Understanding ASTs and TRPL¶
Introduction¶
The underlying infrastructure upon which FWD's automated code processing is built consists of Abstract Syntax Trees (ASTs) and an environment called TRee Processing Language (TRPL, pronounced "TRiPLe").
This chapter will explain how these work and why they are important.
Your Source Is Not Helping¶
For all common programming languages, application source code is simply a set of text files. Although many development tools (the most common of which are IDEs or Integrated Development Environments) do provide some level of syntax support, the majority of existing code was written manually by a programmer.
On a project of any significant size, that source code is text that was most probably written by many different humans. This text will have a range of variability depending on the existence of coding standards and the discipline/tools with which those standards are enforced. When a human is involved, the result is going to vary.
All programming languages have a valid syntax (the grammatical rules) that limit the variability of the result. This grammar can be designed to be more or less regular and more or less ambiguous. Beyond that problem of input variability, the 4GL language includes many features that allow programs to be coded in ways that are non-regular or ambiguous.
- Non-Regular Code has different text with the same meaning.
- Ambiguous Code has the same text with different meanings.
Most languages will have some non-regular and/or some ambiguous aspects. There is a natural trade off in design decisions. The more flexible the grammar, the larger the set of possible valid constructs that can be written by the programmer that creates new code while simultaneously magnifying the long term cost of reading, maintenance, debugging, support and refactoring.
Greater flexibility in syntax results in greater long term cost over the life cycle of an application.
The more regular and unambiguous the code, the easier it is to read (understand), maintain, debug, support, and refactor. If one were to calculate these long term costs, they usually will overwhelm the value of up front syntax flexibility in writing new code. When designing the grammar for a language, it should be a very rare and conscious decision to introduce something non-regular or ambiguous.
In comparison to nearly all modern languages, the designers of the Progress 4GL made several unusual decisions that were presumably intended to save development time.
Non-Regular Code¶
The following are prominent examples but it is not an exhaustive list of all non-regularities in the 4GL:
| Non-Regular Code Feature | Description | Different Text, Same Meaning |
|---|---|---|
| Case Insensitivity | Source code may be entered with any case (all upper, all lower, mixed). This frees the programmer from having to think about or match specific case of keywords and symbols (including user defined symbols). | Display
DISPLAY display dIsplay disPlay |
| Keyword Abbreviations | Some keywords (not all of them are documented) are allowed to be arbitrarily abbreviated to some minimum number of characters. | display
displa displ disp |
| Database Symbol Abbreviations | 4GL source code will include direct references to database table names and database field names. Both table and field names are user defined symbols. The references can be arbitrarily abbreviated to the smallest form of the symbol that does not overlap with any other field. What is actually allowed will depend on the context of where the name references occur. Changes in surrounding code can make some abbreviations possible that would not be valid in other places of the same program. | Given two tables cust and customer, all of the following refer to the customer table:
customer custome custom custo Given two fields (not necessarily in the same table) name and number, all the following refer to number: number numbe numb num nu If cust and customer both have name and number, then all of these refer to customer.number: customer.number custome.number custom.num custo.nu ... |
| Optional Database Name Qualifiers | Database tables and fields can appear in either a qualified or unqualified form. What is actually allowed will depend on the context of where the name references occur. Changes in surrounding code can make some unqualified forms possible that would not be valid in other places of the same program. | Table:
mydb.customer customer Field: mydb.customer.number customer.number number |
| Ordering of Options/Clauses | The ordering of keywords, options and clauses in most statements is very flexible. This was probably an unavoidable consequence of the keyword-heavy nature of the 4GL syntax. Since there is a low ratio of punctuation to keywords, there are relatively fewer natural cues in the language to differentiate the grammatical structure of “sentences” (statements). Without the flexible ordering, the syntax would be harder to remember. | def var num format “999” init 14 extent 4.
def var num init 14 extent 4 format “999”. |
| Synonyms | Some punctuation and keywords can be used interchangeably. Often these are undocumented capabilities. | Most code blocks can have their header ended with either a . (period) or a : (colon).
function help returns int (). end. function help returns int (): end. Keywords WAIT and WAIT-FOR are synonyms even though WAIT-FOR cannot be abbreviated (WAIT-FO is not valid): WAIT go of my-widget. WAIT-FOR go of my-widget. |
Ambiguous Code¶
The following are prominent examples but it is not an exhaustive list of all ambiguities in the 4GL:
| Ambiguous Code Feature | Description | Same Text, Different Meaning |
|---|---|---|
| Unreserved Keywords | With well over 2000 keywords in the language, not all of them could be made into reserved keywords (keywords whose text cannot be a user-defined symbol). Over 400 keywords are reserved, leaving more than 1900 (approximately) as unreserved. The keywords can appear as source text for user-defined names. | A user defined function encrypt() can be named the same as a built-in function encrypt() that uses an unreserved keyword:
some-var = encrypt(some-data). |
| Overloading Punctuation and Keywords | Some punctuation and keywords are used for multiple purposes, whose function is differentiated by the context of the program. | The . (period or dot) is used for many purposes: statement terminator, qualified database name separator, date separator, decimal point, package name separator, included in a unquoted filename.
The : (colon) is similarly overloaded, including many cases where it can be substituted for the . (period).
The ERROR keyword can be used as part of an ON ERROR clause, as a handle-based attribute, as a key function, as a type of alert-box, as a built-in function or as part of the RETURN statement. |
| Many Namespaces | The 4GL contains at least 14 and possibly up to 19 different namespaces, some of which are “flat” and some of which as scoped to code blocks. The same user defined symbols can appear in any and all of these namespaces in the same program. | A variable can be named the same thing as a stream which can be the same name as a buffer, and so forth. |
High Costs of Non-Regular and Ambiguous Code¶
In the preceding tables, the examples given are just for illustration. The actual number of ways these non-regular or ambiguous source forms can occur are quite large. The use of these “features” is pervasive throughout 4GL application source code. It is the rule rather than the exception. These features don’t exist in modern languages or if they occur it is in a very limited form.
In each of the above examples, at best there may have been a savings of a few seconds when the code was originally written. For example, typing DEF instead of DEFINE may save a fraction of a second. Spread over an entire program, perhaps it is possible that a a few minutes may have been saved during the original development.
The majority of time in initial development is spent thinking, not typing. Initial development time is spent in understanding requirements, planning the approach to implement the feature, testing and other kinds of tasks. It may have taken a day to write that program where perhaps three minutes were saved by using features of the 4GL which make the resulting code non-regular and ambiguous.
The majority of time spent doing subsequent development on that program is dependent on how readable (understandable) and simple the program is. Non-regular and ambiguous text makes code hard to understand and fragile (sensitive to minor changes or changes that seem unrelated). 4GL programs are full of non-regular or ambiguous text which will cost hours, days or weeks over the lifetime of those programs.
All of these add much more cost over the long term than they save in initial development time.
Scale Makes Things Harder¶
When the scale of large applications is factored in, it magnifies the problems inherent in human written source code.
Programmatic analysis or transformation of a 4GL application can only be done with tools that are aware of the 4GL language syntax. These tools must not only handle the syntax but they must also be able to properly handle both non-regular code and differentiate ambiguous code.
To enable proper analysis of code, the text form of the code must be transformed into a data structure that represents the pure syntax of the code. ASTs represent the code’s language syntax without syntactic sugar. The result is both regular and unambiguous.
ASTs are used by compilers and any other tools that programmatically process code.
How ASTs Are Made¶
FWD contains tools to convert source code (and schemata) into ASTs. This generically is called "parsing" and it is handled by an automated process called the ConversionDriver. The parsing is done in the "conversion front-end" which processes the entire application as a batch and the output is the complete set of ASTs. More details can be found in the Conversion Technology Architecture chapter.
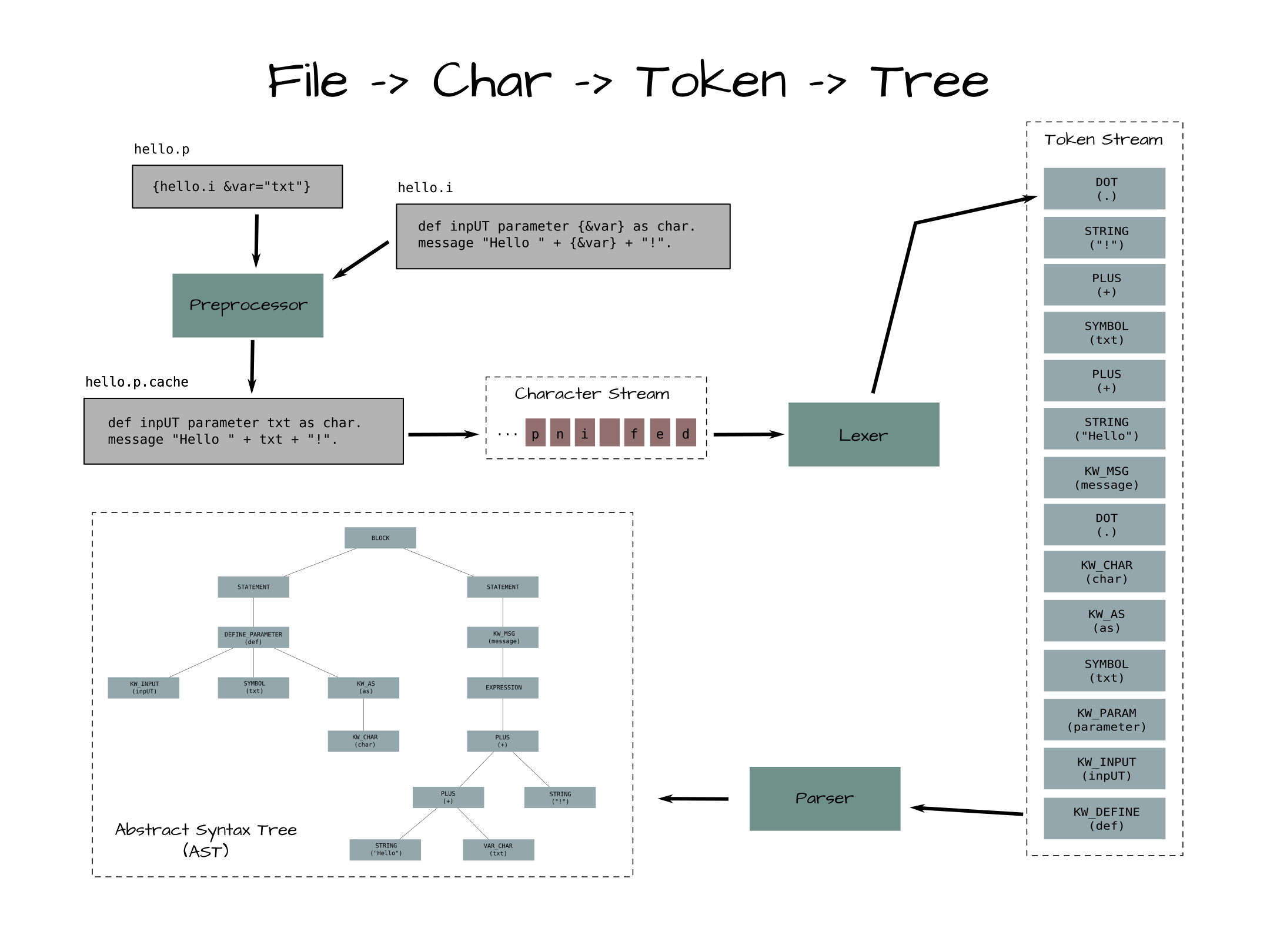
The specific process that takes a single source file and converts it into an AST is depicted here:
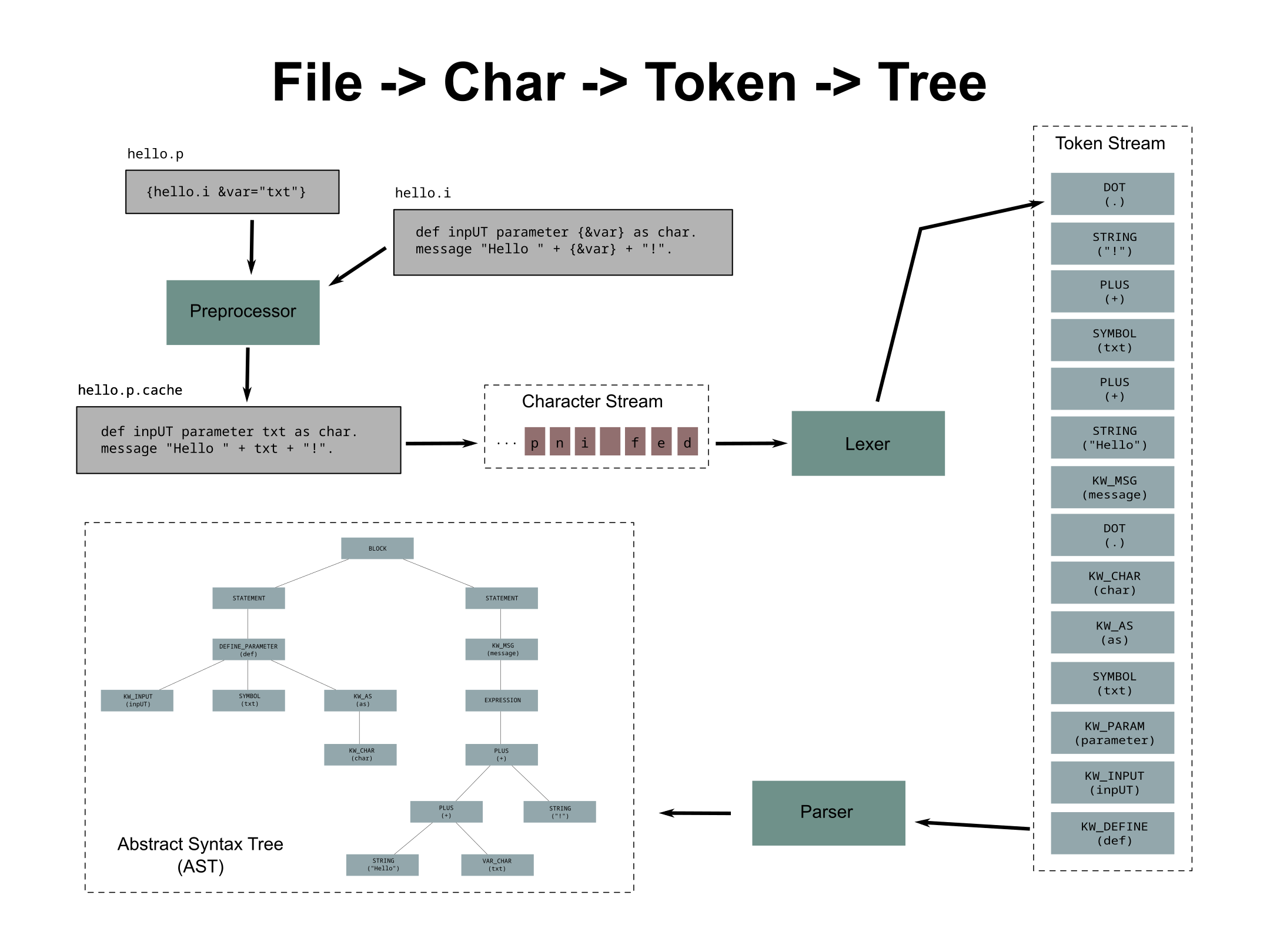
Summary of the process for a source file:
- The primary input is a source program (external procedure or an OO 4GL class).
- The source program is read into the FWD preprocessor.
- The preprocessor which duplicates the preprocessing that OpenEdge would do. Include files are read, preprocessing directives are honored, preprocessor references to defines or arguments are resolved.
- The output from the preprocessor is a
.cachefile that represents the syntactically valid 4GL program. - The FWD lexer reads the cache file one character at a time.
- The lexer is a 4GL-aware program that creates tokens (words) from individual characters.
- This token stream is written as output from the lexer.
- The FWD parser reads the lexer's token stream.
- The parser is a 4GL-aware program that processes the stream of tokens into a tree structure matching the 4GL syntax.
- The tree structure is the AST and it is saved for downstream analysis or transformation by TRPL programs.
There is a simpler process that takes a schema definition (.df file) and converts it into an AST. This is handled by the SchemaLoader class.
TRee Processing Language (TRPL)¶
FWD provides tools to parse an entire application. Each source file and each schema file (.df) is represented as an AST. TRPL is the analysis and transformation toolset in FWD which can operate on the entire set of ASTs as a batch.
When you process trees, it is commonly called a tree walk. TRPL includes an engine that handles the tree walking for programs written in the TRPL language. By taking away the burden of the tree walking, TRPL programs make it much simpler to process trees.
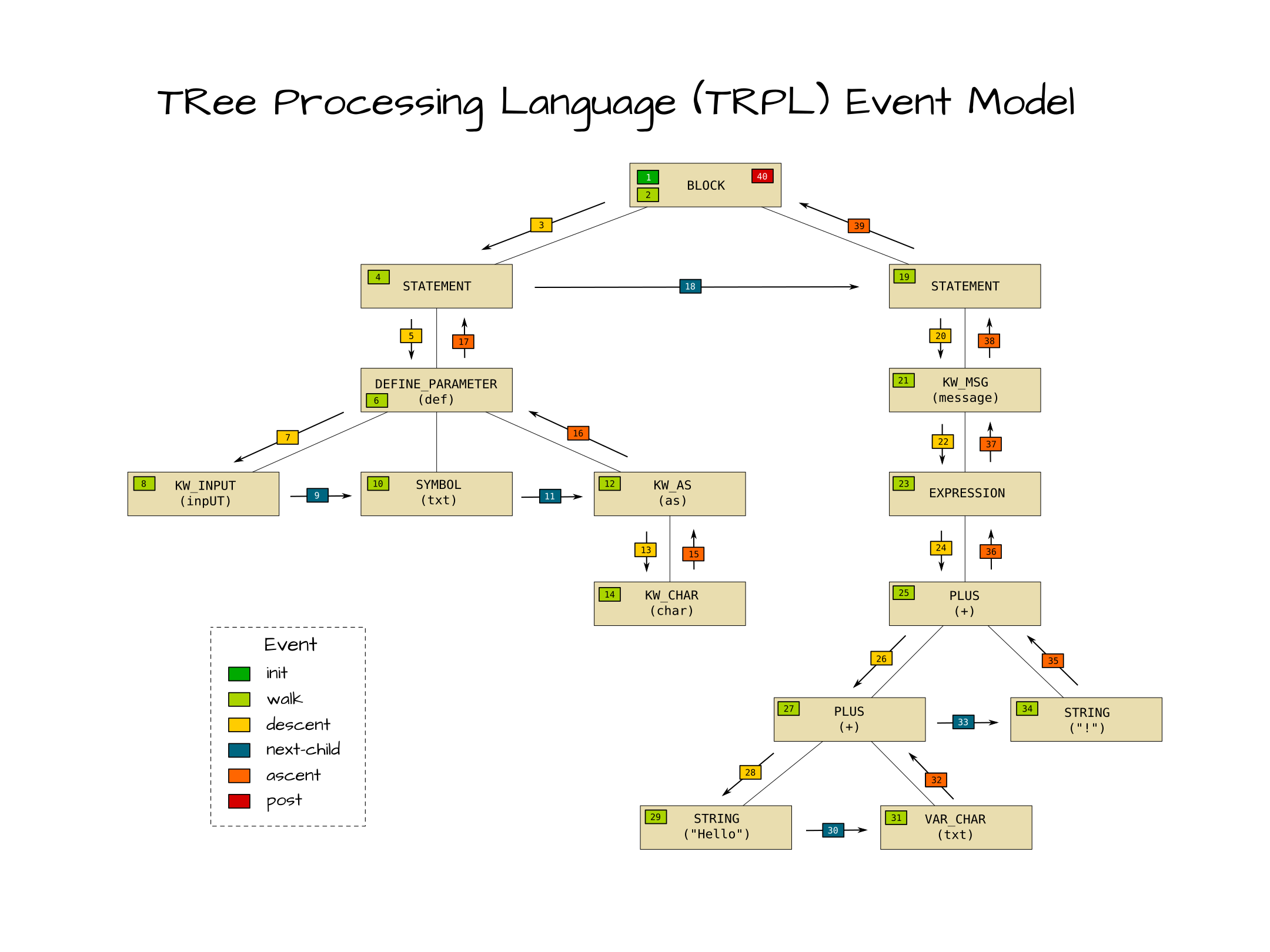
To understand how trees are processed, one must understand the event model used in TRPL programs.
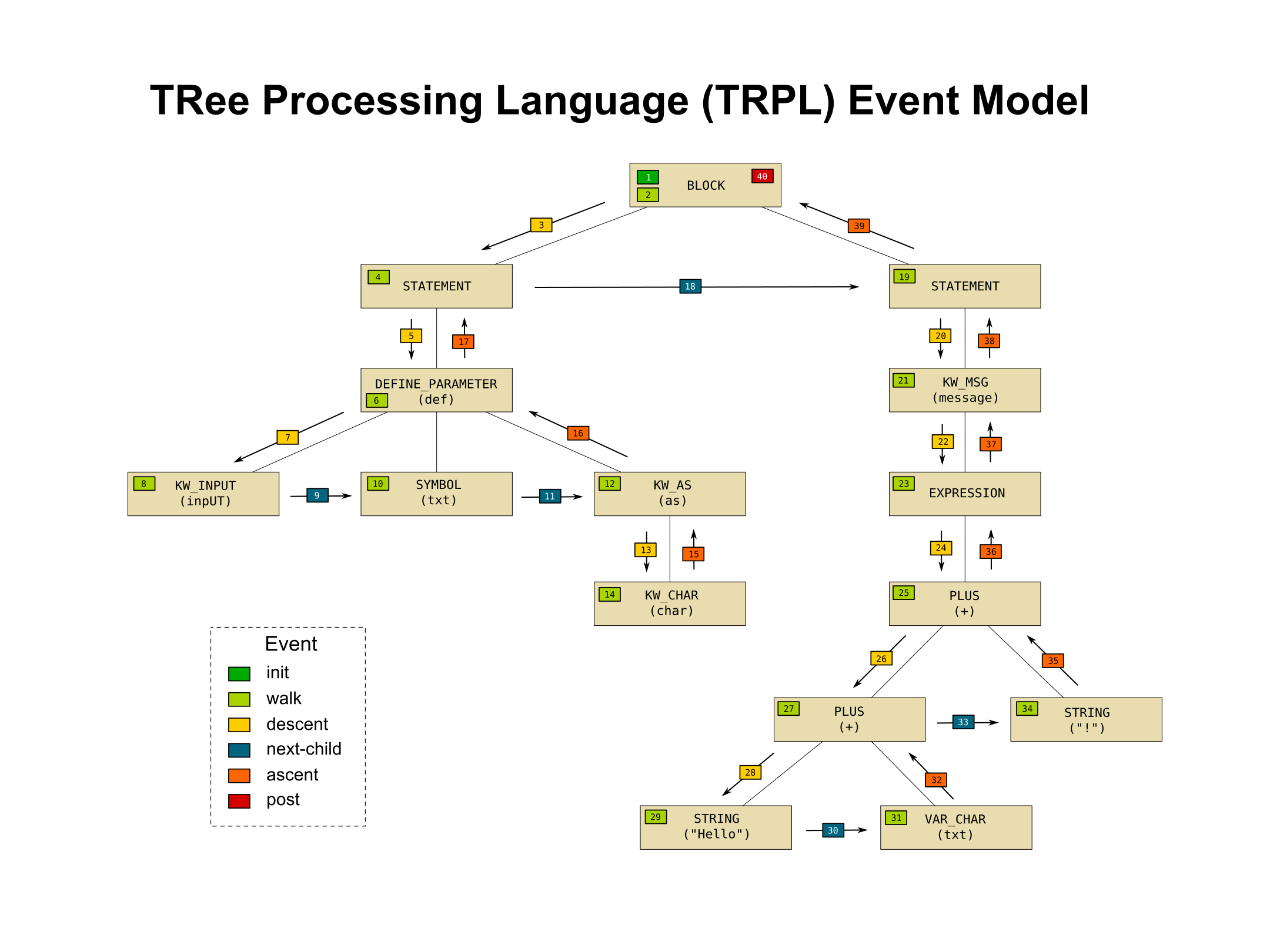
There are 6 kinds of tree events. Each event occurs at an AST node or between two AST nodes.
- init Occurs once per tree, at the root node. It is always the first event to occur.
- walk Occurs once per node.
- descent Occurs in between a parent and its first child.
- next-child Occurs in between a child and its next rightward sibling.
- ascent Occurs in between the last child and its parent.
- post Occurs once per tree, at the root node. It is always the last event to occur.
The numbers in the above diagram show the order in which these events occur. TRPL programs are written as sets of callbacks that are associated with a specific event. The TRPL engine processes each tree for each TRPL program and invokes those callbacks based on the matching events that are occurring.
Processing just the walk events for the whole tree would be the equivalent to the traditional visitor pattern. TRPL has a much richer set of events that make it easier to implement certain transforms or calculations than the simplistic visitor pattern.
TRPL programs can be pipelined to achieve incremental analysis or transformation, allowing complex processing to be split into a modular form.
For more details on programming in TRPL, see:
AST Designed for Transformation¶
The FWD AST implementation was designed with transformation in mind. At parse time, there is a great deal of knowledge about the code. Encoding that knowledge into the tree makes downstream work easier.
- Resolving data types of each expression component is very important. This allows downstream code to calculate the type of each subexpression or expression in the application.
- By tracking resources by scope and creating linkages between the references and the definition, it becomes easier to work with these resources later.
- Structuring the tree is important. This can make it easier to walk the tree, match patterns and then calculate or transform based on those matches.
- Multiple nodes can be rewritten as a single unambiguous node (e.g. KW_DEFINE KW_PARAMETER can be written as DEFINE_PARAMETER).
- Artificial nodes can be inserted to group multiple related nodes.
- Calculated values and context-specific information are stored in the associated nodes as annotations.
The result is a very rich AST.
© 2004-2019 Golden Code Development Corporation. ALL RIGHTS RESERVED.
{kind=link}
{kind=link}