Writing TRPL Expressions¶
- Writing TRPL Expressions
Introduction¶
This document is meant to provide guidance on the syntax and limitations of TRPL expressions. This is useful for writing conversion rules, general transformation processing and also for searching/custom reports in the Code Analytics tools.
It is important to read Understanding ASTs and TRPL before starting this chapter. TRPL expressions are useful in these cases:
- Creating new reports for Code Analytics.
- Writing custom search conditions in Code Analytics.
- Writing larger TRPL programs (a.k.a. "rule-sets") which embody more complete flow control and data processing. These can be used in the
PatternEngineto inspect, analyze, interpret and/or transform a group of ASTs in diverse ways.
The FWD project uses TRPL for both Code Analytics and for fully automated conversion of entire Progress 4GL applicatons to Java (see Conversion Technology Architecture). Details on how to write full TRPL programs (rather than just expressions), can be found in Writing TRPL Rule-Sets.
TRPL Expression Types¶
At the highest level, TRPL supports two types of expressions:
- Assignment
- Non-assignment
An assignment expression is one whose top level operation stores a literal, a variable value, or the result of a calculation or method invocation into a variable. This expression's top level operator is the assignment operator (=). This expression always returns null. Thus, inline or nested assignment operations are not possible. Examples of an assignment expression are:
myVar = 10 myVar = a + b myVar = null myVar = foo.getBar() myVar = a > b
A non-assignment expression is one which returns some object, but which does not assign it to a variable. Any object type supported by Java may be returned. It is up to the application or framework which uses the expression to capture the object and act upon it or analyze it according to the needs of the application or framework. Examples of a non-assignment expression are:
7 true myVar == a + b a > b a * b + 5 foo.getBar()
TRPL Syntax¶
The syntax supported by the TRPL expression engine is largely the same as that supported by the Java language itself as of J2SE version 1.4. Notable differences are discussed below.
All symbols are case-sensitive. In addition to basic, scalar expressions, method invocation using familiar Java syntax (object.method()) is supported. In addition, where the default type conversion behavior is insufficient, type casting is possible, using a modified syntax.
Features¶
TRPL syntax introduces a set of features aimed at making the development process smoother and more flexible by automating common data type and reference handling tasks. These features simplify expression handling in code by eliminating the need for explicit conversions, boxing/unboxing, null checks, and property management. Below, we explore the key features of TRPL syntax and how they are implemented under the hood, utilizing the methods within the Compiler and SymbolResolver classes and supporting structures like CodeUnit, ExtraAST, and related utilities.
The implementation relies heavily on a set of core tool classes that support the functionality of bytecode assembly, expression evaluation, and runtime type conversions. These classes play a critical role in organizing and managing bytecode instructions, abstract syntax trees (AST), and other related data structures during the expression compilation process.
Let's explore the following key components:ExtraAst: A specialized version of an Abstract Syntax Tree (AST) node that extends basic AST functionality. This class adds support for tracking additional metadata (like a user-defined object reference) and providing basic line/column number support, which is essential for debugging and error tracking.CodeUnit: The core unit that represents a logical group of bytecode instructions. Code units are used to structure the assembled bytecode for different operations. They can be nested, branched, and contain additional logic for stack management during code execution. This structure is crucial for the final bytecode generation.Compiler: This class orchestrates the compilation process. It parses infix expressions into ASTs, generates bytecode for logical operations, and assembles them into a compiled class. The compiled expression is encapsulated within a custom Java class that can be executed at runtime. TheCompilerclass handles the entire lifecycle from parsing, bytecode generation, and class creation to execution.SymbolResolver: This abstract base class is responsible for resolving symbols found in user expressions into objects and functions. TheSymbolResolverensures that the correct methods are invoked for variable and property access. It also manages variable pools segregated by scope, handling everything from the registration of user-defined variables to enforcing security around accessible methods. TheSymbolResolverprovides crucial functionality in managing and resolving symbols like constants, variables, and functions in user expressions. This class ensures a secure environment by verifying whether method calls are allowed during expression parsing and execution.
TRPL syntax has the following features:
1. Auto-boxing. This feature allows seamless integration within an expression between primitive data types and their associated Java wrapper objects. For instance, a variable of type java.lang.Integer can be assigned an int value directly in an expression; a method which requires a primitive boolean parameter may be invoked from an expression which passes a java.lang.Boolean object as that parameter. The TRPL expression compiler detects these conditions, determines that these fixups are required, and compiles instructions accordingly to perform the proper wrapping and unwrapping of data at expression execution time.
- Primitive and Object Interaction: TRPL expressions might contain both primitive types (like
int,boolean) and object types (Integer,Boolean). The TRPL compiler recognizes when these need to be converted to work together. - Automatic Boxing and Unboxing:
- Boxing refers to the conversion of a primitive type into its corresponding wrapper class (e.g., an
intbeing wrapped into anIntegerobject). - Unboxing refers to the conversion of a wrapper class into its corresponding primitive type (e.g., extracting the
intvalue from anIntegerobject).
When an expression requires an object but receives a primitive (or vice versa), the compiler automatically performs the boxing or unboxing operation to ensure the types match without explicit code from the programmer.
- Boxing refers to the conversion of a primitive type into its corresponding wrapper class (e.g., an
Method Implementation (Compiler.convertToRequiredType):
convertToRequiredType plays a crucial role in implementing auto-boxing and unboxing in TRPL. It handles the conversion between primitive and reference types, and even between different types of wrapper classes. Here's how it works:
- Primitive to Reference Conversion: If a primitive is provided and a reference (e.g.,
Integer) is required, TRPL automatically wraps the primitive into the corresponding wrapper class. This is achieved using theassembleNewObjectReference()method and the relevant class from theWRAPPERSmap. - Reference to Primitive Conversion: If a reference is provided but a primitive is required, TRPL performs unboxing by invoking the relevant
assemblePrimitiveUnwrap()method to extract the primitive value.
// Example logic for boxing a primitive to a reference type.
if (primToRef || wrapToWrap) {
outer.addCodeUnit(assembleNewObjectReference(required));
}
- Null Checking: If the provided object is null, a branch is inserted to skip the expression evaluation using
logData.getFalseTarget()andCodeUnit.
Example Scenario in TRPL:
<expression>referenced = (exprRef.isAnnotation("referenced") and
(#(boolean) exprRef.getAnnotation("referenced"))) or
(type != prog.kw_count and type != prog.kw_sub_cnt)</expression>
Here, referenced is expected to be a boolean primitive, but exprRef.getAnnotation("referenced") may return a Boolean object. The TRPL expression compiler detects this and automatically converts (unboxes) the Boolean object into the corresponding primitive boolean before evaluating the expression.
2. Automatic Type Conversion. Similar to auto-boxing, the compiler will detect when a provided data type must (and can) be converted to a required type at expression execution time. This feature will perform both widening numeric and object reference conversions, as well as narrowing conversions. Note that this is a double-edged sword; truncation and data/precision loss may occur in a narrowing conversion. Thus, some of the safety of strict typing may be lost with this convenience, as the compiler assumes that the author of an expression knows best.
How It Works:- Widening Conversion: If an expression expects a larger or more inclusive type, the TRPL compiler will automatically widen a smaller or more specific type to meet the requirement. For example, it might convert an
intto alongor afloatto adoublewithout requiring manual intervention from the developer. - Narrowing Conversion: If the expression requires a more specific or smaller type, the compiler will perform a narrowing conversion. For example, if an expression expects an
int2 but receives a @long, the TRPL compiler will automatically cast it to the correct type. However, narrowing conversions can cause data truncation or loss of precision (e.g., converting a double to an int).
Compiler.assemblePrimitiveConversion):The method
assemblePrimitiveConversion is responsible for performing numeric type conversions between different primitive types (e.g., int to long, float to double). It uses specific opcodes to perform the conversion at runtime:
- Widening: Converting from a smaller primitive type to a larger one (e.g.,
inttolong). - Narrowing: Converting from a larger primitive type to a smaller one (e.g.,
doubletoint).
// Example for numeric type conversion from int to long:
if (provided == Integer.TYPE && required == Long.TYPE) {
opCode = _i2l; // Opcode for converting int to long.
}
Example Scenario in TRPL:
<rule>name == null
<action>name = execLib("lookup_name", expr, nameMap)</action>
</rule>
In this case, execLib("lookup_name", expr, nameMap) returns a value that might be of type java.lang.Object, but name is expected to be a String. The TRPL compiler would automatically convert the returned Object to a String before assigning it to name, ensuring the correct type is used.
Another scenario involves narrowing conversion:
<expression>exprRef.getValue() == (exprVal + 1)</expression>
If exprVal is a double and exprRef.getValue() returns a long, the TRPL compiler will automatically convert exprRef.getValue() from long to double to ensure that the arithmetic operation can proceed smoothly.
- Widening Conversion: Automatically converting smaller types to larger types (e.g.,
inttolong,floattodouble). - Narrowing Conversion: Converting larger types to smaller types (e.g.,
doubletoint). This could lead to truncation, so it's done carefully. - Object Reference Conversion: If one object reference type is needed but another is provided, the compiler can attempt to cast the object or convert it to the required type, as long as the types are compatible.
3. Automatic Null Checking. In (and only in) expressions which evaluate to a boolean result or which contain sub-expressions which evaluate to a boolean result, object references retrieved at runtime are checked for null before they are dereferenced by the expression, in order to avoid the expression from throwing a NullPointerException. If an object reference involved in some boolean operation evaluates to null, that operation will always evaluate to false. On the other hand, if an object reference is passed as a parameter to a method, it is not first checked against null, as the compiler can not presume in this case that a null parameter passed to a method call is invalid.
- Boolean Expressions: If an expression involves a boolean result and references an object, TRPL checks for
nullbefore evaluating the expression. - Object Null Handling: If an object reference is null, the boolean operation is short-circuited, returning
false. This ensures that the expression does not throw aNullPointerException.
Method Implementation (Compiler.convertToRequiredType with Null Check):
The method convertToRequiredType handles null checking for expressions that involve boolean results. If a null object reference is encountered, a branch is inserted to ensure the expression evaluates safely to false.
// Example logic for null-checking an object reference in a boolean expression.
if (logData != null && !providedPrim) {
CodeUnit notNullUnit = new CodeUnit(true, notNullDest, NOT_NULL, false);
notNullUnit.addInstruction(_dup);
notNullUnit.addBranchInstruction();
CodeUnit gotoUnit = new CodeUnit(true, logData.getFalseTarget(), GOTO, false);
gotoUnit.addCodeUnit(popUnit);
gotoUnit.addBranchInstruction();
outer.addCodeUnit(notNullUnit);
outer.addCodeUnit(gotoUnit);
}
Example Scenario in TRPL:
- The condition
is automatically null-checked by the TRPL compiler.parent.type == prog.kw_all and getNoteBoolean("enable_all") - Before evaluating
parent.type, TRPL ensures parent is notnull. - If
parentisnull, the entire condition evaluates tofalse, preventing an exception. - If
parentis valid, execution continues as expected.
4. Property Notation. Properties of an object accessible to an expression, which are exposed via a bean-like API, can be referenced from an expression using a shorthand notation which eliminates the semantics of method invocation. For instance, if an object foo has methods, int getBar() and void setBar(int), they can be referred to respectively, in expressions as follows: foo.bar > 10 and foo.bar = 55.
- Property Access: The TRPL compiler recognizes when an expression accesses a property (like
foo.bar) and automatically resolves the getter or setter method associated with the property. - Getter/Setter Method Resolution: If a property access is encountered, the compiler will look for the corresponding getter (
get<Property>) or setter (set<Property>) methods and convert the shorthand notation into the appropriate method calls.
Method Implementation (SymbolResolver.resolveFunction): The resolveFunction (SymbolResolver.resolveFunction) helps resolve the appropriate getter or setter for a given property. It identifies whether the property belongs to a read-only callback library, whether it's a user-defined variable, or whether it corresponds to a standard getter/setter method.
// Example logic for resolving property access.
resolveFunction(function, name, isSetter, scope);
This method ensures that the correct getter or setter method is called when the shorthand notation is used in an expression.
The resolveFunction method works by searching for the corresponding getter or setter method within the current scope and its enclosing scopes, ensuring proper method resolution for property access.
Supported Data Types¶
TRPL expressions can contain string, integral, and floating point literals, as well as any Java Object reference.
Literals are used as follows:- String literals are quoted text, delimited by either double or single quotes (e.g.,
"Hello World",'Hello World'). String literals are auto-boxed to instances ofjava.lang.String. - Integral literals are base 10 numbers without a decimal point, optionally preceded by a unary minus sign (e.g.,
100,-9999). They are mapped to the Java primitive data typelong. Integral literals are auto-boxed to instances ofjava.lang.Long. - Hex literals are base 16 numbers designated by a
0xprefix (e.g., 0x01, 0xffff). Hex literals are auto-boxed to instances ofjava.lang.Long. - Floating point literals are base 10 numbers with a decimal point, optionally preceded by a unary minus sign (e.g.,
1.234,-56.7). They are mapped to the Java primitive data typedouble. Floating point literals are auto-boxed to instances ofjava.lang.Double. - Boolean literals are the logical constants
trueandfalse. Boolean literals are auto-boxed to instances ofjava.lang.Boolean. - The
nullliteral represents the null value. Typically, this is used with the==or!=operator to test whether the opposite operand is or is not the null value, respectively.
- as the return value of a method call (e.g.,
this.getText()during a tree walk returns a the text associated with the active AST node as ajava.lang.String); - as the return value of a property accessor shorthand call (e.g.,
this.textduring a tree walk returns a the text associated with the active AST node as ajava.lang.String); - as the return value of a user-defined function (e.g.,
getNoteBoolean("my-annotation")during a tree walk returns the logical value stored in an annotation calledmy-annotationin the active AST node as ajava.lang.Boolean, ornullif there is no such annotation); - as an exported resource from a registered worker library;
- as the return value of one of the special
create*functions (e.g.,stringBuilder = create("java.lang.StringBuilder", 64)ormyListOfStrings = createList("a", "b", "c", "one", "two", "three")); - by de-referencing a variable (e.g.,
myVar); - by auto-boxing1 a literal value;
- by auto-boxing1 a primitive value returned by a method call.
Notes:
- Object instances might be created implicitly by TRPL's auto-boxing feature. For example, given the existence of a variable
lineNumberof typejava.lang.Integer, the execution of the expressionlineNumber = 1or, during a tree walk, either of the expressionslineNumber = this.getLine()orlineNumber = this.line, would result in the implicit creation of ajava.lang.Integerobject instance. This happens because the right operand of the assignment operator evaluates to a primitive value of typeint. In order to enable the assignment to the left operand's type ofjava.lang.Integer, TRPL's auto-boxing feature creates an instance of thejava.lang.Integerclass in which to store thisintvalue, then assigns a reference to that object into thelineNumbervariable.
Method Invocation¶
The TRPL expression engine supports the direct invocation of arbitrary methods against an object reference using the dot (.) operator. This always requires an object instance upon which to apply the invocation (even for static methods). An unqualified method invocation will fail to compile, since unlike Java, the TRPL expression engine provides no implicit this reference by default. Likewise, a static method invocation qualified by a class name will fail to compile, since there is no implicit class resolution.
There are libraries of worker functions that can be imported as global methods that can be imported. Some workers are always implicitly imported:
CommonAstSupport(library qualifiercommon)PropsWorker(library qualifierprops)DictionaryWorker(library qualifierdict)FileOperationsWorker(library qualifierio)
Features of these libraries can be used without an explicit qualifier and without importing them at the top of a rule-set.
Other than the above caveats, syntax for method invocation in a TRPL expression is quite similar to method invocation in Java. It takes the form:
<object reference>.<method name>([param1 [, ...]])
For instance, given a variable string1 of type java.lang.String, initialized to "Hello World", the following represents a valid invocation of a java.lang.String method:
string1.indexOf('He')
which would return 0 upon execution.
Differences/Limitations Compared to Java Syntax¶
Please note there are a number of differences and exceptions to the TRPL expression engine's support for Java syntax:
- No direct static references. Static references in the form
<class name>.<static member name>are not supported. For method invocation, one must either have an object instance upon which to invoke a method with the dot operator (.), or one must be invoking a user function in a registered callback library. - Special typecast syntax. If casting an object reference to a class type, the fully qualified class name is required. In addition, the opening left parenthesis is preceded by the hash symbol (
#). For example, given a variablemyIntegerof typejava.lang.Integer, an objectfoo, and a method offoowith signatureObject getIntegerAsObject(), which is known to return ajava.lang.Integer(widened to ajava.lang.Object), the following cast would be appropriate:myInteger = #(java.lang.Integer) foo.integerAsObject - No inline assignments. Assignments only can be made at the top level of an expression. Thus, the following expression is not valid:
(myVar = a + b) > 24, because the assignment tomyVaroccurs inline, whereas the greater than (>) comparison is made at the top level of the expression. - No
newkeyword. There is no direct support in the TRPL expression engine for the construction of new object instances. Object references are available only from callback library methods (user functions) and from variable references. Any support for the construction of new object instances must be provided by the application code which uses the expression engine. - Arrays not supported. There is no syntax to create arrays, nor to reference array elements by subscript. As an alternative, use
java.util.Listand its implementation variants. - String delimiters. Strings literals embedded within expressions may be delimited by either single quotes (e.g.,
'Hello World') or by double quotes (e.g.,"Hello World"), so long as the same character is used on both ends of the string. Note that it is possible to mix and match the delimiter for different strings within the same expression. However, this is bad form and should be avoided unless it is necessary to escape one delimiter, and then the other, from within the same expression. - No support for
charliterals. Primitive characters are not supported within expressions as literals; any single character inside single quotes is instead interpreted as a string of length one. However, values of typecharmay be returned from method calls and passed as parameters to other methods, just as any other primitive or object. For instance, the following expression is valid:string1.indexOf(string2.charAt(7)) >= 0 - String literals may not be dereferenced. Thus, the following syntax is invalid:
"Hello World".length(). Instead, intermediate storage of a string literal in a variable is necessary to perform this type of dereferencing. - Several operators are not available:
new(see above)instanceof- string concatentation (
+) - ternary (
?:) - increment (
++) - decrement (
--) - assignment combination operators (
+=,-=,*=,/=,%=,|=,&=,^=,>>=,<<=,>>>=)
- Method call chaining is limited. Calls may be chained from a variable or from the result of an explicit method/user function invocation. No other forms of call chaining are supported. In particular, one cannot chain a method call from a parenthesized sub-expression.
- No
importstatement. All class name references must be fully qualified. - Generics not supported. The generics syntax added to Java in version 5 is not supported at this time.
Supported Operators¶
The set of operators which may be used within expressions is listed in the table below. Operators in this table are listed in order of their precedence, from those evaluated first to those evaluated last. Operators which have the same precedence are grouped together. When evaluating operations whose operators have the same precedence, operations are performed in the order in which they appear, from left to right. Parentheses (()) may be used to group operations which must be evaluated in a different order.
| Precedence | Symbol | Type | Unary/Binary | Operation Performed |
|---|---|---|---|---|
| 0 | . |
Special | Binary | Method invocation |
| 1 | ! or not |
Logical | Unary | Logical complement |
| 2 | ~ |
Bitwise | Unary | Bitwise complement |
| 3 | - |
Arithmetic | Unary | Negation |
| 4 | * |
Arithmetic | Binary | Multiplication |
/ |
Arithmetic | Binary | Division | |
% |
Arithmetic | Binary | Modulo/Remainder | |
| 5 | + |
Arithmetic | Binary | Addition |
- |
Arithmetic | Binary | Subtraction | |
| 6 | << |
Bitwise | Binary | Left shift |
>> |
Bitwise | Binary | Right shift w/ sign extension | |
>>> |
Bitwise | Binary | Right shift w/ zero extension | |
| 7 | < |
Logical | Binary | Is less than |
<= |
Logical | Binary | Is less than or equal to | |
> |
Logical | Binary | Is greater than | |
>= |
Logical | Binary | Is greater than or equal to | |
| 8 | == |
Logical | Binary | Is equal to (primitive or object identity) |
!= |
Logical | Binary | Is not equal to (primitive or object identity) | |
| 9 | & |
Bitwise | Binary | Bitwise AND |
| 10 | ^ |
Bitwise | Binary | Bitwise XOR |
| 11 | | |
Bitwise | Binary | Bitwise OR |
| 12 | && or and |
Logical | Binary | Logical AND |
| 13 | || or or |
Logical | Binary | Logical OR |
AST Basics¶
In order to write TRPL expressions to examine and manipulate ASTs, it is important to understand a few basic concepts.
Token Types¶
Each AST node has a token type. This is an integer value that identifies the meaning of the node. In a TRPL expression, however, a human-readable token name is used instead of the integer value. Different types of ASTs use different sets of token type to token name mappings. FWD separates these by namespaces:
prog- Progress token types (seeProgressParserTokenTypes). This namespace is available when using the Code Analytics tool set and during code and schema conversion.java- Java token types (seeJavaTokenTypes). This namespace is available during code and schema conversion.xml- XML grammar token types (seeXmlTokenTypes). This namespace is available during code and schema conversion.data- Data model token types (seeDataModelTokenTypes). This namespace is available during schema conversion.
Namespaces are used as qualifiers in TRPL expressions, so that the correct token type to name mapping is used. For example, prog.kw_for specifies the token type for the Progress 4GL FOR statement; java.kw_for specifies the token type for the Java for statement.
Node Text¶
For ASTs generated by the parser, the text property of an AST node usually represents the text of the original symbol in the code that was parsed. This might be the name of a variable or field, or a keyword in the language. This text is usually left in its original form. Since it is not normalized into any regular form, the node text is not always the most reliable property of an AST on which to match a pattern. Symbols might be abbreviated or might be inconsistently cased, making matching problematic.
Annotations¶
An annotation is arbitrary information that is added to an AST node with a given label, so it can be retrieved later. Annotations are added by the parser to store information that isn't inherently available from the tree structure or other standard properties of an AST. Downstream processing by TRPL programs adds many more annotations. Certain annotations are extremely useful for pattern matching, particularly for reporting features. One such example is the schemaname annotation which is a qualified, canonical name attached to the AST node of every database table and field reference in an application's business logic.
Structural Relationships¶
The structure of an AST is key to its meaning. The tree structure represents the syntax of the language expressed in its most pure form. The relationships between nodes when combined with token types, encode the meaning of language constructs the AST represents. It is important to understand the structure of an AST in order to write a TRPL expression which describes the meaning of the underlying code construct.
Some common terms used to describe the structure of an AST follow. Where the placeholder <ref> is used in an example expression, it represents an Aast object reference.
- node - One point or location in the tree which represents a single token of code. Every node has a token type and text (could be an empty string) associated with it. Every node except the root of the tree has a single parent; each node has 0 or more direct child nodes. Every node of type
Aasthas a unique numeric identifier associated with it. - this - The "active" node; the node which is the focus of the current event during a tree walk.
- root - The single ancestor of the entire tree. The root is the only node in a tree which has no parent. Thus, a call to
<ref>.getParent()at the root node will returnnull. Retrieved with<ref>.getRoot()or<ref>.root. - depth - The number of generations or levels a node is remote from the root node. The depth of the root node is 0; the depth of its immediate child nodes is 1; the depth of its grandchildren is 2; and so on. Depth is retrieved with
<ref>.getDepth()or<ref>.depth. - leaf - A node which has no children. "Leaf-ness" can be tested with
<ref>.isLeaf()or<ref>.leafor the helper functionleaf(). - ancestor - A node which has a direct lineage to another node and which has a lower depth. There are several variants of the
getAncestorandancestormethods and helper functions to retrieve ancestor nodes or test whether an ancestor node with certain properties exists, respectively. - descendant - A node which has a direct lineage to another node and which has a higher depth. There are several variants of the
descendantmethods and helper functions to test whether a descendant node with certain properties exists. - parent - The direct ancestor of another node. A node can have 1 or 0 parents. Multiple nodes may have the same parent. Retrieved with the method
<ref>.getParent()or the shorthand<ref>.parent, or simply the helper functionparent. - child - The direct descendant of another node. A node can have 0 or more children. The first of a node's children can be retrieved (as a
BaseASTobject) with<ref>.getFirstChild()or<ref>.firstChild. An arbitrary child node can be retrieved (as anAastobject) with<ref>.getChildAt(N), where N is a zero-based index. - sibling - A different child node with the same parent. Siblings are retrieved with calls to
<ref>.getPrevSibling()or<ref>.prevSibling(as anAastobject) or with<ref>.getNextSibling()or<ref>.nextSibling(as aBaseASTobject), relative to the active node.
The authoritative reference for the Progress ASTs created by the FWD parser is the parser's grammar definition, located in the source code at src/com/goldencode/p2j/uast/progress.g.
Common/Useful AST Methods¶
When walking an AST, it is common to invoke methods of the AST object itself to extract property data or contextual information. Some useful methods include:
| Method | Class | Purpose | Example(s) |
|---|---|---|---|
getType |
CommonAST | Retrieve token type | this.getType()parent.type |
getText |
CommonAST | Retrieve node text | this.getText()this.firstChild.text |
getFirstChild |
BaseAST | Retrieve first child node | this.firstChild |
getNextSibling |
BaseAST | Retrieve next sibling node | this.nextSibling |
getLine |
BaseAST | Get line number of parsed code | this.line == 12 |
getColumn |
BaseAST | Get column number of parsed code | colNum = parent.getColumn() |
ancestor |
Aast | Check if node has an ancestor of a certain type | this.ancestor(-1, prog.record_phrase) |
descendant |
Aast | Check if node has an descendant of a certain type | this.descendant(0, prog.string) |
getAnnotation |
Aast | Retrieve a previously stored annotation object | name = this.getAnnotation("my-name")name2 = this.getAnnotation("name-array", 2) |
getChildAt |
Aast | Get a child node at the specified index | this.getChildAt(2)parent.getChildAt(1) |
getFilename |
Aast | Get source file name associated with an AST | this.filename == "example.p" |
getId |
Aast | Get the unique identifier of the node | this.id |
getIndexPos |
Aast | Get index of a node among its siblings | this.getChildAt(node.indexPos) |
getNumImmediateChildren |
Aast | Get count of a node's direct children | parent.numImmediateChildren > 1 |
getParent |
Aast | Get parent node | myParent = this.parent |
upPath |
Aast | Report if node's path upward matches given path | this.upPath("KW_RUN/KW_ON") |
This list is not exhaustive; there are many more useful methods that are accessible from TRPL. Please follow the links for the classes and interfaces referenced in the table above to explore their public APIs.
AST Helper Functions in FWD¶
Many helper functions have been added to FWD for use from TRPL expressions, to make it easier to examine and manipulate ASTs and the environment while performing a tree walk. Helper functions differ from methods in that they behave somewhat like Java static methods; that is, they do not require an object reference against which to be invoked. They operate within the context of the TRPL tree walk event with which they are associated.
Helper functions which have a bean-like API may be invoked using the same shorthand notation available for method calls. For example, a helper function named getFoo() can be invoked simply as foo; a function named isBar can be invoked simply as bar.
The following functions are some of the more commonly used helpers defined in the CommonAstSupport.Library class:
| Function | Purpose | Example |
|---|---|---|
evalLib |
Evaluate a library function which returns a true/false result 1 | evalLib("fields") and getNoteString("schemaname").startsWith("database1.employee") |
getCopy |
Retrieve the mutable copy of the AST node being walked 2 | copy.text == "Hello!" |
getNoteBoolean |
Retrieve an annotation of type java.lang.Boolean 3 |
getNoteBoolean("builtin") |
getNoteDouble |
Retrieve an annotation of type java.lang.Double 3 |
xPos = getNoteDouble("position-x") |
getNoteLong |
Retrieve an annotation of type java.lang.Long 3 |
getNoteLong("table_count") > 1 |
getNoteString |
Retrieve an annotation of type java.lang.String 3 |
key = getNoteString("name").toLowerCase() |
getParent |
Get the parent node of the AST node being walked | parent.isAnnotation("extent") |
getThis |
Get the AST node being walked | this.firstChild.type == prog.table |
getText |
Get the text of the AST node being walked | ref.putAnnotation("name", text) |
getType |
Get the token type of the AST node being walked | type == prog.var_char |
isNote |
Determine whether an annotation exists 3 | isNote("refid") |
putNote |
Set an annotation in the current AST node 3 | putNote("legacy_name", parent.text) |
- See the
rules/include/common-progress.rulesTRPL library in the FWD source code for many useful library functions that can be invoked from within TRPL. - When FWD walks an AST, it first makes a mutable, working copy of the AST being walked. The walk is then performed using the original, source AST. This allows annotations to be added to the copy or for the copy to be transformed, without changing or breaking the walk itself. The source AST (referenced via the
thisorsourcereserved variables) should never be modified during a walk; all access should be read-only. - The
getNote*,isNote, andputNotehelper functions operate in the context of the mutable working copy of the currently active node. This allows for annotations added during earlier events in the walk to be available for retrieval when later events in the walk are fired.
This list is not exhaustive; there are many more useful helper functions that are accessible from TRPL. Please explore the CommonAstSupport.Library API for further information.
Writing TRPL Pattern Matching Expressions¶
FWD uses TRPL to match patterns in Abstract Syntax Trees (ASTs). As discussed in Understanding ASTs and TRPL, FWD parses Progress 4GL source code into ASTs and provides a tree walking engine which visits the individual nodes of an AST in a well-defined order, firing events at various points of the walk. TRPL expressions can be associated with these events to match patterns in the structure and content of an AST.
Anatomy of a Sample Pattern Matching Expression¶
A TRPL pattern matching expression must be a non-assignment expression which returns a logical (i.e., boolean) result: true or false. If the result is true, the desired pattern has been matched. Conversely, if the result if false, it has not.
For example, the following TRPL expressions each use slightly different syntax to determine whether the current AST node represents a 4GL DEFINE BUFFER language statement:
this.getType() == prog.define_buffer this.type == prog.define_buffer type == prog.define_buffer
The above expressions are all equivalent in function. Let's break the first and most verbose form of the expression down into its constituent parts:
this . getType() == prog . define_buffer
| Token | Purpose | Description |
|---|---|---|
this |
active node reference | TRPL syntax on its own does not define an implicit object reference named this. However, the FWD tree walking engine does. The reference this represents the AST which is the focus of the tree walk event which has fired. The meaning of this varies by event type. Most commonly (i.e., for a walk event), it refers to the AST node currently being visited. However, the meaning differs for a descent event, for instance: it refers to the parent node most recently visited, to whose first child node the walk is descending. |
. |
dot operator | In this case, the dot (.) represents the method invocation operator. The left operand is a Java object reference and the right operand is a method to be invoked. |
getType() |
method invocation | This is the method to be invoked on the this object reference. It uses the same method invocation syntax as Java. In this case, the method takes no parameters, but if there were parameters, they would be specified with the same syntax as in Java. The this object reference is actually to a Java object instance of type AnnotatedAst. Any public method of that class can be invoked in this way. The getType() method will return a constant of type int, which represents the token type assigned to the AST. |
== |
equality operator | This operator compares its left and right operands for equality by value. In this case, both operands will evaluate to values of the Java primitive type int. As the lowest precedence operator in the expression, this equality test is performed last, and the result of this test is the overall result of the expression: true if the active node represents a 4GL DEFINE BUFFER language statement; otherwise false. |
prog |
namespace qualifier | FWD defines various constants in different well-known namespaces. For example, constants which represent Progress 4GL language token types are defined in the prog namespace; Java language token types are defined in the java namespace. The namespace qualifier must used in a TRPL expression to disambiguate constants across namespaces. |
. |
dot operator | In this case the dot operator (.) is used to separate a constant namespace qualifier from the constant itself. |
define_buffer |
FWD constant | DEFINE_BUFFER is the well-known constant which represents the token type for a 4GL DEFINE BUFFER statement. All the token type constants for the prog namespace are defined in the ProgressParserTokenTypes interface. |
The second TRPL expression is a less verbose form which performs the same pattern match:
this.type == prog.define_buffer
The only difference compared to the first expression is that the method invocation this.getType() has been replaced with the shorthand notation this.type. This will invoke the Aast.getType() method under the covers.
The third TRPL expression is the least verbose form. It still performs the same pattern match:
type == prog.define_buffer
In this case, the FWD tree walking engine understands from context that type actually is a reference to the FWD helper function getType(), which it will invoke invoke accordingly.
When a pattern is matched, typically some unit of work is performed. For example, content might be added to a report about the 4GL source code being analyzed; the AST node might be annotated, edited, transformed, copied, or persisted; or it could be anti-parsed back into source code.
Understanding What to Match¶
Writing a TRPL expression to match a particular AST pattern presupposes an understanding of the target pattern. Essentially, you are describing the structure and/or content of some portion of an AST using TRPL syntax. One of the simplest ways to gain an understanding of the structure and content you are describing is to write or identify a particular snippet of 4GL code and to explore the AST FWD creates after parsing that code.
This section describes the generic process for writing an expression that matches a specific AST pattern.
1. Examine the AST structure that corresponds to the code you are trying to match.
If the code idiom already exists in the application, use the predefined reports in the Code Analytics to find locations that already exist. Display those nodes in the Source View use the companion AST View to explore the AST. The following is an (annotated) AST visualization of DEFINE BUFFER:
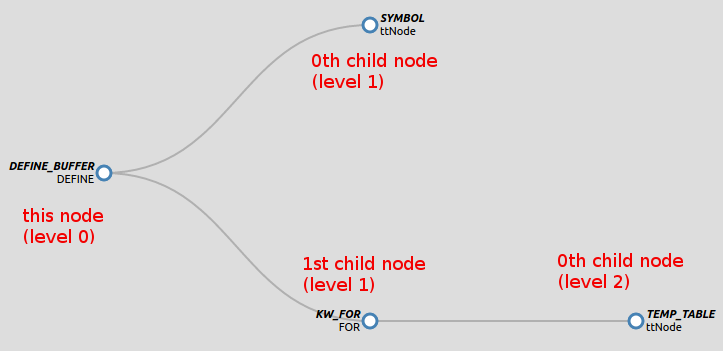
The original 4GL code represented by this AST branch is:
DEFINE BUFFER ttNode FOR TEMP-TABLE ttNode
We can see that parsing this statement produced a parent node with token type DEFINE_BUFFER and text DEFINE. Notice that the BUFFER token has been dropped. The parser combined its information with that of the DEFINE token to produce the DEFINE_BUFFER node. This makes downstream processing simpler, because now we can just match on the single token type DEFINE_BUFFER instead of devising the more complicated pattern match that would be necessary had two separate but related DEFINE and BUFFER nodes been left behind by the parser.
The DEFINE_BUFFER node has two child nodes. The first has token type SYMBOL and text of ttNode. This is the name of the buffer being defined.
The second child of the DEFINE_BUFFER has token type KW_FOR and text of FOR. In this case, the text is somewhat redundant, since the token type is enough to identify the node in this context.
The KW_FOR node itself has a child with token type TEMP_TABLE and text ttNode. This represents the temp-table for which the buffer is being defined.
2. In the AST nodes that are related to the pattern you are matching, decide which node is the best situated.
Usually this is about finding the node that is most "centrally" located. All the context for the expression is written from that node’s "perspective". From this node, the parent, previous sibling, next sibling and children all can be inspected as part of the expression. The more central the node, the simpler the references can be.
Since the 4GL syntax is directly represented in the structure of the AST itself, much of the pattern matching must model the syntactic structure of the AST pattern being matched.
3. Use the token type first, to roughly match a set of possible nodes. Refine this to get an exact match by adding use of tree structure, annotations and text.
It is usually most efficient to filter on token type first, both in terms of writing the most compact and expressive pattern match expression, and in terms of compute speed.
See below for some common examples based on the simple AST structure pictured above.
Don’t Fight the Tree¶
Let the structure of the AST solve the problem for you. TRPL will walk the tree for you. Your expression is being executed at each possible location in the entire application. It is a "callback" model with the events determined by the tree structure.
The tree structure is the pure form of the 4GL language syntax as represented in your code. Matching on the tree structure is matching on the syntax.
If you are finding yourself doing something "unnatural", ask: how can the tree structure help me?
A good example of this is when a while loop is needed. This is (nearly always) a sign that:
- The proper callback has not been hooked; OR
- Something should have been calculated or processed at an earlier step so that it is available/completed without looping.
Refactor your approach if you find that a loop is needed. The result will be less code, simpler, less error prone and easier to understand. This means the code will be less fragile and less likely to cause bugs over its lifetime.
Common Examples¶
Let's build off the DEFINE_BUFFER AST pictured above.
Suppose we want to write a pattern matching expression for all DEFINE BUFFER statements, regardless of buffer name or table. The DEFINE_BUFFER node on its own has all the information needed to accomplish this; we really only need to match the token type. So, the most straightforward way to do this would be to use one of the TRPL expressions from the section above. For instance:
type == prog.define_buffer
Next, suppose we want to refine this match to only match DEFINE BUFFER statements which create a buffer named ttNode. We could do this in two ways. The first expression is defined from the perspective of the DEFINE_BUFFER node:
type == prog.define_buffer and this.getChildAt(0).type == prog.symbol and this.getChildAt(0).text.toLowerCase().equals("ttnode")
Situating this expression at the DEFINE_BUFFER node seems awkward, because most of the description of the pattern is about the SYMBOL node which represents the buffer name. Let's try defining the expression from the perspective of the SYMBOL node instead:
type == prog.symbol and parent.type == prog.define_buffer and text.toLowerCase().equals("ttnode")
This seems like a better approach.
Suppose we want to refine the match differently. Let's write an expression to match on all DEFINE BUFFER statements which define a buffer for a temp-table, regardless of the buffer's name or the temp-table's name. First, we might try:
type == prog.define_buffer and this.getChildAt(1).type = prog.kw_for and this.getChildAt(1).getChildAt(0).type == prog.temp_table
This will work, but it is a bit clumsy; we can do better. Let's try expressing the pattern from the perspective of the TEMP_TABLE node instead:
type == prog.temp_table and parent.type == prog.kw_for and parent.parent.type == prog.define_buffer
Although slightly less specific about the structure of the tree, this expression is specific enough to meet our needs and it is performant, since the lookups of parent node and token types are fast.
We could write an alternative expression which accomplishes the same match by using the upPath helper function:
type == prog.temp_table and upPath("DEFINE_BUFFER/KW_FOR")
This is more compact thus a bit easier to read. A minor trade-off, however, is that this expression is slightly less performant compared to the previous one, due to the string-heavy implementation of the upPath helper function.
Finally, let's imagine we have to match all DEFINE BUFFER statements which define a buffer whose name begins with the prefix buf- which are defined for permanent tables in the employee table of the corp database. The AST structure for this pattern will be very similar to the one displayed above, except the grandchild node will be of token type TABLE instead of TEMP-TABLE. Most of the information to describe this pattern will come from the TABLE node, so it probably is best to "center" the expression on that node:
type == prog.table and upPath("DEFINE_BUFFER/KW_FOR") and getNoteString("schemaname").equals("corp.employee") and parent.parent.firstChild.text.toLowerCase().startsWith("buf-")
This should accomplish the match, but it bears some explanation. First, we match on the token type of the TABLE node. Then, we match on the structure of the tree above that node to ensure this is a DEFINE BUFFER statement. Next, we extract a well-known annotation of all database table and field reference nodes called schemaname. This annotation stores the canonical, qualified, lowercased name of the field or table being referenced. For table references, it takes the form database.table. For field references, it takes the form database.table.field. Thus, we can use this annotation to uniquely match on the employee table in the corp database. Finally, match on the prefix of the buffer name text in the SYMBOL child node of the DEFINE_BUFFER node. Note that we cheat a bit by not matching on the SYMBOL token type as well, but that would be redundant, as we know that node must always exist as the first child of the DEFINE_BUFFER node.
By now it should be clear that pattern matching expression can be arbitrarily complex. To better understand what is possible and to find short-cuts for expressing complex patterns, it is worth exploring the APIs of the various AST implementation classes discussed above, as well as the CommonAstSupport.Library class, and the TRPL functions in rules/include/common-progress.rules.
Useful References¶
The following is a set of useful links to further reading material about the use of TRPL in the FWD Project:
| Document | Purpose |
|---|---|
| Package Summaries | |
| Pattern Engine Javadoc | Description of the pattern matching engine which drives all code analytics and conversion features of FWD. Please note that some of this information is out of date; where it conflicts with this document, this document should take precedence. |
| AST classes and Token Types | |
| AnnotatedAst | AnnotatedAst class javadoc |
| ProgressAst | ProgressAst class javadoc |
| ProgressParserTokenTypes | ProgressParserTokenTypes interface javadoc. Defines all token types used by the FWD Progress parser. |
| JavaAst | JavaAst class javadoc |
| JavaTokenTypes | JavaTokenTypes interface javadoc. Defines all token types used when creating Java ASTs which will be anti-parsed into Java source code. |
| FWD Helper Function Libraries | |
| CommonAstSupport | Helper functions for common AST navigation, inspection, manipulation, and other tasks. |
| ExpressionHelper | Helper functions to convert Progress expressions to Java expressions. |
| File Ops | Helper functions for file operations. |
| Dictionaries | Helper functions for scoped symbol dictionary use during conversion and tree walking tasks. |
| Hints | Helper functions which enable conversion hints |
| Progress ASTs | Helper functions specific to Progress ASTs |
| Java ASTs | Helper functions specific to Java ASTs |
| Preprocessing | Helper functions for conversion preprocessing hints |
| Statistics | Helper functions for code statistics generation |
Debugging¶
See Debugging TRPL.
© 2004-2022 Golden Code Development Corporation. ALL RIGHTS RESERVED.