Feature #7504
Export data tool from FWD into .d files
100%
Screenshot_2025-05-26_17-57-37.png (322 KB)
{kind=link}
build.properties  (379 Bytes)
(379 Bytes)
build.xml
(45.3 KB)
build_db.xml
(18.9 KB)
Related issues
History
#1 Updated by Alexandru Lungu about 3 years ago
This is a task inspired by #7241: the need of exporting the data from FWD in .d files to do a schema upgrade on import.
The goal here is to have a Java native fast internal tool that allows the extraction of persistent data into .d files. There files should be "importable" in the sense that they can be used for a further database import back in a newer FWD. This is fundamental to schema upgrades and data migration.
#3 Updated by Alexandru Lungu almost 3 years ago
- Status changed from New to WIP
- Assignee set to Ștefan Roman
#4 Updated by Alexandru Lungu almost 3 years ago
Plan¶
We need an ant option for this. To be consistent, I suggest something like ant export.db that relies on the build.properties configuration (database HOST, PORT, USERNAME, PASSWORD, ENGINE, etc.). The target should be a light-weight brand new com.goldencode.p2j.schema.ExportWorker main class.
The database can be spoiled with different kind of extra tables / fields we don't actually want to export, right? Also, I don't think that we actually want to rely on an existing .df for that matter, so we need to stick to a complete solution that works exactly like the OpenEdge export tool.
- We need to infer what tables are to be exported and what are their legacy name / order. If we simply select all tables from the database, we may end up with incorrect names, order or tables that we don't actually support in FWD (we don't have specialized DMO classes). The same goes for the table fields and indexes. The most reliable meta-data source is our own DMO annotations. Thus, I suggest making use of:
DmoMetadataManagerto actually parse our own DMO classes.DatabaseManager.getDatabaseTablesto trigger the registering of all DMO classes we have.
- Once we have all
DmoMetafor each table to export, we need to do the actual data dumping. This is not quite a challenge; we can easily usePersistence.executeSQLQueryto retrieve a list of the results we intend to use. Don't forget here to make use of sever-side cursors: no auto-commit, set fetch-size and FORWARD-ONLY. - Once we have the hydrated records, we can basically use
Streamto do the dumping. However, how do we actually take the data out of the DMO?- Maybe we can use something similar to
TableMapper.getLegacyOrderedListandDmoMeta.getLegacyGetterMapto actually retrieve the underlyingBDTfor each legacy field in the right order! - For each list of BDT (a table row basically), we can simply call
Stream.putWorkerwithExportField.
- Maybe we can use something similar to
- AFAIK, lobs are dumped in a separate
LOBSfolder, so we will need to support this as well. - .d files also have a footer, so we may want to generate it as well.
Challenges¶
- We need to double check the export for each kind of type we have. Simple: int, char, logical, etc., but most important we need to pay extra attention to edge cases like memptr, blob, clob, etc.
- We need to ensure the output is consistent with the
.dfthat we used for the initial import, but most important the output should be "equal" to the initial dump we use for testing. This implies order of fields. - Is the cpstream relevant in this whole process? If no, I guess we can set a standard cp-stream (
UTF-8) and just specify in the footer whatever we used. Otherwise, we can make it configurable from Java args.
Dump definition¶
I think we have all we need to actually regenerate the df file, but I guess this is not a priority here. Usually, this tool will be used to reimport the database, so the df would still be there from the very initial import. However, if the df is to be lost in the process, we can actually integrate a tool that also export the data definition based on the existing code (dmo package).
#5 Updated by Greg Shah almost 3 years ago
I agree our ant build should have an option to use this, but I do want our utility code (Java) to be a complete standalone command line tool with all needed parameters passed on the command line. We are moving away from the build.properties approach in the near future, so only the ant scripting should depend on it.
The database can be spoiled with different kind of extra tables / fields we don't actually want to export, right?
I'm not sure about this. In the 4GL, the code would usually be written with an outer loop of for each _file: which would pick up all tables. If we don't do that, then we can't really migrate the existing database.
.d files also have a footer, so we may want to generate it as well.
Yes
We need to double check the export for each kind of type we have. Simple: int, char, logical, etc., but most important we need to pay extra attention to edge cases like memptr, blob, clob, etc.
We should match the behavior of the EXPORT statement.
Is the cpstream relevant in this whole process?
Yes, our import process is very dependent upon the encoding.
#6 Updated by Ovidiu Maxiniuc almost 3 years ago
Greg Shah wrote:
The database can be spoiled with different kind of extra tables / fields we don't actually want to export, right?
I'm not sure about this. In the 4GL, the code would usually be written with an outer loop of
for each _file:which would pick up all tables. If we don't do that, then we can't really migrate the existing database.
If this utility/script will be run as the import counterpart then the full persistence support might not be available (the _meta database and _file populated). But, as for import, we can use the .p2o xml, which is normally present.
Alternatively, the dmo/ of a specified schema folder can be scanned for @Table annotated interfaces and iterate from there. Registering the DMO with DmoMetadataManager, which is anyway required, will return the DmoInfo with all needed metadata. I would recommend staying away from TableMapper with this utility.
#7 Updated by Greg Shah almost 3 years ago
From Stefan via email:
I created an ExportWorker class for #7504 and now I am trying to understand
ant import.dbandImportWorkerapproach, so I can try a similar one for the export tool.
I actually would like to move away from the current ant import.db and ImportWorker approach. These rely upon TRPL and there is not a good reason to use TRPL for this purpose. The ASTs we are "traversing" are highly regular and using an AST for this "structure" is overkill. It complicates the solution without adding any value. I prefer if we read the stored metadata dynamically and then just processed the tables as needed.
For the export, please avoid TRPL completely.
#8 Updated by Alexandru Lungu almost 3 years ago
I actually would like to move away from the current ant import.db and ImportWorker approach. These rely upon TRPL and there is not a good reason to use TRPL for this purpose. The ASTs we are "traversing" are highly regular and using an AST for this "structure" is overkill. It complicates the solution without adding any value. I prefer if we read the stored metadata dynamically and then just processed the tables as needed.
Greg, by stored metadata dynamically you mean the beans we can find in the dmo package (read annotations, hydrate from database and export) or the ones we find in .p2o xml (query the database based on that information). Stefan already has some attempts with both solutions (the second one being more advanced).
- If we rely on the
dmopackage, we are bound to the generated jar and its annotations. I guess this is OK and clean as we have a lot of logic withDMOalready in our persistence layer (i.e. hydration). The good part here is that we have the hydration for free (including extent fields resolution). Also, all of our persistence layer is based onRecord. The bad part here is that we depend on the customer application compiler solution (I don't think we ever do that in our ant commands). - If we rely on the
p2osolution, we can execute such routine without having the application compiled. The good part is that this was already achieved until some point and it was quite accessible to retrieve and parse thep2o. The bad part is that we don't have a clean solution of "hydrating" (going from Java type -> FWD type ->ExportField). AFAIK, there is no FWD type factory solely based on Java types (without record/DMO meta). At best, I think we can retrieve the field type from thep2o, but this will require a
Please advice on the approach here.
If this utility/script will be run as the import counterpart then the full persistence support might not be available (the _meta database and _file populated).
I don't think that a script is the way to go here. A Java utility will be the solution.
Is there any gain into having such information (_meta / _file)? Of course we won't have the full support, but using FWD persistence layer is still the way to go. There are easier solutions as simple JDBC metadata inquiry, but these are too "vanilla" and may loose some FWD inner functionality.
I agree our ant build should have an option to use this, but I do want our utility code (Java) to be a complete standalone command line tool with all needed parameters passed on the command line. We are moving away from the build.properties approach in the near future, so only the ant scripting should depend on it.
An ant command is exactly what I was thinking of as an interface. Note that we have already documented build_db.xml as "commands for import, export, drop, create", even though there is no export yet. Of course, most of the commands will be the same as the import's one (database, url, user, password, etc.), so I can't see how this can be unrelated to an eventual build.properties. I mean, we can remove build.properties and hard-code the parameters into the command-line, but I don't see the advantage here.
#9 Updated by Greg Shah almost 3 years ago
Greg, by stored metadata dynamically you mean the beans we can find in the
dmopackage (read annotations, hydrate from database and export)
Yes, this one.
or the ones we find in
.p2oxml (query the database based on that information).
I want to avoid this usage as this brings more dependencies on TRPL.
- If we rely on the
dmopackage, we are bound to the generated jar and its annotations.
We already have this dependency for ImportWorker since we use the DMOs to actually process each record.
An ant command is exactly what I was thinking of as an interface. Note that we have already documented
build_db.xmlas "commands for import, export, drop, create", even though there is no export yet. Of course, most of the commands will be the same as the import's one (database, url, user, password, etc.), so I can't see how this can be unrelated to an eventual build.properties. I mean, we can removebuild.propertiesand hard-code the parameters into the command-line, but I don't see the advantage here.
The current ant approach has many limitations:
- It requires
antto be installed in addition to FWD. - It is pretty old and doesn't handle things like dependency management, so most customers would prefer moving to gradle or maven. We ourselves prefer gradle for project builds but we have development involved to make the shift. If I recall correctly, gradle still may have some problems with aspectj.
- It is something that is outside of FWD and so we have to maintain independent copies of this scripting for every customer project. Anything built into FWD is standard and does not have to be maintained separately.
Yes, any such utilities will often have some requirement for configuration. But we don't want them to be hard coded to a specific project build approach that we have been using (build.properties, build.xml and the build_db.xml). That stuff was created as a quick and dirty way to script the import and was never meant to be the utimate solution.
#10 Updated by Alexandru Lungu almost 3 years ago
Yes, any such utilities will often have some requirement for configuration. But we don't want them to be hard coded to a specific project build approach that we have been using (build.properties, build.xml and the build_db.xml). That stuff was created as a quick and dirty way to script the import and was never meant to be the utimate solution.
Well, the ant script is ultimately calling a Java command under the hood right, but with some "easy to set" parameters. How do you think of having this integrated? From the Java side, all these options will come a args right? So it makes sense to have an ant (or anything else, including command-line) in place to avoid long command lines. Or maybe we should have a export.sh?
Anyway Stefan, please fall-back to the dmo package approach. This means having <customer-application>.jar in path to do the proper Class look-up.
#11 Updated by Greg Shah almost 3 years ago
We might want to consider reading the configuration from the directory. In that case it will require little or no parameters.
#12 Updated by Greg Shah almost 3 years ago
Also I should point out that export will be used on production systems that won't have the standard application cfg project installed.
#13 Updated by Alexandru Lungu almost 3 years ago
Greg Shah wrote:
We might want to consider reading the configuration from the directory. In that case it will require little or no parameters.
An abstract approach is suitable then. Stefan, please pass down the parameters through the args. Later on, we can adapt this routine to use DirectoryService identically. The point here is that we shall use an abstraction on the way we retrieve the parameters. Consider using an ExportConfiguration instance that is built from main (for now) and passed down to the ExportWorker. Do your development independently from ant / customer project structure. Just add the customer-application jar into the classpath and move on.
I think everything is clear now.
#14 Updated by Eric Faulhaber almost 3 years ago
Another configuration option to consider is to allow a dump of only a subset of tables (perhaps an inclusive or exclusive filter), instead of every table for which a DMO exists.
This poses special challenges, in that:
- it can produce an extremely long command line parameter, compared to other, simpler arguments;
- it should support ad-hoc use, making the directory an inconvenient mechanism.
This is only an issue for the export. The import is naturally filtered by which *.d files are present in the dump directory.
This is a secondary concern to getting the base mechanics of an export working, but it is something to consider now, so we don't make it harder to implement later.
#15 Updated by Alexandru Lungu almost 3 years ago
- Assignee changed from Ștefan Roman to Alexandru Lungu
#16 Updated by Alexandru Lungu about 2 years ago
- Assignee changed from Alexandru Lungu to Andrei Plugaru
#17 Updated by Alexandru Lungu about 1 year ago
- Assignee changed from Andrei Plugaru to Lorian Sandu
Andrei, please commit whatever changes you've done for #7504 and introduce Lorian to this task.
#18 Updated by Alexandru Lungu about 1 year ago
- Priority changed from Normal to High
I am raising the priority to High.
Please make regular updates on this task on the progress.
#19 Updated by Lorian Sandu about 1 year ago
I have started working on the implementation.
Taking into consideration the discussion from the previous notes, i've created a plan with the following steps for the core implementation:
- Retrieve the list of tables to export
- I've used our own DMO classes and the
DatabaseManagerto retrieve allDmoMetafor each table.
- I've used our own DMO classes and the
- Fetch results from the database
- Utilized our persistence layer (
Persistence.executeQuery) to execute queries
- Utilized our persistence layer (
- Export the data
Several considerations are important for this step: - Preserving field order
DmoMeta.getFields()provides an iterator over theoriginalPropertieswhich maintains the required field order
- Mapping result rows to legacy 4GL types
- using
Property._fwdType, we determine the FWD class corresponding to the legacy type and instantiate it using values from the result set - there are a few cases that need special attention:
datetime-tz
- An additional column (_offset) is stored in the DB and must be used to construct thedatetimetzobjectmemptrblob
In OE, the.dfile contains the filename/path of the.blb
In FWD storage varies depending on the dialect. (Will need some more info on this)clob
Requires similar attention depending on the underlying storage mechanism.
- using
- Export the data to a file
- Data is exported using
Stream.export, provided with the list of BDT entries.
- Data is exported using
- Add the footer
- Currently investigating how the footer is generated in OE and what specific information it includes. This still needs clarification.
- How the tool will operate and where it will retrieve required information (e.g., database connection details, dialect, etc.) - will also need to have the
Persistenceinitialized - Encoding requirements
- Support for multitenancy
- Option to export only a subset of tables via include/exclude filters
#21 Updated by Ovidiu Maxiniuc about 1 year ago
- indeed,
DmoMeta.getFields()will give you the correct order of fields to be serialized; - for rehydrating the
datetime-tzyou dan useDatetimetzType.readProperty(). It will automatically read the datetime and offset from aResultSetand store the result at a specified location in the destination array.readProperty()and sibling methods will return the number of column processed fromrsparameter, if you need to know the offset of the next column to be processed; - do not worry/focus on the footer, for now. Both 4GL and FWD will handle the import without it in majority of cases. You'll add it when everything else is working fine;
- in a task like this, if I may offer a work approach, I would export a set of .d files from 4GL from a test database, import them normally in FWD. No need to start the server. Then do the export with your tool and meld (compare) the output with the original file(s). At least this is how I would test my output. Using a set of .d files from a customer application is an alternative, but if a test database would allow you the flexibility to configure the table structures and data as you need. Maybe use that for final tests.
#22 Updated by Lorian Sandu about 1 year ago
I've got a working version and managed to export the data from the database to .d files.
A few things i want to discuss:
- There is a discrepancy with the BLOB columns.
In OE the.dfile stores the name of the*.blbfile0 0 0 0 0 ? ? ? ? ? ? ? ? ? ? ? "blb3836_49.blb" "clb!UTF-8!3836_50.blb"
When importing the database, we don't store the original name of the file at the dmo level, therefore when i export the data back to.dthe row will look like this (there are no functional issues, only the naming is different):0 0 0 0 0 ? ? ? ? ? ? ? ? ? ? ? "null647764_1.blb" "null!ISO8859-1!647764_2.blb"
I wasn't able to retrieve its original name at runtime. - Using Stream needs a client (?):
- for doing the actual export of the BDT list i use something like this:
Stream stream = new StreamWrapper(filename); stream.assign(StreamFactory.openFileStream(filename, true, false)); [......] FieldEntry[] fe = new FieldEntry[fieldsCounter]; fieldEntries.toArray(fe); stream.export(fe);
- as far as i know, using
Streamwill need a client, so running the ExportTool on server side would not be possible with this approach, but correct me if i'm wrong - if there are other ways of doing the actual export, i'm open to suggestions
Up until now, the export was done on the Conversation thread (so, on a single thread).
I used an Executor and modified the export to run on multiple spawned threads but i got some security errors when Stream.export is called (something related to the current context):
Stacktrace...
#23 Updated by Ovidiu Maxiniuc about 1 year ago
Lorian Sandu wrote:
When importing the database, we don't store the original name of the file at the dmo level, therefore when i export the data back to
.dthe row will look like this (there are no functional issues, only the naming is different):
I think what you are looking for IS already in DMO: see @Table.dumpName.
Using Stream needs a client (?):
Maybe StreamWrapper is not the right type of object. See the com.goldencode.p2j.util.FileStream. It is already extended as DataFileReader in ImportWorker to work multithreaded with offline FWD.
#24 Updated by Greg Shah about 1 year ago
In OE the .d file stores the name of the *.blb file
At a minimum we should use blb and clb instead of null in the names.
#25 Updated by Eric Faulhaber about 1 year ago
Do the exported files need to be on the client? It seems like going through the legacy stream support will be a performance killer.
#26 Updated by Lorian Sandu about 1 year ago
Eric Faulhaber wrote:
Do the exported files need to be on the client? It seems like going through the legacy stream support will be a performance killer.
I think no. I used the FileStream as Ovidiu suggested and it seems to be working on the server.
#27 Updated by Greg Shah about 1 year ago
The export isn't converted code and does not need to be executed using the FWD client. Writing the dump on the server makes sense.
#28 Updated by Lorian Sandu about 1 year ago
Greg Shah wrote:
In OE the .d file stores the name of the *.blb file
At a minimum we should use
blbandclbinstead ofnullin the names.
Yes, i agree with this.
I put more thought into this and we can't store the original names of the blob/clob files the at the dmo level. That type of information is per Record so we can't do that, unless we store it somewhere in the database.
For now, i will simply remove the "null" and append "blb/clb" to the filename. Since it doesn't affect the functionality the naming shouldn't be much of a problem.
#29 Updated by Ovidiu Maxiniuc about 1 year ago
Isn't the dumpName attribute of @Table DMO annotation useful (4GL DUMP-NAME attribute) and neither the field name?
Is it anything else from .df syntax?
#30 Updated by Lorian Sandu about 1 year ago
Update on the Implementation
- Successfully made the
ExportWorkerrunnable in offline mode using a lightweight Java command.
The command currently requires the following parameters:- A classpath (-cp) including all necessary JAR files.
- Database connection details.
- The path to the compiled DMO classes (used to load table metadata).
It can be extended to accept additional parameters, such asmaxThreads.
- The export process now runs in multiple threads for improved performance.
- Verified that
RAW,BLOB, andCLOBfields are exported in the same format as in the original.dfiles. - Generated the PSC footer successfully, though it doesn't yet match the original exactly — further refinement is in progress.
#31 Updated by Lorian Sandu about 1 year ago
*.d files with the original ones.Due to the size of some tables (with over 20 million records), I wasn’t able to compare all files. However, I did observe the following:
- The original files were generated on Windows and include carriage return characters (^M), whereas the exported files from my Linux environment do not.
- The date formats can differ. To handle this, my implementation reads the date format from the
p2j.cfg.xmlfile (embedded in the JAR). If no format is specified, it defaults todmy.
- I imported a .d file containing the value
01/01/1920for adatecolumn. - After import, the stored value in the database was
1919-12-31(disregarding the formatting), which indicates the date was altered during the import process.
#32 Updated by Greg Shah about 1 year ago
After import, the stored value in the database was
1919-12-31(disregarding the formatting), which indicates the date was altered during the import process.
Hmm. EEST vs GMT timezone issue?
#33 Updated by Lorian Sandu about 1 year ago
Greg Shah wrote:
After import, the stored value in the database was
1919-12-31(disregarding the formatting), which indicates the date was altered during the import process.Hmm. EEST vs GMT timezone issue?
Probably something related to the timezone. If the column is of type date i would incline to say that it should not take into consideration any timezones, and keep its original value.
Will need to investigate.
#34 Updated by Lorian Sandu about 1 year ago
Lorian Sandu wrote:
Greg Shah wrote:
After import, the stored value in the database was
1919-12-31(disregarding the formatting), which indicates the date was altered during the import process.Hmm. EEST vs GMT timezone issue?
Probably something related to the timezone. If the
columnis of typedatei would incline to say that it should not take into consideration any timezones, and keep its original value.
Will need to investigate.
Should i create a new task for that, or try to solve it here?
#35 Updated by Greg Shah about 1 year ago
Create a new task for the import bug.
#36 Updated by Lorian Sandu about 1 year ago
The implementation is nearly complete; however, I still need some information regarding the PSC footer.
. PSC filename=test_table records=0000000000084 ldbname=empty timestamp=2025/05/14-14:03:03 numformat=44,46 dateformat=mdy-1950 map=NO-MAP cpstream=ISO8859-1 . 0000004564
Does anyone know what the last line from the .d file 0000004564 means ?
#37 Updated by Ovidiu Maxiniuc about 1 year ago
Yes.
That's the size of the payload. In other words, the offset at which the the footer starts (the file offset of the .).
So you just need to get the file size at the end of the import (before writing the footer) and then print into the stream, padded with 0 s up to 10 digits (or more, if the case).
#38 Updated by Lorian Sandu about 1 year ago
While exporting data from a tenant database i found this error when reading a datetimetz value from the database
** Year is out of range or 0. (79)
Postgresql : 0001-12-30 15:52:16.781+01:44:24 BC
Fwd - java : It is mapped as an OffsetDateTime with this value 0000-12-28T08:07:52.325-06:00
Because the year is 0000 when it reaches date.instantiateDate
protected static long instantiateDate(int year, int month, int day)
throws ErrorConditionException
{
if (year < -32768 || year > 32767 || year == 0)
{
ErrorManager.recordOrThrowError(79, "Year is out of range or 0");
return INVALID_DATE;
}
an exception will be thrown.
#39 Updated by Lorian Sandu about 1 year ago
- Status changed from WIP to Review
- reviewer Ovidiu Maxiniuc added
I have committed my changes to 7504b / rev 15905.
Ovidiu, when you have a moment, could you please take a look? I’d appreciate a first round of review.
For running the export tool this command can be used from the root of the project:
java -server -Xmx8g -XX:+HeapDumpOnOutOfMemoryError \ -classpath p2j/build/lib/p2j.jar:deploy/lib/dataset.jar \ -Djava.system.class.loader=com.goldencode.asm.AsmClassLoader \ -Dfile.encoding=UTF-8 \ -Ddialect=com.goldencode.p2j.persist.dialect.P2JPostgreSQLDialect \ -Ddatabase_name=fwd \ -Dconnection.password=admin \ -Dconnection.username=fwd_admin \ -Dconnection.driver_class=org.postgresql.Driver \ -Dconnection.url=jdbc:postgresql://localhost:5432/fwd \ -Ddmo_package=com.goldencode.dataset.dmo \ com.goldencode.p2j.schema.ExportWorker \ -exportPath export \ -lobsPath lobs \ -maxThreads 6 \ -encoding UTF-8 \ 2>&1 | tee data_export_$(date '+%Y%m%d_%H%M%S').log
lobsPath is relative to the exportPath, this directory should be inside it.
App jar, dmo path and db connection info should be changed accordingly.
And also, the directories where the .d and lobs are saved need to be created manually.
-exportPath -lobsPath -maxThreads -encoding are optional, i set some default values for them in the code.
As I write this, I realize the command mixes two ways of passing parameters—both JVM options and arguments to the main method. I think we should decide on a consistent approach.
LE : exportPath is the location where the new exported .d files will be saved
#40 Updated by Ovidiu Maxiniuc about 1 year ago
Review of 7504b / r15905
It seems pretty advanced to me. None of the next issues are really serious, but they should be fixed, anyway:- All files: missing H entry and copyright year, where the case;
DatabaseManager.java:- line 848-863: the indentation of javadoc is incorrect. Please use 3 characters;
Record.java:- lines 2097-2105: this seems like a change belonging to #7020? This looks like a code leak;
DmoMeta.java- line 1650: an empty line is required as a separator between two methods;
- lines 1680: caching in local variable is not needed. The result of
composeFullStatement()can be returned directly;
Loader.java:- line 340: I am sure the name of the method can be improved to better reflect its action.
Note: this method will only work for expanded database layout. In case of normalized tables, the extents from the secondary tables will not be processed. - line 348: please drop the
.append(", ")at line 348, and always rely on line 356 to append the,. It will work since there is always at least the PK in the list.
- line 340: I am sure the name of the method can be improved to better reflect its action.
raw.java:- lines 447/458: I do not think adding quotes here is the right thing to do.
OTOH, exporting this kind of data is not recommended. At the time the records will be imported, there is no possibility to they will keep the originalrowid. LE: I see you excluded them inExportWorker;
- lines 447/458: I do not think adding quotes here is the right thing to do.
ExportWorker.java(the file has some extra empty lines, but I assume these will be removed in later revisions):- lines 1-63: please back-indent the H lines to 1st column;
- line 168: the
*is at wrong position; - line 264: the
implementsshould be placed on the new line; - line 172: line too long;
- line 292: missing method javadoc
- line 494: the
extendsshould be placed on the new line; - line 550:
windowingYearshould be initialized incatchor when declared, otherwise it may remain uninitialized in case of an exception thrown here; - line 634: please remove 'Hibernate'. It is misleading, we are not using (any more) this technology.
#41 Updated by Lorian Sandu about 1 year ago
Thanks for the review, Ovidiu.
Sorry for the formatting issues, i've addressed all of them in rev 15906.
Record.java:
- lines 2097-2105: this seems like a change belonging to #7020? This looks like a code leak;
Yes, the change was intentional. Prior to my update, the handling of denormalized extents was inconsistent. For the first element in an extent, it used legacyName as the key (since res.containsKey(legacyName) was false). However, for subsequent elements, it switched to using prop.getName() as the key, because legacyName had already been added to the map.
This inconsistency led to unpredictable behavior, so I updated the logic to consistently use the property's name (e.g., prop_1, prop_2, etc.) as the key for all elements in denormalized extents.
Loader.java:
- line 340: I am sure the name of the method can be improved to better reflect its action.
Note: this method will only work for expanded database layout. In case of normalized tables, the extents from the secondary tables will not be processed.
Yes, the sql does not contain normalized extents (i've added a note in the javadoc). But, the export implementation works for both types of extents. For normalized tables, the hydration (AbstractRowStructure.hydrateExtents) takes care of fetching the data from the secondary tables if needed.
raw.java:
- lines 447/458: I do not think adding quotes here is the right thing to do.
OTOH, exporting this kind of data is not recommended. At the time the records will be imported, there is no possibility to they will keep the originalrowid. LE: I see you excluded them inExportWorker;
Columns of type raw can be exported. recid and rowid not.
My testing in 4GL reflected that the exported value from a raw type looks like this : "020000", whereas in fwd it was 020000 (note that the quotes are missing). I changed it so that we match OE.
I've committed my changes to 7504b / rev 15906. Please review.
#42 Updated by Ovidiu Maxiniuc about 1 year ago
Review of 7504b / r15906
Good job. Just some minor issues:Record.java:2099: a space is required afterifkeyword;DmoMeta.java:82: The initials should be in CAPs;raw.java: Sorry, that I was a bit confused. Please disregard my reference torowid. However, the issue still remains. The problem is that thetoStringExport()is also called in other cases, where the quotes are not needed. For example, when the value is printed withmessage:message string(raw-field).The call stack is:valueOf()/toStringMessage()/toStringExport(). I wonder whether we can inverse the last two,toStringExport()to add the quotes to the result obtained fromtoStringMessage(). The issue is that not only therawis processed this way and all other BDTs will be affected. I am open to suggestions.ExportWorker:425: I failed to see in my previous review: in jdk8, an inner class cannot bestatic. You can move the class one level, I guess.
#43 Updated by Lorian Sandu about 1 year ago
Ovidiu Maxiniuc wrote:
Review of 7504b / r15906
raw.java: The problem is that thetoStringExport()is also called in other cases, where the quotes are not needed. For example, when the value is printed withmessage:message string(raw-field).The call stack is:valueOf()/toStringMessage()/toStringExport(). I wonder whether we can inverse the last two,toStringExport()to add the quotes to the result obtained fromtoStringMessage(). The issue is that not only therawis processed this way and all other BDTs will be affected. I am open to suggestions.
toStringExport() should only be called in the context of an export statement.
The core logic for constructing the string has been moved to toStringMessage(), and toStringExport() now simply wraps that result in double quotes.
This is similar to the approach used for character, where the value is also wrapped in quotes during export.
I addressed the review from #7504-42 and committed the changes to 7504b / rev 15907.
Please review.
#44 Updated by Ovidiu Maxiniuc about 1 year ago
Review of 7504b / r15907
I think there might be some issues with current changes from raw class. The problem is a bit more complex: the toStringExport() (from BDT super class) is called from in many places (30+). In some of these places, the quotes might not be expected. Each of these must be checked. If that's the case, we have the solution of calling the toStringMessage() in the places where quotes are not wanted. But, because this is an virtual method, all BDTs are affected. In some cases we implemented them the same idiom: toStringMessage() calling toStringExport(). We need to swap the calling order in all these cases.
Please start by investigating whether toStringExport() is returning the expected result in all places where it is called for a raw data type.
#45 Updated by Lorian Sandu about 1 year ago
toStringExport():
- Within the
rawclass: it's only used intoString(), which can be updated to usetoStringMessage()instead. - From the superclass
BaseDataType: it's used inStream.writeField(), which is part of the export flow.
I wasn't able to find any other usages in this specific class or in the superclass BDT.
Ovidiu, did I miss anything? Or is it possible that IntelliJ IDEA didn't list all the usages?
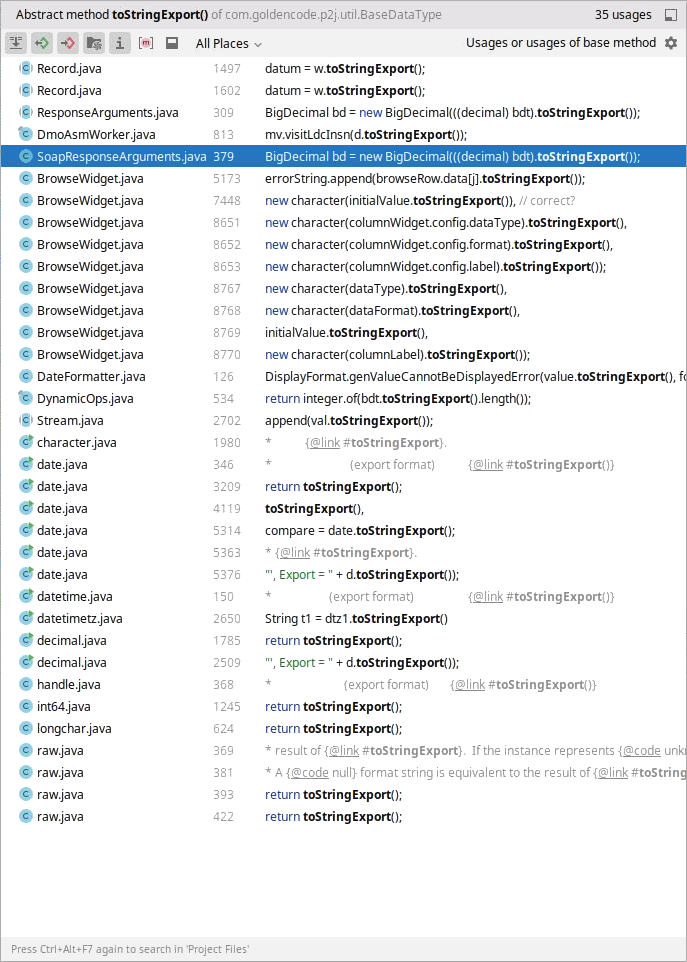
#46 Updated by Ovidiu Maxiniuc about 1 year ago
- File Screenshot_2025-05-26_17-57-37.png added
I'm also on Idea and I see 35 of them. Maybe you have a filter of some kind?
I cannot export this list so I attached a file with the occurrences.
#47 Updated by Lorian Sandu about 1 year ago
Ovidiu Maxiniuc wrote:
I'm also on Idea and I see 35 of them. Maybe you have a filter of some kind?
I cannot export this list so I attached a file with the occurrences.
These are the same occurrences I saw. However, if you examine each usage closely, you’ll notice that only the two I mentioned in #7504-45 are actually relevant for raw or BDT. The others involve character or other base data types, which aren't applicable to our case.
#48 Updated by Ovidiu Maxiniuc about 1 year ago
OK, you mentioned only 2 occurrences, but I knew that there are more calls of the method from the base class.
When I did the capture, I only looked up the occurrences, but did not do any further research on them. If you did that and noticed that each occurrence is guarded by a type-check or otherwise constrained to other BDTs then we should be fine.
#49 Updated by Lorian Sandu about 1 year ago
Ovidiu Maxiniuc wrote:
When I did the capture, I only looked up the occurrences, but did not do any further research on them. If you did that and noticed that each occurrence is guarded by a type-check or otherwise constrained to other BDTs then we should be fine.
Great. So only the usage of toStringExport in raw.java needs to be changed.
7504b / rev 15908:
raw.java: Replaced the use of toStringExport() with toStringMessage().
Ovidiu, could you please take another look at the changes and provide a final review?
#50 Updated by Ovidiu Maxiniuc about 1 year ago
I had a look at r15908 of 7504b.
I noticed that the main() method in ExportWorker lacks the javadoc.
Also, I wonder how will this utility be run? The ExportWorker uses System.out / System.err to report the events and information. I think in certain cases the CentralLogger (or possibly other logger implementation) should be preferred, though. Did the customer give any specifications in this regard?
#51 Updated by Lorian Sandu about 1 year ago
Ovidiu Maxiniuc wrote:
I had a look at r15908 of 7504b.
I noticed that the
main()method inExportWorkerlacks the javadoc.
Added javadoc for main() in rev 15909
Also, I wonder how will this utility be run? The
ExportWorkerusesSystem.out/System.errto report the events and information. I think in certain cases theCentralLogger(or possibly other logger implementation) should be preferred, though. Did the customer give any specifications in this regard?
I don't have any information on the way this export tool is supposed to be run. If needed, i can modify the implementation to use a logger instead. I'm not sure whether directory.xml is required for the logger to work — but if it is, note that ExportWorker only has access to the application JAR and the p2j JAR.
- the connection parameters and the dmo package path sent as
jvmparams-Ddialect=com.goldencode.p2j.persist.dialect.P2JPostgreSQLDialect \ -Ddatabase_name=fwd \ -Dconnection.password=admin \ -Dconnection.username=fwd_admin \ -Dconnection.driver_class=org.postgresql.Driver \ -Dconnection.url=jdbc:postgresql://localhost:5432/fwd \ -Ddmo_package=com.goldencode.dataset.dmo \
- the export params as command line arguments for the main method
-exportPath export \ -lobsPath lobs \ -maxThreads 6 \ -encoding UTF-8 \
The last question isn’t specifically for Ovidiu — anyone can jump in and answer.
#52 Updated by Alexandru Lungu about 1 year ago
I think the best way to deliver this is through an export.sh similar to import.sh we already have.
You can also encode it as an ant script for the GCD team to use and this should be committed to hotel (along with the export.sh) script.
#53 Updated by Ovidiu Maxiniuc about 1 year ago
My vote is for ant target. It's more flexible and the configuration is already there (build.properties).
#54 Updated by Greg Shah about 1 year ago
The ant target is only there when the conversion project is there. In production, it is not there, so the export.sh in FWD itself is a requirement.
#55 Updated by Ovidiu Maxiniuc about 1 year ago
Right :(. It was my developer side talking :).
#56 Updated by Lorian Sandu about 1 year ago
I created export.sh and committed it to 7504b / rev 159107504b / rev 15911.
It it stored in tools/scripts/export.sh and follows the same structure as import.sh.
Ovidiu / Greg , please review.
In the meantime, i will start working on the ant target for export.
#57 Updated by Lorian Sandu about 1 year ago
I added the support for exporting using ant export.db .
The changes are in build.xml and build_db.xml.
Should i post the diffs here so i can get a review before committing them to hotel?
#58 Updated by Greg Shah about 1 year ago
- reviewer Roger Borrello added
Roger: Please review export.sh.
#59 Updated by Lorian Sandu about 1 year ago
Greg Shah wrote:
Roger: Please review
export.sh.
Roger, the revisions that need to be reviewed from 7504b are 15910 and 15911.
#60 Updated by Lorian Sandu about 1 year ago
- File build_db.xml added
- File build.properties added
- File build.xml added
Attached the build.properties, build.xml and build_db.xml from hotel with support for export.
After reviewing export.sh from 7504b, Roger could you also have a look on these?
#61 Updated by Roger Borrello about 1 year ago
Greg Shah wrote:
Roger: Please review
export.sh.
Sorry I missed this. I don't think adding as a reviewer adds as a watcher... is that a function that can be added?
#62 Updated by Roger Borrello about 1 year ago
Lorian Sandu wrote:
Greg Shah wrote:
Roger: Please review
export.sh.Roger, the revisions that need to be reviewed from
7504bare15910 and 15911.
Please update the default values to:
fwd_jar=/opt/fwd/build/lib app_jar=/opt/hotel/lib/hotel.jar
We could discuss whether or not the typical production usage and Docker container will be these, but they should be consistent between import and export.
Don't forget to remove your debug statements:
echo ${db_physical_name}
echo ${db_logical_name}
You can add a check that the export directory doesn't exist before attempting to create it. (Yes, the ! -z is the same as -n, but I sometimes forget).
[ -n "$export_dir_name" ] && [ ! -d "$export_dir_name" ] && mkdir -p "$export_dir_name"
This clever one-liner would read better if the curly brackets were positioned correctly:
mkdir -p "${export_dir_name}/${db_logical_name}/${lobs}" ||
{
echo "ERROR: Failed to create export directory: ${export_dir_name}/${db_logical_name}"
exit 1
}
Better yet, just jettison the one-liner to make it explicit:
if ! mkdir -p "${export_dir_name}/${db_logical_name}/${lobs}"; then
echo "ERROR: Failed to create export directory: ${export_dir_name}/${db_logical_name}"
exit 1
fi
Pass {dbtype} to a single export function, since they are all exactly the same. (If there is a chance different DB types may have different steps, the of course keep the current structure).
exportdb()
{
local dbtype=$1
local export_cmd="${@:2}"
echo "Performing cmd (dbtype=${dbtype})=\"${export_cmd}\""
eval "$export_cmd" 2>&1 | tee "data_export_${dbtype}_$(date '+%Y%m%d_%H%M%S').log"
}
...
exportdb ${dbtype} $cmd
#63 Updated by Roger Borrello about 1 year ago
I'm also curious why you don't allow a list of DBs to be passed in, same as import.sh? I'm not sure I understand the need to track them both (physical and logical)? Perhaps import.sh needs to do similar?
Regarding lobs, this is a little confusing. Does lobsPath always position itself below exportPath? The way I read the help, I could put them anywhere, but we form the directory to be "${export_dir_name}/${db_logical_name}/${lobs}". Why make it an option?
build.properties, did you work off the latest hotel?
- There are vast differences in the
app.4gl.pattern sql.userchanged fromfwd_usertofwd_admin(and password).
Please explain.
I also notice the encoding in the build_db.xml is hardcoded to UTF-8, but in export.sh the -e option is available (yet the -Dfile.encoding=UTF-8 is passed as a java option). What are the plans for supporting more encodings?
#64 Updated by Greg Shah about 1 year ago
I don't think adding as a reviewer adds as a watcher... is that a function that can be added?
No
#65 Updated by Lorian Sandu about 1 year ago
Roger Borrello wrote:
I'm also curious why you don't allow a list of DBs to be passed in, same as
import.sh? I'm not sure I understand the need to track them both (physical and logical)? Perhapsimport.shneeds to do similar?
export.sh was designed with multitenant applications in mind, where the logical and physical database names can differ. Supporting a list of databases would also mean handling a corresponding list of logical names.
In the current implementation, if db.logical.name isn’t specified in build.properties, the script defaults to using the physical name. I don't believe import.sh needs to support this, since its implementation doesn't rely on the logical name.
That said, I could consider adding a parameter to the export command that explicitly enables multitenant mode—requiring the user to provide the logical name for each database when it's enabled.
Regarding lobs, this is a little confusing. Does
lobsPathalways position itself belowexportPath? The way I read the help, I could put them anywhere, but we form the directory to be"${export_dir_name}/${db_logical_name}/${lobs}". Why make it an option?
Yes, the lobs directory is always inside export directory (it has to be this way because our FileStream.setLobDirectory "Sets the stream's lob directory located as a subdirectory for opened current file stream directory." ). The option allows setting a custom name for the directory where the lobs will be saved. If it is something that is not needed, i can hardcode the lobs directory to have lobs name.
Regardingbuild.properties, did you work off the latest hotel?
- There are vast differences in the
app.4gl.patternsql.userchanged fromfwd_usertofwd_admin(and password).
Please explain.
I've uploaded my build.properties file just to highlight the addition of new properties like db.logical.name and db.export_threads. There's no intention to modify any of the existing properties.
I also notice the encoding in the
build_db.xmlis hardcoded to UTF-8, but inexport.shthe-eoption is available (yet the-Dfile.encoding=UTF-8is passed as a java option). What are the plans for supporting more encodings?
The encoding specified via the -e option is used only when writing the data to the .d files, and is meant to replicate the behavior of the OpenEdge export tool. It’s independent of the JVM’s default encoding, which is set to UTF-8 via -Dfile.encoding=UTF-8. I will add an entry in build.properties such as db.export_encoding for the ant equivalent.
#66 Updated by Lorian Sandu about 1 year ago
Committed to 7504b / rev 15912 :
export.sh:
- added support for multiple databases export
- added support for mapping logical database names to physical database names
- when exporting multiple tenant databases, the user must provide a list of logical names matching the order of physical names;
Each logical name must correspond to its respective physical database to ensure correct data export - for single (non-multitenant) databases, the
logical_namesarray is automatically set to match thephysical_namesarray, so specifying logical names separately is not necessary.
- when exporting multiple tenant databases, the user must provide a list of logical names matching the order of physical names;
- append the
physical_nameto the directory name/logical_name_physical_name/so that we could differentiate them (in case thelogical_nameis the same). - addressed some of the concerns from #7504-62
Roger, when you are available, please have a look.
#67 Updated by Greg Shah about 1 year ago
Roger: I would prefer if import.sh did not work on multiple database at once. The reasoning: separate logs for each run and better control over parallelism.
#68 Updated by Roger Borrello about 1 year ago
Greg Shah wrote:
Roger: I would prefer if
import.shdid not work on multiple database at once. The reasoning: separate logs for each run and better control over parallelism.
You have the option of calling import.sh in your own loop, passing each DB individually. Both use cases can be handled.
#69 Updated by Roger Borrello about 1 year ago
Lorian Sandu wrote:
Roger, when you are available, please have a look.
Updates look good. Again, the use case for calling export individually can be accomplished, but now there is the option to do all in one logical unit of work.
#70 Updated by Lorian Sandu about 1 year ago
- Status changed from Review to Internal Test
#71 Updated by Lorian Sandu about 1 year ago
When testing the export tool and importing/exporting the db from a large gui app i encountered again this type of error i mentioned in #7504-31:
I also encountered a potential bug during import:
- I imported a .d file containing the value
01/01/1920for adatecolumn.- After import, the stored value in the database was
1919-12-31(disregarding the formatting), which indicates the date was altered during the import process.
I created #10181 for that and addressed the issue.
#72 Updated by Lorian Sandu about 1 year ago
- Related to Bug #10181: Date shifted one day earlier when importing data added
#73 Updated by Lorian Sandu about 1 year ago
7504b :
rev / 16002- Changed the node name from cfg for
dateformat,numformatandcpstreamto be the same as in theImportWorker. - Added constants for default values.
- Changed the node name from cfg for
rev / 16003- Call
Session.bootstrapto set the value for thePKcolumn name (in case there is a custom value for it inp2j.cfg.xml) - Added null check for Dialect in SQLQuery
- Call
These changes do not affect the core logic of the implementation.
Ovidiu, could you have a look on these two commits please?
#74 Updated by Ovidiu Maxiniuc about 1 year ago
I cannot update to those revisions. The latest I see on branch 7504b is 15914. Maybe you forgot to bind / push?
#75 Updated by Lorian Sandu about 1 year ago
Ovidiu Maxiniuc wrote:
I cannot update to those revisions. The latest I see on branch 7504b is 15914. Maybe you forgot to bind / push?
Sorry, it seems i forgot to push. I've done it now.
#76 Updated by Ovidiu Maxiniuc about 1 year ago
I am OK with the changes.
Please update the %Done.
Just out of my curiosity, why the need to check for null Dialect in SQLQuery?
#77 Updated by Lorian Sandu about 1 year ago
Ovidiu Maxiniuc wrote:
I am OK with the changes.
Please update the%Done.Just out of my curiosity, why the need to check for
nullDialectinSQLQuery?
If there is a SqlException , the Query.getDialect() returns null because the dialect was never registered to the DatabaseManager.dialects map. This can happen only with the ExportTool which is offline and doesn't use the directory.xml or other things.
#78 Updated by Lorian Sandu about 1 year ago
- % Done changed from 0 to 100
#79 Updated by Lorian Sandu about 1 year ago
An update on the testing :
- multitenant app : exported the data from a multitenant db ✅
- large GUI app : exported the data and compared the diffs with the original .d files ✅
- ETF : exported the data and compared the diffs with the original .d files ✅
- CHui regressions test app : exported the data ✅
- large app with fwd-tests (with mariadb): exported the data ✅
Is there something else i should test?
#80 Updated by Ovidiu Maxiniuc about 1 year ago
I think that should be enough. If the extracted data was identical to original .d files in the cases where these were available then we should be OK. The other confirm that there are no flaws in the code of the new utility.
Nevertheless, since the branch is not strictly additive, we must do regression testing before this branch can be merged into trunk. Please coordinate and run the runtime regression tests for the above projects.
#81 Updated by Lorian Sandu about 1 year ago
The runtime regression testing for 7504b finished successfully.
#82 Updated by Greg Shah about 1 year ago
Ovidiu: Please get this into the merge queue if it is ready to go.
#83 Updated by Ovidiu Maxiniuc about 1 year ago
Yes, branch 7504b can be queued for merging into trunk.
#84 Updated by Greg Shah about 1 year ago
- Status changed from Internal Test to Merge Pending
7504b can be merged to trunk now.
#85 Updated by Greg Shah about 1 year ago
Actually, please merge after 10286a.
#86 Updated by Lorian Sandu about 1 year ago
- Status changed from Merge Pending to Test
7504b was merged into trunk / rev 16046
I will also update the Data_Migration with details about the new export tool.
#87 Updated by Lorian Sandu about 1 year ago
I will also update the Data_Migration with details about the new export tool.
Done. Added a new section: Export Data from SQL Database into .d Dump Files
#88 Updated by Greg Shah about 1 year ago
The changes are good. I modified the title and contents to remove the reference to "Progress". These are now just referred to as .d Dump Files. I also mentioned that the tool works for both single and multi-tenant.
#89 Updated by Lorian Sandu about 1 year ago
I tested again the export tool and with the new expanded_extents in place, there is a thing that i had to change in Loader.buildCompleteSelectQuery (this method is used exclusively for the export worker) so that the SQL will be the correct one.
Created 7504c and committed the change to rev / 16047. The change is simple and changes how the full select query is created based on the properties metadata.
I'm not sure who should review this, maybe Stefanel or Ovidiu ?
#90 Updated by Ovidiu Maxiniuc about 1 year ago
I took a look at 7504c / 16047.
I think the code is handle the expanded extents correctly. However, I ask you agree to reorder the code which computes the suffix as:
String expandedSuffix = "";
if (propMeta.dmoProperty.expanded)
{
if (allPropMeta[expIndexStart] != propMeta)
{
expIndexStart = i; // start new expanded extent
}
expandedSuffix = "_" + (i - expIndexStart + 1);
}Also, you need a number for the new H entry, as well.
#91 Updated by Constantin Asofiei about 1 year ago
Lorian, please double-check datetime-tz scalar and extent fields.
#92 Updated by Lorian Sandu about 1 year ago
Ovidiu Maxiniuc wrote:
I took a look at 7504c / 16047.
I think the code is handle the expanded extents correctly. However, I ask you agree to reorder the code which computes the suffix as:
[...]Also, you need a number for the new H entry, as well.
Committed the changes to 7504c / rev 16048
Constantin Asofiei wrote:
Lorian, please double-check datetime-tz scalar and extent fields.
Tested and it works ok.
#93 Updated by Lorian Sandu about 1 year ago
Aside from exporting some data, I believe there's nothing else that needs testing, as the changes only affect ExportWorker.
Could we please add 7504c to the merge queue?
#94 Updated by Constantin Asofiei about 1 year ago
- Status changed from Test to Merge Pending
7504c can be merged now.
#95 Updated by Lorian Sandu about 1 year ago
- Status changed from Merge Pending to Test
7504c was merged into trunk / rev 16053.
#96 Updated by Eric Faulhaber about 1 year ago
- Related to Feature #10310: move tenant database from one multitenant cluster to another added
#97 Updated by Eric Faulhaber 8 months ago
- Tracker changed from Bug to Feature