Bug #7657
8-bit character entry problem in ChUI
100%
Related issues
History
#2 Updated by Greg Shah almost 3 years ago
As reported by one of our customers:
I did notice one other thing. It occurs both in the Hotel sample app as well as our own app. When running client-terminal.sh, I can only enter 7 bit ASCII values. When running via swing, I can enter 8 bit ISO8859-1 characters like ä.
Both have CPSTREAM as ISO8859-1.
#3 Updated by Robert Jensen over 2 years ago
Any news on this? We support customers all over the world and to support UTF8 clients.
#4 Updated by Greg Shah over 2 years ago
- Assignee set to Eugenie Lyzenko
#5 Updated by Greg Shah over 2 years ago
At a high level, I think we need to implement (at least) these things:
- Support for "wide characters" in NCURSES. There are alternate versions of the ncurses libraries that are compiled with wide character support. We need to ensure we can enable this support and successfully use it with UTF-8 input.
- FWD client support for setting
CPINTERNALandCPSTREAMto UTF-8. Without this we will improperly process the input. The actual setting of these CP values can be done normally in the directory or via the matching bootstrap config startup parameters. I think the issue here is that we may not properly honor these settings today.
#6 Updated by Robert Jensen over 2 years ago
I see the display is correct for UTF8 when I put data in the database. But I can't enter these charactersfrom the terminal screen (Swing window) I can't input anything but ISO8859-1 characters. I suspect this is a limitation of the "P2J ChUI CLient", not Golden Code directly. Any advice here?
The client-termimnal.sh script does not display UTF8, only 7 bit ASCII characters.
#7 Updated by Greg Shah over 2 years ago
I suspect that item 2 in #7657-5 will address this issue. If not, we will fix the bug.
#8 Updated by Eugenie Lyzenko over 2 years ago
The small sample to demonstrate the issue will be great here. Or recreation instruction for Hotel application.
#9 Updated by Robert Jensen over 2 years ago
I apologize for my ignorance, but for the Hotel app, where exactly do I set the encoding for the client? I assume it is in directory.xml, but I do not know which section. It does appear to default to ISO8859-1
For the terminal app, I am getting a failure now in terminal start up: "java: symbol lookup error: /home/mfg/projects/hotel/deploy/lib/libp2j.so: undefined symbol: auto_getch_refresh
Swing is ok.
Which may be related to the p2j updates, or I did something wrong in my setup. I think I need to rebuild/recompile the hotel app. Altough we will be running as terminal most likely as we need to get the input/output streams programatically.
I agree that Note 5 does sound like the answer.
#10 Updated by Theodoros Theodorou over 2 years ago
Robert Jensen wrote:
I apologize for my ignorance, but for the Hotel app, where exactly do I set the encoding for the client? I assume it is in directory.xml, but I do not know which section. It does appear to default to ISO8859-1
You can set cpinternal or cpstream through directory.xml using:
<node class="container" name="standard">
<node class="container" name="runtime">
<node class="container" name="default">
<node class="container" name="i18n">
<node class="string" name="cpinternal">
<node-attribute name="value" value="UTF-8"/>
or thorugh
client.xml using:<client> <cmd-line-option cpinternal="UTF-8"/> </client>
Setting command line parameters through directory.xml is preferred because sometimes some effects are missed through client.xml.
#11 Updated by Greg Shah over 2 years ago
- Related to Feature #6431: implement support to allow CPINTERNAL set to UTF-8 and CP936 added
#12 Updated by Greg Shah over 2 years ago
I apologize for my ignorance, but for the Hotel app, where exactly do I set the encoding for the client? I assume it is in directory.xml, but I do not know which section. It does appear to default to ISO8859-1
In addition to Theodoros' comments, anything that goes into the bootstrap configuration (e.g. client.xml) can also be passed at the end of the ClientDriver command line in the form client:cmd-line-option:cpinternal=UTF-8. The client.sh can also take these same parameters at the end of its command line and it will pass them through to the ClientDriver.
The core problem remains in #6431, we know that setting CPINTERNAL to UTF-8 will not fully work properly. We will fix that.
For the terminal app, I am getting a failure now in terminal start up: "java: symbol lookup error: /home/mfg/projects/hotel/deploy/lib/libp2j.so: undefined symbol: auto_getch_refresh
This means you have not patched ncurses. That is a requirement for the native terminal client. Please see Patching NCURSES Using Static Linking, Patching NCURSES and Patching TERMINFO.
#13 Updated by Robert Jensen over 2 years ago
When running my App, I see that Unicode is supported. I put in Unicode (beyond 8 bit) into Item Descriptions in Maria DB
client-swing.sh will show the characters. But I can not enter them through the terminal.
client-terminal.sh will not show or enter anything beyond 7 bit ASCII.
So I suspect the problem is in my terminal setup. I did try setting cpinternal:UTF-8 in when calling client-swing.sh, it did nothing.
directory.xml already has cpinternal as UTF-8.
I think the problem is in the client-swing and client-terminal scripts themselves.
An oddity here. I can enter the 8 bit ISO characters such as ä in client-swing. I suspect the client script is ISO8859-1 and something is converting the character to UTF-8 as they are entered. Encoding is always difficult.
#14 Updated by Greg Shah over 2 years ago
client-swing.sh will show the characters. But I can not enter them through the terminal.
client-terminal.sh will not show or enter anything beyond 7 bit ASCII.So I suspect the problem is in my terminal setup. I did try setting cpinternal:UTF-8 in when calling client-swing.sh, it did nothing.
directory.xml already has cpinternal as UTF-8.
No, you are not doing anything wrong. The items in #7657-5 need to be implemented before it will work. The reason you get further with Swing is that our Swing client is not dependent upon NCURSES. The ncurses changes are absolutely needed for this to work.
#15 Updated by Robert Jensen over 2 years ago
I fianally got around to trying the ncurses update. No change. The setup_ncurses6x.sh script did appear to work correctly. The.bashrc file has the "export NCURSES_FWD_STATIC=/home/<app>/ncurses/ncurses-6.3" line in it. But the terminal output is unchanged. I see "MM" trash in fields where a valid 8 bit character appears. The startup is:
./client-terminal.sh client:cmd-line-option:startup-procedure=com/<app_path>/ClientBootstrap.p client:cmd-line-option:parameter="cpinternal:UTF-8,cpstream:UTF-8,startup=mf.p,mfgwrapper=true"
Also, another small note. We rely on control chracters appearing in the message area to alert of specical processing. These 0x2, 0x3, 0x4 0x5. But the display in terminal shows:
^b ^c (and they do seem to be two characters, not a single control character. This is a bit tricky to deterime)
In swing, they do not appear (they are control chars after all), but they are present.
I may have missed a step here. I am running from Intellij, which I did restart after the changes to .bashrd But maybe I need to reboot? Is there any way fro me to deterime if the patch really got installed and p2j sees it? I'm open to suggestions.
#16 Updated by Robert Jensen over 2 years ago
The comand line is actually:
./client-terminal.sh client:cmd-line-option:startup-procedure=com/<app_path>/ClientBootstrap.p client:cmd-line-option:parameter="cpinternal=UTF-8,cpstream=UTF-8,startup=mf.p,mfgwrapper=true"
I wonder if that is correct.
#17 Updated by Greg Shah over 2 years ago
In #7657-5, I mentioned some changes that were needed. Let me make it more clear: these changes that are needed are mostly modifications to the FWD source code. Unless you have written those changes (unlikely), then it is not expected to work (yet).
- Support for "wide characters" in NCURSES. There are alternate versions of the ncurses libraries that are compiled with wide character support. We need to ensure we can enable this support and successfully use it with UTF-8 input.
- We have to ensure that those versions of the library are installed and patched.
- The FWD build (native portion) needs to bind to the wide versions of the library.
- The FWD native code (
.hand.cfiles) must be modified to process wide characters. That code is very likely to be limited to single byte processing in some areas, including:- the interfaces called in NCURSES
- internal variables/memory allocations on the heap (or local vars on the stack)
- internal interfaces and processing
- The FWD Java code may need edits. In particular, it may have some assumptions that each character coming back or going out is a single byte (e.g. we might apply bitmasks to values to clear the most signficant bytes).
- FWD client support for setting
CPINTERNALandCPSTREAMto UTF-8. Without this we will improperly process the input. The actual setting of these CP values can be done normally in the directory or via the matching bootstrap config startup parameters. I think the issue here is that we may not properly honor these settings today. This work is described in #6431. At this point it is largely a testing effort that remains. I don't know if any code changes are needed in FWD.
#18 Updated by Greg Shah over 2 years ago
I may have missed a step here. I am running from Intellij, which I did restart after the changes to .bashrd But maybe I need to reboot? Is there any way fro me to deterime if the patch really got installed and p2j sees it? I'm open to suggestions.
When you say "if the patch really got installed", I assume you mean the patches to NCURSES that are required to make FWD compile (and run in native mode) properly. We have these patches documented in Patching NCURSES Using Static Linking, Patching NCURSES and Patching TERMINFO.
You do not need to reboot. But you MUST recompile FWD to properly build the libp2j.so module.
If the FWD native build succeeded, then you have a working libp2j.so and it must have linked to a patched version of NCURSES in some way. You can always force load the module using ldd build/lib/libp2j.so to see what it reports as its dependencies. That is a good "check".
#19 Updated by Greg Shah over 2 years ago
Robert Jensen wrote:
The comand line is actually:
./client-terminal.sh client:cmd-line-option:startup-procedure=com/<app_path>/ClientBootstrap.p client:cmd-line-option:parameter="cpinternal=UTF-8,cpstream=UTF-8,startup=mf.p,mfgwrapper=true"I wonder if that is correct.
No, it is not correct if you are trying to override the cpinternal and the cpstream. For those, you must add the client:cmd-line-option:cpinternal=UTF-8 client:cmd-line-option:cpstream=UTF-8 to the command line for the script. Or you can configure them in the directory as noted in #7657-10.
But please note that without the FWD code changes described in #7657-17, this will not work yet.
We will allocate some time next week to write these changes.
#20 Updated by Robert Jensen over 2 years ago
I am open to trying out and testing any FWD changes here on my end. Let me know if I can help in any way. I have worked on terminal emulators at various times in the past.
#21 Updated by Eugenie Lyzenko over 2 years ago
Guys,
During testing Hotel ChUI with wide chars environment I'm getting the following warning when starting server:
...
24/04/11 19:07:57.647+0300 | WARNING | com.goldencode.p2j.security.SecurityCache | ThreadName:main, Session:00000000, Thread:00000001, User:standard | Can't find or can't instantiate the user-provided implementation for SsoAuthenticator.
java.lang.ClassNotFoundException: com.goldencode.hotel.HotelChuiSsoAuthenticator
at java.net.URLClassLoader.findClass(URLClassLoader.java:382)
at java.lang.ClassLoader.loadClass(ClassLoader.java:418)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:352)
at java.lang.ClassLoader.loadClass(ClassLoader.java:351)
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:264)
at com.goldencode.p2j.security.SecurityCache.instantiateSsoAuthenticator(SecurityCache.java:2136)
at com.goldencode.p2j.security.SecurityCache.readAuthMode(SecurityCache.java:2104)
at com.goldencode.p2j.security.SecurityCache.<init>(SecurityCache.java:460)
at com.goldencode.p2j.security.SecurityAdmin.currentCache(SecurityAdmin.java:5941)
at com.goldencode.p2j.security.SecurityAdmin.addUser(SecurityAdmin.java:2101)
at com.goldencode.p2j.admin.AdminServerImpl.addUser(AdminServerImpl.java:1493)
at com.goldencode.p2j.main.TemporaryAccountPool.createUser(TemporaryAccountPool.java:245)
at com.goldencode.p2j.main.TemporaryAccountPool.createTemporaryAccounts(TemporaryAccountPool.java:178)
at com.goldencode.p2j.main.TemporaryAccountPool.<clinit>(TemporaryAccountPool.java:152)
at com.goldencode.p2j.main.StandardServer$14.initialize(StandardServer.java:1576)
at com.goldencode.p2j.main.StandardServer.hookInitialize(StandardServer.java:2503)
at com.goldencode.p2j.main.StandardServer.bootstrap(StandardServer.java:1230)
at com.goldencode.p2j.main.ServerDriver.start(ServerDriver.java:534)
at com.goldencode.p2j.main.CommonDriver.process(CommonDriver.java:593)
at com.goldencode.p2j.main.ServerDriver.process(ServerDriver.java:225)
at com.goldencode.p2j.main.ServerDriver.main(ServerDriver.java:1010)
...
Does it mean something serious issue with my application config or I can ignore this?
#22 Updated by Greg Shah over 2 years ago
It must be something pulled over from the Hotel GUI directory. In October 2023, Galya implemented single signon for Hotel GUI. That is a web based thing and there is no equivalent at this time that has been implemented for Hotel ChUI in web mode.
In Hotel GUI, the class is embedded/src/com/goldencode/hotel/HotelGuiSsoAuthenticator.java (actually, I think it is a mistake that it was put in the embedded directory). Anyway, there is no such class for Hotel ChUI.
#23 Updated by Eugenie Lyzenko over 2 years ago
Greg Shah wrote:
It must be something pulled over from the Hotel GUI directory. In October 2023, Galya implemented single signon for Hotel GUI. That is a web based thing and there is no equivalent at this time that has been implemented for Hotel ChUI in web mode.
In Hotel GUI, the class is
embedded/src/com/goldencode/hotel/HotelGuiSsoAuthenticator.java(actually, I think it is a mistake that it was put in the embedded directory). Anyway, there is no such class for Hotel ChUI.
Thanks for clarification. Disabling SSO in directory.xml resolves this issue.
#24 Updated by Eugenie Lyzenko over 2 years ago
The news so far.
After experimenting I would like to share some finding at this time. For minimal usage we need to:
1. To use UTF-8 or other char sets outside ASCII we use in ChUI we need to build special NCURSES set with configure command:
make clean ./configure --with-termlib CFLAGS='-fPIC -O2' --with-abi-version=6 --enable-widec make
This will create wide char capable version of the
NCURSES libraries to kink with. I mean to use static linking for MCURSES libraries with w name postfix in this case.
2. The FWD build config file for native code (makefile) is need to be changes to use this version of the NCURSES:
...
# linux section
ifeq "$(OS)" "Linux"
override CFLAGS+=-fpic
# NCURSES library is a requirement in the project anyway so the C code
# calls functions in that interface directly instead of exec'ing command
# line utilities for the same purpose (to avoid the hard requirement of
# having extra utility programs installed in addition to P2J); this is
# the reason why libp2j depends on libncurses:
override LDFLAGS+=-ldl -lutil
ifdef NCURSES_FWD_STATIC
override INCLUDES+=-I${NCURSES_FWD_STATIC}/include
override LDFLAGS+=-L${NCURSES_FWD_STATIC}/lib -l:libncursesw.a -l:libtinfow.a
else
override LDFLAGS+=-lncursesw
endif
# this option is valid in Linux but not in Solaris
override RMCMD+=v
endif
...
3. The native code in FWD is need to be changed to use alternative API calls to get/put data from/to ChUI terminal(terminal_linux.c):
+#define NCURSES_WIDECHAR 1
+#include <wchar.h>
...
+#include <locale.h>
...
void addchNative(int chrToDraw)
{
- addch(chrToDraw);
+ // the lowest 8 bits is the char, while the rest
+ const cchar_t wch = {chrToDraw & 0xFFFFFF00, {chrToDraw & 0x000000FF, 0, 0, 0, 0}};
+ add_wch(&wch);
}
...
void initConsole(JNIEnv *env, char * termname)
{
...
+ // do we need this call?
+ setlocale(LC_ALL, "");
...
}
...
jint readKey()
{
- return (jint) getch();
+ jint retValKey = -1;
+ int rc = get_wch((wint_t*)&retValKey);
+ if (rc == OK || rc == KEY_CODE_YES)
+ {
+ // TODO: need to transform incoming data to use in Java?
+ }
+ else
+ {
+ // assuming rc == ERR here
+ retValKey = -1;
+ }
+
+ return retValKey;
}
...
This is the minimal set of changes to start using of the Hotel ChUI demo application. Note both read/write function have changed the usage approach. For wide char version the character attribute and key value are separated in two fields. In current FWD version we combine/pack both values into single 32-bit integer.
These changes does not mean the full UTF-8 support. I think we need to change Java classes that responsible for preparing data to put in terminal and handling the key obtained from native key reader. Currently we assume the character value can be represented with 8-bit single byte. This will not work for wide chars. So we need to have another I/O processing inside Java classes for wide chars. So we will have to get two versions of FWD classes, one for single byte chars and other - for wide chars. Or may be we will drop usage of the regular NCURSES and always use *w version of the libraries having backward compatibility with previous projects. I have no clear picture here.
But at runtime we need to have the ability to know whether ChUI terminal is wide or not to choose respective approach to pack/unpack the data to display or got. Also in wide version there is a difference between wide character(rc OK) and function key(rc KEY_CODE_YES) returned from get_wch(). This might need special attention too.
The further work will depend on what we want as result. In any case I'm expecting this can take more than one day to complete.
#25 Updated by Greg Shah over 2 years ago
Good work!
Some thoughts:
- We should add a build-time option to control whether the native module will use wide chars or not.
- We can't switch exclusively to UTF-8. The existing environments mostly are not UTF-8 and this even includes hardware terminals. These things must be handled with full compatibility. We are just adding the option to support UTF-8 and wide chars.
- On the Java side, it seems like we can make the changes to always pass the data down in wide mode. Only the JNI code needs to know how to process the result.
- The idea is that we only need a single API for the Java code to call.
- Do you see a reason that won't work?
#26 Updated by Eugenie Lyzenko over 2 years ago
Greg Shah wrote:
Good work!
Some thoughts:
- We should add a build-time option to control whether the native module will use wide chars or not.
Agreed.
- We can't switch exclusively to UTF-8. The existing environments mostly are not UTF-8 and this even includes hardware terminals. These things must be handled with full compatibility. We are just adding the option to support UTF-8 and wide chars.
OK. I think we will need to change JNI signatures to use more input options to note the wide char mode is in use and to pass attribute in a separate variable to have 32-bit variable we currently use for character code completely.
- On the Java side, it seems like we can make the changes to always pass the data down in wide mode. Only the JNI code needs to know how to process the result.
- The idea is that we only need a single API for the Java code to call.
- Do you see a reason that won't work?
It is difficult to say for sure. For now I think it is possible (with JNI methods input options change). I will have the exact answer during implementation.
#27 Updated by Eugenie Lyzenko about 2 years ago
Making required code changes to add ChUI terminal support with optional UTF-8 characters for input/output.
1. The first things to do is to have proper building environment to make correct linking with NCURSES libraries, static or dynamic. At this time I offer to introduce new system variable NCURSES_FWD_WIDE_CHARS to separate required libraries to link for native code. If we need to have the ability to compile for both NCURSES versions (wide and legacy) we should have two separate location for static NCURSES libraries, one for wide chars aware and other for legacy one. The variable can be added alongside with NCURSES_FWD_STATIC in .bashrc. The value is not important, just assign something like yes. The respective FWD makefile changes will be:
...
ifeq "$(OS)" "Linux"
override CFLAGS+=-fpic
# NCURSES library is a requirement in the project anyway so the C code
# calls functions in that interface directly instead of exec'ing command
# line utilities for the same purpose (to avoid the hard requirement of
# having extra utility programs installed in addition to P2J); this is
# the reason why libp2j depends on libncurses:
override LDFLAGS+=-ldl -lutil
ifdef NCURSES_FWD_STATIC
override INCLUDES+=-I${NCURSES_FWD_STATIC}/include
ifdef NCURSES_FWD_WIDE_CHARS
override LDFLAGS+=-L${NCURSES_FWD_STATIC}/lib -l:libncursesw.a -l:libtinfow.a
else
override LDFLAGS+=-L${NCURSES_FWD_STATIC}/lib -l:libncurses.a -l:libtinfo.a
endif
else
ifdef NCURSES_FWD_WIDE_CHARS
override LDFLAGS+=-lncursesw
else
override LDFLAGS+=-lncurses
endif
endif
# this option is valid in Linux but not in Solaris
override RMCMD+=v
endif
...
This way we can easily switch between two different NCURSES libraries depending on current building requirements.
2. The second step is to find out when the wide char version is to be used in FWD environment. On the terminal setup we can use for every client session the CPINTERNAL variable defined in directory.xml and checking for Linux OS behind. If defined as UTF-8 then boolean flag is passing to native FWD library to inform the wide chars calls is to be used. The check can be done in ConsoleHelper:
/**
* Initialize the native layer.
*/
public static void initChui()
{
- initConsole(); // call native function to initialize console.
+ // call native function to initialize console.
+ initConsole(!EnvironmentOps.isUnderWindowsFamily() &&
+ "UTF-8".equalsIgnoreCase(I18nOps._getCPInternal()));
}
This way we can let the native FWD layer to know what NCURSES API to use(teminal_linux.c):
...
void addchNative(int chrToDraw)
{
- addch(chrToDraw);
+ if (useWideChars)
+ {
+ // the lowest 8 bits is the char, while the rest
+ const cchar_t wch = {chrToDraw & 0xFFFFFF00, {chrToDraw & 0x000000FF, 0, 0, 0, 0}};
+ add_wch(&wch);
+ }
+ else
+ {
+ addch(chrToDraw);
+ }
}
...
jint readKey()
{
- return (jint) getch();
+ jint retValKey = -1;
+ int rc = get_wch((wint_t*)&retValKey);
+ if (rc == OK || rc == KEY_CODE_YES)
+ {
+ // TODO: need to transform incoming data to use in Java?
+ }
+ else
+ {
+ // assuming rc == ERR here
+ retValKey = -1;
+ }
+
+ return retValKey;
}
3. The next step is to ensure the Java code layer properly handle UTF-8 as subset of generic chars processing for In/Out with native ChUI console. Now I'm thinking about good representation of the Java Strings for output to ChUI. We currently convert Strings to byte array with String.getBytes() call, meaning every byte is a single ASCII char. I think for generic purpose we need to represent the String as array of chars, letting native code to do some post-processing before terminal output depending on whether the UTF-8 in use or not. On the other hand what we will get as result of the String.getBytes("UTF-8")? Every byte will represent single character? Or amount of bytes per char will depend on particular char Unicode point? Should we completely shift to splitting single String into array of Unicode chars(16-bit) used internally in Java?
Please let me know what you think.
#28 Updated by Eugenie Lyzenko about 2 years ago
Created task branch 7657a from trunk revision 15162.
#29 Updated by Robert Jensen about 2 years ago
UTF-8 encoding has a variable number of bytes per character. By the way, Java actually uses UTF-16 internally. It can also have characters taking up more then one 16 bit word. But this rarely happens with most common character sets.
So yes, the number of bytes used by a character depends on the Unicode code point.
#30 Updated by Eugenie Lyzenko about 2 years ago
The 7657a updated for review to revision 15163. Rebased with recent trunk. New revision is 15165.
This is the first steps of changes at this time to compile and test. Continue working.
#31 Updated by Greg Shah about 2 years ago
1. The first things to do is to have proper building environment to make correct linking with
NCURSESlibraries, static or dynamic. At this time I offer to introduce new system variableNCURSES_FWD_WIDE_CHARSto separate required libraries to link for native code. If we need to have the ability to compile for bothNCURSESversions (wide and legacy) we should have two separate location for staticNCURSESlibraries, one for wide chars aware and other for legacy one. The variable can be added alongside withNCURSES_FWD_STATICin.bashrc. The value is not important, just assign something likeyes. The respectiveFWDmakefilechanges will be:
[...]This way we can easily switch between two different
NCURSESlibraries depending on current building requirements.
This generally seems correct.
However, I would ask this: is there a problem if we always use wide mode? All modern Linux systems probably support it. Is there any problem it would cause? If it slows things down, that would be a problem. But if it would just work the same way, even for non-wide character sets, then perhaps we should always use wide mode.
If wide mode limits the implementation in some way, then we probably don't want to use it always. One way it would be a problem is if wide mode did not support all terminal types.
2. The second step is to find out when the wide char version is to be used in
FWDenvironment. On the terminal setup we can use for every client session theCPINTERNALvariable defined indirectory.xmland checking for Linux OS behind. If defined asUTF-8then boolean flag is passing to nativeFWDlibrary to inform the wide chars calls is to be used. The check can be done inConsoleHelper:[...]
This way we can let the native
FWDlayer to know whatNCURSESAPIto use(teminal_linux.c):
This part I don't fully understand. The native code can't use wide chars if it isn't linked to the wide version of ncurses, right? And we know which version of ncurses we've linked with at compile time, so shouldn't we just conditionallly preprocess the code so that only the correct API is used?
3. The next step is to ensure the
Javacode layer properly handleUTF-8as subset of generic chars processing for In/Out with nativeChUIconsole. Now I'm thinking about good representation of theJavaStringsfor output toChUI. We currently convert Strings to byte array withString.getBytes()call, meaning every byte is a single ASCII char. I think for generic purpose we need to represent the String as array of chars, letting native code to do some post-processing before terminal output depending on whether theUTF-8in use or not. On the other hand what we will get as result of theString.getBytes("UTF-8")? Every byte will represent single character? Or amount of bytes per char will depend on particular char Unicode point? Should we completely shift to splitting singleStringinto array of Unicode chars(16-bit) used internally in Java?
As Robert points out, Java already has its String in 16-bit Unicode format and there the "supplementary characters" cases where a single character is larger than 16-bits (so it takes more than one char element in the char[] that is the internal representation of a String).
Consider that OE has a concept of setting the CPTERM codepage explicitly. This is meant to be the codepage in which character data is output on the terminal. If not set explicitly, then the CPINTERNAL value is used for CPTERM. In ChUI and in redirected terminal streaming in GUI, if there is a difference between CPTERM and CPINTERNAL, then the characters are converted from CPINTERNAL into CPTERM before writing them out. We currently don't support this but I think we now need to figure it out.
Consider that our existing customers (that use ChUI) have a mixture of hardware terminals and software based terminal emulators. We currently support VT100, VT220, VT320 and xterm terminal types. The VT series were ASCII terminals (or maybe extended ASCII) as far as I remember. I don't know it they could be configured to handle a wider range of character encodings (e.g. like 8859-15 which is similar to Windows 1252). I think xterm is different and can in fact even support UTF-8. My point here is that we have existing users that have external terminals (hardware and software) that we must be able to support. I suspect OE needed the CPTERM so that the output could be forced into a specific codepage that the terminals would accept. We need to honor that same idea of translating the "internal" Java Unicode characters into the CPTERM codepage.
We need to plan that characters can be multibyte and pass the data accordingly. Using the Java char or char[] is not OK because these are 16-bit Unicode and they require special handling to deal with specific characters (like those that take more than 2 bytes). Instead, the Java code should do any codepage conversion and then write the results into a form that the native code can just write out to NCURSES.
#32 Updated by Robert Jensen about 2 years ago
You bring up a very good point about using a vt220/320 terminal. They techincally do not support Unicode characters at all. We had to limit our virtual vt320 in Java to only process 7-bit commands.
We had cases (Japanese?) where the CSI charcater (0x9b) would appear in messages. The terminal thought this was a control character and it caused a good deal of trouble on certain messages. Using <ESC>[ was far more stable.
It is odd in that Linux think we are an xterm, while Progress sees vt320. They are very close, but different.
From what I have seen in our widget walk code, we do see the UTF-8 characters when we examine the screen widgets, even if they do not display correctly. But when we attempt to enter these values through the terminal, they get corrupted. This may simplify your problem, although the message area may be an issue. However, there are times we need to see the screen. At spacebar pauses for example.
I do feel your pain, we had a good deal of trouble back in 2012 when we went to UTF-8 databases. We appreciate your looking into this. It is a challenge.
#33 Updated by Eugenie Lyzenko about 2 years ago
The 7657a rebased with recent trunk 15277, updated to revision 15282.
With this change the flag to use wide char API in native code was removed. Instead the pragmas used to select respective NCURSES API to use, either legacy or wide chars capable. Continue working.
#34 Updated by Eugenie Lyzenko about 2 years ago
Robert,
Currently I'm working on the Java part for UTF-8 support in ChUI. And I need some assistance.
The changes I've made has a good feedback for US locale/keyboard for input/output. But this is very not enough to say the support is ready to use. So I need some sample to debug which certainly do not work with current implementation.
For now I use Cyrillic keys based i/o. And this has an issues with FWD I'm working on. Good starting point but seems like I need more cases specific to your needs (or not specific to my specific) This way we will ensure the new implementation will be generic to cover all cases.
#35 Updated by Eugenie Lyzenko about 2 years ago
The addition issue here is not clear how to set up UTF-8 as cpinternal or charset. I have tried 3 ways:
1. directory.xml
2. client.xml
3. client-terminal.sh
None ways provide the change for internal CP to become UTF-8. It remains ISO8859-1.
#36 Updated by Robert Jensen about 2 years ago
What I have done in the past is put various characters into MAriaDB, then display them. The encoding is UTF-8.
1) 8 bit ISO8859-1 characterss, such as ä. This is a single byte in ISO8859-1, two bytes in UTF-8
2) I use charmap on my PC to get Cyrillic or Japanese.
3) I also try copy/paste from international websites.
I did discover soemthing interesting. I can see the UTF-8 characters by looking at the screen widgets internal value. Even if the CHUI screen shows trash.
#37 Updated by Eugenie Lyzenko about 2 years ago
The UTF-8 config issue resolved. So the note #7657-35 can be dropped.
The other issue here is the input handling. Currently we support only for extended LATN1 characters. So the key chars outside 0-255 range are now ignored.
Greg,
What our plan here? Do we need the all Unicode chars do be enter into for example FILL-IN? Or we need to be limited with current country/locale setting?
The answer will define the further changes for Keyboard FWD class. Especially for isPrintableKey() and keyLabel() method.
Or may be it will be better to have only Unicode based processing to all internal Java logic making UTF-8 transformation only for calls to native layer? Currently for example we do CPINTERNAL processing when constructing KeyInput event from incoming key press.
#38 Updated by Robert Jensen about 2 years ago
We <company_name> support customers all over the world. 255 characters are not enough.
But for now, the current new product is going out to US customers only. We may need the Euro sign (ISO8859-15), but otherwise ISO8859-1 will suffice for the short term.
#39 Updated by Eugenie Lyzenko about 2 years ago
Robert Jensen wrote:
We
<company_name>support customers all over the world. 255 characters are not enough.But for now, the current new product is going out to US customers only. We may need the Euro sign (ISO8859-15), but otherwise ISO8859-1 will suffice for the short term.
Another word we need to be able to enter the Euro sign(and other possible chars from alternative layout) from keyboard into application widget, correct?
#40 Updated by Eugenie Lyzenko about 2 years ago
Another question. Do we really need to support UTF-8 for interactive ChUI client? I see in a Progress DOC only GUI client supports Unicode/UTF-8.
Remembering previous note for VT* terminals with only 0-127 key code range constraint. Or we need this support only for XTERM?
#41 Updated by Eugenie Lyzenko about 2 years ago
The 7657a rebased with recent trunk 15284, new revision is 15286.
#42 Updated by Eugenie Lyzenko about 2 years ago
Fixed the output in wide char mode issue. So now we have at least Euro sign in ChUI terminal session. Also all Cyrillic letters(just for test, not sure we need this in production).
Will resume work on Tuesday.
#43 Updated by Greg Shah about 2 years ago
The
UTF-8config issue resolved. So the note #7657-35 can be dropped.
Just to be clear: #7657-19 and #7657-10 explain how to set these values.
The other issue here is the input handling. Currently we support only for extended
LATN1characters. So the key chars outside0-255range are now ignored.
I would not say it is dependent upon LATIN1 characters. Rather, it is dependent upon single byte character sets. For example, Cyrillic should work if all of the codepages are set properly.
What our plan here? Do we need the all Unicode chars do be enter into for example
FILL-IN?
Yes, it needs to be possible if it is configured as such.
Or we need to be limited with current country/locale setting?
Yes, this is what must be honored. But it is OK for this to be set to UTF-8 or CP936 or whatever. We should honor the support no matter if it is a single byte charset or multi-byte charset.
Or may be it will be better to have only
Unicodebased processing to all internal Java logic
Yes, this is already how we do it in general. All internal Java processing is in Unicode (Unicode 16, actually). We just need to implement the proper conversions to/from the internal Java Unicode approach and the input or output on the terminal.
making
UTF-8transformation only for calls to native layer?
We only want there to be a UTF-8 transformation if that is what the CPTERM is set to. Or if there is no CPTERM, then whatever codepage is set in CPINTERNAL.
Currently for example we do
CPINTERNALprocessing when constructingKeyInputevent from incoming key press.
Yes, we must use CPTERM (or CPINTERNAL) as the "source codepage" for conversion of incoming key presses into Java unicode characters.
#44 Updated by Greg Shah about 2 years ago
We
<company_name>support customers all over the world. 255 characters are not enough.But for now, the current new product is going out to US customers only. We may need the Euro sign (ISO8859-15), but otherwise ISO8859-1 will suffice for the short term.
The point of this task is to properly implement multi-byte charset support including full support for Unicode. We will do so.
#45 Updated by Greg Shah about 2 years ago
Another word we need to be able to enter the Euro sign(and other possible chars from alternative layout) from keyboard into application widget, correct?
Yes, we must support it if the configured CPTERM or CPINTERNAL support the Euro character.
#46 Updated by Greg Shah about 2 years ago
Another question. Do we really need to support
UTF-8for interactive ChUI client? I see in a Progress DOC onlyGUIclient supportsUnicode/UTF-8.
Yes, we must support this.
And by the way, OE supports it too (see #6493).
Remembering previous note for
VT*terminals with only0-127key code range constraint. Or we need this support only forXTERM?
Some terminal emulation types only support a limited choice of charset (e.g. VT100 supports ASCII). Other terminal emulation types support a wider range. We don't really care what the terminal emulator supports as long as it is compatible with what has been configured in FWD for CPTERM or CPINTERNAL.
#47 Updated by Greg Shah about 2 years ago
Also all Cyrillic letters(just for test, not sure we need this in production).
These were previously working at one point, but perhaps we had broken that support in the meantime.
#48 Updated by Greg Shah about 2 years ago
To be clear: we have existing customers that use hardware terminals and we must continue to support their use cases. This means that we cannot just switch everything to Unicode always. Old school terminals like VT100, VT220 would break.
So we need to optionally support Unicode.
#49 Updated by Eugenie Lyzenko about 2 years ago
- File euro_sign_chui.jpg added
The 7657a updated to revision 15287, rebased with recent trunk 15306, new revision is 15309.
The changes to enable UTF-8 chars to use inside interactive ChUI terminal when supported. Disabled double key code transformation because in wide chars the keys are ready to be used as is. Modified terminal output to support Unicode Base Multilingual Pane chars.
This is an example of the Euro sign typed from keyboard:

Continue working.
#50 Updated by Greg Shah about 2 years ago
Reposted from #6431-50 by Robert Jensen:
I'm not asure where to bring this up. I ran into some new issues with our latest p2j library. We use functions key F17 to F20 to read the current screen values. We do this by mapping F17 to F20 to help. In our help routine, we look at the current screen widgets and send xml up to the webapp.
The problem is that some of the function keys no longer do anything. As a result, our processing stalls.
FYI, we use an vt320 terminal. <F19> is sent as <ESC>[33~ This should (and did) work for xterm as well as vt220 terminals earlier. This may a result of a change to ncurses, or some other encoding issue?
There is a second problem as well. The output stream from our ssh session has lots of NULL characters in it once we start running the converted code on a Ubuntu OS. Odd, but it is not fatal. However, when running from a AWS Linux, we get 0xFF instread of 0x00, and this requires extra work. What is going on in the output stream? Talking to the OS does not show these characters. The good news is that 0xFF never really appears in UTF-8 encoded streams, so I can filter it out.
#51 Updated by Eugenie Lyzenko about 2 years ago
The 7657a rebased with recent trunk 15337, new revision is 15340.
#52 Updated by Eugenie Lyzenko about 2 years ago
The 7657a rebased with recent trunk 15338, new revision is 15341.
#53 Updated by Eugenie Lyzenko about 2 years ago
The 7657a updated to revision 15342, rebased with recent trunk 15339, new revision is 15343.
The small change to select different native char reading functions from NCURSES library.
#54 Updated by Greg Shah about 2 years ago
Eugenie: What is the list of things that you know need to be completed?
#55 Updated by Eugenie Lyzenko about 2 years ago
Greg Shah wrote:
Eugenie: What is the list of things that you know need to be completed?
I'm thinking of this already some time. The answer is not yet clear. I need some strategy for implementation or the milestone to reach. My points:
1. Technically the FWD should be ready to support wide chars now.
2. On the other hand I'm not sure how this implementation will work with UTF-8 characters that are more than 2 bytes in size(exceeding wide char range).
3. Another point is the wide char range can cross some Progress defined special characters range (see ui/Keyboard.java for different key codes considered as synthetic combinations of CTRL/SHIFT/ALT + key). So this can present interpretation issue for how we consider/separate these chars.
4. To test some key support I need to know how to emit them on keyboard. An example is <F19> from #7657-50.
5. The other question: Should we always use wide char version of NCURSES instead of having a choice between two versions?
So I think to understand what we need to do more here we need to have a scenarios that should work after modifications complete. Something like UTF-8 certification suite, when passing it we could say all done.
If there is no such scenario what we need to do is to ensure the 7657a is completely compatible with all regular project in old legacy mode. This should protect us from regressions.
But again it would be great to have some good testcases to verify UTF-8 implementation. From my side I tested Cyrillic support and it works fine.
#56 Updated by Eugenie Lyzenko about 2 years ago
The 7657a rebased with recent trunk 15344, new revision is 15348.
#57 Updated by Tijs Wickardt about 2 years ago
Eugenie Lyzenko wrote:
2. On the other hand I'm not sure how this implementation will work with UTF-8 characters that are more than 2 bytes in size(exceeding wide char range).
This was investigated and dismissed at the time, it's a big effort.
See: #7010-239. That customer is aware of the limitation and has currently no need for a fix.
#58 Updated by Tijs Wickardt about 2 years ago
#59 Updated by Greg Shah about 2 years ago
2. On the other hand I'm not sure how this implementation will work with UTF-8 characters that are more than 2 bytes in size(exceeding wide char range).
This was investigated and dismissed at the time, it's a big effort.
See: #7010-239. That customer is aware of the limitation and has currently no need for a fix.
Other customers have different requirements and this task is not for the same customer as #6268. This primary focus here is about the input and output of UTF-8 characters on the terminal.
#60 Updated by Tijs Wickardt about 2 years ago
Greg Shah wrote:
2. On the other hand I'm not sure how this implementation will work with UTF-8 characters that are more than 2 bytes in size(exceeding wide char range).
This was investigated and dismissed at the time, it's a big effort.
See: #7010-239. That customer is aware of the limitation and has currently no need for a fix.Other customers have different requirements and this task is not for the same customer as #6268. This primary focus here is about the input and output of UTF-8 characters on the terminal.
I'm not referring to UTF-8. That is important for that customer as well.
I am referring to Eugenie's:
UTF-8 characters that are more than 2 bytes in size(exceeding wide char range).
#61 Updated by Greg Shah about 2 years ago
2. On the other hand I'm not sure how this implementation will work with UTF-8 characters that are more than 2 bytes in size(exceeding wide char range).
This was investigated and dismissed at the time, it's a big effort.
See: #7010-239. That customer is aware of the limitation and has currently no need for a fix.Other customers have different requirements and this task is not for the same customer as #6268. This primary focus here is about the input and output of UTF-8 characters on the terminal.
I'm not referring to UTF-8. That is important for that customer as well.
I am referring to Eugenie's:UTF-8 characters that are more than 2 bytes in size(exceeding wide char range).
I don't understand how you are not referring to UTF-8 but to Eugenie's comment about UTF-8.
Anyway, UTF-8 support in general includes characters that are encoded in 1, 2, 3 or 4 bytes, even though most characters in use can be encoded in 2 byte UTF-16. We have to consider this implementation in relation to the terminal support. That has nothing to do with #6268.
#62 Updated by Tijs Wickardt about 2 years ago
Apparently this is open to misinterpretation (twice), so let me rephrase:
Eugenie mentions "UTF-8 characters that are more than 2 bytes in size(exceeding wide char range)." .
That is only a subset of the UTF-8 characters. It is not about UTF-8 in general.
Eugenie has tested Cyrillic keys in UTF-8. But those are 2 bytes, not more than 2 bytes.
If Greg wishes that all UTF-8 characters are needed required to be supported at input (entering and displaying emoji's in the ChUI), all that I'm saying is: there is a lot of work to do.
If it has nothing to do with #6268, then that's good news.
But I doubt it. If someone pastes an emoji, and Greg wishes to support UTF-8 completely, the emoji needs to be passed on via the JVM, and the String.length() will fail. It will not return 1 for one emoji, as it does in OE correctly. As mentioned in #6268.
EDIT: correction, striked through
#63 Updated by Greg Shah about 2 years ago
We don't care about emojis. But we might care about other characters that have encodings that are more than 2 bytes. For example, most of the characters in the Basic Multilingual Plane (BMP) must be encoded in 3 bytes. That includes the majority of the characters for Chinese, Japanese and Korean. This is much more "about UTF-8 in general" than about some exceptional cases (e.g. emojis). Also, this is first and foremost about the terminal processing. It may reach back into the string processing depending on the use cases, but if the terminal processing isn't working properly that none of the stuff in strings matters.
#64 Updated by Tijs Wickardt about 2 years ago
Thanks for the clarification.
Emoji's are only an example, and easy for testing. That Greg doesn't care about them is slightly odd, it's a modern world and they will cause real issues.
But I'm of course happy that Greg states clear requirements. Not needed is not needed.
"the majority of the characters for Chinese, Japanese and Korean." share the same aspect and are comparable to emoji's in that regard: more bytes than two.
Good that Greg limits this task to terminal processing only, that part wasn't clear to me until now.
#65 Updated by Eugenie Lyzenko about 2 years ago
The 7657a rebased with recent trunk 15347, updated to revision 16352.
This is the fix for compatibility issues found with testing GUI application in wide chars and legacy building modes. We can now use both modes in projects I guess.
#66 Updated by Eugenie Lyzenko almost 2 years ago
The 7657a rebased with recent trunk 15350, new revision is 15355.
#67 Updated by Eugenie Lyzenko almost 2 years ago
Found some interesting site to generate UTF-8 characters outside of the basic Latin encoding: https://jeff.cis.cabrillo.edu/tools/homoglyphs
We can use it to test different text and copy/paste into FILL-IN/EDITOR to compare the result in terminal or to make input text file to use for redirected input for example.
At this time I've got the exception for text: Ң𝔢ḽļ۵ 𝖶ọ𝑟ḽ𝕕
This means in FWD we still have the places where the UTF-8 string is still handling incorrectly. Will debug this tomorrow.
#68 Updated by Greg Shah almost 2 years ago
Please test to see how OE handles multi-byte input for CPTERM=UTF-8 in combination with various CPINTERNAL settings (i.e. single byte charsets like ISO8859-1 as well as being set to UTF-8). Make sure to check the error-status handle for details of character conversion errors.
Optimally we would have these as ABLUnit testcases, which is tricky because of the interactive input. Marian's team has implemented Sikuli for this kind of test.
Marian: Do we have documentation for how to use Sikuli with ABLUnit?
#69 Updated by Marian Edu almost 2 years ago
Greg Shah wrote:
Marian: Do we have documentation for how to use Sikuli with ABLUnit?
There is a Readme file in either sikuli or support/sikuli folder. I do not think we’ve accounted for the fact various encoding can be used though, the events to be applied are read from one script file, the screen/program to take user input is started afterwards and when available sikuli will send those event to it and if not closed will apply end-error to it to make it end.
#70 Updated by Eugenie Lyzenko almost 2 years ago
Testing original 4GL application with Unicode/UTF-8 chars gives us some fact can be found interesting.
Seems like the only widget can accept UTF-8 extended chars is EDITOR. While the FILL-IN does not accept the Unicode/UTF-8. And only in GUI mode. I tested ChUI mode in Windows but CPTERM=UTF-8 gives incorrect content for EDITOR that reads text from file. The console PASTE operation works even worse.
#71 Updated by Eugenie Lyzenko almost 2 years ago
A bit more finding for original 4GL Unicode support is not the EDITOR is only widget can work with it in GUI mode but this is true for copy/paste operations via system feature. The reading from file gives incorrect result on screen, event when specifying cpstream=UTF-8. So the status of the Unicode support in OpenEdge is undefined.
In these conditions I see the best possible way for FWD is to implement the right Unicode/UTF-8 support wherever we can(may be there are some Java restrictions) and not to duplicate possible Progress bugs or missed features. In this case we can follow the official Progress documentation where the Unicode support is declared as completed.
#72 Updated by Greg Shah almost 2 years ago
In these conditions I see the best possible way for
FWDis to implement the rightUnicode/UTF-8support wherever we can(may be there are some Java restrictions) and not to duplicate possible Progress bugs or missed features. In this case we can follow the official Progress documentation where the Unicode support is declared as completed.
Agreed.
#73 Updated by Eugenie Lyzenko almost 2 years ago
The 7657a updated to revision 15356, rebased with recent trunk 15354, new revision is 15360.
This update includes more compatibility fixes to make the FWD UTF-8 friendly. Tested with different Unicode characters.
The next step is to ensure the text based widget are working properly with Unicode range we need to support. And here we need to answer the main question: do we need to support Unicode range outside 0-0xFFFF? Currently our implementation is based on fact the Java single 16-bit char is enough to present one Unicode symbol. This is related to FILL-IN and EDITOR GUI widgets. So to ensure we can properly handle Unicode 2 chars symbols we need to rework key processing for text based widget.
That's why I'm asking before any work here is started.
#74 Updated by Greg Shah almost 2 years ago
Robert: Do you need support for characters outside of the BMP? This would include Chinese, Japanese and Korean characters.
#75 Updated by Marian Edu almost 2 years ago
Eugenie Lyzenko wrote:
A bit more finding for original 4GL Unicode support is not the EDITOR is only widget can work with it in GUI mode but this is true for copy/paste operations via system feature. The reading from file gives incorrect result on screen, event when specifying
cpstream=UTF-8. So the status of the Unicode support inOpenEdgeis undefined.
EDITOR and FILLIN should support UTF, though the font used also must support that.
#76 Updated by Greg Shah almost 2 years ago
#77 Updated by Eugenie Lyzenko almost 2 years ago
Found yet another possible incompatibility point for current FWD implementation with UTF-8. This method is never used in current ChUI double buffer approach but it is potential hidden bug we face as soon as the code will be used.
The Java call is ConsolePrimitives.append():
...
public void append(String str, Color color)
{
// the input string is encoded as unicode which has 2 bytes for each
// character, when anything other than 7-bit ASCII chars are used
// the result is corrupted unless we convert to the native platform
// charset (via getBytes()) --> as long as the native platform
// character set is a single byte charset, then this result will
// preserve the data properly all the way through to the terminal
//TODO: use encoding
byte[] bytes = null;
try
{
bytes = str.getBytes(I18nOps.getJavaCPInternal());
}
catch (UnsupportedEncodingException uee)
{
bytes = str.getBytes();
}
helper.addStringNative(bytes, bytes.length, attribute(color), color(color));
}
...
The respective native call is:
...
JNIEXPORT void JNICALL Java_com_goldencode_p2j_ui_client_chui_driver_console_ConsoleHelper_addStringNative
(JNIEnv *env, jobject jo, jbyteArray jstr, jint len, jint attrib, jint colorpair)
{
int i;
if (len <= 0)
{
return;
}
int attr = attrib;
attr = colorPairNative(attr, colorpair);
jbyte* chrs = (jbyte*) malloc(len * sizeof(jbyte));
if (chrs == NULL)
{
throwException(env, "java/lang/OutOfMemoryError", "Cannot copy data.");
}
(*env)->GetByteArrayRegion(env, jstr, 0, len, chrs);
for (i = 0; i < len; i++)
{
// remove the automatic sign extension (we want to treat this as
// an unsigned 8-bit number)
int extended = 0x000000FF & (int) chrs[i];
addchNative(extended | attr);
}
(*env)->DeleteLocalRef(env, jstr);
free(chrs);
}
...
In this implementation we assume the every chat in string is inside 8-bit byte value. This can work fine for basic Latin1 but can be a problem with generic Java char outside this range. Honestly I do not see the reason why we need to over-complicate this by getting byte array. It is more natural to get char array ant pass it to native layer. Then we can use either legacy call(using only first 8-bit) to add char or wide char version. At lest Unicode BMP symbols should be processed properly here.
#78 Updated by Eugenie Lyzenko almost 2 years ago
The 7657a rebased with recent trunk and updated to revision 15362.
This change should resolve the issue noted in #7657-77. The idea is not to differentiate use cases on Java level but instead for wide char capable native module to reconstruct the UTF-8 characters from incoming bytes stream based on generic UTF-8 encoding rules. This change should cover BMP chars and more, technically all UTF-8 range. We can decide later if we will support cases other than used 2 bytes per char.
#79 Updated by Eugenie Lyzenko almost 2 years ago
The 7657a rebased with recent trunk 15362, new revision is 15369.
#80 Updated by Eugenie Lyzenko almost 2 years ago
The findings so far for EDITOR widget.
The EDITOR widget was tested with standalone testcase for compatibility with full range UTF-8 characters. Found the issue with characters outside of the 0xFFFF 16 bit character range. I have found the regular terminal can properly display these chars (just copy/paste into terminal).
Also we can see the proper symbols in Java code (even inside the Java debugger). So I think we can display them in FWD wide char capable terminals.
The key point here is to change working to the code points obtained from Java source string instead of using simple char(16-bit) value. So far we need to change the double buffered terminal Cell class implementation to use integer code point instead of currently used char.
Also the EDITOR widget slightly different handles the text pasted by OS clipboard key sequence. The length of the text is not the same as for text imported from file(but the Java text looks the same inside FWD temporary code). So need to find out what the difference is and make common processing.
#81 Updated by Eugenie Lyzenko almost 2 years ago
Finally after reading a lot of small document distributed on the Web and making large amounts of experiments I found the answers letting me make several conclusions for Unicode/UTF-8 usage inside NCURSES:
1. We can use full range of Unicode chars for NCURSES native calls. Including the range outside BMP symbols. The wide char version of the NCURSES library should be used. The restriction I know is the single Unicode code point should be within 32-bit unsigned integer.
2. The internal data implementation for wide NCURSES mentions the wchar_t as the base char type. The wide char from NCURSES is not the same as UTF-16 encodes 16-bit char used internally in Java. The surrogate pair approach used in Java to represent complex chars outside BMP range does not work and can not be used with NCURSES, even wide char aware. The wchar_t is 32-bit in size and only code point fro Java can be used to represent the Unicode symbol in general. The BMP range is a subset of general case but the 16-bit java char should also be put into single wchar_t.
3. To display a char the wide version of NCURSES API should be used, not mixing with old one within single session. Also the wide version of the constants should be used.
4. Unlike the regular old style NCURSES the color and attribute values can not be safely mixed/OR-ed with character values in wide version of NCURSES API. Ignoring this can have unexpected visual result is very difficult to debug.
5. The data types can be machine dependent and to set up complex structures like cchar_t the better way is to use NCURSES API calls if any. This should provide more compatibility from one NCURSES version to another.
The good info source: https://invisible-island.net/ncurses/man/
So I need to make more changes to our Java code. The main big deal is to refactor console primitive calls to use code point count as the String length. This is distributed within almost all text based widgets in ChUI and GUI and until we fix this we will have real String length regression for complex UTF-8/Unicode cases when processing is dependent on String length. The EDITOR and FILL-IN widgets are the good examples with respect to the correct cursor position and real char location.
From far perspective I think at some time we can completely move to the wide char version because it should have full Unicode support we only need to work with Java code. The wide version is just an extension for regular one and should be compatible I guess.
#82 Updated by Greg Shah almost 2 years ago
Very nice summary and good job on this research!
Are you sure that the NCURSES wide char (wchar_t) is 100% the same as the UNICODE code point as returned from Java? If so, that does indeed make this work reasonably.
The main big deal is to refactor console primitive calls to use code point count as the String length.
Eventually, this will have to be done on a wider basis across the rest of the string processing in FWD. But for now, I think you plan is perfect. Let's make the low level UI implementation completely safe.
Are you planning to convert String.length() to String.codePointCount(0, String.length())? Instead, I wonder if we should put this (and other wide char helpers) inside a class like StringHelper to make it more obvious these methods are deliberately implemented for code points.
From far perspective I think at some time we can completely move to the wide char version because it should have full Unicode support we only need to work with Java code. The wide version is just an extension for regular one and should be compatible I guess.
Is there any reasonable scenario where we have a system that supports NCURSES but only in single byte charset mode? I do prefer if we can just move completely to the full Unicode approach and wide NCURSES. Please see if you can find any examples of Linux distributions that don't support Unicode in the terminal.
#83 Updated by Eugenie Lyzenko almost 2 years ago
Greg Shah wrote:
Very nice summary and good job on this research!
Are you sure that the
NCURSESwide char (wchar_t) is 100% the same as the UNICODE code point as returned from Java? If so, that does indeed make this work reasonably.
For now I'm inclining to to think this way. I tried to consider the wchar_t as Java char but Java symbols having surrogate pair does not properly rendering with NCURSES, we have screen junk instead. On the other hand only using code point with wchar_t does work. Let's say it is compatible with code point. There is one thing left. The NCIRSES documentation refers to the so called "space char" and "non-space" char inside wchar_t array. As far as I understand the "space char" is one that moves the cursor one position to the right. While non-space char is a kind of decoration to previous space char(should always be the first in array). Like acute(^) or umlaut(") above main character. But in Unicode I think every these characters have respective code point without separation for main char and decoration so seems like this is not an issue for Strings coming from Java code. But we have to keep the track on this too.
The main big deal is to refactor console primitive calls to use code point count as the String length.
Eventually, this will have to be done on a wider basis across the rest of the string processing in FWD. But for now, I think you plan is perfect. Let's make the low level UI implementation completely safe.
Are you planning to convert
String.length()toString.codePointCount(0, String.length())?
Yes.
Instead, I wonder if we should put this (and other wide char helpers) inside a class like
StringHelperto make it more obvious these methods are deliberately implemented for code points.
Yes, putting this calculation in StringHelper is a good idea. This should simplify debug/support. The only point here I'm worry about is performance. The call will be used many times. What about static method execution time expenses? Will the private code be faster?
From far perspective I think at some time we can completely move to the wide char version because it should have full Unicode support we only need to work with Java code. The wide version is just an extension for regular one and should be compatible I guess.
Is there any reasonable scenario where we have a system that supports NCURSES but only in single byte charset mode?
The shout answer is no. But probably there is a terminal that does not support wide chars. Or has no GUI desktop like embedded systems or cash machine? Or if the user forces single byte encoding for some old hardware?
I think all modern Linux distributions should be compatible. The possible exceptions: FreeBSD or Solaris where wide NCURSES might be missing at all.
I do prefer if we can just move completely to the full Unicode approach and wide NCURSES. Please see if you can find any examples of Linux distributions that don't support Unicode in the terminal.
OK. I'll make this research. What about Solaris and FreeBSD? Do we need to consider these OS as possible targets for FWD to deploy?
#84 Updated by Greg Shah almost 2 years ago
The shout answer is no. But probably there is a terminal that does not support wide chars. Or has no GUI desktop like embedded systems or cash machine? Or if the user forces single byte encoding for some old hardware?
Whatever we do MUST be compatible with hardware terminals. This means that if you are configured with VT100 or any of the other terminal types that can only deal with single byte charsets, then we need to safely handle it. Those definitely need to work, we have existing customers with hardware terminals using FWD in ChUI mode.
OK. I'll make this research. What about
SolarisandFreeBSD? Do we need to consider theseOSas possible targets forFWDto deploy?
We have no plans to support Solaris or FreeBSD.
#85 Updated by Eugenie Lyzenko almost 2 years ago
Greg Shah wrote:
The shout answer is no. But probably there is a terminal that does not support wide chars. Or has no GUI desktop like embedded systems or cash machine? Or if the user forces single byte encoding for some old hardware?
Whatever we do MUST be compatible with hardware terminals. This means that if you are configured with VT100 or any of the other terminal types that can only deal with single byte charsets, then we need to safely handle it. Those definitely need to work, we have existing customers with hardware terminals using FWD in ChUI mode.
OK. Understood. In this case the plan is: Check wide NCURSES usage with VT100 or other single byte terminal. If wide char version is fully backward compatible we can safely move to only wide char version. Otherwise we will have to support both old and wide NCURSES versions.
#86 Updated by Greg Shah almost 2 years ago
OK. I'll make this research. What about
SolarisandFreeBSD? Do we need to consider theseOSas possible targets forFWDto deploy?We have no plans to support
SolarisorFreeBSD.
Actually, we do need to support Solaris (on risc hardware, not intel) but we don't need to support FreeBSD.
#87 Updated by Eugenie Lyzenko almost 2 years ago
Yet another possible modification requirement. In addition to String.length() we probably need to have substitution for String.substring() method in StringHelper to have method version supporting code points. Otherwise the broken substring can be returned if start or end indexes are inside surrogate pair of the original string.
I'm using "possible" term here because the real requirement can be clarified on debugging and if we can avoid this we should bypass this call implementation because on the first view the implementation can be pretty complex and can cause performance degradation.
#88 Updated by Eugenie Lyzenko almost 2 years ago
Guys,
I have added new method in StringHelper. The prototype:
...
/**
* Computes the length of the string in code points. Can handle Unicode string with possible surrogate
* pair for single character.
*
* @param str
* The string to check.
*
* @return The length of the string in code points or 0 if the string is NULL
* or empty.
*/
public static int length(String str)
...
Please let me know if any objections for name or return value. It is better to adjust this sooner than later until I made big amount of changes.
#89 Updated by Greg Shah almost 2 years ago
I've been thinking about this. Instead of a set of static helpers, please design a class (maybe U32String?) that represents a string that honors the full 32 unicode range. Each instance of this helper class will contain a Java String and can be substituted easily into our code in place of a regular Java String. Unfortunately, the Java String is final so we can't subclass it. Likewise, we can't make the interface compatible, since the String methods mostly work with char instead of int. The idea is to implement the most important helpers as instance methods that are named the same as the String versions, but have a different signature. Thus we can create an instance with a string and then easily use it in the existing code.
What do you think?
#90 Updated by Eugenie Lyzenko almost 2 years ago
Greg Shah wrote:
I've been thinking about this. Instead of a set of static helpers, please design a class (maybe
U32String?) that represents a string that honors the full 32 unicode range. Each instance of this helper class will contain a JavaStringand can be substituted easily into our code in place of a regular JavaString. Unfortunately, the JavaStringisfinalso we can't subclass it. Likewise, we can't make the interface compatible, since theStringmethods mostly work withcharinstead ofint. The idea is to implement the most important helpers as instance methods that are named the same as theStringversions, but have a different signature. Thus we can create an instance with a string and then easily use it in the existing code.What do you think?
I agree with your offering. The similar idea came to me as well last night, I thought why everything we need was not yet implemented in JDK? The Unicode support level declared as supported long time ago, so the question is why Java String is still committed to 16-bit char values? As least they could introduce true 32-bit Unicode objects, like String.
Anyway there are the points to take into account for new U32String class:
1. Sometimes the text widget code needs old versions of the length(), substring... There are several places in EDITOR widget we need to keep old logic.
2. Several built-in String operation will be invalid for U32String, like String1 + String2 as concatenations.
3. We will have to implement all String methods currently used when dealing with text, like equals, equalsIgnoreCase() and so on. Yes, implementation will be pretty simple by routing to internal String peer object, the class U32String could be big and memory hungry.
I'll try to implement this see what the result is.
#91 Updated by Eugenie Lyzenko almost 2 years ago
Greg,
What do you think is the best location for this class? Like StringHelper - com/goldencode/util? Or may be com/goldencode/p2j/util?
#92 Updated by Eugenie Lyzenko almost 2 years ago
- File editor-unicode0.jpg added
This picture is a current status of the EDITOR widget for Unicode I/O handling:

The upper line is the text imported from file, while the bottom line is the text inserted/typed from keyboard. The text is Ң𝔢ḽļ۵ 𝖶ọ𝑟ḽ𝕕. The most chars are outside BMP Unicode range.
The only difference is missing letter with green mark in imported text. For keyboard the key is 316 which is reserved for Progress "F16" so for keyboard input such symbols are not considered as printable text. Otherwise screen looks fine I think.
Now checking the FILL-IN widget.
#93 Updated by Greg Shah almost 2 years ago
What do you think is the best location for this class? Like
StringHelper-com/goldencode/util? Or may becom/goldencode/p2j/util?
Yes, it should be very generic so com/goldencode/util.
#94 Updated by Greg Shah almost 2 years ago
Cool result!
#95 Updated by Eugenie Lyzenko almost 2 years ago
Greg Shah wrote:
What do you think is the best location for this class? Like
StringHelper-com/goldencode/util? Or may becom/goldencode/p2j/util?Yes, it should be very generic so
com/goldencode/util.
OK. Agreed.
#96 Updated by Eugenie Lyzenko almost 2 years ago
Seems like we need to have similar class for StringBuilder. At this time I know at least two methods to adjust for correct working with code points:
1. StringBuilder.length() to return code point count and actually use StringBuilder.codePointCount().
2. StringBuilder.setCharAt() to replace one char with another. In a case when we need to replace 16-bit char with code point and opposite the additional delete/insert char is necessary to handle surrogate pair to get consistent builder to make a String.
Is it enough demand to introduce one more new class?
#97 Updated by Greg Shah almost 2 years ago
Why not include those methods in the U32String? That class will already be containing other data structures inside. It can edit them too.
#98 Updated by Robert Jensen almost 2 years ago
I've been watching the comments here. I know from my own experince with code pages and C# that Strings are difficult. When you mention "32 bit Unicode" what you really mean is UTF-32, not Unicode. Java uses UTF-16, not Unicode, for it's String class. One drawback to 32 bit characters is memory usage . It goes up dramatically when each character is 32 bits rather than 16. I do agree that it is odd that Java does not seem to fully support Unicode. But I do understand why they use UTF-16. I am curious how you end up solving this rather difficult problem. It is interesting.
#99 Updated by Eugenie Lyzenko almost 2 years ago
Robert Jensen wrote:
I've been watching the comments here. I know from my own experince with code pages and C# that Strings are difficult. When you mention "32 bit Unicode" what you really mean is UTF-32, not Unicode.
OK. Let's clarify the terms. When here I told 32-bit Unicode it means working with regular Java strings with code points base units in mind instead of char variable value. We will introduce new methods so simplify processing. This is not double increasing memory for every String object.
#100 Updated by Tijs Wickardt almost 2 years ago
Eugenie Lyzenko wrote:
Robert Jensen wrote:
I've been watching the comments here. I know from my own experince with code pages and C# that Strings are difficult. When you mention "32 bit Unicode" what you really mean is UTF-32, not Unicode.
OK. Let's clarify the terms. When here I told 32-bit Unicode it means working with regular Java strings with code points base units in mind instead of
charvariable value. We will introduce new methods so simplify processing. This is not double increasing memory for every String object.
That sounds right. You also benefit from the JVM's string interning algorithms this way.
#101 Updated by Greg Shah almost 2 years ago
Correct. We only will use this "wrapper" in the places where we must expose the text as the code point values. Otherwise we leave the Java String implementation intact.
#102 Updated by Eugenie Lyzenko almost 2 years ago
Greg Shah wrote:
Why not include those methods in the
U32String? That class will already be containing other data structures inside. It can edit them too.
OK. This works.
#103 Updated by Eugenie Lyzenko almost 2 years ago
Eugenie Lyzenko wrote:
Greg Shah wrote:
Why not include those methods in the
U32String? That class will already be containing other data structures inside. It can edit them too.OK. This works.
We need to have another method for StringBuilder with modified processing: deleteCharAt(). I'm going to add it in U32String class:
...
public void deleteCharAt(StringBuilder sb, int codePointIdx)
{
// get required index in 16-bit char measure units
codePointIdx = sb.offsetByCodePoints(0, codePointIdx);
sb.deleteCharAt(codePointIdx);
// check if next char is remaining of previous low surrogate value
if (codePointIdx < sb.length() && Character.isLowSurrogate(sb.charAt(codePointIdx)))
{
// remove char becoming a junk
sb.deleteCharAt(codePointIdx);
}
}
...
For now there is one constraint for this approach: the U32String object instance should exist in caller logic when we need this method. But in current use cases this condition is respected so we can use it.
#104 Updated by Eugenie Lyzenko almost 2 years ago
- File fill-in-unicode0.jpg added
This is the first result of FILL-IN refactoring to fully support Unicode fro character based widget:

As you can see the key processing works the same as for EDITOR widget.
The code changes:
1. Fixed cursor positioning, move key handling issues found during implementation.
2. The FILL-IN processing code reworked to use Unicode code points instead of 16-bit char.
3. The new class U32String was extended to include methods, required to operate the String based on code point index, not char index.
4. Whenever it is possible static calls to StringHelper were replaced with U32String for ChUI FILL-IN widget.
So far I'm inclining we will have to replace most of the static methods in StringHelper with same U32String class instance methods.
Greg, in some future we probably will have the ability to get rid of the StringHelper static calls as long as whole FWD will be moved to use U32String class instead of String.
The next steps plan:
1. Verify other data types for FILL-IN widget, including decimal, integer, logical and date(time).
2. Test and debug the Unicode support for ChUI Swing mode client. I think we need to keep this compatibility, let me know if not.
3. Ensure GUI mode compatibility with full range Unicode. Including Swing and Web.
#105 Updated by Eugenie Lyzenko almost 2 years ago
- File chui_swing-unicode0.jpg added
After some debugging and changes we have got full Unicode support for ChUI Swing client:

The additional check is to ensure the selected monospaced font support glyphs painting for full range. I have added new method to check in SwingHelper:
...
/**
* Checks the given font and reports if that font is having all Unicode glyphs to display.
* <p>
* <b>WARNING:</b> this method checks if the given font can display some Unicode code point outside
* BMP Unicode range. The checking criteria can be made more complicated on demand.
*
* @param font
* The font being tested.
*
* @return true if the given font is detected as having a complete enough Unicode glyphs
* to draw.
*/
public static boolean isFullUnicodeGlyps(Font font)
{
// for now we do simple check for code point outside BMP range
return font != null && font.canDisplay(120098);
}
...
The criteria is very simple for now: we check single code point outside BMP range.
The usage for SwingHelper:
...
public static synchronized String[] getMonoFontList(Component comp)
{
if (monofonts == null)
{
String[] all = getFontList();
ArrayList<String> array = new ArrayList<String>();
// filter the list down to monospaced fonts
for (int i = 0; i < all.length; i++)
{
Font font = Font.decode(all[i]);
- if (isMonospaced(font, comp.getFontMetrics(font)))
+ if (isMonospaced(font, comp.getFontMetrics(font)) && isFullUnicodeGlyps(font))
{
array.add(all[i]);
}
}
// save the list
monofonts = (String[]) array.toArray(new String[0]);
}
return monofonts;
}
...
If new method name is need to be changed to some more convenient please let me know.
#106 Updated by Greg Shah almost 2 years ago
isFullUnicodeGlyps should be isFullUnicodeGlyphs.
#107 Updated by Eugenie Lyzenko almost 2 years ago
Greg Shah wrote:
isFullUnicodeGlypsshould beisFullUnicodeGlyphs.
OK.
#108 Updated by Eugenie Lyzenko almost 2 years ago
- File chui_web-unicode0.jpg added
Now after more debug we have correct working for ChUI Web client:

Continue with rest of GUI modes.
#109 Updated by Eugenie Lyzenko almost 2 years ago
The rework for GUI mode widgets is in progress. Fixed multiple issues with cursor positioning and text selection y keyboard in GUI mode for FILL-IN and EDITOR widgets. Had to rework all code referring previous regular String class usage. For full range Unicode this code will not properly work without this refactor. At least in the cases when FWD logic is depending on String text length and substring result values. Also had to fix some similar GUI driver text related code. Finally now it seems to work good. The last point that is not fixed yet is the pretty strange font resolution logic for Swing clients. I see the FWD font usage difference between simple start with./server.sh
and./server.sh net:connectn:secure=true net:server:secure_port=7448.
The first version allows to use full Unicode with test sample, while last shows blank squares instead of expected symbols outside BMP Unicode range. Also the Hotel GUI application does not properly display full Unicode range.
#110 Updated by Eugenie Lyzenko almost 2 years ago
The 7657a updated for review to revision 15372 with last changes rebased with recent trunk 15408, new revision is 15416.
Testing for regression from trunk changes since last rebase.
#111 Updated by Eugenie Lyzenko almost 2 years ago
The 7657a updated to revision 15417.
This change adds support for U32String usage in recent StringFormat changes for incomplete value parsing.
#112 Updated by Eugenie Lyzenko almost 2 years ago
Guys,
During additional testing I have got one point to discuss and clarify.
Currently when 4GL code has full range Unicode literal it is not properly converted for target Java code. Is this a problem we need to fix here? Otherwise for example the widget labels(as well as other string literals) having symbols outside the BMP range will be converted and displayed incorrectly (not the same way as for original code).
The testcase example:
def var fin1 as char view-as FILL-IN label "Čℎấ𝓻___" format "X(20)":U no-undo. def var fin2 as integer view-as FILL-IN label "١ղ𝝉ℯģ℮𝑟" no-undo. def var fin3 as decimal view-as FILL-IN label "Ḍⅇ𝙘𝜄м𝞪ⱡ" no-undo. def var fin4 as logical view-as FILL-IN label "Ɫ੦ĝ𝑖𝕔ąḹ" format "yes/no":U no-undo. def var fin5 as date view-as FILL-IN label "Ḏ𝛂ƫȇ___" no-undo. def var fin6 as datetime view-as FILL-IN label "Ƌ𝗮𝑡ḗ𝗧𝙞м" no-undo. define button ExitButton label "Ε𝔵ỉ𝒕". /* Define frames */ define frame f0 ExitButton skip(1) fin1 skip(1) fin2 skip(1) fin3 skip(1) fin4 skip(1) fin5 skip(1) fin6 with size 60 by 20 side-labels centered title "Ȕ𝔗ᖴ-8 𝙇𝗔𝚩ΣȽ ţḕ𝒔ť". /* Trigger definitions */ enable all with frame f0. wait-for choose of ExitButton.
#113 Updated by Eugenie Lyzenko almost 2 years ago
The 7657a rebased with recent trunk 15411, new revision is 15420.
#114 Updated by Eugenie Lyzenko almost 2 years ago
The 7657a updated for review to revision 15421.
This adds conversion support for full range Unicode literals. As result the testcase from #7657-112 is now properly converging keeping original text values.
#115 Updated by Eugenie Lyzenko almost 2 years ago
The 7657a updated for review to revision 15422. Rebased with recent trunk 15418, new revision is 15429.
The fixed to make full Unicode range support for TEXT, RADIO-SET, TOGGLE-BOX, SELECTION-LIST, COMBO-BOX, MENU widgets for ChUI and GUI clients in different modes (native/Swing/Web). Also fix for PUT-SCREEN statement with Web ChUI simulator mode.
#116 Updated by Eugenie Lyzenko almost 2 years ago
The 7657a rebased with recent trunk 15421, new revision is 15432.
#117 Updated by Eugenie Lyzenko almost 2 years ago
The 7657a updated for review to revision 15433.
This is the fix for issue found while additional testing the EDITOR widget. After PASTE operation the content should be properly updated and cursor should be positioned to the last character of the PASTE string block.
#118 Updated by Eugenie Lyzenko almost 2 years ago
The 7657a rebased with recent trunk 15424, new revision is 15436.
#119 Updated by Eugenie Lyzenko almost 2 years ago
- File selection-list-unicode-chui-swing.jpg added
The 7657a updated for review to revision 15437. Rebased with recent trunk 15426, new revision is 15439.
This is the fix for text rendering issue in ChUI Swing mode. The problem was the MONOSPACED font selected for this mode gets variable symbol width for some code points in full Unicode range. So even requesting fixed width font does not guarantee the real characters will have the same constant width. The best solution I see for now is to draw the single char at position based on some average char width inside base range. The sample for SELECTION-LIST widget is:

The interesting fact is neither native ChUI not Web ChUI are affected by this issue.
#120 Updated by Greg Shah almost 2 years ago
The best solution I see for now is to draw the single char at position based on some average char width inside base range.
It is a clever solution but I prefer not to put this extra processing into the code. If a monospaced font is not really monospaced, then I guess I would prefer to not use it or for glyphs that are not properly sized, to draw the "rectangle character" that means there is no glyph that matches.
#121 Updated by Eugenie Lyzenko almost 2 years ago
Greg Shah wrote:
The best solution I see for now is to draw the single char at position based on some average char width inside base range.
It is a clever solution but I prefer not to put this extra processing into the code. If a monospaced font is not really monospaced, then I guess I would prefer to not use it or for glyphs that are not properly sized, to draw the "rectangle character" that means there is no glyph that matches.
This is original screen for monospaced font that is really not monospaced:

As you can see it is far away from monospaced.
What I think is if we will check every glyph for expected width this will be even more processing per string than in approach we just unconditionally draw string char by char.
I think for your suggest we could complicate the monospaced font selection criteria to ensure glyphs in extended range have same width as in BMP or basic Latin. In this case it is possible to get the font when not all Unicode glyphs are available to draw. So we will get frame square instead of glyph (or other predefined substitution char). If I correctly understood your suggest.
#122 Updated by Eugenie Lyzenko almost 2 years ago
This is an example of using true monospaced font (Dejavu Sans Mono):
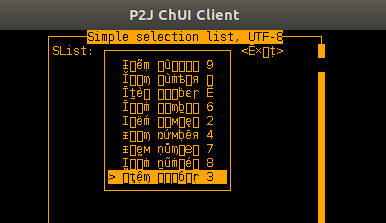
As you can see most of the glyphs are blanked.
#123 Updated by Greg Shah almost 2 years ago
Eugenie Lyzenko wrote:
This is an example of using true monospaced font (
Dejavu Sans Mono):
As you can see most of the glyphs are blanked.
Yes, that is OK. My point here: the customer must use a font that is monospaced for all of the glyphs that they need to display. I don't want to put special processing into our code. I'm OK with the "blanked" characters.
#124 Updated by Eugenie Lyzenko almost 2 years ago
Greg Shah wrote:
Eugenie Lyzenko wrote:
This is an example of using true monospaced font (
Dejavu Sans Mono):
As you can see most of the glyphs are blanked.
Yes, that is OK. My point here: the customer must use a font that is monospaced for all of the glyphs that they need to display. I don't want to put special processing into our code. I'm OK with the "blanked" characters.
OK. I'll revert the recent changes in ChuiSimulator.
The respective custom font can be configured in standard_client.xml like this:
...
<node type="client">
...
<client>
<driver type="chui_swing"/>
...
<chui fontname="Any Mono Font Name if Default Java Monospaced is not good enough"/>
...
</client>
</node>
...
Is this approach OK?
I have found there is a problems with making this option available in client.sh, swing parameter.
#125 Updated by Greg Shah almost 2 years ago
Is this approach OK?
Yes
I have found there is a problems with making this option available in
client.sh,swingparameter.
What is the issue?
#126 Updated by Eugenie Lyzenko almost 2 years ago
Greg Shah wrote:
Is this approach OK?
Yes
I have found there is a problems with making this option available in
client.sh,swingparameter.What is the issue?
The line
swing="client:driver:type=chui_swing client:chui:rows=24 client:chui:columns=80 client:chui:background=0x000000 client:chui:foreground=0xFFA500 client:chui:selection=0x0000FF client:chui:fontname=monospaced client:chui:fontsize=12"
woks fine, but the custom font usage:
swing="client:driver:type=chui_swing client:chui:rows=24 client:chui:columns=80 client:chui:background=0x000000 client:chui:foreground=0xFFA500 client:chui:selection=0x0000FF client:chui:fontname=dejavu sans mono client:chui:fontsize=12"
is not properly parsing, even with swing="... client:chui:fontname='dejavu sans mono' ...". Seems like the font name here should have no " " space chars inside. Am I missing for something?
#127 Updated by Constantin Asofiei almost 2 years ago
Add it in the bootstrap client.xml file. Values with spaces will not work, in the command line arguments.
#128 Updated by Eugenie Lyzenko almost 2 years ago
Constantin Asofiei wrote:
Add it in the bootstrap client.xml file. Values with spaces will not work, in the command line arguments.
Yes, this is noted in #7657-124.
#129 Updated by Eugenie Lyzenko almost 2 years ago
The 7657a updated for review to revision 15440. Rebased with recent trunk 15432, new revision is 15446.
This is reverted ChuiSimulator.java last change. Now the Swing ChUI font usage is adjustable via standard_client.xml file instead of char by char painting.
#130 Updated by Eugenie Lyzenko almost 2 years ago
The 7657a rebased with recent trunk 15436, new revision is 15450.
Additional testing confirms good working usage of the standard_client.xml based font selection with recent trunk.
#131 Updated by Eugenie Lyzenko almost 2 years ago
The 7657a rebased with recent trunk 15448, new revision is 15462.
#132 Updated by Eugenie Lyzenko almost 2 years ago
The 7657a rebased with recent trunk 15450, new revision is 15464.
#133 Updated by Eugenie Lyzenko almost 2 years ago
The 7657a rebased with recent trunk 15454, new revision is 15468.
#134 Updated by Eugenie Lyzenko almost 2 years ago
Detected tooltip issue for Swing client. Debugging.
#135 Updated by Eric Faulhaber almost 2 years ago
- case_num set to PI-11687
#136 Updated by Eugenie Lyzenko almost 2 years ago
The 7657a rebased with recent trunk 15467, new revision is 15481.
Tooltip issue not related to this branch changes. Continue to work on Java 17 compatibility. The testcases looks good. Working on to run other big applications.
#137 Updated by Eugenie Lyzenko almost 2 years ago
The 7657a rebased with recent trunk 15469, new revision is 15483.
#138 Updated by Eugenie Lyzenko almost 2 years ago
The update and question.
Finally I've got wide char capable FWD be compatible with Java 17. Including large customer application in all it's parts and components.
However I have a question for custom fonts usage with full Unicode range. From design the custom fonts are the ones that are constructing with data loading from particular *.ttf font file. This is up to application consumer to ensure the font compatibility with character range planning to use with application. So if the given font is in use - this should mean 100% compatibility with characters used in application. In this case we do not need to perform additional font check inside application. Is my understanding correct?
Asking because some fonts specified as custom ones could be not compatible with full Unicode range and if we do additional strong checking inside FWD - these fonts will not be used in application causing broken L&F. As alternative solution we could introduce extra option in directory.xml to define if we need to check custom font for full Unicode compatibility but I think the custom fonts should be used without additional check. Or the custom-fonts section should be just removed from directory.xml letting default mapper to do the work.
What do you think? I'm going to remove strong Unicode font checking from FontTable.java class.
#139 Updated by Greg Shah almost 2 years ago
Eugenie Lyzenko wrote:
The update and question.
Finally I've got wide char capable
FWDbe compatible with Java 17. Including large customer application in all it's parts and components.However I have a question for custom fonts usage with full Unicode range. From design the custom fonts are the ones that are constructing with data loading from particular
*.ttffont file. This is up to application consumer to ensure the font compatibility with character range planning to use with application. So if the given font is in use - this should mean 100% compatibility with characters used in application. In this case we do not need to perform additional font check inside application. Is my understanding correct?
Yes
What do you think? I'm going to remove strong Unicode font checking from
FontTable.javaclass.
I'm OK with that.
#140 Updated by Eugenie Lyzenko almost 2 years ago
Greg Shah wrote:
Eugenie Lyzenko wrote:
The update and question.
Finally I've got wide char capable
FWDbe compatible with Java 17. Including large customer application in all it's parts and components.However I have a question for custom fonts usage with full Unicode range. From design the custom fonts are the ones that are constructing with data loading from particular
*.ttffont file. This is up to application consumer to ensure the font compatibility with character range planning to use with application. So if the given font is in use - this should mean 100% compatibility with characters used in application. In this case we do not need to perform additional font check inside application. Is my understanding correct?Yes
What do you think? I'm going to remove strong Unicode font checking from
FontTable.javaclass.I'm OK with that.
The 7657a updated for review to revision 15486.
Done.
#141 Updated by Eugenie Lyzenko almost 2 years ago
- File chui_combo_cursor_artifact.jpg added
Another issue has been detected for ChUI native client with COMBO-BOX widget. Consider the following screen for opened combo:

As you can see in addition to expected selection bar we have blinking box shaped cursor in a position that does not match the current selection. In original 4GL system we have only selection bar during the drop-down part opening.
And this is generic FWD issue that is currently inside the trunk version. So this is not related to 7657a branch specific changes.
Investigating...
#142 Updated by Eugenie Lyzenko almost 2 years ago
The problem with ChUI unwanted cursor while drop-down activation is when we call TC.waitForWorker() as the final command of the drop down show this call forces the cursor visibility to be ON (line 14636):
public ScreenBuffer[] waitForWorker(EventList list,
int focusWidgetId,
int millis,
final ScreenBuffer[] inbuf,
boolean force,
boolean status,
boolean entryWindow,
BlockingOperation operation,
boolean restoreFocus,
int windowId)
{
// save cursor state
boolean curvis = tk.setCursorStatus(true);
...
Even we disable cursor before activating drop-down it will become visible again in TC.
I think instead in TC.waitForWorker() we need to get current cursor status instead of making it visible:
{
// save cursor state
+ // a bit dirty way to get the current cursor status
boolean curvis = tk.setCursorStatus(true);
+ tk.setCursorStatus(curvis);
...
Or implement new method for OutputManager - getCursorStatus().
#143 Updated by Hynek Cihlar almost 2 years ago
Eugenie Lyzenko wrote:
The problem with
ChUIunwanted cursor while drop-down activation is when we callTC.waitForWorker()as the final command of the drop down show this call forces the cursor visibility to be ON (line14636):
The call to tk.setCursorStatus from TC has been there for ages. Could the problem be that the cursor position is wrong? Perhaps it would help to find the last working revision and compare with that.
#144 Updated by Eugenie Lyzenko almost 2 years ago
Hynek Cihlar wrote:
Eugenie Lyzenko wrote:
The problem with
ChUIunwanted cursor while drop-down activation is when we callTC.waitForWorker()as the final command of the drop down show this call forces the cursor visibility to be ON (line14636):The call to
tk.setCursorStatusfromTChas been there for ages. Could the problem be that the cursor position is wrong? Perhaps it would help to find the last working revision and compare with that.
May be. But it any case there should be no blinking cursor while drop-down is active in ChUI mode. This is how it works in native 4GL system.
#145 Updated by Eugenie Lyzenko almost 2 years ago
- File chui_combo_cursor_fix.jpg added
Yes, the position for drop-down sets up incorrectly in ScrollableListImpl.drawCaret(). The fix could be pretty simple:
public void drawCaret()
{
...
Point origin = screenLocation();
if (currentRow() > 0)
{
origin.y += currentRow();
}
- screen().at(origin);
+ screen().stayAt(origin);
}
The result:

While the position is now correct the cursor is blinking. And this is now how it should look anyway. So we need to turn it off completely when drop-down is active I guess.
#146 Updated by Eugenie Lyzenko almost 2 years ago
The 7657a rebased with recent trunk 15483, new revision is 15498.
#147 Updated by Eugenie Lyzenko almost 2 years ago
The 7657a rebased with recent trunk 15492, new revision is 15507.
#148 Updated by Eugenie Lyzenko over 1 year ago
The 7657a rebased with recent trunk 15513, new revision is 15528.
#149 Updated by Eugenie Lyzenko over 1 year ago
The 7657a updated for review to revision 15529.
This update added the fix for cursor position/visibility in ChUI mode and combo-box opening drop-down.
#150 Updated by Eugenie Lyzenko over 1 year ago
The 7657a rebased with recent trunk 15520, new revision is 15536.
#151 Updated by Eugenie Lyzenko over 1 year ago
The 7657a rebased with recent trunk 15521, new revision is 15537.
#152 Updated by Eugenie Lyzenko over 1 year ago
The 7657a rebased with recent trunk 15528, new revision is 15545.
#153 Updated by Eugenie Lyzenko over 1 year ago
Eugenie Lyzenko wrote:
The
7657arebased with recent trunk15528, new revision is15545.
The number increased from expected 15544 due to rebase mistake I made in ThinClient.java.
#154 Updated by Eugenie Lyzenko over 1 year ago
The 7657a rebased with recent trunk 15532, new revision is 15549.
#155 Updated by Eugenie Lyzenko over 1 year ago
The 7657a rebased with recent trunk 15545, new revision is 15562.
#156 Updated by Eugenie Lyzenko over 1 year ago
The 7657a rebased with recent trunk 15548, new revision is 15565.
#157 Updated by Eugenie Lyzenko over 1 year ago
The 7657a rebased with recent trunk 15557, new revision is 15574.
#158 Updated by Eugenie Lyzenko over 1 year ago
The 7657a rebased with recent trunk 15561, new revision is 15578.
#159 Updated by Eugenie Lyzenko over 1 year ago
The 7657a rebased with recent trunk 15568, new revision is 15585.
At this time the plan is to run ChUI regression tests to find out how much things has been broken for current wide char capable implementation.
#160 Updated by Eugenie Lyzenko over 1 year ago
The 7657a rebased with recent trunk 15575, new revision is 15592.
Status update. Finally the ChUI regression testing is able to be executed. Not so much issue as I have expected. Moreover the current implementation is seems to be OK. From the first run I have got screen failure for every screen the harness to take for comparison. And my first idea was the screen data is delivering wrong to the terminal. But this is not the case. All attempts to fix the output has failed at least for box drawing characters(ones that are greater than basic Latin I think). Meantime the standalone testcases show the correct screens for full Unicode range in ChUI client.
So far at this time I'm inclining to idea the harness itself is need to be adjusted to run with wide char capable FWD. Consider the harness/terminal/Terminal.java class:
...
public Terminal(FilterPlugin session, TerminalSessionSettings cfg)
{
...
// start a thread to service the incoming screen output
Runnable reader = new Runnable()
{
public void run()
{
byte[] buffer = new byte[BUFFER_SIZE];
try
{
LogHelper.finest("polling for screen data");
int x=0;
while (true)
{
int i = Terminal.this.session.read(buffer);
if (LogHelper.isFinestLoggable())
{
LogHelper.finest("read results in i=" + i);
}
// watch for EOF
if (i < 0)
break;
if (i > 0)
{
putString(new String(buffer, 0, i, ENCODING));<--- Problematic call
// update the counter of bytes read (must be done after
// all processing is complete)
synchronized (lock)
...
Currently we have single "ISO-8859-1" value for ENCODING which I think conflicts with wide NCURSESW based FWD runtime. The change that fixes this issue allowing to get correct testing output is:
...
if (i > 0)
{
- putString(new String(buffer, 0, i, ENCODING));
+ putString(new String(buffer, 0, i));
...
The idea is to use platform default encoding for regression testcases. If we need to keep "ISO-8859-1" for some cases we can make this option configurable at harness runtime. Please let me know what you think.
Meantime I'll check how safe this change for legacy FWD from current trunk.
#161 Updated by Greg Shah over 1 year ago
The idea is to use platform default encoding for regression testcases. If we need to keep "ISO-8859-1" for some cases we can make this option configurable at harness runtime. Please let me know what you think.
It is worth a test with the ChUI regression tests but I suspect we forced the ISO=8859-1 for a reason. We probably should make this configurable.
#162 Updated by Greg Shah over 1 year ago
- reviewer Greg Shah, Hynek Cihlar, Tomasz Domin added
#163 Updated by Greg Shah over 1 year ago
+Tomasz
#164 Updated by Tomasz Domin over 1 year ago
Eugenie Lyzenko wrote:
The idea is to use platform default encoding for regression testcases. If we need to keep
"ISO-8859-1"for some cases we can make this option configurable at harness runtime. Please let me know what you think.
Platform default encoding of which platform ? Note that harness in current configuration connects to remote host or docker container over SSH.
I think we can add a Harness command line option to set remote client encoding the same way we set host/port/userid/password.
#165 Updated by Eugenie Lyzenko over 1 year ago
Tomasz Domin wrote:
Eugenie Lyzenko wrote:
The idea is to use platform default encoding for regression testcases. If we need to keep
"ISO-8859-1"for some cases we can make this option configurable at harness runtime. Please let me know what you think.Platform default encoding of which platform ?
The platform the current terminal screen is capturing by harness Terminal class. This is currently Ubintu 22.04 docker, meaning Ubuntu 22.04, right?
#166 Updated by Eugenie Lyzenko over 1 year ago
The 7657a rebased with recent trunk 15579, new revision is 15596.
#167 Updated by Tomasz Domin over 1 year ago
Eugenie Lyzenko wrote:
The platform the current terminal screen is capturing by harness
Terminalclass. This is currently Ubintu22.04docker, meaning Ubuntu22.04, right?
Its true for ChUI regression testing. But harness is a general purpose testing tool, so it cant be limited to the mentioned configuration.
#168 Updated by Eugenie Lyzenko over 1 year ago
The 7657a updated to revision 15596, rebased with recent trunk 15586, new revision is 15604.
This change adds improvements for Unicode string display native implementation.
The ChUI regression testing is in progress.
#169 Updated by Eugenie Lyzenko over 1 year ago
Eugenie Lyzenko wrote:
The
7657aupdated to revision15596, rebased with recent trunk15586, new revision is15604.This change adds improvements for Unicode string display native implementation.
The
ChUIregression testing is in progress.
The details:
The improvement work performed for native method implementation that should display Unicode string in terminal. We can bypass any extra conversion and pass the 32-bit Unicode code point directly to libp2j compiled with wide char NCURSES static libraries. The Java native call addW32StringNative() now handles this. But only if the CPINTERNAL is UTF-8. For Windows version the result has constraints because seems like only 16-bit Unicode BMP characters are supported for Console session. Or should be handled differently. Also changed the internal getFirstWCharFromCChar() implementation. Now it uses NCURSES API for extracting wchar_t from cchar_t structure. Because I think we should not consider the data type be a constant during NCURSES updates, better to use API for transformations.
However sometimes I have the floating bug with box drawing symbols. Even if the testing will be finally OK I need to think about how the problematic condition is possible because probably we can have data interference or serialization issue.
#170 Updated by Eugenie Lyzenko over 1 year ago
The current implementation is under review to find out possible reasons for floating errors with horizontal lines box drawing. The most like candidates to improve is the new U32String wrapper class. Already found one location where in a loop the U32String length is calculated for each iteration. We need to do it only once before loop starts. Also the next point is a Cell class instances. Currently we make new instance for every cell to be changed. Considering the regression test amount of screens this is pretty hard payload for Java runtime especially for memory consumption. I think we can sometimes exceeds the heap. We have at least 3 cells array with (width x height) size, master, matrix and render. And I'm not sure we need to permanently create new Cell object for every change inside the terminal screen.
#171 Updated by Eugenie Lyzenko over 1 year ago
The 7657a updated to revision 15605, rebased with recent trunk 15590, new revision is 15609.
The set of improvements to optimize U32String processing and usage. The main change is the EMPTY_CELL static object is moved to BasePrimitives class to decrease the size of the new Cell object relaxing memory allocation system a bit. Continue testing to catch remaining issues.
#172 Updated by Eugenie Lyzenko over 1 year ago
The 7657a rebased with recent trunk 15594, new revision is 15613.
The testing looks better, but there is one test failure I need to recheck.
#173 Updated by Eugenie Lyzenko over 1 year ago
The 7657a updated to revision 15614, rebased with recent trunk 15595, new revision is 15615.
This is another improvements to make FWD more stable with memory operation. The current screen arrays are now copied to native layer to exclude ability to mutually change the screen data during terminal update.
Although I have now clean ChUI testing session I still worry about Cell object permanent creation, so continue working to have better approach that does not load the Java memory system.
#174 Updated by Eugenie Lyzenko over 1 year ago
Status update.
The next improvements set is still in progress. The idea is to use update approach for current cell instead of creating new object. This is planned to be used for two arrays, render and master. The matrix array will contain only pointers to the existed objects. This way we will allocate limited numbers of Cell object per client session, maximum 2x80x24. This means the equal size for two sequential full screen updates for previously used approach. I think this is significant improvement that can eliminate or at least greatly reduce memory fragmentation and general loading for memory allocation system for JVM. However while in standalone testcases it works fine the ChUI regression testing has regression failures for this improvement. So I need to understand what the problem is and fix it before I can commit these changes for review. I think it worth the efforts because the improvement is very perspective on my guess.
#175 Updated by Eugenie Lyzenko over 1 year ago
The 7657a rebased with recent trunk 15605 and updated to revision 15626.
This change adds ability to optimize the Cell object creation for ChUI terminal session output. Now instead of permanently create new Cell object for every new symbol to display we do real creation only if the Cell does not yet exist. Otherwise the Cell content is just updated. For long running ChUI terminal session this can give better memory usage from Java heap and significantly reduces the risk of heap fragmentation. We do not need to permanently create new pretty small cell objects relaxing the Garbage Collector work for clean up.
Tested with standalone UTF-8 testcases and singe test run ChUI sessions. The next plan is to do many full ChUI regression testing to find out how it works in critical conditions and heavy load.
#176 Updated by Eugenie Lyzenko over 1 year ago
The 7657a rebased with recent trunk 15611 and updated to revision 15632.
Status update. The stress testing performed for revisions 15626 and 15632, same 7657a but rebased with different recent trunk revisions. The ChUI regression testing are now passing with several runs. Also big GUI application works fine. Seems like the branch is ready for review and merge into trunk.
But I have the question to clarify. How do we plan to use the wide char version of the libp2j.so? Will it be the our default runtime library, or should exist alongside with regular one(not wide char capable). My point is having support for both version can complicate our deployment efforts. What is our strategy for this part of the FWD?
#177 Updated by Greg Shah over 1 year ago
- Status changed from New to Review
#178 Updated by Greg Shah over 1 year ago
Hynek: Please review.
How do we plan to use the wide char version of the
libp2j.so? Will it be the our default runtime library, or should exist alongside with regular one(not wide char capable). My point is having support for both version can complicate our deployment efforts. What is our strategy for this part of theFWD?
To answer this, I need to understand the implications of only having wide char support. How does forcing wide char support limit existing customers? Does it cause issues with hardware or software terminals that are encoded using 7 or 8 bit characters? Are there systems or platforms on which the wide char ncurses is not available?
Please research these questions and report the results. If there is any meaningful limitation to our customers, we will retain both wide char and single byte char support for ncurses.
#179 Updated by Hynek Cihlar over 1 year ago
The changes in 7657a attempt to solve the representation of the full unicode set. So not just the Basic Multilingual Plane (0xFFFF range). Do we actually need this? Going beyond 0xFFFF would have huge consequences. All the string manipulations currently done with Java String class would have to be revisited. Besides, do we know how OpenEdge handles code points above BMP?
#180 Updated by Eugenie Lyzenko over 1 year ago
Hynek Cihlar wrote:
The changes in 7657a attempt to solve the representation of the full unicode set. So not just the Basic Multilingual Plane (0xFFFF range).
Yes, exactly. As much as Java can handle the full Unicode.
Do we actually need this?
Why not? The difference between moving from 0xFFFF to full Unicode range is smaller than from current code to 0xFFFF. We have to rework String processing anyway to correctly handle even BMP range. And if we consider full range this will save further efforts to extend to Unicode. If the output device (terminal or GUI) and fonts have support for symbols - it will display everything, otherwise the empty Java char will be rendered.
Going beyond 0xFFFF would have huge consequences. All the string manipulations currently done with Java String class would have to be revisited.
I have created new U32String wrapper class in FWD to handle everything we need. You can review the class to find out details.
Besides, do we know how OpenEdge handles code points above BMP?
This is a chance to make FWD better than original 4GL making support for full Unicode seamless. No need to convert source or data files from one encoding to another.
#181 Updated by Hynek Cihlar over 1 year ago
Eugenie Lyzenko wrote:
Hynek Cihlar wrote:
The changes in 7657a attempt to solve the representation of the full unicode set. So not just the Basic Multilingual Plane (0xFFFF range).
Yes, exactly. As much as Java can handle the full Unicode.
Do we actually need this?
Why not?
Because this is a lot of work. You would really need to go through all the aspects of text processing in OpenEdge and figure out how it handles code points above BMP. For every individual piece of text logic you would need to check how OpenEdge operates, does it consider code points or wide characters? That is you would need to test every OpenEdge function performing text manipulation, every widget (layout, rendering), text input and output, etc.
Also moving to code points isn't straight forward by itself. Consider the accents for example. An accented symbol can be represented by a single code point or two code points (base char + individual accent).
The difference between moving from
0xFFFFto full Unicode range is smaller than from current code to0xFFFF. We have to reworkStringprocessing anyway to correctly handle evenBMPrange.
Java String already provides support for BMP, it operates on 2-byte characters. Well it supports non-bmp as well, but then the application logic must deal with the surrogate chars.
#182 Updated by Eugenie Lyzenko over 1 year ago
The 7657a rebased with recent trunk 15612 and updated to revision 15634.
Small change to remove dead code and making TODO reminder to check for possible issues.
Also I did the ChUI regression testing for 7657a in non-wide char mode. The tests are passing. This means the 7657a is compatible with currently used mode in trunk for ChUI application. Continue research.
#183 Updated by Hynek Cihlar over 1 year ago
Hynek Cihlar wrote:
Because this is a lot of work. You would really need to go through all the aspects of text processing in OpenEdge and figure out how it handles code points above BMP. For every individual piece of text logic you would need to check how OpenEdge operates, does it consider code points or wide characters?
Eugenie, please consider the following code sample.
message length(a-non-bmp-value).
What should the above output? Is it the number of individual chars or the number of code points?
#184 Updated by Eugenie Lyzenko over 1 year ago
Hynek Cihlar wrote:
Hynek Cihlar wrote:
Because this is a lot of work. You would really need to go through all the aspects of text processing in OpenEdge and figure out how it handles code points above BMP. For every individual piece of text logic you would need to check how OpenEdge operates, does it consider code points or wide characters?
Eugenie, please consider the following code sample.
[...]
What should the above output? Is it the number of individual chars or the number of code points?
My testing in 4GL under Windows shows strange result. The LENGTH(..., "CHARACTER") is 0 if value exceeds BMP Unicode range. Even for -cpinternal is UTF-8.
#185 Updated by Hynek Cihlar over 1 year ago
Eugenie Lyzenko wrote:
Hynek Cihlar wrote:
Hynek Cihlar wrote:
Because this is a lot of work. You would really need to go through all the aspects of text processing in OpenEdge and figure out how it handles code points above BMP. For every individual piece of text logic you would need to check how OpenEdge operates, does it consider code points or wide characters?
Eugenie, please consider the following code sample.
[...]
What should the above output? Is it the number of individual chars or the number of code points?
My testing in 4GL under Windows shows strange result. The
LENGTH(..., "CHARACTER")is0if value exceedsBMPUnicode range. Even for-cpinternalisUTF-8.
Eugenie, I posted the example just for illustration. There are many many cases which must be addressed in order to properly support the full unicode set. And I'm not mentioning the change in the development process (the use of the base Java classes) and potential performance implications.
May I suggest, and assuming BMP is enough for the customer now, to fix support for BMP now and consider full unicode as a future enhancement?
#186 Updated by Greg Shah over 1 year ago
Please see #7657-59 for the scope of this task. I am focused on the terminal input/output and making that safe. I am OK with supporting the full range of Unicode (and prefer it) so long as it doesn't require an extensive effort to rework all of FWD (and the 4GL compatibility support) at the same time.
LENGTH(..., "CHARACTER")is0if value exceeds BMP Unicode range
In regard to things like this, there is a tightrope we walk between "OpenEdge Bug" and "OpenEdge Quirk". If an application can reasonably rely upon a weird behavior in order to process correctly, then even something that looks like a bug may have to be implemented. On the other hand, some things are just bugs and we don't duplicate such things. Sometimes it is hard to know the difference. Anyway, for now the behavior of these parts of the code are not things we will work on.
#187 Updated by Eugenie Lyzenko over 1 year ago
The 7657a updated to revision 15635, rebased with recent trunk 15616, new revision is 15639.
This is the small fix for LENGTH() function return value when operating with BMP Unicode range. Making ChUI regression testing for rev 15639.
Also I made some research for how this wide char mode can behave on different systems/terminals.
0. The general case. The 7657a implementation is based on using 32-bit code point for every cases. So no matter what is the final output device is all Java processing operating with full code points. Only final rendering step of displaying code point to particular terminal can have UI artifacts.
1. The Linux systems. As far as I know all distributions have NCURSES wide package. I tested xterm, vt320, vt220 and vt100. At this time I do not see any issues from using wide char mode.
2. The Windows systems. In command shell sessions there are no changes in native code. So I do not think we will have new issues/bugs. But as general consideration the particular Windows installation will only support the code page integrated in system, otherwise the characters will work with errors. In a best case we will have invalid chars for unknown Unicode symbols. However I have only English US Windows set up and no experience of using 32-bit Unicode capable OS.
3. The Solaris does not have wide char version of NCURSES, I can not find any reference for this possibility. In this case FWD will working old fashion. However it might be useful to refresh my local Solaris install to see how it will now work.
The other OS are out of the scope of our support program, correct? No FreeBSD or other Unix like ones.
Greg,
You mentioned some hardware terminal. Can you clarify what it can be? Can we simulate this environment inside KVM? Seems like I need some specific testing environment that is close to the real deployment system. Otherwise I'm sitting on the too comfortable system to find out more possible issues to fix. Does 'hardware' terminal operate under some minimal version of Linux distro?
Taking all into account I have reviewed my preference, we need for customer to have an option for whether to use wide char version or not.
#188 Updated by Greg Shah over 1 year ago
You mentioned some hardware terminal. Can you clarify what it can be? Can we simulate this environment inside KVM?
The customer has vt100, vt220 and vt320 hardware terminals connected via serial ports to some Linux client system (Red Hat/CentOS) on which they run the FWD client and NCURSES.
I don't think there is any difference from using a terminal emulator, except that the hardware terminals cannot be re-configured to a different terminal type.
The other OS are out of the scope of our support program, correct? No FreeBSD or other Unix like ones.
For now, yes. But who knows what customer requests may require in the future.
we need for customer to have an option for whether to use wide char version or not.
Correct. The Solaris case forces this.
#189 Updated by Eugenie Lyzenko over 1 year ago
The 7657a rebased with trunk 15619, updated to revision 15644.
The name convention change for method to display U32String in native terminal. Also changed access to buffer data in native code to copy data instead of simple dereferencing.
#190 Updated by Tomasz Domin over 1 year ago
Review 7657a/15644
It took me some time to understand scope changes/detailing over time here, please forgive if I am still behind.
Besides ComboBox cursor changes (I am always worried when I see any ComboBox changes) I see all changes are related to string processing.
From what I understand - in order to support BMP the only Java code changes were needed on interface to NCURSES. As Java supports Unicode via its internal UTF-16 encoding String was fine for BMP, but not for other planes - it was needed to switch to CodePoint API anyway to support additional planes of UTF-8 - and U32String does it. The natural next step was to migrate from String to U32String wherever it was needed. I also share the some worries as HC - if implemented changes are enough to consider that all cases for UTF-8 encoding on terminal are implemented already.
We have to rework String processing anyway to correctly handle even BMP range
Eugenie - wouldn't that work out of the box - except for NCURSES interface ?
I am fine with code changes/formatting.
#191 Updated by Eugenie Lyzenko over 1 year ago
- File chui_issues.jpg added
Tomasz Domin wrote:
Review 7657a/15644
It took me some time to understand scope changes/detailing over time here, please forgive if I am still behind.
BesidesComboBoxcursor changes (I am always worried when I see anyComboBoxchanges) I see all changes are related to string processing.From what I understand - in order to support BMP the only Java code changes were needed on interface to NCURSES. As Java supports Unicode via its internal UTF-16 encoding
Stringwas fine for BMP, but not for other planes - it was needed to switch to CodePoint API anyway to support additional planes of UTF-8 - andU32Stringdoes it. The natural next step was to migrate fromStringtoU32Stringwherever it was needed. I also share the some worries as HC - if implemented changes are enough to consider that all cases for UTF-8 encoding on terminal are implemented already.We have to rework String processing anyway to correctly handle even BMP range
Eugenie - wouldn't that work out of the box - except for NCURSES interface ?
Yes, if building 7657a with legacy (not wide char capable NCURSES) it works as before. Even passing ChUI regression testing.
Now I'm struggling with issues like this:

It happens only when using wide char NCURSES. And happening not always, sometimes tests are clean. Not testcase specific. The only I can tell is the area is box drawing symbols, vertical or horizontal lines.
And only for heavy load multi-threaded ChUI harness. The standalone manual tests work fine.
#192 Updated by Hynek Cihlar over 1 year ago
As Tomasz says the scope should be really very narrow, close to the NCURSES library and the low-level terminal processing (ConsolePrimitives.append looks like the big one).
Certainly there is no need to move out from UTF-16 to resolve this issue. I.e. the U32String class should not be needed, at least not to address this issue.
In ConsolePrimitives.append the UTF-8 case doesn't seem right for Windows. The supplied string is converted to an array of code points (int[]) and this array is passed to addchNative. There the 32bit code point is casted to WORD, which is 16bit char type.
#193 Updated by Eugenie Lyzenko over 1 year ago
Hynek Cihlar wrote:
As Tomasz says the scope should be really very narrow, close to the NCURSES library and the low-level terminal processing (
ConsolePrimitives.appendlooks like the big one).Certainly there is no need to move out from UTF-16 to resolve this issue. I.e. the
U32Stringclass should not be needed, at least not to address this issue.In
ConsolePrimitives.appendthe UTF-8 case doesn't seem right for Windows. The supplied string is converted to an array of code points (int[]) and this array is passed toaddchNative. There the 32bit code point is casted toWORD, which is 16bit char type.
Yes, in Windows we use only low 16-bit of the int character passed to windows native call. This means only BMP range is supported in Windows and this is how it currently works in FWD trunk.
#194 Updated by Eugenie Lyzenko over 1 year ago
The 7657a rebased with trunk 15621, new revision is 15646.
#195 Updated by Hynek Cihlar over 1 year ago
Eugenie Lyzenko wrote:
Yes, in Windows we use only low 16-bit of the int character passed to windows native call. This means only
BMPrange is supported in Windows and this is how it currently works inFWDtrunk.
If Windows is scoped out, then this is fine.
#196 Updated by Hynek Cihlar over 1 year ago
Hynek Cihlar wrote:
Eugenie Lyzenko wrote:
Yes, in Windows we use only low 16-bit of the int character passed to windows native call. This means only
BMPrange is supported in Windows and this is how it currently works inFWDtrunk.If Windows is scoped out, then this is fine.
And I should add that it will still work fine for BMP.
#197 Updated by Tomasz Domin over 1 year ago
Eugenie Lyzenko wrote:
We have to rework String processing anyway to correctly handle even BMP range
Eugenie - wouldn't that work out of the box - except for NCURSES interface ?
Yes, if building
7657awith legacy (not wide char capableNCURSES) it works as before. Even passingChUIregression testing.
I meant - if building 7657a with wide char interface changes would FWD support FWD without other changes ?
Now I'm struggling with issues like this:
I tried and got first screen broken. Did you do any special harness configuration ?
#198 Updated by Eugenie Lyzenko over 1 year ago
Hynek Cihlar wrote:
Hynek Cihlar wrote:
Eugenie Lyzenko wrote:
Yes, in Windows we use only low 16-bit of the int character passed to windows native call. This means only
BMPrange is supported in Windows and this is how it currently works inFWDtrunk.If Windows is scoped out, then this is fine.
And I should add that it will still work fine for BMP.
Yes, and it should.
#199 Updated by Eugenie Lyzenko over 1 year ago
Tomasz Domin wrote:
Eugenie Lyzenko wrote:
We have to rework String processing anyway to correctly handle even BMP range
Eugenie - wouldn't that work out of the box - except for NCURSES interface ?
Yes, if building
7657awith legacy (not wide char capableNCURSES) it works as before. Even passingChUIregression testing.I meant - if building
7657awith wide char interface changes would FWD support FWD without other changes ?
Sorry I still do not understand what conditions you meant. You can build FWD either with wide char enabled or not. Both builds will be different you can not mix components from different builds. But no matter what version you choose the existed applications should behave the same way.
What do you mean by "FWD without other changes"?
#200 Updated by Eugenie Lyzenko over 1 year ago
The 7657a rebased with trunk 15623, new revision is 15648.
#201 Updated by Tomasz Domin over 1 year ago
- Related to Bug #9489: Support for different terminal encodings added
#202 Updated by Eugenie Lyzenko over 1 year ago
Status update.
Updating NCURSESW knowledge and double check the source code for possible root causes of the screen garbage floating issues. Also reading the libc manual library to ensure the data types are correctly used in wide char native module. No obvious issues have been found.
But one possible case encountered. When putting text string on the screen the NCURSESW refresh() function should be finally called to do real transfer of the internal changed buffer to the terminal screen. So far we can ensure the current screen is up to date before making next changes to terminal.
#203 Updated by Greg Shah over 1 year ago
Does NCURSESW need to be modified to extend the auto_getch_refresh patch to a different location? The problem you are describing seems to be the same as the one for which we originally introduced auto_getch_refresh. When the key processing thread in FWD is reading keys from NCURSES, it causes a refresh() of the terminal, which caused corruption because NCURSES (without extra code to leverage new facilities) assumes that the calling code is on a single thread. We introduced our patch to disable that extra refresh when getch was called. If we are calling a different key reading function, that could explain the problem.
#204 Updated by Eugenie Lyzenko over 1 year ago
Greg Shah wrote:
Does NCURSESW need to be modified to extend the
auto_getch_refreshpatch to a different location? The problem you are describing seems to be the same as the one for which we originally introducedauto_getch_refresh. When the key processing thread in FWD is reading keys from NCURSES, it causes arefresh()of the terminal, which caused corruption because NCURSES (without extra code to leverage new facilities) assumes that the calling code is on a single thread. We introduced our patch to disable that extra refresh whengetchwas called. If we are calling a different key reading function, that could explain the problem.
Yes, we have different function for key reading: get_wch(). I'll investigate if we need to patch this too.
#205 Updated by Tomasz Domin over 1 year ago
Eugenie Lyzenko wrote:
Status update.
Updating
NCURSESWknowledge and double check the source code for possible root causes of the screen garbage floating issues. Also reading thelibcmanual library to ensure the data types are correctly used in wide char native module. No obvious issues have been found.
Eugenie
I've bulild wide-char ncurses FWD and I am running regression tests with a bit modified harness to support UTF-8 encoding and I don't get that garbage and tests are passing normally.
Is there a way to check which version of NCURSES is used in FWD runtime to make sure I am testing a proper version ?
#206 Updated by Eugenie Lyzenko over 1 year ago
Tomasz Domin wrote:
Eugenie Lyzenko wrote:
Status update.
Updating
NCURSESWknowledge and double check the source code for possible root causes of the screen garbage floating issues. Also reading thelibcmanual library to ensure the data types are correctly used in wide char native module. No obvious issues have been found.Eugenie
I've bulild wide-char ncurses FWD and I am running regression tests with a bit modified harness to support UTF-8 encoding and I don't get that garbage and tests are passing normally.Is there a way to check which version of NCURSES is used in FWD runtime to make sure I am testing a proper version ?
1. You need to build wide char NCURSES static library in separate location, different from regular NCURSES.
2. Before building FWD ensure the following system variables set up correctly:
... export NCURSES_FWD_STATIC=/full/path/to/ncurses_static_wide_char export NCURSES_FWD_WIDE_CHARS=yes ...
3. The easy way to check if you are on wide char FWD is to check libp2j.so. It should have reference to wide char native calls like addWchNative.
#207 Updated by Tomasz Domin over 1 year ago
Eugenie Lyzenko wrote:
3. The easy way to check if you are on wide char
FWDis to checklibp2j.so. It should have reference to wide char native calls likeaddWchNative.
So all good:
fwd@03d46f5d8bc9:~/testing/xxxxx/deploy/lib$ nm libp2j.so |grep addWchNative 0000000000015aab T addWchNative
If garbage is multi-threading issue it may not show up in every case or on every machine, for me regression tests are passing but it does not mean the issue does not exists.
#208 Updated by Eugenie Lyzenko over 1 year ago
Tomasz Domin wrote:
Eugenie Lyzenko wrote:
3. The easy way to check if you are on wide char
FWDis to checklibp2j.so. It should have reference to wide char native calls likeaddWchNative.So all good:
[...]
Yes, this is wide char version.
If garbage is multi-threading issue it may not show up in every case or on every machine, for me regression tests are passing but it does not mean the issue does not exists.
Moreover the result can vary even on the same machine. Some days tests are clean but this does not mean the problem is gone. So pretty difficult to diagnose/debug.
#209 Updated by Eugenie Lyzenko over 1 year ago
Tomasz Domin wrote:
Eugenie Lyzenko wrote:
Status update.
Updating
NCURSESWknowledge and double check the source code for possible root causes of the screen garbage floating issues. Also reading thelibcmanual library to ensure the data types are correctly used in wide char native module. No obvious issues have been found.Eugenie
I've bulild wide-char ncurses FWD and I am running regression tests with a bit modified harness to support UTF-8 encoding and I don't get that garbage and tests are passing normally.
Tomasz,
What is your change to support UTF-8. Is it config only or harness Java code is involved? My fix was describe in #7657-160. Is your one related? I would like to test.
#210 Updated by Tomasz Domin over 1 year ago
Eugenie Lyzenko wrote:
What is your change to support
UTF-8. Is it config only or harness Java code is involved? My fix was describe in #7657-160. Is your one related? I would like to test.
yes, that's exactly the change, nothing more was changed.
Please checkout harness/active/9489a and use following regression tests command line update -o "-encoding utf-8 -v password=fwd -d -c -x"
#211 Updated by Eugenie Lyzenko over 1 year ago
Eugenie Lyzenko wrote:
Greg Shah wrote:
Does NCURSESW need to be modified to extend the
auto_getch_refreshpatch to a different location? The problem you are describing seems to be the same as the one for which we originally introducedauto_getch_refresh. When the key processing thread in FWD is reading keys from NCURSES, it causes arefresh()of the terminal, which caused corruption because NCURSES (without extra code to leverage new facilities) assumes that the calling code is on a single thread. We introduced our patch to disable that extra refresh whengetchwas called. If we are calling a different key reading function, that could explain the problem.Yes, we have different function for key reading:
get_wch(). I'll investigate if we need to patch this too.
The code checking result. Both getch (regular version) and get_wch() (wide char version) finally use recur_wrefresh() to optionally sync the screen. And this is the call where getch_refresh is taking into account to decide if to refresh screen or not. So seems like the key reading in wide char version is not a cause for screen corruption.
#212 Updated by Eugenie Lyzenko over 1 year ago
More investigating the NCURSES character output functions for wide char mode I've found the implementation uses conditional internal locks to serialize output. But in default NCURSESW config mutex locking is not used because we have to configure --with-pthreads before comping NCURSES itself. On the other hand seems like the NCURSES is not thread safe. But we can make libp2j.so to be thread safe. I guess if we have two concurrent thread that one reading key and other - making screen updates, the libp2j.so should be made thread safe having required data synchronization facilities. As the first step we can enable PTHREADS and see how this will affect the testing results. The idea of the sync concept to have key reading priority and when idle then do the screen refresh.
#213 Updated by Eugenie Lyzenko over 1 year ago
The further investigation of the NCURSES internal shows the library has some locking facility to serialize screen access. This could be enough to do our work to eliminate screen garbage issue. However to leverage this the NCURSES wide version of static library should be rebuild with additional config option: --with-pthread. The complete cofig command become:
./configure --with-termlib CFLAGS='-fPIC -O2' --with-abi-version=6 --with-pthread --enable-widec
I have prepared this version and tested FWD once for full ChUI regression cycle. No problems found so far. However one positive round is not enough to be more or less sure the FWD is in good shape.
So I'm planning to do several rounds to get stable results, then commit the changes into branch.
#214 Updated by Eugenie Lyzenko over 1 year ago
The 7657a rebased with trunk 15627, new revision is 15652.
Continue testing different fixes that can eliminate screen garbage issues with harness ChUI regression testing main round. For now there is no absolute cure. The only I can tell for sure is the problem is not related to auto_getch_refresh variable. I temporary changed the key reading to old fashion(used in current trunk) with wide char version and no changes, sometimes we still getting incorrect chat in harness. Will continue after vacation. The problem is somewhere in char display call or harness compatibility with wide char FWD.
#215 Updated by Greg Shah over 1 year ago
- % Done changed from 0 to 90
- Status changed from Review to WIP
As far as I know, there are fixes needed.
#216 Updated by Eugenie Lyzenko over 1 year ago
Greg Shah wrote:
As far as I know, there are fixes needed.
Yes, we still have sometimes screen garbage chars in harness.
Tried to use PTHREADS capable NCURSES. Unfortunately sometimes I still have FFFD char instead of box drawing characters. I have two theories, one is the NCURSES build with pthreads support should be configures with option '--enable-pthreads-eintr' to get more thread safe code. The other possible cause is to check if the harness terminal screen reading code has condition that can emit incorrect char when reading is failing or other error. Actually I disabled the failing char (FFFD) to be put into terminal screen so for now I do not know where it is came from (in regular interactive terminal I never saw this). Also I'm learning how to use pthread mutex objects to make alternative data serialization between key reading and screen update threads. The idea is to make key reading calls only when screen is idle(all updates transferred to real terminal and can be seen). This is the next plans in short. Continue working.
#217 Updated by Tomasz Domin over 1 year ago
Eugenie Lyzenko wrote:
Tried to use
PTHREADScapableNCURSES. Unfortunately sometimes I still haveFFFDchar instead of box drawing characters. I have two theories, one is theNCURSESbuild with pthreads support should be configures with option'--enable-pthreads-eintr'to get more thread safe code. The other possible cause is to check if the harness terminal screen reading code has condition that can emit incorrect char when reading is failing or other error. Actually I disabled the failing char (FFFD) to be put into terminal screen so for now I do not know where it is came from (in regular interactive terminal I never saw this). Also I'm learning how to use pthread mutex objects to make alternative data serialization between key reading and screen update threads. The idea is to make key reading calls only when screen is idle(all updates transferred to real terminal and can be seen). This is the next plans in short. Continue working.
Eugenie - that gave a me hint. As harness works based on bytes that may be the case where UTF-8 character is missing second or following byte as FFFD stands for non-decodable character.
I think more effort needs to be put into #9489 - I will fix it there.
#218 Updated by Eugenie Lyzenko over 1 year ago
Tomasz Domin wrote:
Eugenie Lyzenko wrote:
Tried to use
PTHREADScapableNCURSES. Unfortunately sometimes I still haveFFFDchar instead of box drawing characters. I have two theories, one is theNCURSESbuild with pthreads support should be configures with option'--enable-pthreads-eintr'to get more thread safe code. The other possible cause is to check if the harness terminal screen reading code has condition that can emit incorrect char when reading is failing or other error. Actually I disabled the failing char (FFFD) to be put into terminal screen so for now I do not know where it is came from (in regular interactive terminal I never saw this). Also I'm learning how to use pthread mutex objects to make alternative data serialization between key reading and screen update threads. The idea is to make key reading calls only when screen is idle(all updates transferred to real terminal and can be seen). This is the next plans in short. Continue working.Eugenie - that gave a me hint. As
harnessworks based on bytes that may be the case where UTF-8 character is missing second or following byte asFFFDstands for non-decodable character.
I think more effort needs to be put into #9489 - I will fix it there.
OK. One note here. The issue is not persistent. I mean there is no recreation scenario. No problems with interactive ChUI terminal. And even with harness there is no logic to explain how bug is happening. It can appear in different screens(or even possible to get clean tests). I think it is somehow depending on system overall loading or number of threads running simultaneously.
#219 Updated by Greg Shah over 1 year ago
- Related to Support #2660: evaluate if the NCURSES 5.7 "threading improvements" can be made to work for P2J such that auto_getch_refresh() is no longer needed added
#220 Updated by Greg Shah over 1 year ago
Also I'm learning how to use pthread mutex objects to make alternative data serialization between key reading and screen update threads. The idea is to make key reading calls only when screen is idle(all updates transferred to real terminal and can be seen). This is the next plans in short. Continue working.
Please see #2660. If that is the solution, I'm OK with it. Please note that a very large intended benefit is to eliminate the need to patch ncurses.
#221 Updated by Eugenie Lyzenko over 1 year ago
The new fix for harness has also been integrated and moved into stress testing environment. I'm going to have 3 sequential full positive cycles to make conclusion the screen garbage issue has been fixed. Meantime working on the capability to use mutex object to serialize I/O between two threads in libp2j.so. For possible ability to eliminate requirements to patch NCURSES. The main task here related to the fact we have semi blocking input from getting char code. The key reading loop is a permanent calling readKey() with 500 ms timeout if no key is coming. In this condition having mutex lock/unlock inside native key reader produces almost no chances for screen to be updated if the screen update also uses the same mutex to get control over screen. On the other hand I can not agree with statement the auto_getch_refresh(FALSE) will not work with wide char key reading (as I can see from #2660 conversation). The both getch() and get_wch() have the common refresh logic that disables the screen refresh call in key reader. So this is a valid patch. And some pthread addition since 5.7 of NCURSES are useless in this regard. It can help if two thread will do screen update simultaneously, so this is seems to be not our case.
#222 Updated by Eugenie Lyzenko over 1 year ago
The 7657a updated to revision 15653, rebased with trunk 15634, new revision is 15660.
The update contains small changes to simplify native code reading/understanding.
So far after fixing harness issue I do not see the screen garbage in wide char linked libp2j.so anymore. Even without any pthread specific code/link options. This lets me conclude the 7657a has no regression and is in a good shape. I'll make control testing for 15660 revision but do not expect any surprises.
For making libp2j.so thread safe and getting rid of requirement to patch NCURSES I think we can consider this task as separate one. Using additional mutex to sync the screen updates constantly regresses the GSO_197 testcase. On the other hand the single full ChUI regression round shows no failures for NCURESES version that has no auto_getch_refresh(FALSE) call. This means equivalent to unpatched NCURSES compiled with pthreads option enabled and NCURSES version 6.3+. What if we do not need to patch NCURSES anymore when compiling static NCURSES with enabled pthreads?
Is there any scenario that will certainly fail for not patched NCURSES in regular conditions? If yes and we can pass it with pthreads enabled then we could not patch NCURSES anymore.
#223 Updated by Greg Shah over 1 year ago
For making
libp2j.sothread safe and getting rid of requirement to patchNCURSESI think we can consider this task as separate one. Using additional mutex to sync the screen updates constantly regresses theGSO_197testcase. On the other hand the single fullChUIregression round shows no failures forNCURESESversion that has noauto_getch_refresh(FALSE)call. This means equivalent to unpatched NCURSES compiled withpthreadsoption enabled andNCURSESversion6.3+. What if we do not need to patchNCURSESanymore when compiling staticNCURSESwith enabledpthreads?Is there any scenario that will certainly fail for not patched
NCURSESin regular conditions? If yes and we can pass it withpthreadsenabled then we could not patchNCURSESanymore.
In #2660, please detail exactly what you did to setup your test and these results.
#224 Updated by Eugenie Lyzenko over 1 year ago
The 7657a rebased with trunk 15635, new revision is 15661.
Continue different regression testing. The ChUI harness suite is OK. Big GUI application also looks regressions free. Started new round after rebase. May be need to ensure Java 17 is fully compatible with this branch.
#225 Updated by Eugenie Lyzenko over 1 year ago
- % Done changed from 90 to 100
- Status changed from WIP to Review
#226 Updated by Eugenie Lyzenko over 1 year ago
The 7657a rebased with trunk 15652, new revision is 15678.
Just rebase with new trunk. Passed ChUI regression testing.
#227 Updated by Eugenie Lyzenko over 1 year ago
The 7657a rebased with trunk revision 15800, new revision is 15826.
Just rebase to match current trunk.
#228 Updated by Eugenie Lyzenko over 1 year ago
The 7657a rebased with trunk revision 15842, new revision is 15868.
Just rebase.
#229 Updated by Eugenie Lyzenko about 1 year ago
The 7657a rebased with trunk revision 15873, updated to revision 15901.
The update after rebase to fix rebase issues, some code corruption detected while compiling and testing.
#230 Updated by Eugenie Lyzenko about 1 year ago
The 7657a rebased with trunk revision 15875, new revision is 15903.
Tested with regular samples used with implementation. No problems found so far.
#231 Updated by Eugenie Lyzenko about 1 year ago
The 7657a rebased with trunk revision 15877, new revision is 15905.
#232 Updated by Eugenie Lyzenko about 1 year ago
The 9526b rebased with trunk revision 15878, new revision is 15879.
The branch was tested with Java 17. No problems found.
I would suggest to merge this into trunk if no objections. In theory we could resolve some Unicode related issues that are currently under development.
#233 Updated by Sergey Ivanovskiy about 1 year ago
I looked at the diff and found that these changes bring back this code
+ public static char[] toCharArray(int i)
+ {
+ synchronized (Utils.class)
+ {
+ if (!init)
+ {
+ override = getCharsetOverride(I18nOps.getJavaCharset());
+ init = true;
+ }
+ }
+
+ return toCharArray(i, override);
+ }
Is this method needed? We added
KeyInput.getChar() and this method was removed.
In respect to #9293 these changes are independent and seems to me they should not fix #9293-195 because of
/**
* This class represents the keyboard event codes, key labels and Progress
@@ -1338,11 +1342,14 @@
*/
public static int keyCode(final String label)
{
- final int labelLength = label.length();
+ int labelLength = label.length();
if (labelLength == 0)
{
return -1;
}
+
+ // fixup Unicode string length, one Unicode char can occupy 2 Java chars
+ labelLength = label.codePointCount(0, labelLength);
final Keyboard kb = work.obtain();
@@ -1461,6 +1468,8 @@
return new String(Character.toChars(code));
}
+ // we need to safe Unicode BMP original code value
+ int codeBmp = code;
code = code % 4096;
// some labels can be overwritten, depending on the client type (ChUI/GUI, linux/windows).
@@ -1469,6 +1478,14 @@
return kb.extendedKeys.get(code);
}
+ // Support for Basic Multilingual Pane (BMP)
+ // but first 655 codes are hard reserved for Progress
+ if (codeBmp > 655 && Character.isLetterOrDigit(codeBmp))
+ {
+ return new String(new int[] {codeBmp}, 0, 1);
+ }
+
+
if (kb.useRule1(code))
{
return kb.applyRule1(code);
@@ -1968,14 +1985,10 @@
*/
public static boolean isPrintable(String event)
{
- if (event.length() != 1)
- {
- return false;
- }
-
- int codePoint = event.codePointAt(0);
-
- return !Character.isISOControl(codePoint);
+ // the string chars size can be more than string length for Unicode
+ U32String u32str = new U32String(event);
+ int strLength = u32str.length();
+ return strLength == 1 && !Character.isISOControl(event.codePointAt(0));
}
#9293-195 is not related to 4GL but it is an issue happened when we tried to extend characters in the case when 4GL does not display them in the case of the web client. Thus I planned to make changes that the java script web client sends additional data that indicates that the key is unicode key represented a printed character to the java web client.
#234 Updated by Sergey Ivanovskiy about 1 year ago
I imported the project and did a search for Utils.toCharArray(int i) usages. The result was one usage
com.goldencode.p2j.ui.client Editor<O extends OutputManager<?>> processKeyEvent(KeyInput)
#235 Updated by Sergey Ivanovskiy about 1 year ago
The javascript web client for printed typed keys sends this value key.codePointAt(0) as a Unicode code point value of the character
function getKeyCharCode(event)
{
return getCodePoint(event.key);
}
me.getKeyCharCode = getKeyCharCode;
function getCodePoint(key)
{
if ((key) && key.length <= 2)
{
return key.codePointAt(0);
}
return 0;
}
https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/String/codePointAt
This is UTF-16 encoding. In the code we suppose that this is UTF-8 and it looks confusing
public static int getCodepoint(int keyCode, String cset)
{
// for UTF-8 no need additional conversion
if ("UTF-8".equalsIgnoreCase(cset))
{
return keyCode;
}
ByteBuffer bf = ByteBuffer.allocate(4);
..............................................
}
#236 Updated by Hynek Cihlar 3 months ago
Code review 7657a revisions 15878..15906
Before I go into any comments for the code changes I'd like to raise a concern about the introduction of U32String in the UI layer as the replacement of native Java String class.
- Link against wide NCURSES (libncursesw) and use add_wch/get_wch in the native layer
- Pass the correct encoding (UTF-8) through the terminal harness
- Properly handle multi-byte UTF-8 sequences at the native/Java boundary
None of these require replacing String.length() or String.substring() with code-point-aware equivalents throughout the UI layer.
Design-wise, introducing a new string class is a heavyweight decision. It's essentially a parallel to java.lang.String that every developer on the project needs to know about and use correctly. Every place that passes a String to a widget, formats text, or computes a cursor position becomes a potential bug if someone forgets to wrap it in U32String. The class doesn't integrate with standard Java APIs (CharSequence, Comparable), so it can't be used interchangeably with String or StringBuilder - it requires explicit conversion at every boundary. That kind of pervasive type is a long-term maintenance cost that needs its own design discussion, not something to slip in with a character encoding bug fix.
If full supplementary-plane Unicode support is a goal, it should be a separate issue.