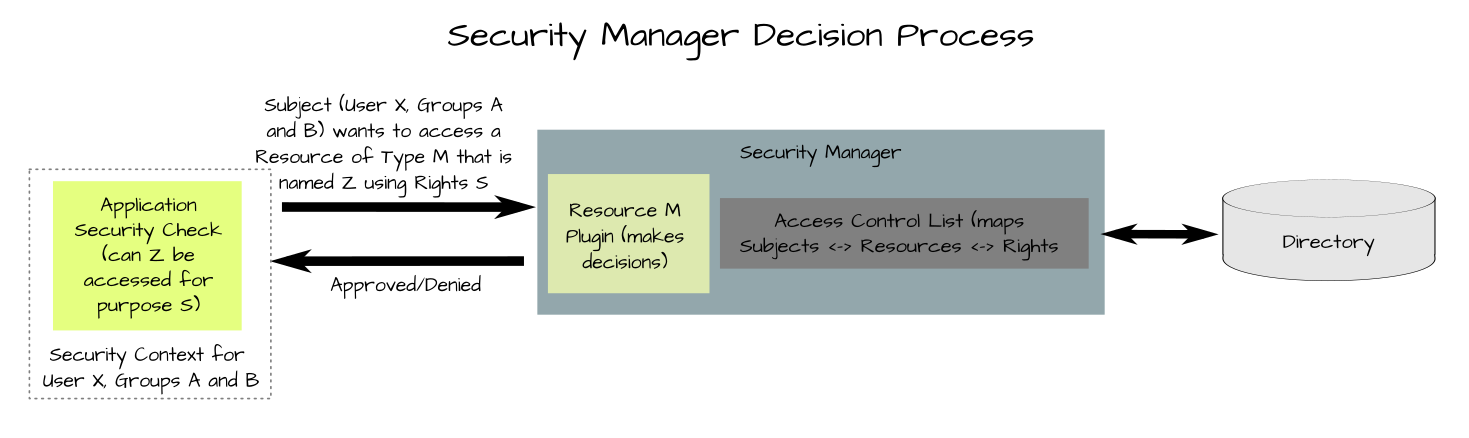
For any resource which is protected, a resource plug-in is loaded into the security manager. This plug-in provides an custom external interface to request specific security decisions for specific instances of that resource. The plug-in also provides the resource-specific backing logic to make the decision.
Resource instances are differentiated with a name. For example, if the resource is a "file system object" then the resource name would be a fully qualified path and file name to a specific file system object.
Resource plug-ins make security decisions in cooperation with the security manager. The security manager provides services to identify all access control lists (ACLs) that are assigned to the security context (the internal representation of a subject's identity) for the thread requesting the security decision. ACLs describe how security subjects relate to resources in terms of rights. This means that given a subject (security context) and a specific resource name, a list of assigned ACLs can be produced by the security manager. The resource plug-in then compares the requested rights (the operation or access that the subject needs) with the rights specified in each ACL until it determines that access should be allowed or denied.
The rights that are possible for a given resource are completely defined by the resource plug-in. The security manager has no understanding of specific rights but rather treats them as opaque data. This allows the resource plug-in to define custom data structures of arbitrary complexity to represent the rights and the security manager can still associate these rights with a subject and resource instance in an ACL. This enables a very granular and flexible security model which is customized to each resource's needs.
While the resource plug-in provides the mechanism to make security decisions, the request for a security decision must actually come from the application code that manages the resource. This application code provides a service to multiple subjects and when a request is made that must be controlled or limited, that service code must make the appropriate request to the resource plug-in to get a security decision. What the code does with that decision is not controlled by the resource plug-in or the security manager. Thus, to properly secure any given resource, all service layers by which that resource can be accessed must make the proper requests for security decisions at the proper point in its processing AND it must properly honor the security decision.
Service layers may use security decisions for the purposes of simple boolean decisions (allow/deny access) or for the purposes of filtering. Filtering allows for a range of access from completely allowed to partially allowed to completely denied. For example, data in a database table might be filtered using a security manager resource plug-in by specifying which subjects have access to which records in the database table. Then the service layer might filter a query result set down based on record-level security decisions.
Users can be grouped for the purpose of easy access rights management. A group is a collection of users that share a set of ACLs. Users may participate in multiple groups. The security context for such users has references to all relevant groups.
All of the security configuration is stored in the directory. This includes account data (users, groups, processes), authentication plug-in configuration, resource plug-in configuration, ACLs, rights and all other security configuration. The directory service is a separate component of the runtime which provides the security manager with access to this data storage.
The directory, security manager and the remote object protocol are all integrated into a single working system such that authentication, authorization, access control, auditing and other critical functions are handled consistently and comprehensively.
© 2004-2019 Golden Code Development Corporation. ALL RIGHTS RESERVED.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}