Writing TRPL Rule-Sets¶
Introduction¶
An abstract syntax tree (AST) is a powerful representation of the source code of a program, in that it imposes a well-known, programatically accessible structure upon the logic and language statements of a program's source code. ASTs are built by language parsers or by other means. The purpose of the pattern package is to provide a processing engine which is applied against ASTs to detect structural and data patterns, and to perform actions conditionally, according to the needs of the user. Given a definition which includes, at a high level:
- a programming language for control flow, logic, data processing;
- instructions to access and/or modify the ASTs to be processed; and
- a pipeline of sets of rules to apply to the ASTs;
The pattern processing engine, or pattern engine, allows one to inspect, analyze, interpret and/or transform a group of ASTs in diverse ways.
Rules¶
At the core of the pattern engine is the notion of a rule. A rule defines a logical condition which must evaluate to true or false at runtime. Each rule may define zero or more actions, which are executed if and only if the rule's condition evaluates to true. An action can do anything a Java method can do; typical uses for actions are to record information for later use, annotate an AST node, edit an AST's structure, or to provide feedback to the user.
A rule generally is applied to a single node of an AST, though some rules (those used for global initialization and termination processing for a session of the pattern engine) are processed outside of the scope of any AST. The current node for a given rule can be accessed using this or copy. This corresponds to the source and target trees where this is the source (read-only) node that should not be changed and copy is the target (writable) node that can be changed. Both of these special variables are of type com.goldencode.p2j.uast.Aast and one can call any public method directly on these variables.
A rule's condition and its actions are each represented as logical, algebraic expressions in infix notation (e.g., a + b = c), which is a natural convention for most people. It is possible to embed constants, variables, functions, and a variety of operators within these expressions. An action typically utilizes one or more function invocations within its expression, since an algebraic comparison in and of itself does not invoke any behavior beyond simple evaluation to a boolean result. A symbol resolver is used to substitute runtime data for the constants, variables, and function invocations in an expression. This data may be extracted from the environment, from user-provided variables, or from an AST.
See Writing TRPL Expressions for the syntax of the expression language.
Symbol Resolver¶
A specialized symbol resolver is used by the pattern engine. This symbol resolver is aware of the properties and general structure of an AST. Thus, expressions can reference properties of the AST, such as its token type, its text, its source filename, etc. Furthermore, the symbol resolver can answer questions about the structure of an AST via user functions, such as who its ancestors, siblings, and descendants are. The pattern engine inspects an AST, updating the state of the symbol resolver as it visits each node in the AST, such that the symbol resolver always has the correct AST node in context when a rule's expressions are applied.
In cooperation with pattern workers, the symbol resolver can resolve symbolic constants that exist in a given pattern worker's namespace.
Rule-Sets¶
Rules are organized into rule-sets. Rule-Sets have a notion of the programming language tokens they expect to encounter within the ASTs they are required to process. They optionally may define a library of named functions which can be executed or invoked within expressions by an their name.
Rulesets differentiate between six types of rules, each of which is applied at a different time for a different purpose:
init-ruleswalk-rulesdescent-rulesascent-rulesnext-child-rulespost-rules
A rule-set is applied against each AST being processed by a run of the pattern engine.
init-rules are run once at the beginning of the inspection of an AST hierarchy. They are applied in a pre-defined order, within the context of the root AST node of that hierarchy.
walk-rules are run once per AST node visited. As the tree is inspected, each node in the tree (or in a filtered view of the tree) is visited by the engine. The entire list of walk-rules is applied in a pre-defined order, within the context of each node, before the next node is visited. If one were to write code only using walk-rules, it would simulate the well known "visitor pattern".
descent-rules are run in between the walk-rules for a parent node and the walk-rule for that parent's first child.
ascent-rules are run in after all of a parent's last child's children nodes are done being processed. This is the moment when the tree walk would naturally "ascend" back up the tree to the parent node.
next-child-rules are run in before the walk-rules for rightmost of two sibling nodes, after all the child nodes of the leftmost sibling have been processed. This is equivalent to when the tree walk would move between the two sibling nodes.
post-rules are run once at the end of the inspection of an AST hierarchy. They are applied in a pre-defined order, within the context of the root AST node of that hierarchy.
Each ruleset actually processes a related pair of AST hierarchies: a read-only source AST and a writable target AST. The target AST is simply a deep copy of the source AST. The source AST is used to drive the node-visiting logic, and as such, should not be modified by a rule's actions. The target AST is intended to be modified as a ruleset sees fit.
Pipelining¶
Rule-Sets may be chained together into a pipeline, such that the writable target AST modified by one ruleset becomes the read-only source AST available to the next ruleset in the pipeline. This enables a list of related rules-sets to progressively analyze and transform an AST in multiple steps. Each step can be for a specific purpose, enabling a very complex analysis and/or transformation to be written in a maintainable manner.
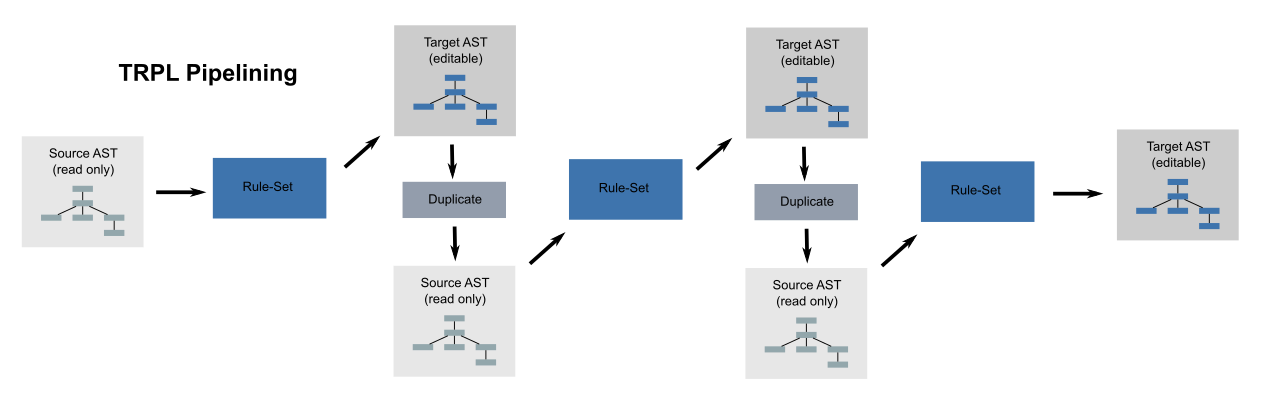
Additionally, each ruleset has the opportunity to create a filtered view on its target AST, to which it adds only those AST nodes which meet some criteria defined by its rules. This view is also made available to the next ruleset in the pipeline, which has the option to iterate over the filtered view only, or over the entire tree. The designation to iterate over the view vs. the tree is known as the ruleset's input mode.
Within a pipeline, rule-set elements can reference an external .rules file instead of inline rules. These can be used in two ways:
- Top-Level When the rule-set element is contained directly within a cfg element, this is considered a top-level rule-set. Such a rule-set will have its contents executed in its entirety with a tree walk that is specific to that rule-set. Any other top-level rule-set elements in the same cfg element will be executed in order. This provides the pipelining feature to the master profile document. In a file with 2 top-level rule sets, the first rule set will be processed through a complete tree walk (with all nodes being visited and all events being triggered) before any processing in the second rule set will occur.
- Merge When the
rule-setelement is nested (contained within) anotherrule-setelement, this has the effect of merging the named.rulesfile into the containingrule-setelement as if those rules were defined there directly. This allows rules to be split into multiple different rules files but then walked as a combined set. In such a case, each of the merged rule sets will have their events triggered in the same order as therule-setelements are merged. In a rule-set that contains mergedrule-setelements, the first event of the tree walk will be processed for each mergedrule-setin turn and then the next tree walk event will be processed for eachrule-setin turn and so on, until the tree walk is complete. Theserule-setelements are really part of a simultaneously executing single tree walk that occurs for the top-levelrule-setelement.
Pattern Workers¶
It is possible to augment the TRPL language itself (at least the functionality available to expressions defined within rules) using pattern worker objects. These objects perform the grunt work of exposing symbolic constants, variables and user functions, such that they can be used within expressions. They may also be used to implement actions for the purpose of collecting, maintaining, and otherwise using information specific to a particular set of functionality, such as statitistical analysis or AST transformation. It is the pattern worker objects that provide the implementation behind the symbol resolver's ability to expose AST properties and structural relationships, for instance, or to collect statistics about language structure.
The list of pattern workers available to a rule-set is encoded ("imported") at the top of the rule-set.
Certain pattern workers are generally useful across a wide range of applications. These are registered directly by the pattern engine as default workers. The following are loaded by default:
CommonAstSupport(library qualifiercommon)PropsWorker(library qualifierprops)DictionaryWorker(library qualifierdict)FileOperationsWorker(library qualifierio)
Features of these libraries can be used without an explicit qualifier and without importing them at the top of a rule-set.
Event Model¶
The pattern engine is a tree processing framework where the engine handles the details of walking the tree and the programmer uses hooks or callbacks that are triggered based on specific events that occur during the walk. The pattern engine is programmed using a "rule-set" or a combination of rule-sets that are executed in series. These programs are written in an XML-based markup language. Each rule-set is separated into sections that define the type of tree walk event in which that section is executed. There are 6 different event types:
| Event Type | Occurs | Node in Scope | Notes |
|---|---|---|---|
<init-rules> |
once for each tree, before any other rule executes | tree root | Useful for initialization logic, especially for variables that are unique per-tree (a single instance is used to track state across an entire tree walk. |
<walk-rules> |
once for each node, this is the "primary" visit to the node | the current node being visited | Most logic is inserted in these rules. Anything that does not depend upon the order of processing children is usually placed here. |
<descent-rules> |
when the tree walk descends from a parent to its first child (it occurs after the parent has gotten its <walk-rules> and before the child gets its <walk-rules>) |
the parent node | Very useful for implementing scope-aware data structures (such as a stack). Scopes are normally pushed (added) on descent.
This never occurs for nodes that have no children. |
<next-child-rules> |
when the tree walk moves between siblings (it occurs after the current [left] sibling has gotten its <walk-rules> event and after all processing is complete for that left sibling's descendants and before the next [right] sibling gets its <walk-rules> event) |
the parent node | In rule-sets that convert a tree to a human readable form, these rules are highly useful for implementing differential processing based on the index of the child being processed (the "nextChildIndex"). For example, in converting the tree form of a Java method call (assume that the first child is the Object instance upon which the method is called) into a source code version, one might need to output a ".methodName(" after the first child has been processed but before all other children are processed.
This is generally useful in any case where processing needs to occur between the processing of any two children. This never occurs for nodes that have no children. |
<ascent-rules> |
when the tree walk ascends from the last child to its parent (it occurs after the last child has gotten its <walk-rules> event and after all processing is complete for the last child's descendants) |
the parent node | Very useful for implementing scope-aware data structures (such as a stack). Scopes are normally popped (deleted) on ascent.
In rule-sets that convert a tree to a human readable form, these rules are highly useful for closing processing after all children are processed. For example, in converting the tree form of a function call (assume that the children represent function call parameters) into a source code version, one might need to output a closing ")" after all parameters are emitted. This never occurs for nodes that have no children. |
<post-rules> |
once for each tree, after all other rules have executed | tree root | Useful for termination logic, especially for implementing any filesystem or database persistence that is done on a per-tree basis. |
To hook a particular event for a specific node, just insert a rule that matches that node using its logical condition. Then inside this rule, you can put any combination of actions and nested rules (which can have any combination of actions and rules inside it). While the pattern engine will visit every node (and trigger every one of the actions as needed), if you have no matching expressions to a given node, the node will be ignored.
The following diagram shows a trivial example. The legend lists each event in the order that the events are triggered. The event number matches the numbers on the tree nodes and the arrows. The arrows designate events that are triggered in between <walk-rules>, while moving between the visits of two related nodes. The numbers inside a node specify the case where there is a specific visit to a node (<init-rules>, <walk-rules> and <post-rules>).
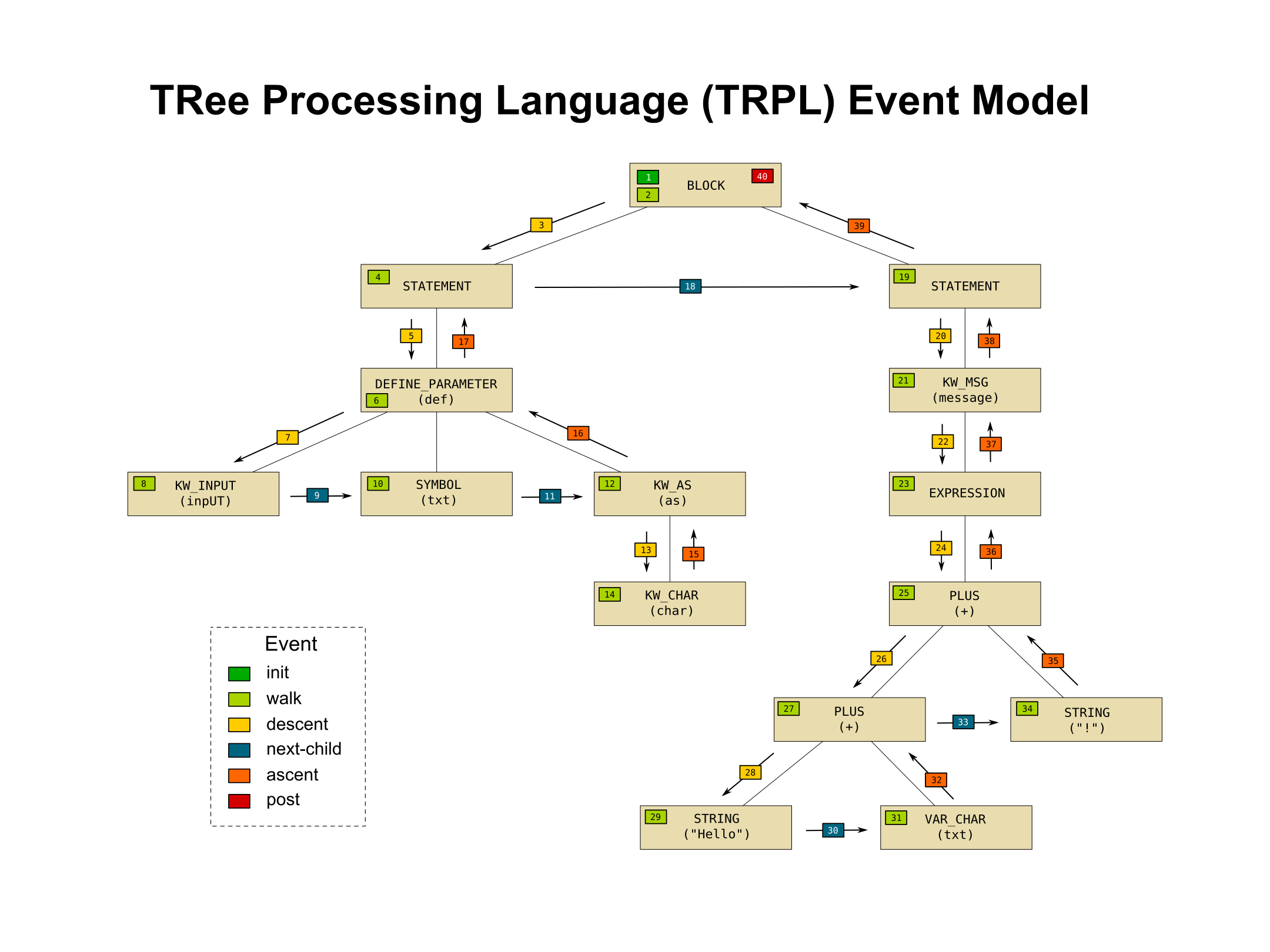
The numbers in the above diagram show the order in which these events occur. TRPL programs are written as sets of callbacks that are associated with a specific event. The TRPL engine processes each tree for each TRPL program and invokes those callbacks based on the matching events that are occurring.
Processing just the walk events for the whole tree would be the equivalent to the traditional visitor pattern. TRPL has a much richer set of events that make it easier to implement certain transforms or calculations than the simplistic visitor pattern.
TRPL programs can be pipelined to achieve incremental analysis or transformation, allowing complex processing to be split into a modular form.
Why Use TRPL?¶
The PatternEngine is a tree processor. It walks every node in the tree in a very defined manner (as shown by the event model above). A rule set is really a set of call-backs that are invoked in response to events occuring during the tree walk. So, if a rule set has walk-rules, each one is executed (in the order of occurance) when the walk of any node triggers the walk-rules "event". For each walk-rule in that rule set, the condition is evaluated and if it evaluates true, then the body (actions or rules) of the rule will trigger (and so on as things are nested inside). But if a rule-set has no rules that evaluate true for a given node, then that node is essentially ignored by the given rule set, even though it will be processed by the engine.
There is support for if/else conditional processing (this is the purpose of a <rule> which has a condition and then actions, rules and loops that can be used on either false or true) and loops (<while> which can be easily used to also simulate a for). Along with the variable support included (any kind of object can be instantiated or obtained and then all of its methods are available in rules and actions) and the assignment operator support, there is little that cannot be done directly in a rule set.
There is great power in letting the pattern engine handle the tree walking. The tree processing logic is expressed in a very compact form (much smaller than the corresponding Java program that implements the same logic) while still taking advantage of nearly every feature of the Java language. The only Java features that are not provided: array subscripting, static methods and some operators like "new". See Differences and Limitations Compared to Java.
The pattern engine removes the duplication of tree walking code that would be required in any set of Java programs that hard-code tree processing. This reuse reduces development time, makes the programs standardized, leverages tested/debugged/documented code and allows the developer to focus on the logic of the pattern matching and the objectives of what to do when a pattern is found.
PatternEngine Flow¶
The PatternEngine is launched as a command line driver, or it may be constructed, configured, and invoked programmatically. When launched from the command line, a configuration profile must be specified. Processing is invoked using the run method, which accepts the name of the profile to load and execute. The logic flow is as follows:
- begin
- perform global initialization processing:
- create a new symbol resolver
- initialize and register default worker objects
- load the pattern configuration profile
- set a default specification to find ASTs if not provided by profile
- apply global, user-defined
init-rules
- for each AST to be processed:
- for each ruleset defined in the pipeline:
- make a deep copy of the source AST hierarchy; this copy becomes the editable copy for the current ruleset pass and becomes the read-only source AST for the next ruleset in the pipeline
- perform ruleset-specific, initialization processing:
- configure the symbol resolver for the current ruleset
- set the source and copy root ASTs as the current ASTs in the symbol resolver
- apply user-defined
init-rulesfor the ruleset
- walk the AST (or the filtered view of results of previous ruleset) and generate the proper events
- apply all
walk-rulesof the ruleset to the each AST visited - apply
descent-rulesupon moving to the first child - apply
next-child-rulesupon moving from one child to another - apply
ascent-rulesupon moving back up the tree from the last child
- apply all
- perform ruleset-specific termination processing:
- set the source and copy root ASTs as the current ASTs in the symbol resolver
- apply user-defined
post-rulesfor the ruleset
- use the copy AST from the last ruleset as the source AST for the next ruleset
- for each ruleset defined in the pipeline:
- perform global termination processing:
- apply global, user-defined
post-rules - call each registered worker object's termination processing hook
- null out the symbol resolver
- apply global, user-defined
- end
Programming¶
A PatternEngine profile is a program which defines everything necessary for the engine to process one or more ASTs against a pipeline of rulesets. A profile is defined in one or more XML documents. A master document, the pipeline profile document, defines (usually specified in this order):
- imported pattern workers
- function libraries (imported or inline)
- variables
- one or more rule-sets (external or inline), containing sections for each event type
- global initialization and termination rules to be applied at the beginning and end of the processing session, respectively
A rule-set defines the rules (the control flow and programming logic) to be applied against each AST, based on the TRPL event (e.g. walk-rules or descent-rules).
An external rule-set document does not have the same top-level node of an profile document but instead it can contain (usually specified in this order):
- imported pattern workers
- function libraries (imported or inline)
- variables
- rules as noted above, enclosed in sections for each event type
A ConfigLoader object is responsible for parsing the pipeline profile document, for resolving any references to external ruleset profile documents, and for configuring the pattern engine using all of the information extracted from the resulting network of documents.
Pipeline and Ruleset Profile File Format¶
The same general XML grammar is used for both the master profile, which drives the entire pipeline of ruleset processing, and for each, individual ruleset within the pipeline. A pipeline profile must use the .xml file name extension; a ruleset profile must use the .rules file name extension. The ruleset profile file format is a subset of the pipeline profile format. The following describes the grammar.
The Scope column refers to P (profile) or R (rule-set).
| Element Name | Scope | Num | Valid Child Elements | Description |
|---|---|---|---|---|
cfg |
P | 1 | ast-spec
worker
include
variable
init-rules
descent-rules
rule-set
ascent-rules
post-rules
|
Outermost containing element (root) of the pipeline profile document.
No attributes are defined for this element. |
ast-spec |
P | 0+ | none | This element is deprecated and should not be used.
Defines a directory and file specification used to find a list of either (a) persisted AST files to process; or (b) root node entries in a call graph. If no such element is provided, such a specification must be provided at the pattern engine command line; otherwise, no processing will occur. Attribute: directory
Required: yes Description: An absolute or relative path to a directory which is the root of a directory tree containing .ast files (persisted ASTs), or which contains one or more .graph files (call graph definitions). If relative, the directory will be processed relative to the value of the P2J_HOME system property.
Attribute: file-spec
Required: yes Description: A regular expression used to identify the names of source files (i.e., .p or .w files) to be processed. The appropriate .ast or .graph file name extension will be appended automatically, depending upon the pattern engine mode of operation. |
worker |
P | 0+ | none | Defines a PatternWorker implementation for the pattern engine to load for a specialized task. Several pattern workers are loaded by default to provide standard services. This element gives the user the opportunity to load additional worker objects, to provide additional variables and/or user functions for a particular purpose.
Attribute: class
Required: yes Description: The fully qualified name of the PatternWorker implementation class to load within a worker element. Attribute: namespace
Required: no Description: Acts as an alias for types managed by the specified worker class, allowing them to be referenced more concisely in transformation rules. |
include |
P/R | 0+ | none | Loads a function library from the given rules filename. Whether this filename is unqualified or partially qualified, each segment in the pattern path is searched for the first file that matches. That file is loaded and any public func-library element in that file is made accessible.
Attribute: name
Required: yes Description: The unqualified or partially qualified name of the rules file to load. |
func-library |
P/R | 0+ | expression
function |
Provides a set of named expressions or functions which can be used in the current rule file or imported into an external rule file for use.
Attribute: access
Required: no Description: The string public or private. Private access means that the function library can only be accessed from within the same rules file. Public access allows the function library to be loaded (and then accessed) by any rules file. By default a function library is public. |
expression |
P/R | 1+ | none | Use of this element is discouraged. This should be considered deprecated.
Contains a single expression which is evaluated unconditionally. This is similar to an action element, except:
actions cannot be named
actions can be set to execute based on the boolean result of an enclosing rule element, expressions cannot do this
When directly contained inside of a func-library element, a named expression is the equivalent to a named function, except that the expression can only contain a single expression and none of the structure or contained elements of a function can be used.
Attribute: name
Required: no Description: The name of the expression. This is the first parameter (a string literal) to execLib() or evalLib(). |
function |
P/R | 1+ | parameter
variable
return
rule
while
expression |
Defines a named block of logic that:
Is only invoked explicitly by the use of CommonAstSupport execLib() and evalLib() methods. This code does not get implicitly called based on tree walking.
Can be invoked at any time in an expression, from any action or rule (even from other functions).
The logic can be specified as a single expression or as a set of one or more contained rule, while or expression elements. If a single expression is specified, this is done without any contained elements, instead the text of the function element itself must be a single valid expression that can be evaluated to a result. This non-element mode for defining a function is considered deprecated and should not be used for new functions. By default, if no return element is defined, the return value is the same as the last executed expression in the function (whether this expression is directly specified in the function element's text or whether this is a contained rule, action, expression or while element).
Variables that are in enclosing scopes can be accessed but this is discouraged. The function element is considered a new scope and can hide variables which have the same name in enclosing scopes. Some problems to note: Recursion is not allowed at this time. Actions can't be embedded directly in a function, but can be embedded inside a rule in a function. Pattern worker access is based on the worker definitions in the calling rule set NOT the rule set in which the function is defined. Attribute: name
Required: yes Description: The name of the function. This is the first parameter (a string literal) to execLib() or evalLib(). |
variable |
P/R | 0+ | none | Declares a user variable to use in rule expressions. Variables are global across rulesets if defined in the scope of a pipeline profile. Variables are local to an individual ruleset if defined within the scope of a ruleset profile.
Attribute: name
Required: yes Description: Name which will be used to refer to variable within user expression tests and assignments. Attribute: type
Required: yes (if init does not exist) Description: Data type of the variable. Valid entries are int, long, double, string, boolean or any fully qualified Java classname.
Attribute: init
Required: yes (if type does not exist) Description: An expression which when evaluated yields a result that is the initial value (and type) for the variable. |
parameter |
P/R | 0+ | none | Declares a parameter to use in a named function. This is equivalent to a local variable, except the value is assigned by the caller in the parameter list (2nd and subsequent parameters to the execLib() and evalLib() functions). Note that the order, type and number of the parameters in the function definition must match those passed in the function invocation.
Attribute: name
Required: yes Description: Name which will be used to refer to parameter within the function. Attribute: type
Required: yes (if init does not exist) Description: Data type of the parameter. Valid entries are int, long, double, string, boolean or any fully qualified Java classname.
Attribute: init
Required: yes (if type does not exist) Description: An expression which when evaluated yields a result that is the initial value (and type) for the parameter. |
return |
P/R | 0 or 1 | none | Declares a local variable, whose value will be returned to the caller of the function when the function completes. This also determines the type of the function's return value.
Attribute: name
Required: yes Description: Name which will be used to refer to return variable within the function. Attribute: type
Required: yes (if init does not exist) Description: Data type of the return value. Valid entries are int, long, double, string, boolean or any fully qualified Java classname.
Attribute: init
Required: yes (if type does not exist) Description: An expression which when evaluated yields a result that is the initial value (and type) for the return variable. |
rule-set |
P/R | 1+ | expr-library
include
variable
init-rules
descent-rules
walk-rules
ascent-rules
post-rules
rule-set |
Defines a set of rules and resources used by the pattern engine to process the information stored within an AST. Rulesets which are tightly coupled to the purpose of the pipeline's task may be defined inline, within the main pipeline profile document. Alternatively, more general purpose, reusable rulesets may be defined individually, within their own .rules files.
If defined within a .rules file, this element is the outermost containing element (root) of the profile document (rather than having an outermost cfg element).
If defined within a .xml file (the master profile document), this element can either define an entire ruleset inline, or refer to an external ruleset defined within a .rules file. If the element contains the name attribute (see below), it refers to an external ruleset profile. Otherwise, it is expected that an inline ruleset definition follows the opening tag.
This element defines a new scope for the purpose of resource access such as variables. Resources in enclosing scopes can be accessed but enclosing scopes cannot access resources defined within this element. Attribute: load-condition
Required: no Description: This attribute is processed only when the rule-set element is not the root element (to allow a function library to be included by other files unconditionally). It contains a comma-separated list of flags which will be checked only when conditional rule-set processing is activated (the PatternEngine.conditionalRuleSets field is set to true).
When conditional rule-set processing is activated, it will process all the rule-sets which have at least one load-condition flag matching one from the PatternEngine.activatedFlags set.
The following APIs from the PatternEngine class are related to conditional rule-set processing:
void setConditionalRuleSets(boolean) to enable or disable conditional rule-set processing.
boolean isConditionalRuleSets() to check the current state of conditional rule-set processing.
void addConditionalFlag(String) to add a new flag to the PatternEngine.activatedFlags set.
void removeConditionalFlag(String) to remove a flag from the PatternEngine.activatedFlags set.
boolean isFlagActivated(String) when conditional rule-set processing is enabled, it will check if the given flag is part of the activated flags.
boolean activeFlags(Set) when conditional rule-set processing is enabled, it will check if any flag from the given set is part of the activated flags.
Attribute: name
Required: no Description: If present, this attribute defines the name of an external ruleset definition which is included by reference in the master pipeline profile. It should not include the .rules file name extension. If this attribute is present, any information contained within the opening and closing rule-set tags is ignored.
There are 2 ways to use this external reference: Top-Level - when the rule-set element is contained directly within a cfg element, this is considered a top-level rule-set. Such a rule-set will have its contents executed in its entirety with a tree walk that is specific to that rule-set. Any other top-level rule-set elements in the same cfg element will be executed in order. This provides the pipelining feature to the master profile document. In a file with 2 top-level rule sets, the first rule set will be processed through a complete tree walk (with all nodes being visited and all events being triggered) before any processing in the second rule set will occur. Merge - when the rule-set element is contained within another rule-set element, this has the effect of merging the named rules file into the containing rule-set element as if those rules were defined there directly. This allows rules to be split into multiple different rules files but then walked as a combined set. In such a case, each of the merged rule sets will have their events triggered in the same order as the rule-set elements are merged. In a rule-set that contains merged rule-set elements, the first event of the tree walk will be processed for each merged rule-set in turn and then the next tree walk event will be processed for each rule-set in turn and so on, until the tree walk is complete. These rule-set elements are really part of a simultaneously executing single tree walk that occurs for the top-level rule-set element. If this attribute is not provided, an inline ruleset definition is assumed. Attribute: input
Required: no Description: Defines the type of input for this ruleset to process. Acceptable values are tree or view. A value of tree indicates that this ruleset should be applied against the entire AST hierarchy, regardless of the output of the previously processed ruleset in the pipeline. A value of view indicates that this ruleset should be applied only against the individual AST nodes which the previous ruleset in the pipeline added to its filtered view of ASTs. If this attribute is not provided, a default value of tree is assumed. Attribute: honor-hidden
Required: no Description: If present, this boolean value determines if the tree walk will include nodes that have their hidden flag set to true. An AST can have its hidden flag set by com.goldencode.p2j/uast.Aast.setHidden(). If honor-hidden is true, then hidden nodes will NOT be included in the tree walk. Note that "manual" dereferencing of nodes (e.g. this.getChildAt(4)) will still return hidden nodes. Attribute: depth
Required: no Description: The number of generations or levels a node is remote from the root node. The depth of the root node is 0; the depth of its immediate child nodes is 1; the depth of its grandchildren is 2; and so on. Depth is retrieved with <ref>.getDepth() or <ref>.depth.Attribute: execute-condition
Required: no Description: Execute rule set only if a condition is specified in p2j.cfg.xml file.Attribute: drop-condition
Required: no Description: Ignore rule set if a condition specified in p2j.cfg.xml file.Attribute: optional
Required: no Description: If the rule set is found and can be loaded it is executed normally, otherwise silently ignore the missing file event. |
init-rules |
P/R | 0-1 | rule |
A list of rules to run as initialization processing, either globally across all rulesets in the pipeline, or locally, within an individual ruleset. If defined within the pipeline profile document, the init rules are global; if defined within a ruleset profile document, the init rules are local to that ruleset.
Global init rules are applied once per pipeline, after pattern workers are initialized, but before any individual rulesets are processed. No AST is in scope for purposes of rule expression processing when the global init rule list is applied. Local init rules are applied each time a ruleset is applied against an AST, before any of the ruleset's walk rules are applied. The root node of the AST being processed by the current ruleset is in scope for purposes of rule expression processing when a local init rule list is applied. So, any rule expressions which refer to properties of an AST will use the root AST to resolve AST property variables or to apply changes against the AST. No attributes are defined for this element. |
descent-rules |
P/R | 0-1 | rule |
|
walk-rules |
R* | 0-1 | rule |
A list of rules to apply against an iteration of AST nodes. Depending upon the value of the input attribute of the enclosing rule-set element, this list of rules is either applied against every AST node in the current AST hierarchy, or against only those AST nodes included in the filtered view defined by the previous ruleset in the pipeline.
No attributes are defined for this element. |
ascent-rules |
P/R | 0-1 | rule |
|
post-rules |
P/R | 0-1 | rule |
A list of rules to run as termination processing, either globally across all rulesets in the pipeline, or locally, within an individual ruleset. If defined within the pipeline profile document, the post rules are global; if defined within a ruleset profile document, the post rules are local to that ruleset.
Global post rules are applied once per pipeline, after all individual rulesets have been processed, but before pattern worker termination processing takes place. No AST is in scope for purposes of rule expression processing when the global post rule list is applied. Local post rules are applied each time a ruleset is applied against an AST, after any of the ruleset's walk rules are applied. The root node of the AST being processed by the current ruleset is in scope for purposes of rule expression processing when a local post rule list is applied. So, any rule expressions which refer to properties of an AST will use the root AST to resolve AST property variables or to apply changes against the AST. No attributes are defined for this element. |
rule |
R* | 1+ | rule
while
action |
Defines a logical condition and an optional list of actions to perform if that condition is met or not met. The condition and actions are each defined as logical expressions. They may contain system/AST variables (exposed by pattern worker objects) or global or local user variables defined using the variable element.
CDATA may be used to contain the condition however, it is common to put the condition directly in the element text. Note that a rule with no contained elements is the functional equivalent of an action.
This element defines a new scope for the purpose of resource access such as variables. Resources in enclosing scopes can be accessed but enclosing scopes cannot access resources defined within this element. Attribute: on
Required: no Description: If true, this rule is executed if the enclosing rule's condition evaluates to true. If false, this rule is executed if the enclosing rule's condition evaluates to false. If not provided, defaults to true. |
while |
R* | 0+ | rule
while
action |
This is a looping construct. While the logical condition is true, the optional list of rules, whiles and actions are performed. Any contained elements which use the on="false" attribute are never executed as the concept of a while loop inherently precludes this. The condition is defined as a logical expression. They may contain system/AST variables (exposed by pattern worker objects) or global or local user variables defined using the variable element.
Attribute: on
Required: no Description: If true, this action is executed if the enclosing rule's condition evaluates to true. If false, this action is executed if the enclosing rule's condition evaluates to false. If not provided, defaults to true. |
action |
R* | 0+ | none | Defines an action to perform in the event the enclosing rule's condition is met or not met.
Attribute: on
Required: no Description: If true, this action is executed if the enclosing rule's condition evaluates to true. If false, this action is executed if the enclosing rule's condition evaluates to false. If not provided, defaults to true. |
break |
R* | 0+ | none | Defines a statement, which exits the containing while loop. |
continue |
R* | 0+ | none | Defines a statement, which jumps to the start of the containing while loop. |
Examples¶
TBD
Why XML¶
It was a short cut taken at the beginning of the project, with the intention to replace it with a proper parser before long. The team has never been able allocate time to that technical debt. It was a mistake which will be resolved at some point.
Developing Rule-Sets¶
Let the PatternEngine handle the tree traversal. As a developer of rule sets, you must only insert call-backs for those events that you care about. So you don't control the traversal, you instead control which events matter. A node is "skipped" by simply never matching it in the condition portion of the rule. This is simply a matter of carefully designing the rules such that they can only match the exact tree construct that you are looking for, and no others.
This is where it becomes important to review the related nodes and constructs in the parser that creates the tree since this is the authoritative source of what is possible. The general approach to identifying the pattern:
- Identify the token types that you are looking for. Writing a small testcase, running it through the parser and then reviewing the generated AST is a good way to do this.
- Identify the location(s) in the parser at which the construct you are trying to match is created. This shows you the possible structure (or context) in which the node(s) will be found.
- Search in the parser source for all other instances of the token types you are matching on. This will tell you if you need to make your rule conditions more specific in order to avoid false positives (matching where a match really doesn't exist). Many input data streams are heavily context sensitive. This means that the same tokens can be used differently based on context. In such context sensitive input streams, the matching rules generally must be more specific, often have a condition that tests data from multiple related nodes at once (e.g. the current node, the parent node, the parent's parent...).
Draw the pattern (the tree relationship/structure) out on paper as the above steps are taken. Once the unique pattern is defined, encoding this in rule form is usually very straightforward. Then add logic in the body of the rule to do whatever it is that is the objective of the rule.
How to Use Scoping During a Tree Walk¶
In many cases, one may need to keep a stack or a scoped dictionary of data to keep track of data which is inherently scoped. For example, in traditional languages the meaning of a particular symbol is different depending upon the subtree which is being visited. Due to the nesting features of many languages, it is often the case that there can be an arbitrary number of scoping levels.
Often a simple stack can be used for this, but a scoped dictionary is especially useful if you have > 1 variable which has the same scoping semantics. This is the more general case, so the following text will show how that works.
- The
DictionaryWorkeris already loaded as one of the base workers so it doesn't need to be added manually. Examine this class to understand how it works. The key point is that each dictionary is named using an arbitrary string and you may have any number of variables stored in this named dictionary. Each variable is also named using a string and can be gotten, put and queried to see if the dictionary contains such a variable. A stack of maps is used and each level in the stack is a different scope. You can add and delete scopes (maps) and when a variable is accessed, the stack of maps is searched from the top down until the variable is found or there is nothing more to search. - You may want to "clear" your dictionary at a known point, especially if you are processing multiple trees. In this example, 2 variables named "process" and "num" are "prepopulated" with the value 0:
<init-rules> <!-- keep track of the current scope --> <rule>deleteDictionary("my_scoped_dictionary")</rule> <rule>addDictionaryLong("my_scoped_dictionary", "process", #(long) 0)</rule> <rule>addDictionaryLong("my_scoped_dictionary", "num", #(long) 0)</rule> </init-rules> - Find the correct place to add scopes. This is typically in a walk-rule or in a descent-rule. You do this to ensure that anything deeper in the tree will see the latest version of the variables. In this examples, new versions of the variables are added to the new scope, though this could be split into rules triggered elsewhere.
<walk-rules> <rule>type == something <action>addScope("my_scoped_dictionary")</action> <action>addDictionaryLong("my_scoped_dictionary", "process", getSomeDataHere())</action> <action>addDictionaryLong("my_scoped_dictionary", "num", getSomeOtherDataHere())</action> </rule> </walk-rules> - Find the correct place to delete scopes. This is usually done in an ascent-rule since this is the moment when the subtree rooted at a particular node is known to have completed processing.
<ascent-rules> <rule>type == something <action>deleteScope("my_scoped_dictionary")</action> </rule> </ascent-rules> - Use the
dictionaryContains()orlookupDictionary*()methods to access the data and make decisions. Since these variables are scoped using a stack, this technique cleanly handles any amount of nesting. References to these variables always get the most recent version and when the variables go out of scope they automatcially get cleaned up by deleting the top scope from the stack.
Implementation Classes¶
The primary classes of interest are those that correspond with the constructs described in the introduction:
Ruleis the implementation of the conditional rule.AstSymbolResolveris the implementation of the symbol resolver.RuleSetis the implementation of the ruleset.PatternEngineis the implementation of the pattern engine, and also manages the ruleset pipeline.PatternWorkeris the interface which all pattern worker objects implement.AbstractPatternWorkeris a partial implementation of this interface to simplify the creation of concrete pattern worker implementations.
All of these classes are in the com.goldencode.p2j.pattern package.
© 2004-2022 Golden Code Development Corporation. ALL RIGHTS RESERVED.